DLPF:基于異構體系結構的并行深度學習編程框架
2016-07-19 01:54:12王岳青李寶峰
計算機研究與發展 2016年6期
王岳青 竇 勇 呂 啟 李寶峰 李 騰
1(國防科學技術大學并行與分布處理國防重點實驗室 長沙 410073)2 (國防科學技術大學計算機學院 長沙 410073) (yqwang2013@163.com)
?
DLPF:基于異構體系結構的并行深度學習編程框架
王岳青1竇勇1呂啟1李寶峰2李騰1
1(國防科學技術大學并行與分布處理國防重點實驗室長沙410073)2(國防科學技術大學計算機學院長沙410073) (yqwang2013@163.com)
摘要深度學習在機器學習領域扮演著十分重要的角色,已被廣泛應用于各種領域,具有十分巨大的研究和應用前景.然而,深度學習也面臨3方面的挑戰:1)現有深度學習工具使用便捷性不高,盡管深度學習領域工具越來越多,然而大多使用過程過于繁雜,不便使用;2)深度學習模型靈活性不高,限制了深度學習模型發展的多樣性;3)深度學習訓練時間較長,超參數搜索空間大,從而導致超參數尋優比較困難.針對這些挑戰,設計了一種基于深度學習的并行編程框架,該框架設計了統一的模塊庫,能可視化地進行深度學習模型構建,提高了編程便捷性;同時在異構平臺對算法模塊進行加速優化,較大程度減少訓練時間,進而提高超參數尋優效率.實驗結果表明,該編程框架可以靈活構建多種模型,并且對多種應用取得了較高的分類精度.通過超參數尋優實驗,可以便捷地獲得最優超參數組合,從而推斷各種超參數與不同應用的聯系.
關鍵詞深度學習;編程框架;可視化;異構平臺;加速

Fig. 2 The module library of deep learning.圖2 深度學習的算法模塊庫
信息時代,大數據已經滲透到眾多行業和業務領域,成為重要的生產因素,但其原始數據往往量大而價值密度低,傳統的數據分析技術已經無法有效挖掘數據的功能和價值.因此,必須采取更有效的方法提取大數據的主要特征和內在關聯.2006年,Hinton和Salakhutdinov[1]在國際頂尖學術期刊Science發表文章,提出利用深度信念網絡(deep belief network, DBN)實現大數據的降維及分析,引發了深度學習的浪潮.
典型的深度學習模型結構如圖1所示,由多層構成,每層通過編碼產生隱層輸出,通過解碼將隱層輸出重構輸入數據,并依據重構數據與原始數據的差異更新輸入層與隱含層的連接權值.這種層次化的訓練過程是模仿大腦的層次信息處理機制,組合低層特征形成高層特征從而發現數據的分布式特征表示,進而解釋圖像、聲音和文本等數據的潛在關聯.

Fig. 1 Structure of deep learning model.圖1 深度學習模型結構
與淺層神經網絡相比,深度學習可以有效防止網絡規模劇烈增加.總之,深度學習已經發展為機器學習領域一個十分重要的分支,具有十分大的研究潛力和應用價值,已成為各個領域智能化信息處理的熱點.
深度學習的研究充滿了機遇,但同時面臨著諸多挑戰.
1) 深度學習工具使用便捷性不高
深度學習的不斷發展必然促進開源工具的增加,然而大多數開源工具的使用需要一系列復雜配置,容易出錯;同時,深度學習算法對硬件平臺和軟件環境要求較高,很多研究者并不具備相應的研究條件;此外,已有的深度學習工具種類繁多,不易選擇.以上因素會給深度學習的使用帶來諸多不便,無疑會限制深度學習在新領域的推廣和使用.
2) 深度學習模型靈活性不高
大腦分層進行認知和學習,這是深度學習思想的來源.但大腦各個區域的結構和功能并不相同,因而很可能在學習過程的各個階段使用的是不同的學習算法.為了更好地模擬大腦的學習過程,需要在深度學習的不同層次使用不同算法,這要求深度學習模型具有很高的靈活性,能夠自由組合各種算法模塊.深度學習包括具有不同結構和功能的算法模塊,圖2給出了基本的算法模塊,如稀疏編碼(SC)、自動編碼機(AE)、受限玻爾茲曼機(RBM)、深度信念機(DBM)、遞歸神經網(RNN)、高斯混合模型(GMM)和卷積神經網絡(CNN)等.然而,現有的深度學習模型的各層均由相同的算法模塊構成,這限制了模型的靈活性和多樣性,對深度學習模型研究帶來了不便.
3) 深度學習中超參數尋優比較困難
深度學習算法在訓練過程中主要計算網絡中層與層之間連接的強度參數.此外,深度學習算法訓練得到的特征好壞還與超參數相關.所謂超參數,是指需要人為調整的參數,例如學習率(反映了調整權值參數的快慢程度)、隱層節點數、動量參數等,這些參數對最終的特征提取有著至關重要的作用.目前在深度學習領域并沒有完善的理論指導求解最優超參數組合,只能憑借經驗配置超參數,但大多數人并沒有相關經驗,因此更常用的是網格搜索(grid search)法,即將超參數的各種組合窮舉并依據交叉驗證的平均準確率得到最優組合.由于超參數數量和可能取值較多,從而導致搜索空間大、搜索耗時長.這對深度學習的模型選擇帶來了極高的難度.
綜上所述,深度學習研究已經成為熱點,但同樣面臨著諸多挑戰.本文結合深度學習算法的特點,使用可視化界面簡化深度學習模型的構建過程,通過統一深度學習算法模塊的接口增加模型靈活性,通過自動搜索最優超參數減小超參數配置難度,在此基礎之上研究深度學習并行編程框架.
1相關工作
目前,深度學習領域已有諸多較為成熟的開源工具和平臺.
上面介紹的開源工具盡管應用廣泛,訓練速度較快;但使用便捷性不高,配置較為復雜,對機器配置要求較高,使用過程容易出錯,同時不支持具有混合算法模塊的深度學習模型,靈活性不高,此外,大多數工具并不能自動搜索最優超參數組合.
深度學習除在學術界有較大發展之外,還被廣泛應用于工業界,各大公司都成立了深度學習研究小組,也實現了自己的軟件框架.
Google的DistBelief[10]系統是CPU集群實現的數據并行和模型并行框架,集群內使用上萬個CPU 核來訓練參數數目多達10億的深度神經網絡模型.Facebook實現了多GPU訓練深度卷積神經網絡的并行框架[11],結合數據并行和模型并行的方式來訓練CNN模型.百度搭建了PADDLE(parallel asynchronous distributed deep learning)[12]多機GPU訓練平臺,將數據分布到不同機器,通過參數服務器協調各機器訓練,該架構支持數據并行和模型并行.騰訊的深度學習平臺(Mariana)[13]是為加速深度學習模型訓練而開發的并行化平臺,包括深度神經網絡的多GPU數據并行框架、深度卷積神經網絡的多GPU模型并行和數據并行框架,以及深度神經網絡的CPU集群框架.
工業界的深度學習框架面向特定的應用領域能夠達到較好的效果,但后果就是其模型結構特別復雜,無法兼顧使用的便捷性和模型的靈活性.
本文提出一種基于異構平臺的深度學習編程架構,將深度學習模型構建可視化,使得深度學習編程更為簡單,從而使得更多應用領域的學者方便地使用深度學習模型進行研究;同時設計統一接口模式,使得模型構建更加靈活,增加模型的多樣性.此外,我們的編程框架可以并行搜索最優超參數組合,代替手動調參的繁瑣過程.
2深度學習并行編程框架
深度學習并行編程框架包括4層:Web層、調度層、計算層和加速層.Web層面向用戶,提供可視化編程界面;調度層動態調度計算資源和計算任務;計算層接受不同的應用數據訓練和測試模型;加速層使用協處理器加速訓練和測試過程.如圖3所示,各層之間通過數據傳遞緊密耦合,形成完整架構.

Fig. 3 Hardware architecture of DLPF.圖3 深度學習編程架構硬件映射示意圖
2.1Web層
Web層目標是提供簡潔的可視化編程界面,提高深度學習使用的便捷性.該層由3個界面組成:模型管理界面、數據管理界面和任務管理界面.模型管理界面將深度學習算法以模塊形式顯示,支持通過添加算法模塊動態創建深度學習模型.
圖4是Web層的可視化模型構建界面,左側部分提供多種算法模塊,右側是根據左側算法模塊創建的深度信念網(DBN)模型.在此界面中,用戶無需編程,只需要點擊相應算法模塊并加入到模型中即可,操作簡單,無需任何平臺和軟件配置.

Fig. 4 Visual programming interface.圖4 可視化模型構建界面
模型構建完成后,用戶需要點擊模型的各個模塊進行超參數設置和選擇,超參數設置有3種選項,分別對應設置特定值、設置搜索范圍和步長以及自動搜索.其中,設置特定值針對具備調參經驗的用戶;而后2種選項主要針對其他用戶,采用后臺并行搜索的方法搜索最優組合.用戶使用該界面構建好模型之后,進入數據管理界面.數據管理界面提供數據上傳和數據管理服務,用戶可以選擇已有的數據集或者上傳新的訓練和測試數據,如果數據集過大,也可以直接提供網址以供后臺自動下載數據集.當模型和數據都準備完成后,用戶可以使用任務管理界面為模型分配數據從而創建計算任務,此外,該界面還提供任務管理功能,用戶可以方便地新建、暫停、停止和刪除已有任務.當計算任務完成后,DLPF會將結果發送到Web服務器和用戶的注冊郵箱,并在任務管理界面顯示.
2.2調度層
調度層目標是為空閑節點動態分配計算任務.它接受Web層傳遞的任務,通過任務解析器將任務轉換為模型文件,并將模型文件放置在任務池中等待調度,當有空閑節點時,從任務池中選擇優先級較高的任務進行計算.調度過程必須保證公平性和響應時間,而深度學習訓練過程復雜、所需時間較長,如果任務耗時較長,將會急劇增加其他任務的響應時間,因此采用時間片輪轉算法進行任務調度,這可以保證每個用戶都能公平地使用資源,同時減少響應時間.通過時間片輪轉算法調度之后,各個計算節點能夠盡量均衡地接受任務,從而展開進一步計算.
2.3計算層
計算層包括多個物理節點或者虛擬節點,目標是根據已有數據完成模型參數訓練.當調度層將任務分配給某個計算節點時,計算節點首先從相應存儲設備讀取數據,之后根據調度層傳遞的模型文件,通過已有深度學習模塊庫構建深度學習模型.每個深度學習模型對應一個代價函數,而目標是調整網絡參數使代價函數最小,當代價函數最小時模型達到最優.尋找最小代價函數的過程即為優化過程,可以采用多種優化算法.較為常用的優化算法包括對比散度算法(CD-K)、反向傳播算法(BP)、共軛梯度法(CG)和隨機梯度下降算法(SGD)等.算法1是計算層RBM模塊采用的CD-K算法.在算法1中,首先根據已有數據v計算隱層節點輸出h,然后根據h重構輸入數據v′,再由v′計算出重構數據的隱層輸出h′,最后根據這4個變量更新權值和偏置參數.
算法1.K步對比散度算法(CD-K).
輸入:RBM [v1,v2,…,vn,h1,h2,…,hm],S;
輸出:RBM [Δwij,Δbj,Δci].
① 初始化 Δwij=0,Δbj=0,Δci=0;
②v(0)←S;
③ fort=0,1,…,K-1 do
④ fori=1,2,…,ndo

⑥ end for
⑦ forj=1,2,…,mdo

⑨ end for
⑩ fori=1,2,…,n,j=1,2,…,mdo



Fig. 5 Software architecture of DLPF.圖5 編程框架軟件架構示意圖
所有優化算法在尋優過程中需要不斷計算代價函數值來判斷是否找到最優解,而代價函數的計算過程以矩陣計算為主,當數據量較大時,這一過程成為瓶頸,為了減少矩陣運算時間,DLPF選擇一些速度較快的開源軟件庫用于矩陣運算.例如Armadillo數學庫[14],其底層調用openBLAS[15],NVBLAS[16],LAPACK[17]等庫函數對矩陣運算進行優化加速.此外,由于隨機梯度下降算法(SGD)可以用于除RBM和CRBM之外的其他模塊,而RBM和CRBM都使用CD-K算法優化,因此我們選擇了RBM模塊和SGD算法進行GPU加速.圖5是DLPF框架的軟件架構,核心在于中間的模塊庫(module library),模塊庫目前已經實現了RBM、Auto-Encoder、sparse coding、極限學習機(ELM)[18]、卷積RBM、卷積神經網絡(CNN)以及其他一些變形算法,與核心模塊庫緊耦合的部分包括矩陣運算庫和優化算法庫.
2.4加速層
除在計算層中調用優化數學庫進行程序加速之外,我們還專門設計了高效的GPU并行算法庫,使其在運算過程中可被靈活使用.下面簡單介紹加速層采用的并行算法.
深度學習一般采取分層的網絡結構,采用逐層貪心算法進行訓練.根據層間的連接方式,可以將單層網絡分為局部連接(如卷積神經網)與全連接(如深度信念網絡)2種: 1)對于全連接網絡,設計增強局部并行性的訓練方法,如圖 6所示.單層網絡分為多個局部計算單元,單元間計算并行,并通過通信方式傳遞跨單元計算信息.在此條件下,每個單元存儲整個單層網絡的權值副本,并計算對其他單元中隱含層節點的貢獻,每個隱含層節點接收各個單元的結果后規約更新.2)對于局部連接的卷積網絡,可以對其不同的卷積核展開并行學習,對于相同的卷積核,也可以利用卷積特性進行細粒度并行.

Fig. 6 Parallel algorithm for fully-connected network.圖6 全連接網絡的并行算法
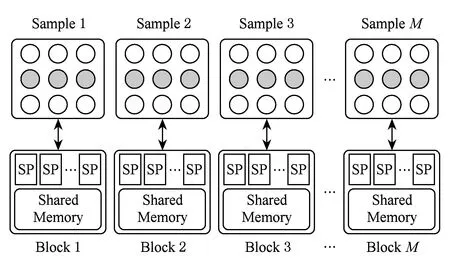
Fig. 7 Block and thread parallel strategies of RBM onGPU.圖7 RBM在GPU的block和thread層面的并行策略
以RBM算法模塊的GPU加速為例,圖7給出了算法在GPU的block和thread層面的并行策略.每個樣本使用1個GPU block計算,而每個樣本需要計算該樣本與所有隱層節點的連接權值,這些連接權值的計算可以完全并行,使用1個線程計算1個連接權值.這種分配策略能夠更好地利用GPU的并行資源,也能更大地挖掘算法的并行性.
統一的編程架構能夠將編程和使用簡單化,可以方便用戶使用和改進機器學習算法.我們的工作是研究各類深度算法處理結構的共性及特異性,根據提取的算法要素提煉出表達簡潔的算法結構,目標是使用戶通過高效的輸入界面、配置文件或者命令語言就能夠準確描述所需要的深度學習算法,之后將算法結構翻譯成為算法模塊,并通過構建數據鏈緊密耦合各個模塊,從而形成完整計算模型.
2.5編程框架特點
1) 可視化編程界面
Web層提供簡潔的可視化編程界面,將深度學習各種算法模塊以圖形方式展現,用戶可以通過添加模塊的形式輕松構建深度學習模型.圖8給出了使用Web界面構建的2個深度學習模型結構的例子,包括有監督的CNN模型和無監督的DBN模型,可視化界面可以清晰地表達模型結構和層間連接關系.

Fig. 8 CNN and DBN models made by the Web layer.圖8 DBN和CNN模型構建示意圖
2) 多模型和多應用支持
DLPF編程框架支持多種應用,目前已經測試過的應用包括手寫字符識別、遙感圖像分類、三維物體分類和自然圖像分類,而且DLPF框架在這些應用上都取得了較好的結果.同時,由于算法模塊的靈活性和統一的接口,DLPF框架還支持構建不同模型,除傳統的深度學習模型之外,還支持構建混合算法模型,例如RBM-AE模型:第1層使用RBM模塊,第2層使用自動編碼機模塊.混合模型的構建是有實際意義的,在引言提到過,大腦在工作時信息會在不同區域接受不同的處理,傳統的深度學習模型在各層使用同樣的算法(DBN)或者每幾層使用類似的算法(CNN),這實際是對大腦不同的區域使用相似的算法模擬,與實際情況并不符合.如果可以構建混合模型,應該能夠更好地模擬大腦工作原理,從而進一步加深人對大腦工作原理的理解.
3) 超參數并行搜索
DLPF框架提供超參數并行搜索功能.用戶在超參數設置時可以指定多個超參數值或者指定超參數范圍和步長,后臺程序會啟動多個主機運行不同的超參數組合,進行網格搜索,通過交叉驗證的方式判斷最優超參數組合并將最優組合和模型返回給用戶.一般模型的超參數個數較多,因此構成的搜索空間巨大,搜索較為耗時,我們采用粗粒度并行方式搜索最佳超參數組合.
3實驗結果與分析
實驗平臺由4臺服務器和1臺PC組成, PC機處理器型號為4核Intel i7-4790K, 主頻4 GHz,用于做加速對比實驗.4臺服務器中1臺作為Web服務器,1臺作為調度服務器,2臺作為計算節點,每臺有2個8核處理器,處理器型號為Intel Xeon E5-2650,主頻為2 GHz,內存為64 GB.每臺計算節點包括1塊NVIDIA K40 GPU,核心頻率為0.745 GHz,共有2 880個核.在多模型實驗、多應用實驗和時間性能測試過程中我們使用1臺計算節點完成,超參數并行搜索實驗采用2個計算節點完成.
3.1多模型支持
DLPF可以靈活構建多種模型,包括RBM,Auto-Encoder,Sparse Coding,Extreme Learning Machine (ELM),ELM-AutoEncoder等簡單模型,也包括DBN,Stacked-AutoEncoder,Stacked-ELM-AE,CNN,Convolutional-ELM(卷積ELM)等深層結構模型,還包括混合算法模型,例如RBM-AE,SC-RBM,CRBM-RBM等.我們在表1給出各個模型針對MNIST手寫字符識別數據庫的最終預測準確率.除ELM相關模型之外的所有模型使用SoftMax模塊進行分類.
通過實驗可以得到3點結論:1)使用深度模型后準確率會增加,但訓練時間也會有所增加;2)不同的模型預測的準確率不相同,這不僅跟算法有關,也跟初始化得到的參數矩陣相關;3)混合模型也能夠得到較好的性能,這是因為在無監督網絡中,每層實際是獨立的,層與層之間通過數據耦合,各層接受輸入數據并抽取數據特征,不需關注這些數據的來源.
Table 1Testing Accuracy of Different Models on MNIST
Dataset
3.2多應用支持
基于DLPF,可以便捷地設計不同模型支持多種應用.目前,DLPF已經成功應用于手寫字符識別、自然圖像識別(CIFAR-10)、合成孔徑雷達(SAR)遙感圖像分類和三維物體識別等應用,并已有研究者愿意使用DLPF開展醫療圖像疾病檢測、駕駛員危險動作識別等應用的研究工作.
圖9是使用DLPF構建的DBN模型對手寫字符無監督提取的特征.從特征圖可以看出,DBN有效提取了字符的一些邊緣信息和紋理特征,這些特征比原圖的像素特征具備更好的區分度.

Fig. 9 Features of MNIST dataset selected by DBN model.圖9 DBN模型提取的手寫字符特征
CIFAR自然圖像分類直接使用無監督網絡的分類精度只有46%,但使用有監督網絡分類精度可達55%左右,如果進行進一步調參并加入RGB三通道訓練,分類精度將會更高.
文獻[19]使用DLPF完成實驗,將深度學習應用于遙感圖像分類中發現,DBN較其他3種算法SVM[20],neural networks (NN),stochastic Expectation-Maximization (SEM)[21],取得了更好的分類效果,在總體分類精度上有較大提升,分類結果與真實的物類別更符合,如圖10所示:

Fig. 10 Remote sensing image classification[21].圖10 遙感圖像分類[21]
DLPF也可以被應用于三維物體識別和分類.通過DLPF設計的三維卷積極限學習機在三維物體分類的數據集上能夠達到87.8%的分類精度,比普林斯頓大學在同樣數據集的分類精度(86%)更高[22]且訓練速度更快.圖11所示是得到的三維物體的特征.

Fig. 11 Features of 3D object.圖11 三維物體特征
3.3超參數并行搜索
采用2個計算節點進行超參數并行搜索實驗,一方面證明并行搜索的有效性,另一方面證明不同超參數對最終預測精度的影響.本節的實驗數據集是MNIST手寫字符庫,模型采用單層RBM+SoftMax分類器,并行搜索學習率(learning rate)和隱層節點數(number of hidden nodes)這2個超參數對模型分類準確率的影響,搜索過程中固定其他超參數.通過測試得到不同的學習率和隱層節點數對最終預測準確率的影響,超參數搜索可以找到分類準確率最高的超參數組合.與單節點相比,雙節點測試時間減少了將近一半,表明并行搜索是有效的.圖12展示了不同超參數組合的預測錯誤率搜索空間.

Fig. 12 The hyper-parameter search space.圖12 超參數搜索空間

Fig. 13 Speedup comparison of RBM module.圖13 RBM模塊加速效果對比
從圖12可以得出3點結論:1)不同超參數組合對最終預測精度是有影響的,如果超參數選擇不好,會直接導致預測錯誤率偏高;2)就手寫字符數據集而言,隱層節點數目越多,對應的預測錯誤率越低,但訓練時間也越長;3)選擇好的學習率有助于快速達到最優解(可能是局部最優),但學習率相近時對性能影響不大.
3.4時間性能
圖13和圖14分別展示了基于CPU-GPU異構平臺對RBM模塊和SGD算法模塊的加速效果.

Fig. 14 GPU speedup comparison of SGD algorithm.圖14 SGD算法的GPU加速效果對比
RBM模塊和SGD算法的GPU加速效果與CPU相比,已經分別達到20多倍和30多倍.在同等硬件平臺下,RBM模塊的加速效果與文獻[23]相比性能更高,加速比達到1.5倍.
4結束語
深度學習在機器學習領域扮演著十分重要的角色,已被廣泛應用于各種領域,具有十分巨大的研究和應用前景.然而,深度學習也面臨著諸多方面的挑戰.本文針對這些挑戰,設計了一種基于異構體系結構的深度學習編程框架.該框架建立了統一的模塊庫,能可視化地進行深度學習模型構建,從而提高了編程的便捷性;同時在異構平臺對算法模塊進行加速,從而減少訓練時間,進而提高超參數尋優效率.實驗結果表明,該編程框架可以靈活構建多種模型,并且對多種應用取得了較高的預測精度.通過超參數尋優實驗,可以便捷地獲得最優超參數組合,從而推斷各種超參數與不同應用的聯系.通過GPU加速實驗可以看到,框架的某些并行算法模塊(RBM,SGD)具有較快的計算速度,與CPU相比,加速比可達數十倍.
參考文獻
[1]Hinton G E, Salakhutdinov R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507
[2]Krizhevsky A. Cuda-convnet: A fast C++/CUDA imple-mentation of convolutional (or more generally, feed-forward) neural networks[OL]. [2014-11-12]. https://code.google.com/p/cuda-convnet
[3]LeCun Y, Jackel L D, Bottou L, et al. Learning algorithms for classification: A comparison on handwritten digit recognition[J]. Neural Networks, 1995, 2(3): 261-276
[4]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C] //Proc of 2012 Neural Information Processing Systems (NIPS’12). Cambridge, MA: MIT Press, 2012: 1097-1106
[5]Jia Yangqing. Caffe: An open source convolutional architecture for fast feature embedding[OL]. [2014-12-12]. http://caffe.berkeleyvision.org
[6]Bergstra J, Breuleux O, Bastien F, et al. Theano: A CPU and GPU math expression compiler[C] //Proc of the Python for Scientific Computing Conf (SciPy). Austin, Texas: No Starch Press, 2010: 3-11
[7]Povey D, Ghoshal A, Boulianne G, et al. The kaldi speech recognition toolkit[C] //Proc of 2011 Automatic Speech Recognition and Understanding(ASRU 2011). Piscataway, NJ: IEEE, 2011
[8]Curtin R R, Cline J R, Slagle N P, et al. MLPACK: A scalable C++ machine learning library[J]. Journal of Machine Learning Research, 2013, 14(1): 801-805
[9]Ronan C, Clement F, Koray K, et al. Torch7 : A scientific computing framework with wide support for machine learning algorithms[OL]. [2015-01-04]. http://torch.ch
[10]Dean J, Corrado G S, Monga R, et al. Large scale distributed deep networks[C] //Proc of the Neural Information Processing Systems (NIPS’12). Cambridge, MA: MIT Press, 2012: 1223-1232
[11]Yadan O, Adams K, Taigman Y, et al. Multi-GPU training of convnets[OL]. [2015-01-12]. http://kr.nvidia.com/content/tesla/pdf/machine-learning
[12]Yu Kai. Large-scale deep learning at Baidu[C] //Proc of Int Conf on Information and Knowledge Management (CIKM 2013). New York: ACM, 2013: 2211-2212
[13]Zou Yongqiang, Jin Xing, Li Yi, et al. Mariana: Tencent deep learning platform and its applications[C] //Proc of the Int Conf on Very Large Data Bases(VLDB 2014). Amsterdam, the Netherlands: Elsevier, 2014: 1772-1777
[14]Conrad S, Ryan C. Armadillo: An open source C++ linear algebra library for fast prototyping and computationally intensive experiments[R]. Queensland, Australia: National Information Communications Technology Australia (NICTA), the University of Queensland, 2010
[15]Zhang Xianyi. OpenBLAS: An optimized BLAS library based on GotoBLAS2 1.13 BSD version[OL]. [2014-12-11]. http://www.openblas.net
[16]NVIDIA. NVBLAS library: A GPU-accelerated library that implements BLAS[OL]. [2014-10-11]. http://developer.nvidia.com
[17]University of Tennessee, University of California, Berkeley, etc. LAPACK (linear algebra package): A standard software library for numerical linear algebra[OL]. [2014-10-12]. http://www.netlib.org/lapack
[18]Huang Guangbin, Zhu Qinyu, Siew C K. Extreme learning machine: A new learning scheme of feedforward neural networks[J]. Neural Networks, 2004, 2(3): 985-990
[19]Lü Qi, Dou Yong, Niu Xin, et al. Remote sensing image classification based on DBN model[J]. Journal of Computer Research and Development, 2014, 51(9): 1911-1918 (in Chinese)(呂啟, 竇勇, 牛新, 等. 基于DBN模型的遙感圖像分類[J]. 計算機研究與發展, 2014, 51(9): 1911-1918)
[20]Chang C, Lin C. LIBSVM: A Library for support vector machines[OL]. [2014-11-20]. http://www.csie.ntu.edu.tw/~cjlin/libsvm
[21]Nielsen S F. The stochastic EM algorithm: Estimation and asymptotic results[J]. Bernoulli, 2000, 3(6): 457-489
[22]Wu Z, Song S, Khosla A, et al. 3D ShapeNets for 2.5D object recognition and next-best-view prediction[OL]. [2015-02-02]. http://arxiv.org/abs/1406.5670
[23]Lopes N, Ribeiro B. Towards adaptive learning with improved convergence of deep belief networks on graphics processing units[J]. Pattern Recognition, 2014, 47(1): 114-127

Wang Yueqing, born in 1988. PhD candidate. His main research interests include computer architecture, machine learning and high performance computing.

Dou Yong, born in 1966. Professor and PhD supervisor. Senior member of China Computer Federation. His main research interests include computer architecture and reconfigurable computing.

Lü Qi, born in 1987. PhD candidate. Student member of China Computer Federation. His main research interests include computer architecture, machine learning and remote sensing image processing.

Li Baofeng, born in 1980. Assistant professor at National University of Defense Technology. His main research interests include design of supercomputer and high performance computer architecture.

Li Teng, born in 1991. Master candidate. His main research interests include computer architecture and high perfor-mance computing.
DLPF: A Parallel Deep Learning Programming Framework Based on Heterogeneous Architecture
Wang Yueqing1, Dou Yong1, Lü Qi1, Li Baofeng2, and Li Teng1
1(ScienceandTechnologyonParallelandDistributedProcessingLaboratory,NationalUniversityofDefenseTechnology,Changsha410073)2(CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073)
AbstractDeep learning plays an important role in machine learning field, and it has been widely used in various applications. The prospect of research and applications of deep learning are huge. However, deep learning also faces several challenges. Firstly, there are many tools in deep learning field, but these tools are not convenient to use for non-expert users because the installation and usage of them are really complex. Secondly, the diversity of deep learning is limited because the flexibility of existing deep learning models is not enough. Furthermore, the training time of deep learning is so long that the optimal hyper-parameters combination cannot be found in a short time. To solve these problems, we design a deep learning programming framework based on heterogeneous architecture in this paper. The programming framework establishes a unified module library which can be used to build a deep model through the visual interface conveniently. Besides, the framework also accelerates the basic modules on heterogeneous platform, and makes the speed of searching optimal hyper-parameters combination be faster. Experimental results show that the programming framework can construct deep models flexibly, and more importantly, it can achieve comparative classification results and better timing performance for a variety of applications. In addition, the framework can search optimal hyper-parameters efficiently and make us infer the relationship of all hyper-parameters.
Key wordsdeep learning; programming framework; visualization; heterogeneous architecture; accelerate
收稿日期:2015-02-15;修回日期:2015-06-23
基金項目:國家自然科學基金項目(61125201,U1435219)
中圖法分類號TP183
This work was supported by the National Natural Science Foundation of China (61125201,U1435219).
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
