一種改進的k均值文本聚類算法
2016-09-14 07:26:42張銀明黃廷磊張嬙嬙
桂林電子科技大學學報 2016年4期
關鍵詞:文本
張銀明,黃廷磊,林 科,張嬙嬙
(桂林電子科技大學 計算機與信息安全學院,廣西 桂林 541004)
?
一種改進的k均值文本聚類算法
張銀明,黃廷磊,林科,張嬙嬙
(桂林電子科技大學 計算機與信息安全學院,廣西 桂林541004)
針對k均值算法在文本聚類中由于初始聚類質心隨機選擇,使得聚類結果陷入局部最優,且孤立點和不確定的聚類個數造成k均值算法準確性低、收斂速度慢的問題,提出了一種改進的k均值文本聚類算法。該算法采用fp-growth算法挖掘文本頻繁項集,過濾頻繁項集得到核心頻繁項集,并利用核心頻繁項集指導文本初始聚類質心和聚類個數的生成,最后k均值算法利用初始聚類質心和聚類個數完成文本聚類。在新浪微博數據集上進行文本聚類實驗,實驗結果表明,改進的k均值算法提高了文本聚類的準確性,加快了收斂速度,具有較強的魯棒性。
文本聚類;fp-growth;k均值
隨著網絡信息的爆炸式增長,在海量文本中高效、準確地提煉有價值的信息已成為研究熱點。文本聚類作為文本挖掘的重要手段,將有價值的信息通過文本聚集呈現,是一個自動劃分類別的過程。k均值算法簡單易懂,是應用最廣泛的聚類方法,但k均值算法存在2個不足:1)在聚類之前需要確定數據的聚類個數;2)初始聚類質心的隨機選擇導致聚類結果局部最優而非全局最優。針對上述不足,李小武等[1]提出了基于最優劃分的k均值初始聚類中心選取算法,該算法通過劃分樣本確定初始聚類中心的分布,但文本維數較高時遞歸次數增多。Krishna等[2]采用k均值聚類算法和二分k均值聚類算法分別對文本進行聚類,二分k均值聚類算法不會出現聚類結果局部最優,效果優于k均值聚類算法。Liu等[3]提出了內核k均值算法,減少了非線性支持向量機的訓練樣本,在保持較高的測試精度的同時降低了采樣時間的復雜度。然而,這些算法未考慮聚類個數,導致聚類效率低,聚類效果不理想。為此,基于fp-growth算法,提出了一種改進的k均值文本聚類算法。
1 算法的基本思想和框架
1.1k均值文本聚類算法
k均值文本聚類算法首先對文本進行分詞,然后采用tf-idf、vsm算法對特征詞和特征詞的頻度建模[4],將文本映射為n維的特征向量,并通過特征向量測量文本之間的語義距離,最后利用k均值算法對文本進行聚類。例如,對3篇文章進行分詞并提取特征,可得特征向量
(1)
其中ai、bi、ci(i=1,2,…,n)分別表示特征在3篇文章中出現的次數,n為文章的特征數。向量空間模型采用特征向量余弦測量文章的相似度。余弦值越大,則文章相似度越差,否則文章相似度越好。特征向量余弦
(2)
其中:文本特征向量A=(a1,a2,…,an),B=(b1,b2,…,bn)。
k均值算法流程[5]為:
1)通過隨機函數,創建k個起始質心。
2)計算文本項與每個質心的相似度,將文本項分配到相似度值最小的簇。
3)重新計算每個簇的質心,質心為簇中文本項特征出現次數的平均值。若質心收斂,則聚類完成,否則繼續步驟2)。
k均值算法由于質心的隨機性導致聚類結果局部最優,若隨機選擇的質心是孤立點,則孤立點將單獨成為一個簇,而且影響其他簇的生成,這與聚類的目的相違背[6]。
1.2改進的k均值算法
改進的k均值算法采用fp-growth算法挖掘文本的頻繁項集,過濾頻繁項集得到核心頻繁項集,并利用核心頻繁項集指導k均值算法的初始聚類質心和簇的個數,最后結合k均值算法完成文本聚類。fp-growth算法挖掘的初始聚類質心降低了k均值算法的計算復雜度,避免了孤立點對k均值算法的影響。主要表現為:
1)核心頻繁項集代表數據集中表達主題的個數,精確地描述了聚類個數。
2)通過核心頻繁項集得到的初始聚類質心在文本相似度上屬于每個簇,減少了聚類過程的迭代次數。
fp-growth算法將數據存儲于高度壓縮的數據結構fp-tree,減少了多次遍歷數據庫,而且fp-growth算法通過統計元素項、挖掘頻繁項建立fp-tree,并采用遞增的方式利用條件fp-tree挖掘頻繁項集[7]。
fp-growth算法挖掘頻繁項集的過程為:對給定的事物數據庫進行2次掃描,第一次掃描數據庫,得到元素項的出現次數為w,設定出現次數閾值ε1,若w>ε1,則該元素項稱為頻繁項。由于fp-tree是一棵有序的樹,且挖掘條件模式基依賴頻繁元素的出現次數,因此第二次掃描數據庫,去除不頻繁元素,篩選出項集中的頻繁元素,并且按照頻繁元素出現的次數完成元素的排序。在挖掘頻繁項集的過程中,原始項集包含頻繁元素和非頻繁元素,而挖掘的頻繁項集只包含頻繁元素。元素項處理結果如表1所示,完成了元素項的篩選及排序。

表1 元素項處理結果
fp-tree是一棵根節點為空的樹,除根節點外,其他節點包含元素的名字和元素出現的次數。fp-tree的構建規則為:
1)讀入項集,若項集已存在,則在原來路徑中修改計數值。
2)若項集不存在,則創建一條新路徑,已存在的部分路徑更改計數值。
為了高效地訪問fp-free,增加了頭指針表,頭指針指向給定類型的第一個實例,相同類型彼此連接。在訪問fp-tree時,通過頭指針表,可以快速地訪問給定類型的所有元素。為了形象地描述建樹過程[8],采用表1的數據建立fp-tree,如圖1所示。
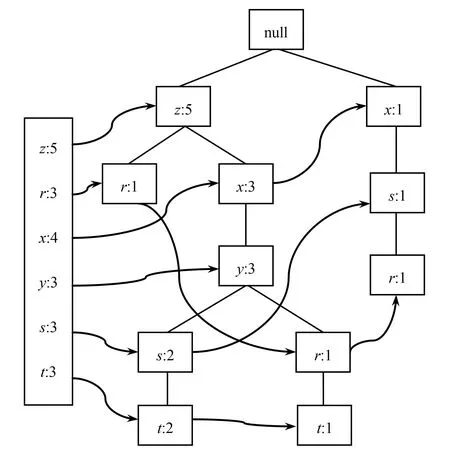
圖1 fp-treeFig.1 fp-tree
在fp-tree中挖掘項集的條件模式基,利用條件模式基構建條件fp-tree。條件模式基是條件fp-tree上查找元素為葉子的路徑集合,條件fp-tree屬于fp-tree。挖掘頻繁項集是一個遞歸的過程,其原理為:
元素項t的條件基為{z,x,y,s}:2,{z,x,y,r}:1,元素項s、r均滿足最小支持度,但項集{t,s}、{t,r}不滿足最小支持度,不是頻繁項集。而項集{t,z}、{t,x}、{t,y}是頻繁項集。下一步查找{t,z}的條件模式基,遞歸挖掘條件模式基,得到所有的頻繁項集。
對頻繁項集進行過濾,得到核心頻繁項集。其過濾規則為:
1)創建一個核心頻繁項集的集合,用于存儲確定的頻繁項集。
2)若頻繁項集Si?Sj,則將頻繁項集Si放入核心頻繁項集。
3)若不存在包含關系,則比較Si、Sj的相似度。若其相似度大于相似度閾值ε,則合并頻繁項集作為核心頻繁項集,否則創建一個新的核心頻繁項集。
核心頻繁項集個數代表聚類的個數,每個核心頻繁項集可作為k均值的初始聚類質心。算法通過調節閾值確定聚類的個數,若對聚類粒度要求較高,可增大閾值,否則減小閾值。改進的k均值算法流程為:
1)采用fp-growth算法指導初始聚類質心和聚類個數的生成。
2)利用初始聚類質心和聚類個數作為k均值的輸入,完成文本聚類。
2 實驗結果與分析
為了測試改進算法的性能,挖掘新浪幾十個熱門話題的10萬條微博,內容包括體育、韓劇、手機等。其中大話題包括多個小話題,對微博聚類測試算法的性能。實驗采用復旦大學的分詞系統對文本分詞,然后使用fp-growth算法挖掘文本的核心頻繁項集,核心頻繁項集的個數由相似度閾值決定,在算法中聚類個數由核心頻繁項集的個數決定,根據聚類結果要求的粗略程度調節閾值。在確定聚類個數和初始聚類質心的前提下,利用k均值算法完成對文本的聚類。
實驗通過改變fp-growth頻繁項集相似度閾值ε,觀察聚類的個數及聚類的效果,并使用準確率P、召回率R和F值評價聚類結果。
(3)
(4)
(5)
其中:T為同類文本被分到同一個簇的個數;M為不同類文本被分到不同簇的個數;N為同類文本被分到不同簇的個數。F為準確率和召回率的協同表現,綜合體現聚類效果的優劣。
改變頻繁項集相似度閾值ε,尋找最佳聚類結果的相似度閾值ε,不同相似度閾值的聚類結果如表2所示。

表2 不同相似度閾值的聚類結果
文本聚類結果的評判方法是文本是否正確歸為本應所屬的簇。簇的個數越多,文本歸屬到對應的簇的概率就越大。若簇的個數足夠多,則每個文本單獨屬于一個簇,顯然聚類個數不能用來衡量聚類效果[9]。由表2可知,當ε=0.75時,F值最大,文本聚類結果最佳。
為了消除參數對算法的影響,改進算法、k均值算法、二分k均值算法3種算法在相同數據集和參數下聚類。取ε=0.75,聚類個數為82個,得到3種算法的聚類結果,如圖2所示。從圖2可看出,改進算法的準確率、召回率、F值均高于k均值算法和二分k均值算法,二分k均值算法高于k均值算法。

圖2 3種算法的聚類結果Fig.2 The clustering results of three algorithms
改進算法、k均值算法、二分k均值算法的迭代次數如圖3所示。從圖3可看出,改進算法的迭代次數在不同數據條數下高于k均值算法和二分k均值算法。由于二分k均值算法將整個數據集作為一個簇,然后將該簇一分為二,并選擇最大程度降低聚類代價函數(誤差平方和)的簇劃分為2個簇,誤差平方和是簇中每個元素與聚類質心距離的平方和。相比k均值算法,二分k均值算法避免了聚類結果的局部最優。但是二分k均值算法的初始聚類質心依然是隨機的,并未避免質心的移動,且誤差平方和增加了算法的計算復雜度,效率沒有顯著提高。改進算法采用核心頻繁項集指導初始聚類質心,聚類質心在文本相似度上與該簇的主題相似,聚類過程中減少了聚類質心的移動,降低了計算復雜度,提高了算法的收斂速度,且獲得了最佳的聚類個數。
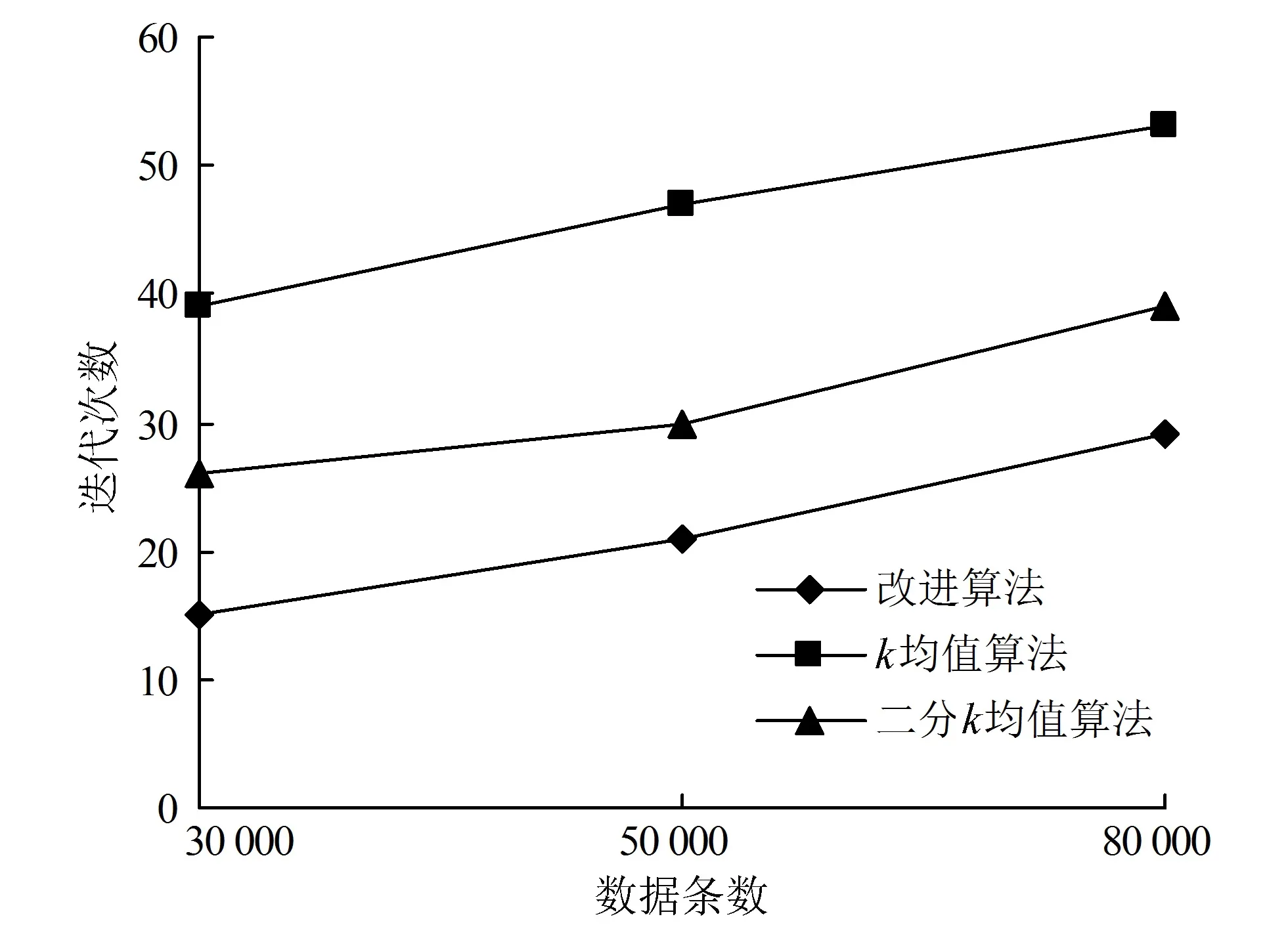
圖3 3種算法的迭代次數Fig.3 The iteration number of three algorithms
3 結束語
基于fp-growth算法,提出了一種改進的k均值文本聚類算法。該算法采用fp-growth算法挖掘頻繁項集,利用頻繁項集過濾核心頻繁項集,通過核心頻繁項集指導聚類個數以及初始聚類質心的生成,最后將其作為k均值算法的輸入,完成了文本聚類。該算法克服了k均值算法容易陷入局部最優的缺陷,提升了算法的收斂速度。
[1]李小武,邵劍飛,廖秀玲.一種基于K-means的分布式聚類算法[J].桂林電子科技大學學報,2011,31(6):460-463.
[2]KRISHNABSV,SATHEESHP,SUNEELKUMARR.Comparativestudyofk-meansandbisectingk-meanstechniquesinwordnetbaseddocumentclustering[J].InternationalJournalofEngineeringandAdvancedTechnology,2012,2249:8958.
[3]LIUXiaozhang,FENGGuocan.Kernelbisectingk-meansclusteringforSVMtrainingsamplereduction[C]//19thIEEEInternationalConferenceonPatternRecognition,2008:1-4.
[4]彭敏,黃佳佳,朱佳暉,等.基于頻繁項集的海量短文本聚類與主題抽取[J].計算機研究與發展,2015,52(9):1941-1953.
[5]XUJiaming,XUBo,TIANGuanhua,etal.Shorttexthashingimprovedbyintegratingmulti-granularitytopicsandtags[J].LectureNotesinComputerScience,2015,9041:444-455.
[6]TIANYun,LIHaisheng,CAIQiang,etal.Measuringthesimilarityofshorttextsbywordsimilarityandtreekernels[C]//IEEEYouthConferenceonInformationComputingandTelecommunications,2010:363-366.
[7]HUXia,SUNNan,ZHANGChao,etal.Exploitinginternalandexternalsemanticsfortheclusteringofshorttextsusingworldknowledge[C]//ACMConferenceonInformationandKnowledgeManagement,2009:919-928.
[8]BHARTIKK,SINGHPK.Hybriddimensionreductionbyintegratingfeatureselectionwithfeatureextractionmethodfortextclustering[J].ExpertSystemswithApplications,2015,42(6):3105-3114.
[9]張建沛,楊悅,楊靜,等.基于最優劃分的k-means初始聚類中心選取算法[J].系統仿真學報,2009,21(9):2586-2589.
編輯:曹壽平
An improved k-means algorithm for text clustering
ZHANG Yinming, HUANG Tinglei, LIN Ke, ZHANG Qiangqiang
(School of Computer and Information Security, Guilin University of Electronic Technology, Guilin 541004, China)
Random selection of initial cluster centroid ink-means algorithm for text clustering resulted in local optimization of clustering results, and isolated points and indeterminate cluster number led to low accuracy and slow convergence speed ofk-means algorithm. So an improvedk-means algorithm for text clustering was proposed. In the proposed algorithm, fp-growth algorithm was used for mining frequent item sets of text, and frequent item sets of text were filtered to obtain the core frequent item sets, and then the core frequent item sets were adopted to generate initial cluster centroid and the number of clustering. Finallyk-means algorithm was applied for text clustering with the generated initial cluster centroid and the number of clustering. The results of text clustering experiment on Sina microblog dataset show that the improvedk-means algorithm can effectively improve the accuracy of text clustering and accelerate the convergence speed, and has strong robustness.
text clustering; fp-growth;k-means
2016-04-07
國家863計劃(2012AA011005)
黃廷磊(1971-),男,安徽肥東人,教授,博士,研究方向為數據挖掘、無線Mesh網絡等。E-mail:tlhuang@guet.edu.cn
TP311
A
1673-808X(2016)04-0311-04
引文格式:張銀明,黃廷磊,林科,等.一種改進的k均值文本聚類算法[J].桂林電子科技大學學報,2016,36(4):311-314.
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
