基于百度指數的登革熱疫情預測研究
2016-08-05 07:58:01王晶晶鄒遠強彭友松李肯立蔣太交
計算機應用與軟件 2016年7期
王晶晶 鄒遠強 彭友松* 李肯立 蔣太交,2
1(湖南大學信息科學與工程學院 湖南 長沙 410082)2(中國科學院生物物理研究所蛋白質與多肽藥物所重點實驗室 北京 100101)
?
基于百度指數的登革熱疫情預測研究
王晶晶1鄒遠強1彭友松1*李肯立1蔣太交1,2
1(湖南大學信息科學與工程學院湖南 長沙 410082)2(中國科學院生物物理研究所蛋白質與多肽藥物所重點實驗室北京 100101)
摘要基于互聯網數據的傳染病疫情監測成為近年來傳染病防治的熱點研究內容。通過對2014年9月暴發的以廣東省為中心的全國登革熱疫情與登革熱相關關鍵詞的百度指數的關聯性分析,發現地區(省、市)登革熱疫情嚴重程度與該地區“登革熱”關鍵詞的百度指數呈很強的正相關性。為了實時地預測疫情動態,建立基于12個登革熱相關關鍵詞的百度指數的多元線性回歸模型。在留一法交叉驗證和反向測試中,該模型對于測試數據的預測值和實際值的皮爾森相關系數分別達到了0.89和0.73。經實驗,該預測模型能夠比較準確地預測登革熱疫情動態,同時該研究對于基于互聯網數據的傳染病疫情監測和防治具有一定的指導意義。
關鍵詞百度指數登革熱定量預測模型
0引言
登革熱是由登革熱病毒引起、伊蚊傳播的一種急性傳染病。臨床特征為起病急驟、高熱、全身肌肉、骨髓及關節痛、極度疲乏,部分患者有皮疹、出血傾向和淋巴結腫大[1]。登革熱廣泛流行于熱帶和亞熱帶的非洲、美洲、東南亞、西太平洋地區以及歐洲個別地區等100多個國家和地區。在中國,本地登革熱暴發地區主要分布在廣東、福建、浙江、云南和臺灣,而輸入性病例地區主要分布在北京、上海、香港、澳門等地[2]。如何及時有效地防治登革熱已經成為了我國和世界其他多個國家和地區日益嚴重的公共衛生問題。
在我國,由于登革熱病毒不像流感病毒那樣季節性地流行,而且一直以來只是散發性流行,很少造成大的公共衛生危機。此外,登革熱疫情的病例數據也很少公開。因此,目前國內針對登革熱疫情監測的研究不多,特別是基于互聯網數據來預測其流行動態的研究很少。2014年9月在我國廣東暴發了史上最大規模的登革熱疫情,在短短的兩個多月時間里登革熱病毒感染人數超過5萬,這對我國的社會和經濟造成了很大的影響。然而此間的登革熱病例數據也給我們研究基于互聯網數據的傳染病(尤其是登革熱)疫情監測提供了一個機會。
在本文中,我們首先分析登革熱在全國和廣東省的疫情分布,以及研究“登革熱”百度指數與地區疫情嚴重程度的關聯性,以此進一步選取與登革熱相關的關鍵詞,并分析其各關鍵詞的百度指數與疫情動態的相關性。由此建立基于12個關鍵詞的百度指數的多元線性回歸模型,并將歷史病例數據加入到模型訓練中,通過留一法交叉驗證評估模型效果,使用反向測試評價預測效果。最終我們發展了一個基于百度指數的定量預測模型來實時地預測登革熱疫情的動態。
1相關研究發展
傳染病監測是預防和控制傳染病疫情的核心。傳統的傳染病疫情監測手段主要依賴各級醫療機構、傳染病預防控制中心和傳染病監測哨點醫院組建的監測網絡提供的數據[3],整個監測體系較為完善,但存在不足。首先,數據的獲取由各級單位逐層上報后匯總,會導致分析結果的滯后性;其次,該監測手段耗費大量人力物力,且病例數據很少對公眾公開。而基于互聯網的傳染病疫情監測在很大程度上彌補了傳統監測手段的不足。首先,互聯網數據涵蓋就診病人和未就診病人對傳染病防控知識、疫情新聞報道等的搜索信息,數據來源的人群范圍更廣;其次,數據雖然集中在少數提供商手中,但其為研究用戶提供了相應數據共享接口,并且數據實時公布[4]。因此,將互聯網數據應用于傳染病疫情的監測成為各國公共衛生研究的重要內容。
利用互聯網數據監測傳染病疫情的思想最先開始于2006年[5]。隨后,各國傳染病疫情監測研究者將互聯網搜索引擎數據[6-11]、社交網絡數據[12-15]、醫療網站數據[16]、藥物銷售數據[17]等應用到疫情的分析監測中。其中針對季節性流感的研究諸多,而且已經取得了很好的效果,如國外的Ginsberg等人[6]利用Google流感趨勢監測流感疫情,其監測時效比CDC監測提前了1~2周。類似的有Li等人[13]利用Twitter數據于流感監測中,同樣具有很強的實時性;在國內,李秀婷等人[7]應用Google搜索引擎數據研究基于互聯網搜索數據的中國流感監測,從116個與流感相關關鍵詞中抽取92個作為分析模型的搜索變量,通過交叉驗證分析,最后取得了較好的模型擬合和預測效果。另袁慶玉等人[8]則是利用百度搜索引擎的百度指數數據監測中國流感趨勢。針對其他傳染病的研究,Milinovic等人[9]基于Google搜索引擎數據利用164個搜索條件對64種傳染病進行分析監測,結果顯示其監測模型對其中17種傳染病的監測效果尤為明顯。這表明基于流感的監測方法對其他傳染病的監測具有很大的潛在意義,尤其是對疫苗可預防、媒介傳播且臨床特征更明顯的傳染病的監測效果更好,其中包括登革熱。而基于互聯網數據來預測登革熱也有了一些研究,影響最大的同樣是來自Google公司的“Google Dengue Trends”。如Althouse等人[10]與Chan等人[11]應用Google趨勢對國外登革熱流行國家如新加坡等地的登革熱疫情進行監測。其研究思路與“Google Flu Trends”一樣,同樣是選擇與登革熱最相關的關鍵詞在Google的搜索數據,建立定量預測模型,將數據集以周為單位進行模型估計和預測,其研究取得了較好的預測效果。
由于一些原因,Google并沒有提供對于中國地區的登革熱流行的預測。百度是國內市場份額最高的互聯網搜索引擎[18],它推出的百度指數已經被各行各業廣泛使用。在傳染病監測領域,同樣已經有研究使用百度指數來預測流感的流行。然而,目前還很少有使用百度指數和其他互聯網數據來預測登革熱的流行。
2登革熱疫情分布
2014年9月,登革熱在中國廣東一帶暴發,病例主要分布在廣東、廣西、云南、福建和臺灣(如圖1(a)所示)。截止10月31日,全國登革熱病例數超過5萬,廣東省疫情最為嚴重,已累計報告登革熱病例42 358例;臺灣省累計報告7425例;廣西、云南、福建省累計報告的本地登革熱病例均超過100例;海南、北京、湖南、浙江、澳門、香港地區累計報告的登革熱病例數均在100例以下,而且主要是輸入性病例。進一步分析廣東省的登革熱疫情(如圖1(b)所示),發現超過80%的病例(累計35 237例)都分布在廣州,其次是佛山(累計3411例),其余市的病例數均在1000例以下。由登革熱引發的死亡病例也主要分布在廣州和佛山,分別有5例和1例病例死亡。
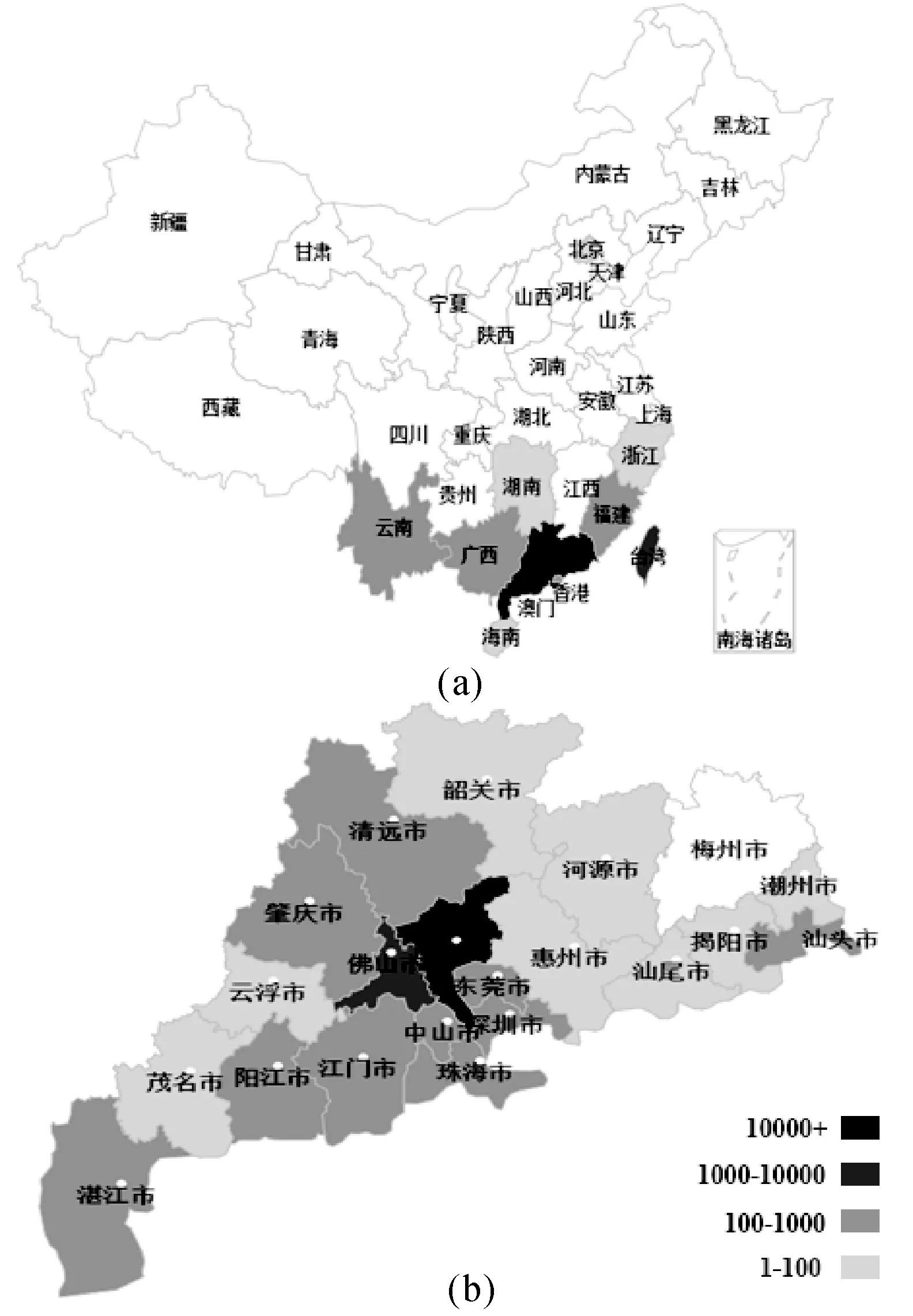
圖1 登革熱疫情在全國、廣東省的病例分布
3實驗數據與方法
3.1數據
(1) 登革熱病例
本文使用的登革熱病例數據來源于中國衛生與計劃生育委員會官方網站、各省衛生與計劃生育委員會官方網站以及網絡新聞報道搜索。病例數據包括全國各疫情省份和廣東省各疫情市截止2014年10月31日的總病例數,以及廣東省從2014年9月22日到2014年10月30日間每日新增病例數,由于除廣東省的其余省登革熱疫情較輕緩,統一報道較少,因此結合網絡新聞搜索共同取得。
(2) 百度指數
本文使用的百度指數數據來源于百度指數平臺(http://index.baidu.com)。百度指數是指關鍵詞在相應時間段內的搜索量數據。本文采集的數據集以天為單位。由于只能得到2014年9月22日到2014年10月30日間廣東省的登革熱每日新增病例數,因此無特別說明外,實驗所使用的關鍵詞的百度指數都是指這段時間的數據。
3.2方法學
(1) 關鍵詞選取
本文根據登革熱定義和臨床癥狀等方面選取了15個與登革熱密切相關的搜索關鍵詞,去除未被百度指數平臺收錄的3個關鍵詞,剩下12個關鍵詞,分別是“登革熱”、“伊蚊”、“皮疹”、“淋巴結腫大”、“頭痛”、“惡心”、“嘔吐”、“腹瀉”、“便秘”、“關節痛”、“發燒”、“皮膚瘙癢”。
(2) 預測模型
(1)
(2)
本文應用的模型為多元線性回歸模型,在模型式(1)中,Dt為第t天的登革熱新增病例數,Bi,t表示第i個關鍵詞在第t天的百度指數數值,n表示模型中包含的搜索關鍵字的個數,n∈[1,12],εt表示模型中的殘差項。在模型式(2)(改進的模型)中,Dt-j表示對于第t天向前偏移j天后得到的登革熱每日新增病例數值,j∈[1,7]。
(3) 相關定義
留一法交叉驗證假設有n條數據,將每一條數據作為測試集,其余n-1條數據作為訓練集。重復方法使每條數據都被作為一次測試集。最后本文用測試集的預測值和實際值之間的相關性作為評價指標。
反向測試指用過去的時間序列數據做訓練集,預測未來的時間序列數據。假設數據集共M條數據,用后N條數據作測試集。以測試其中的第n點為例,我們將前(M-N+n-1)條數據作為訓練集構建模型,預測第n點的值。重復方法N次,最后本文將預測值和實際值之間的相關性作為評價指標。
逐步回歸為建立最優回歸方程,從可供選擇的所有變量中選出對Dt有顯著影響的變量建立“最優”回歸方程。
(4) 統計學分析
本文的相關性分析采用皮爾森相關系數(Pearson)和斯皮爾曼相關系數(Spearman)的方法,使用R語言中的cor()函數完成。多元線形回歸模型使用R語言中的lm()函數完成,逐步回歸使用R語言中的step()函數完成。預測模型的驗證采用留一法交叉驗證LOOCV(Leave-one-out cross validation)和反向測試(Retrospective test),R軟件的版本為R 3.1.2。
4實驗結果與分析
4.1百度指數與地區疫情嚴重程度的相關性
為了定性地衡量百度指數與登革熱疫情的關聯性,我們首先分析了關鍵詞“登革熱”的百度指數與登革熱疫情嚴重程度的相關性。表1展示的是在登革熱流行期間(2014年9月1日到2014年10月31日)各個疫情省份“登革熱”的百度指數中位數,以及相應省份截至2014年10月31日的總病例數。我們發現整體上省份病例數越多其百度指數越高,經計算,兩者存在明顯的正相關:皮爾森相關系數(PCC)為0.997,斯皮爾曼相關系數(SCC)為0.738。
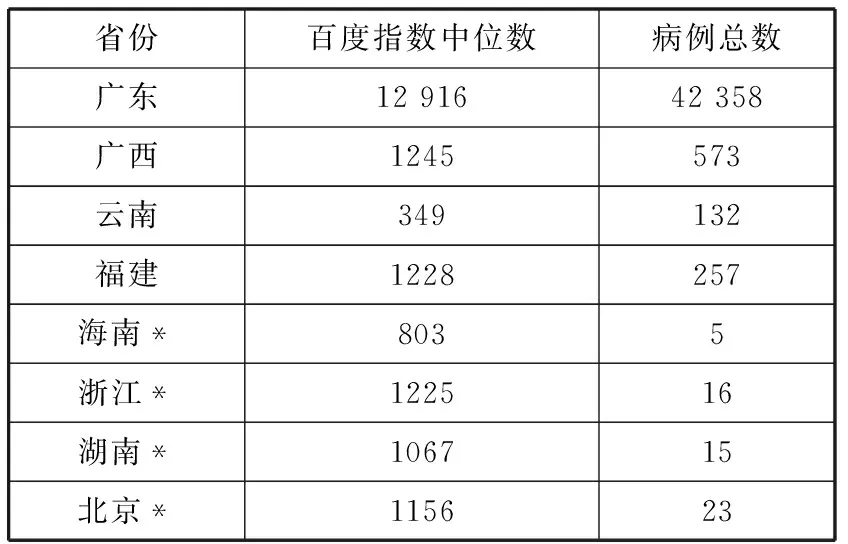
表1 “登革熱”百度指數中位數與病例總數
注:*表示輸入性病例省份
進一步將關聯性分析細化,對廣東省內各個疫情市(20個市)的“登革熱”百度指數中位數與病例總數進行相關性分析,同樣發現兩者之間存在很強的相關性(PCC=0.928,SCC=0.752),兩者的關系如圖2所示。
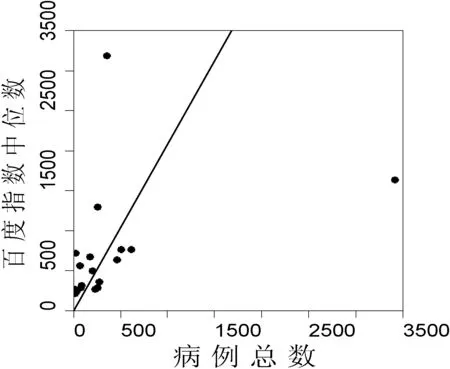
圖2 廣東省各疫情市(除廣州)百度指數中位數與該市的病例總數的關系
4.2各關鍵詞的百度指數與疫情變化的相關性
前面分析表明,從總體上來說,某地區的登革熱疫情的嚴重程度與該地區的“登革熱”百度指數相關性較強,說明可以使用百度指數來定性地評估登革熱疫情的嚴重性。那么它是否能夠用來預測登革熱疫情的動態變化?由于此次登革熱疫情主要發生在廣東省,因此為定量評估百度指數與疫情變化的相關性,本文針對廣東省的疫情動態進行研究。除了關鍵詞“登革熱”,本文另外選擇了11個與登革熱相關的關鍵詞,分析其在廣東省范圍內的每日百度指數與該省登革熱每日新增病例數的相關性。圖3(X軸日期間隔為天;Y軸采用雙坐標,左Y軸為廣東省每日新增病例數(對應實曲線),右Y軸為關鍵詞的百度指數數值(對應虛曲線);BI為百度指數縮寫)舉例展示相關性較強的5個關鍵詞的百度指數與病例數的曲線。經分析,登革熱最常見的癥狀“皮疹”的百度指數與每日新增病例數的相關性最高(PCC=0.825,SCC= 0.823);此外,登革熱名詞“登革熱”和登革熱的常見癥狀“發燒”、“皮膚瘙癢”以及登革熱的傳染源“伊蚊”的百度指數都與病例數有非常強的在時間維度上的正相關。其他關鍵詞的百度指數則與登革熱病例數的相關性較弱。
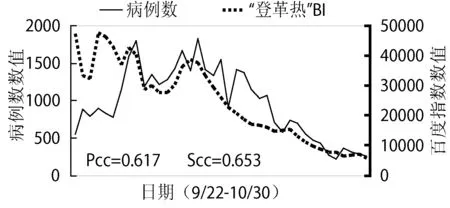
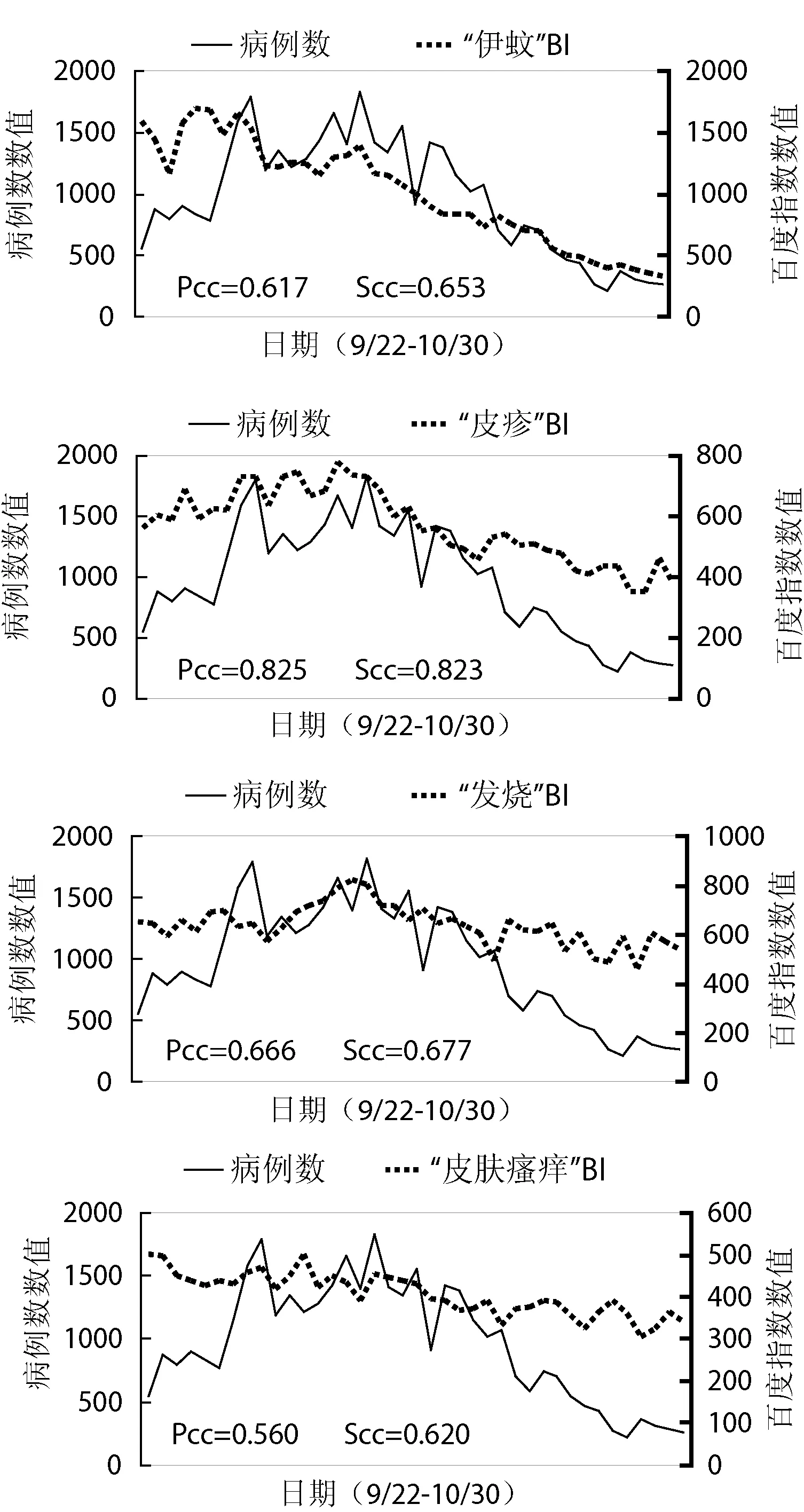
圖3 廣東省每日新增病例數與各個登革熱相關關鍵詞的百度指數的關系
4.3模型預測
為了進一步基于百度指數預測登革熱疫情動態,本文重點研究基于百度指數來預測廣東省的登革熱疫情,建立多元線形回歸模型。該模型以上面相關性分析中與登革熱疫情相關的12個關鍵詞的百度指數作為自變量,以廣東省每日新增病例數作為因變量,該模型增加使用逐步回歸方法去除回歸效果不夠明顯的自變量。
(1) 模型訓練
為了檢測模型的效果,我們首先將所有數據(2014年9月22日至2014年10月30日期間的廣東省每日新增病例數與12個關鍵詞在此期間的每日百度指數,39*13)作為訓練集進行測試。
Input:S={(Ci, Xi_1,Xi_2, …,Xi_12) , i=1,2,…,39}
Process:
Step1//在訓練集S上進行多元線性回歸分析
Ms <- lm(C~ X1+X2+ …+ X12, S)
Step2//逐步回歸
Ss <- step(Ms)
Step3//預測值
Ps <- predict(Ss, S)
Step4//相關性
cor (C, Ps[,1])
Output:{(Ci, Ps[n,1]) , i, n=1,2,…,39}相關系數
模型的訓練效果顯示,其在訓練數據上的預測值和實際值兩者的PCC達到了0.874,說明模型在訓練集上的效果較好。圖4(a)表示該模型在訓練數據上的預測值和實際值的關系。
(2) 模型估計
進一步我們使用留一法交叉驗證來評估該模型的效果,循環將39-1天的數據作為訓練集,其中另1天的數據作為測試集。
Input:S={(Ci, Xi_1, Xi_2,…,Xi_12),i=1,2,…,39}
Process:
Step1 For i=1,2,…,39
//在S上除去第i天的數據得到訓練集
T <- S[-i,]
//在訓練集T上進行多元線性回歸分析
Ms <- lm(C~ X1+X2+ …+ X12, T)
//逐步回歸
Ss <- step(Ms)
//預測值
Ps[i] <- predict(Ss, S)
Step2//相關性
cor (C, Ps)
Output:{(Ci, Ps[i]) , i =1,2,…,39}的相關系數
模型的評估效果顯示,其在留一法交叉驗證的測試集上模型的預測值和實際值的PCC為0.691,說明該模型在測試數據上的效果也較好。圖4表示模型的效果。
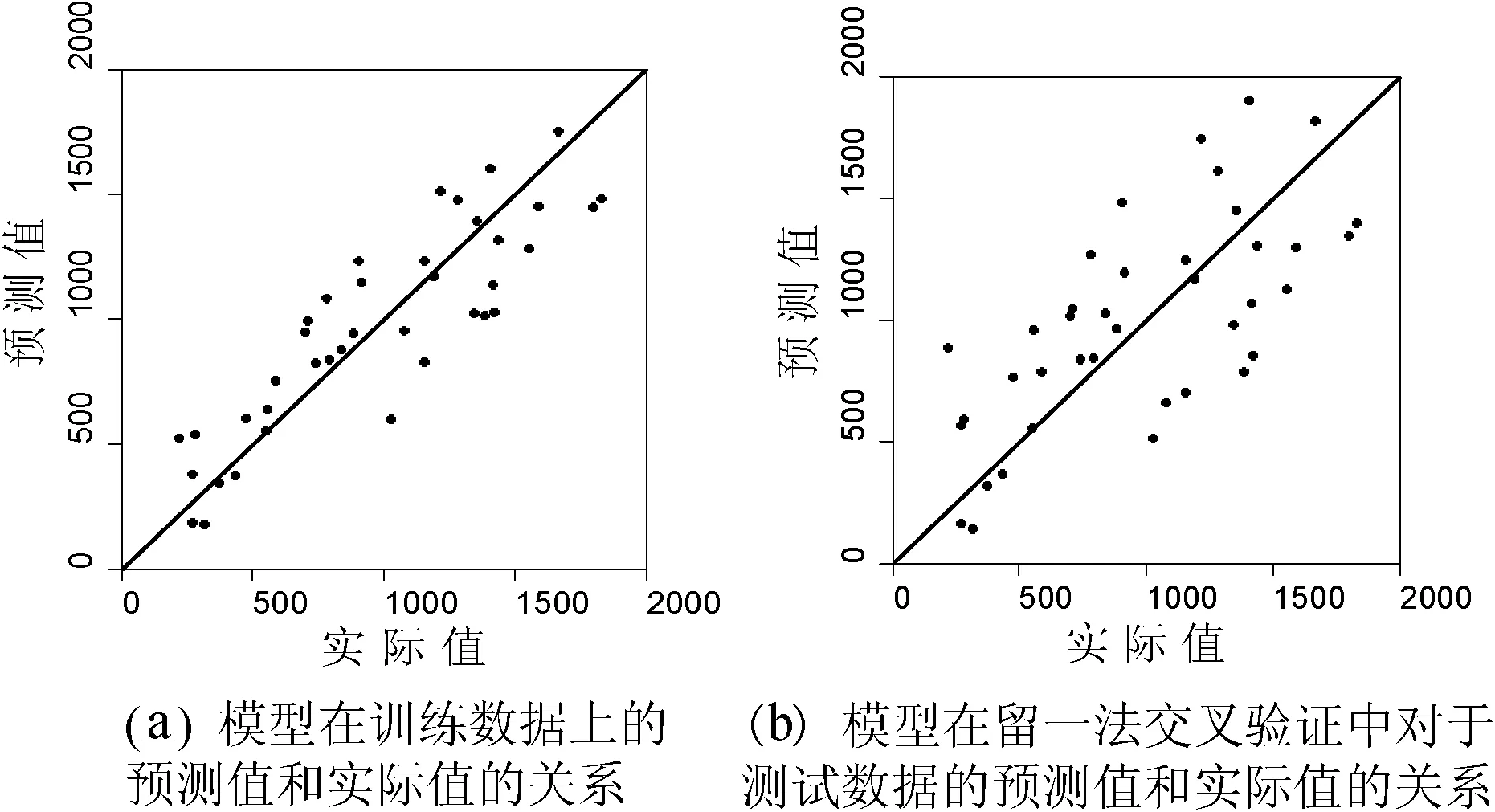
圖4 基于登革熱相關關鍵詞預測登革熱疫情的模型的效果
(3) 模型預測
為了測試模型在實際的登革熱疫情預測中的效果,本文對該模型做了反向測試,即用某天之前的數據訓練模型。然后用得到的模型去預測該天的病例數,進而分析其預測值和實際值的相關性。在本實驗中,我們使用前31天的數據預測后8天的登革熱病例數。
Input:S={(Ci, Xi_1, Xi_2,…,Xi_12) , i=1,2,…,39}
Process:
Step1For j=1,2,…,8
//取S的前j+30天的數據作為訓練集
T <- {Si, i=1,2,…,j+30}
//在訓練集T上進行多元線性回歸分析
Ms <- lm(C~ X1+X2+ …+ X12, T))
//逐步回歸
Ss <- step(Ms)
//預測值
Ps[j] <- predict(Ss, Sj+31)
Step2//相關性
cor (C, Ps)
Output:{(Ci, Ps[j]) , i, j=1,2,…,8}的相關系數
通過模型預測得到后8天的實際值,發現該模型在反向測試中的效果較差,預測值和實際值的皮爾森相關系數只有0.379。
4.4改進的模型預測
考慮到歷史的登革熱疫情也對當前登革熱疫情有一定影響,因此本文將當前登革熱疫情N天(N=1~7)前的登革熱病例數也作為變量加到定量預測模型中,然后評估新模型的效果。
以反向測試舉例說明新模型的預測算法:
Input:S={(Ci, Xi_p,Xi_1, Xi_2, …., Xi_12) , i=1,2,…,39}
Process:
Step1For N=1,2,…,7
For j=1,2,…,8
//取S偏移N天后的前j+30-N天的數據為訓練集
T <- {Si, i=1,2,…,j+30-N }
//在T上進行多元線性回歸分析
Ms <- lm(C~Xp+ X1+X2+ …+ X12, T)
//逐步回歸
Ss <- step(Ms)
//預測值
Ps[j] <- predict(Ss, Sj+31-N)
Step2//相關性
cor (C, Ps)
Output:偏移1~7天的相關系數集Cor[i], i=1,2,…,7。
表2展示了分別把1~7天前的歷史登革熱病例數作為變量增加到模型中得到的新模型在留一法交叉驗證中的效果。可以發現,整合歷史數據之后,模型不管是在留一法交叉驗證還是反向測試中的效果明顯增加,其中在留一法交叉驗證中,其預測值與實際值的PCC均在0.75以上;在反向測試中,預測值與實際值的PCC最高達到了0.733。
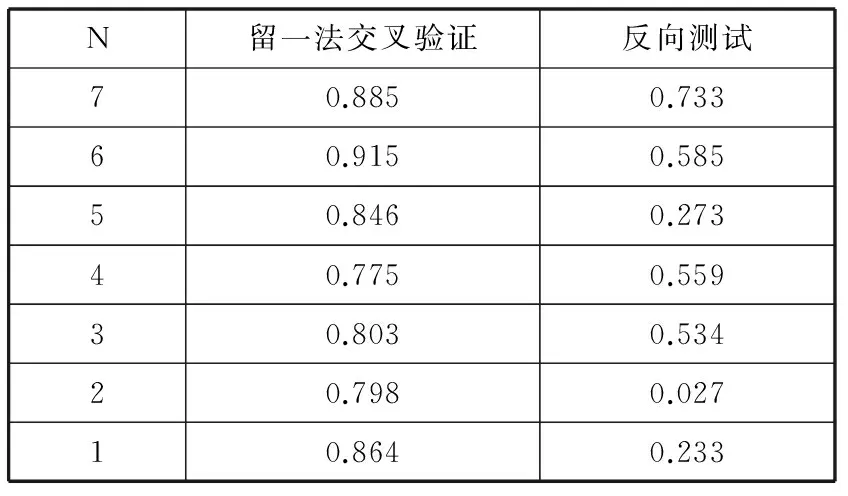
表2 不同偏移時間的模型留一法交叉驗證和反向測試效果
圖5表示在整合7天前的歷史數據時模型在留一法交叉驗證和反向測試中的預測值和實際值的關系。從圖5(a)可以看到在留一法交叉驗證中,整合7天前的歷史數據使得測試值與實際值更為接近;從圖5(b)可以看到在反向測試中,整合7天前的歷史數據使得測試值與實際值不僅相關性較強,而且比較接近。因此加入歷史登革熱病例數據到模型訓練中使得模型的預測效果得到了很大的提高。
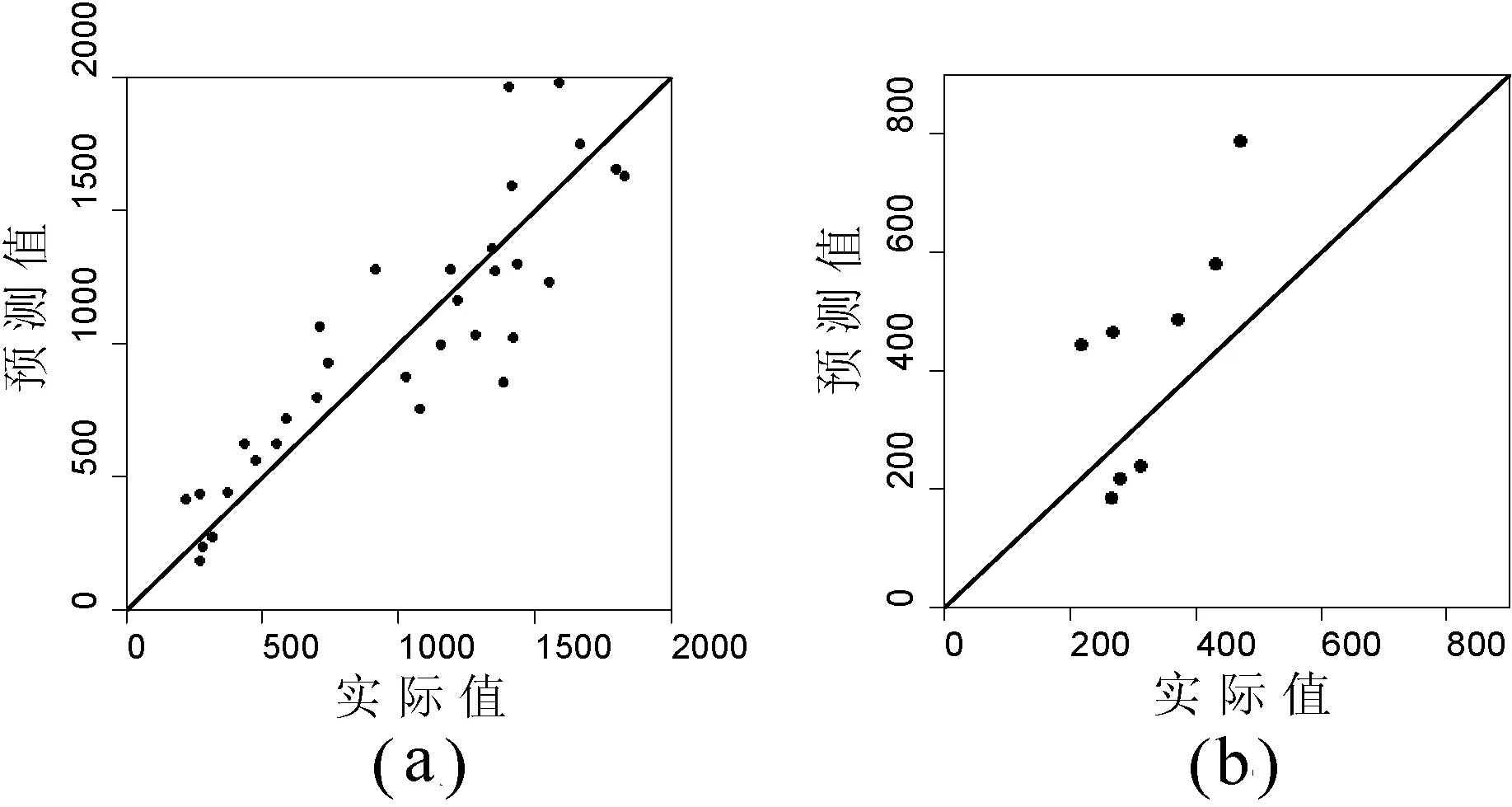
圖5 整合7天前的歷史登革熱病例數據得到的改進的模型在留一法交叉驗證(a)和反向測試(b)中其預測值和實際值的關系
5結語
本文通過對登革熱相關關鍵詞的百度指數與實際登革熱疫情進行相關性分析,發現地區登革熱疫情的嚴重程度與該地區的百度指數存在很強的關聯性。與此同時,在廣東省登革熱暴發期間,每日的登革熱新增病例數與登革熱相關關鍵詞的百度指數也存在明顯的正相關。分析發現,與登革熱相關的幾個關鍵詞,如“登革熱”、“皮疹”、“發熱”、“伊蚊”等的百度指數與實際的登革熱疫情之間存在較強的正相關。基于與登革熱相關的12個關鍵詞的百度指數建立的登革熱預測模型在留一法交叉驗證和反向測試中的效果也較好。因此本文構建的定量預測模型能夠比較準確地預測廣東省的登革熱疫情動態。
由于此次登革熱在廣東省暴發持續的時間較短,因此本研究的一個不足之處在于研究的時間段不長。然而,本研究發現的登革熱相關關鍵詞的百度指數和登革熱疫情的關聯性非常明顯,而且基于它們建立的模型也確實能夠較為準確地預測登革熱的實時疫情。因此,本研究對于國內使用互聯網數據監測傳染病(特別是登革熱)的工作具有一定的參考價值和指導意義。
參考文獻
[1] 中國疾病預防控制中心[EB/OL].(2014-11-06).[2015-01-23].http: //www.china.cdc/gwxx/201411/t20141106_10630.htm.
[2] 何劍峰.登革熱流行趨勢及防控策略[J].實用醫學雜志,2014(19):3462-3463.
[3] 突發公共衛生事件與傳染病疫情監測信息報告管理辦法(衛生部令第37號,2006年8月修改版)[EB/OL].(2009-01).[2015-01-23].http://www.nhfpc.gov.cn/jkj/s7913/200901/896c7b47c2d84 b8b84586f17ade28d71.shtml.
[4] 李銳,王增亮,張志杰.互聯網搜索數據與流感預警[J].中華流行病學雜志,2013(1):101-103.
[5] Eysenbach G.Tracking flu-related searches on the web for syndromic surveillance[J].AMIA Annu Symp Proc,2006(1):244-248.
[6] Ginsberg J,Mohebbi M H,Patel R S,et al.Detecting influenza epidemics using search engine query data[J].Nature,2009,457(7232):1012-1014.
[7] 李秀婷,劉凡,董紀昌,等.基于互聯網搜索數據的中國流感監測[J].系統工程理論與實踐,2013(12):3028-3034.
[8] Yuan Q Y,Nsoesie E O,Lv B,et al.Monitoring influenza epidemics in china with search query from Baidu[J].PloS ONE,2013,8(5):1-7.
[9] Milinovich G J,Avril S M,Clements A C,et al.Using internet search queries for infectious disease surveillance:screening diseases for suitability[J].BMC Infectious Diseases,2014,14(1):3840.
[10] Althouse B M,Ng Y Y,Cummings D A T.Prediction of Dengue Incidence Using Search Query Surveillance[J].PloS Neglected Tropical Diseases,2011,5(8):e1258.
[11] Chan E H,Sahai V,Conrad C,et al.Using Web search Query Data to Monitor Dengue Epidemics:A New Model for Neglected Tropical Disease Surveillance[J].PloS Neglected Tropical Diseases,2011,5(5):e1206.
[12] Gu H,Chen B,Zhu H,et al.Importance of Internet Surveillance in Public Health Emergency Control and Prevention Evidence From a Digital Epidemiologic Study During Avian Influenza A H7N9 Outbreaks[J].J Med Internet Res,2014,16(1):e20.
[13] Li J,Cardie C.Early Stage Influenza Detection from Twitter[J].Eprint arXiv,2013.
[14] Signorini A,Segre A M,Polgreen P M.The use of Twitter to Track Levels of Disease Activity and Public Concern in the U.S during the Influenza A H1N1 Pandemic[J].PLoS ONE,2011,6(5):e19467.
[15] Fung I C,Fu K W,Ying Y C,et al.Chinese social media reaction to the MERS-CoV and avian influenza A(H7N9) outbreaks[J].Infectious Diseases of Poverty,2013,2(1):31.
[16] Hulth A,Rydevik G,Linde A.Web Queries as a Source for Syndromic Surveillance[J].PLoS ONE,2009,4(2):e4378.
[17] Pivette M,Mueller J E,Crepey P,et al.Drug sales data analysis for outbreak detection of infectious diseases:a systematic literature review[J].BMC Infectious Diseases,2014,14(1):604.
[18] 中國互聯網絡發展狀況統計報告[EB/OL].(2014-01).[2015-01-23].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201403/P020140305346585959798.pdf.
收稿日期:2015-01-28。國家自然科學基金項目(31371338);國家傳染病重大專項(2013ZX10004611-002,2014ZX10004002-001);湖南大學青年教師成長計劃項目(531107040720);湖南大學生物醫學超算項目(531106011004)。王晶晶,碩士生,主研領域:生物信息學,數據挖掘。鄒遠強,博士生。彭友松,助理研究員。李肯立,教授。蔣太交,教授。
中圖分類號TP391
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.07.010
ON PREDICTION OF DENGUE EPIDEMICS BASED ON BAIDU INDEX
Wang Jingjing1Zou Yuanqiang1Peng Yousong1*Li Kenli1Jiang Taijiao1,2
1(SchoolofComputerScienceandElectronicEnginnering,HunanUniversity,Changsha410082,Hunan,China)2(KeyLaboratoryofProteinandPeptidePharmaceutical,NationalLaboratoryofBiomacromolecules,InstituteofBiophysics,ChineseAcademyofSciences,Beijing100101,China)
AbstractIn recent years, the internet data-based epidemics surveillance for infectious diseases has been the hot topic of studies in infectious diseases prevention and treatment. Through analysing the correlation between the dengue epidemic outbreak in September, 2014 in whole China with Guangdong province as the centre and the Baidu index of the keywords correlated to dengue, we found that the severity of dengue epidemic in each province has strong positive correlation with Baidu index of keyword “dengue” in given province. For timely predicting dengue epidemic status, we built a multivariate linear regression model, which is based on the Baidu index of 12 dengue-correlated keywords. In both leave-one-out cross-validation and retrospective testing, the model performed well, with Pearson correlation coefficient between the predicted and actual epidemic size equalling to 0.89 and 0.73 respectively. It was indicated through experiment that this prediction model could be preferably accurate in predicting dengue epidemic status, at the same time our study has certain significance in terms of guidance for internet data-based surveillance, prevention and treatment of infectious diseases.
KeywordsBaidu indexDengueQuantitative prediction model
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂天地(音樂創作版)(2022年1期)2022-04-26 13:51:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
Defence Technology(2020年4期)2020-07-02 03:16:58
數學物理學報(2020年2期)2020-06-02 11:29:24
37°女人(2020年5期)2020-05-11 05:58:52
青年與社會(2018年2期)2018-01-25 15:37:06
光學精密工程(2016年6期)2016-11-07 09:07:19
