H7N9疫情背景下的微博信息傳播特性研究
2016-07-19 02:07:27劉寶立董榮勝蔡國永
計算機應用與軟件 2016年6期
劉寶立 董榮勝 蔡國永
(桂林電子科技大學廣西可信軟件重點實驗室 廣西 桂林 541004)
?
H7N9疫情背景下的微博信息傳播特性研究
劉寶立董榮勝蔡國永
(桂林電子科技大學廣西可信軟件重點實驗室廣西 桂林 541004)
摘要自主研制微博爬蟲系統WeiboCrawler。針對2013年3月爆發的甲型H7N9流感疫情,使用該系統抓取了新浪微博中與該主題相關的數據集,包括用戶信息、原創和轉發博文信息。以原創博文為根節點,基于轉發關系采用遞歸方法構造博文轉發樹,為了嚴格、清晰地描述微博信息傳播過程,對博文轉發樹進行形式化定義,進而研究微博信息傳播過程及轉發樹的大小、深度、寬度等結構特性。結果表明:博文轉發樹的結構特性分布符合長尾分布,博文轉發樹具有深度小、密度大的結構特性;博文流行程度取決于博文轉發樹的寬度,而與博文轉發樹的深度無關;在博文轉發的不同階段,信息傳播表現出相似的傳播特性。考慮微博平臺信息傳播的特點以及博文轉發樹的結構特性,結合Galton-Watson分支過程,給出一種新的信息流傳播模型,使用該模型對博文轉發樹的大小、深度、寬度三項結構特性進行仿真,發現該模型能較準確地體現信息傳播的結構特性。
關鍵詞轉發信息傳播結構特性社交網絡傳播模型
0引言
社交媒體作為傳播觀點和意見的重要平臺在近年來得到了巨大的發展,其中最具代表性的是微博客服務。微博客服務為信息傳播提供了一種獨特的方式,用戶在使用微博客推送消息時,消息受到字數限制。在新浪微博和twitter中,用戶推送的消息內容不能超過140個字符,微博客用戶之間的關系無需一定是雙向關注關系,也就是說,如果用戶A關注了用戶B,無需用戶B也關注用戶A,用戶A的個人主頁中就會顯示用戶B發布的博文。新浪微博作為在中國大陸最受歡迎的社交媒體之一,自從2009年發布以來,積累了巨大的用戶群,截止到2013年12月,新浪微博的月活躍用戶(MAU)數量和日活躍用戶(DAU)數量分別達到了1.291億和6160萬[1]。如此巨大的用戶數量以及新浪微博本身便于信息傳播的特點,使得新浪微博中信息的傳播和共享達到了前所未有的高度。
微博客服務具有用戶數量巨大、通信迅速和跨平臺等特性,這些特性使其迅速成為社會熱點事件期間信息傳播的重要媒介。對微博客服務中的信息傳播進行的研究有很多[2-5],但是有一個方面沒有得到應有的關注,即微博客平臺中信息傳播的結構特性研究,也就是微博客服務中信息傳播的實際機制是怎樣的。
社交媒體中的信息傳播具有一定的結構特性,結構特性指的是信息傳播的深度、廣度等特性,文獻[6]研究了網絡連鎖信中信息傳播的結構特性。那么在微博客服務中,特別是在特定的應急事件背景下,信息傳播的結構特性是怎樣的呢?若能構建一種相應的信息傳播模型來對這些結構特性進行仿真,顯然是具有價值的。研究信息傳播的結構特性為信息傳播模型的設計提供了參考,也能夠為輿情監控、應急事件響應提供有價值的信息。本文以2013年3月底中國大陸爆發的甲型H7N9流感疫情為主題背景。研究的微博數據集來源于新浪微博,包括與H7N9流感相關的原創微博數據、轉發微博數據以及所有的原創用戶和轉發用戶信息。為了研究微博信息傳播的結構特性,基于微博轉發功能遞歸構造了博文轉發樹,并對其進行了形式化定義。在此基礎上對微博信息傳播的過程和結構特性進行了實證研究,研究發現博文轉發樹結構特性表現為傳播寬度大、濃度密集;博文最終的流行程度取決于博文轉發樹的寬度,而與轉發樹的深度無關。以基本結構特性分析為基礎,對博文轉發樹中不同層次的博文轉發進行了研究,發現信息傳播在不同的階段表現出了相似的傳播特性。以結構特性研究為基礎,結合Galton-Watson分支過程構建了一種新的信息傳播模型,使用該模型對博文轉發樹的結構特性進行了仿真,得到了與實際情況較吻合的效果。
1相關工作
社交媒體中的信息傳播已經成為了一個熱門的研究領域。Lerman等[7]對Twitter和Digg社交網絡上的信息傳播進行了實證分析發現了網絡結構會影響信息流的傳播動力學特性,具體來說由于Digg相比于Twitter具有更濃密的網絡結構,因此Digg中信息傳播的速度更快,而Twitter中信息傳播的更遠;Suh等[8]對影響twitter博文轉發率的因素進行了研究,發現在博文的內容特征方面,URLs和Hashtag與博文受到轉發具有很強的關系。
微博客服務在近年來政治活動期間的信息傳播中扮演了重要的角色,其中最著名的例子是奧巴馬總統在2008年的選舉中成功的利用了社交媒體。有關這方面的研究工作也有很多,Stieglitz等[9]研究了Twitter中與政治相關的微博中的情感信息是否會影響其轉發速率;Starbird等[10]研究了2011年埃及政治起義期間微博信息傳播活動。
應急事件期間的通信是非常重要的,近年來,微博客服務作為信息傳播的重要媒介,為各種應急事件期間的有效通信發揮了重要的作用。Li等[11]以2011年日本福島地震和海嘯后的核輻射危機為背景,研究了具有警告和安撫意味的相關微博轉發模式,發現當政府部門發布比普通民眾更多的具有安撫作用的微博后,那么政府部門發布的信息會慢慢失去影響力;有關地震災害期間網民如何使用社交媒體進行應急響應的研究包括[12,13];另外Mendoza等[14]探索了2011年智力發生地震后twitter用戶的行為,特別研究了真實消息和錯誤謠言的傳播情況。
社交媒體信息傳播還包括另一個研究領域,也就是對建立信息傳播分析模型的研究。Galuba等[15]研究了Twitter中含有URL信息的傳播,并提出了使用LT(線性閾值模型)模型來對用戶會轉發哪些URL信息進行預測;Yang等[16]基于LT模型構建了LIM(線性影響力模型)來預測信息傳播過程中節點之間的交互;Cha等[17]引進級聯模型研究Fickr社交網絡中信息的傳播。
2數據獲取與說明
本文的數據集是與2013年3月底中國大陸爆發的甲型H7N9流感相關的新浪微博數據。數據的獲取采用自主研制的微博爬蟲系統WeiboCrawler并結合新浪微博開放API完成,新浪微博提供開放的API,用戶可以在經過新浪微博開放平臺認證的情況下獲得相應數據獲取權限,這一點與Twitter提供的API類似。
微博爬蟲系統獲取數據的一個重要前提是微博的模擬登陸過程。新浪微博模擬登錄過程是WeiboCrawler與新浪微博服務器之間建立數據請求連接的前提。微博登錄過程中密碼加密采用的是RSA公鑰加密算法。具體加密過程如下:
username_=urllib.quote(username)
username=base64.encodestring(username)[:-1]
rsaPublickey=int(pubkey, 16)
key=rsa.PublicKey(rsaPublickey, 65537)
message=str(servertime) +′ ′ +str(nonce) + ′ ′ +str(password)
passwd=rsa.encrypt(message,key)
passwd=binascii.b2a_hex(passwd)
對用戶名和密碼進行加密,在建立請求連接時作為授權信息發送給服務器,獲取請求返回的內容,從而實現了模擬登錄。
圖1展示了WeiboCrawler系統的數據獲取流程。數據獲取流程分為三步:(1) 首先使用WeiboCrawler系統向新浪微博高級搜索頁面發送搜索請求,然后通過關鍵詞匹配找出與H7N9相關的所有原創博文頁面,接下來從頁面中提取出所有的原創博文ID;(2) 以上一步中得到的原創博文ID為線索,調用新浪微博API中的statuses/show()接口,通過該接口可以得到每一條原創博文信息及其對應的博主信息;接下來調用API中的statuses/repost_timeline()接口,以原創博文作為根節點,逐層遍歷當前博文的轉發博文及其用戶信息,同時提取博文間的轉發關系;(3) 最后調用friendships/show()接口獲取存在轉發關系的用戶之間的關系類型,并根據博文轉發關系構建原創博文的轉發樹。

圖1 數據獲取流程圖
數據集合的描述性信息如表1所示。最終得到的數據集合包括52 679條原創博文、1 728 850條轉發博文,博文信息屬性包括博文ID、博文用戶ID、博文創建時間、文本信息、博文獲得的轉發次數以及評論次數等屬性;另外還包括1 314 778個用戶信息,用戶信息屬性包括ID、地理位置、帳號注冊時間、粉絲數量、好友數量以及發表的博文數量等屬性。

表1 數據集合描述
3博文轉發樹形式化定義
本部分對博文轉發樹進行形式化定義。每一棵博文轉發樹都由某一條原創博文及其對應的轉發博文組成。首先給出博文的結構定義,然后給出博文轉發樹的形式化定義。博文集合用TS表示,其中包括原創博文OT和轉發博文RT。博文轉發樹集合用TRTS表示(共有22 364棵博文轉發樹)。
3.1博文結構
博文分為原創博文和轉發博文,下面分別對原創博文OT和轉發博文RT的結構進行形式化定義:
定義1
OT=〈id,user,time,text,repostCount,commentCount〉
其中:
id表示原創博文的編號,每一條原創博文都有一條唯一的編號;
user表示博文OT的博主;
time為日期類型數值,表示OT創建的時間;
text為文本類型數據,表示OT的內容;
repostCount,表示博文OT被轉發的次數;
commentCount,表示博文OT獲得的評論次數;
定義2
RT=〈st_id,id,user,time,text,repostCount,commentCount〉
其中:
st_id(sourcetweetid)表示與該轉發博文具有直接轉發關系的源博文(可能為轉發博文,也可能為原創博文)的編號;
id表示該轉發博文的編號,每一條轉發博文都有一條唯一的編號;
user表示博文RT的博主;
time為日期類型數值,表示RT創建的時間;
text為文本類型數據,表示RT的內容;
repostCount表示博文RT被轉發的次數;
commentCount表示博文RT獲得的評論次數;
3.2博文轉發樹TRT
為了研究信息傳播結構特性,遞歸構造每一條原創博文的博文轉發樹,該博文轉發樹是有向的并且屬于根樹,如圖2所示。樹的根節點(OT)表示原創博文,樹中的其他節點(RTi)表示該原創博文的所有轉發博文。

圖2 博文轉發樹
圖2是博文轉發樹的一個實例,其中:
OT∈{OT|(OT∈TS)∧(OT.repostCount>0)}
其中,RTi表示該原創博文的所有轉發博文,博文轉發樹有四個重要的結構特性,即樹的大小(size)、樹的深度(depth)、樹的寬度(width)、樹的度(degree)。
下面給出博文轉發樹TRT∈(TRTS)的形式化定義:
定義3
TRT=〈N,E,Ndegree,size,depth,level,Li_d,width,degree〉
其中:
N表示轉發樹中的節點,對應博文;
E表示有向邊,對應轉發關系;
Ndegree表示節點度,指的是節點具有的孩子數量,也就是某一條博文的直接轉發數量;
size表示轉發樹的大小,對應轉發樹中的博文總數,size=OT.repostCount+1;
depth表示轉發樹的深度,指的是從根節點到葉子節點的最長路徑長度;
level為博文轉發樹的層次,其中0≤level≤depth;
Li_d指轉發樹的層次度,也就是轉發樹第i層節點度最大的節點的度;
width表示轉發樹的寬度,寬度等于具有最多節點數量的那一層的節點數量和;
degree表示轉發樹的度,指的是轉發樹中節點度最大的節點的度;
由上述博文轉發樹的定義可知,圖2中的轉發樹的大小為9,樹的深度為3,樹的寬度為5,樹的度為3(節點RT1的節點度),RT1處于博文轉發樹的第1層,該博文轉發樹的第一層的層次度為3。
4信息傳播結構特性實證研究
本部分對信息傳播的結構特性進行實證研究,博文轉發樹提供了有關信息傳播的重要描述性信息,博文轉發樹的大小反映博文的受歡迎程度相關;博文轉發樹的深度與博文的穿透力相關;博文轉發樹的寬度與博文的擴散能力相關;博文轉發樹度的分布反映轉發樹中的關鍵節點,因為一棵博文轉發樹的度指的是轉發樹中節點度最大的節點的度。
H7N9數據集合中共包含22 364棵博文轉發樹(不考慮未被轉發的原創博文,也就是轉發次數為0的原創博文沒有考慮),每一棵轉發樹都可以被看作是一棵有向樹,信息從一個節點傳播到另一個節點。這里主要關注兩個問題:(1) 信息傳播過程的結構特性有哪些?(2) 信息的傳播過程是否具有階段依賴性,即信息的傳播在轉發樹的不同層次中是否會表現出不同的特征?我們發現,與文獻[6]中的寬度小、深度大的傳播樹型結構特征相比,H7N9博文轉發樹呈現出密度大、深度小的特征;另外信息的傳播過程不具有階段依賴性。
4.1博文轉發樹的結構特性
根據3.2節中對博文轉發樹的形式化定義,對博文轉發樹的大小、寬度、深度、度四項結構特征屬性進行了統計分析。
圖3-圖6分別顯示了博文轉發樹的大小、寬度、深度和度四項結構特征屬性的分布情況。

圖3 博文轉發樹大小分布 圖4 博文轉發樹寬度分布

圖5 博文轉發樹深度分布 圖6 博文轉發樹度分布
四項結構特征屬性的統計公式依次為(說明:|A|表示集合A中元素的數量):
(1)
(2)
(3)
(4)
其中,|TRTS|表示轉發樹集合的大小,對于任一點坐標(k,PTRT.size=k),其統計意義是(以式(1)為例):轉發樹大小為k的轉發樹在所有轉發樹中所占的比例。
對數據進行了線性擬合,線性擬合采用的冪律分布函數為:p(X=x)=c·x-γ,其中c,γ∈R+,x∈N+,置信度設為95%。
首先從四項特征屬性的分布情況可以看出其均具有長尾分布特征,這說明絕大多數的轉發樹的大小、寬度、深度、度都非常小,屬性值很大的轉發樹只占非常小的一部分。從圖3、圖4可以看出博文轉發樹的大小和寬度均服從冪律分布,冪律分布指數分別為1.447、1.507。冪律分布本身并沒有什么特別之處,但是這兩者的冪律指數很相似,這表明博文轉發樹的大小會隨著樹的寬度的變大而增大。可以將樹的寬度看做擴散系數,將樹的大小用來衡量博文的受歡迎程度,那么可知擴散系數會影響博文最終的受歡迎程度,圖7很好地表明了博文轉發樹的這一特點。從圖8可以看出博文轉發樹的深度與博文轉發樹的大小無關。博文轉發樹具有的另一個特點是深度很小,在22 364棵博文轉發樹中,有77%的博文轉發樹的深度都不超過2。結合這四項結構特征屬性分布可知,對于博文轉發樹集合中大小、寬度、度都很大的那一部分轉發樹來說,它們的深度很淺,這體現了博文轉發樹具有密度大的特點。大量的節點都聚集在樹的有限的幾個層次中,另外博文轉發樹深度小、密度大的特點也體現了微博平臺中信息傳播的有效性,即信息擴散到大量的節點后迅速消散衰減。

圖7 博文轉發樹的大小與寬度的關系圖8 博文轉發樹的大小與深度的關系
4.2信息傳播的階段無關特性
在4.1節中對基本結構特性研究的基礎上,本節研究信息傳播是否與傳播階段相關,也就是在不同的階段,信息傳播過程是否會表現出不同的特性。圖9展示了博文轉發樹不同層次的層次度(即Li_d,某一層中節點度最大的節點的度)分布。由于大多數的博文轉發樹的深度都很小,因此只給出了博文轉發樹第0層(根節點所在的層次)到第3層的度分布情況。

圖9 博文轉發樹的不同層次度分布
對于任一點坐標(k,P(k|level=i)),統計公式如下:
(5)
其中i∈{0,1,2,3},概率P(k|level=i)表示具有第i層且該層層次度為k的轉發樹在所有的轉發樹中所占的比例。第0層到第3層的冪律分布指數依次為1.531、1.403、1.487和1.484。從圖9中首先可以看出具有大量孩子的節點很少會出現在樹的深層次中;另外由不同層次的冪律分布指數可知,隨著樹的層次的加深,冪律指數的分布并沒有太大的變化,這與文獻[18]中所提到隨著樹的深度的增加冪律指數分布會變得更加“陡峭”的現象不同,體現了該數據集中的微博信息傳播在不同的階段的傳播機制不會有太大的變化。我們認為導致這種現象的原因一方面是不同的社交平臺的機制不同,另一方面是由于H7N9疫情具有突發性的特點,這一特征可以為微博平臺中信息傳播預測模型的設計提供有價值的參考。
5信息傳播仿真模型
微博空間信息傳播過程構成了博文轉發樹集合,博文轉發樹的結構特性表現為深度小、密度大。結合信息傳播的網絡結構特性和微博平臺信息傳播的特征,本部分構建一個基于Galton-Watson[19]分支過程的新的信息傳播模型對博文轉發樹的結構特性進行仿真。
5.1模型構建
Galton-Watson分支過程是概率論中生成隨機樹的一個經典模型,是隨機圖理論中的重要部分,它曾被成功地用來進行家族姓氏演變消亡過程的模擬[20]。家族姓氏演變消亡的過程與微博平臺信息傳播的過程具有很大的相似之處,一個家族中的男性控制著家族姓氏的演變消亡,而在微博平臺中信息的傳播依賴于轉發博文的用戶。因此選擇采用Galton-Watson過程來對微博信息傳播進行仿真。但微博平臺中的信息傳播與家族姓氏的演變存在一個關鍵的不同,在微博平臺中信息的傳播具有快速擴散、迅速消亡的特點,而家族姓氏演變消亡的過程則要慢得多。考慮到微博平臺信息傳播這一關鍵特性,在仿真模型中考慮在特定情況下結束信息擴散過程。
綜合以上考慮,構建如下信息傳播模型:
(1) 設P(m)是關于一系列獨立同分布的固定概率;
(2) 每一棵博文轉發樹TRT的形成起始于根節點,并以離散的步驟進行。在形成博文轉發樹的第i層時,第i層的每一個葉子節點按照概率P(m)獨立生成一定數量的孩子節點,即葉子節點具有m個孩子的概率為P(m);
(3) 當m=0時,N是一個葉子節點,當m>0時,將節點N加入到博文轉發樹的第i+1層;
(4) 引入一個信息傳播結束概率k,表示到達博文轉發樹第n層時信息結束傳播的概率,即博文轉發樹能夠到達第n層的概率pn如下:
pn=k(1-k)n-1
(6)
由以上定義的模型可知,該模型包含兩個參數:分布概率P和信息傳播結束概率k。對于分布概率P(m),使用最大似然估計法進行計算,設T(x)為該模型下生成博文轉發樹x的概率,f(m,x)為博文轉發樹x中具有m個孩子節點的節點數量,P(m)為博文轉發樹x中具有m個孩子節點的節點概率,則可得如下等式:
T(x)=∏mP(m)f(m,x)
(7)
由式(7)有如下對數似然函數:

(8)
根據最大似然估計法對P(m)求導得:
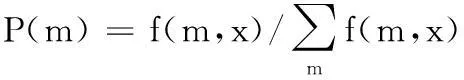
(9)
從式(9)可知P(m)等于博文轉發樹中具有m個孩子節點的節點比例。對于概率k,計算方法如下:將公式pn=k(1-k)n-1與博文轉發樹的深度分布進行擬合,擬合結果如圖10所示,得到k的值為0.46。

圖10 博文轉發深度擬合
5.2模型驗證
根據5.1節中對信息傳播模型的定義,本部分對模型進行驗證。量化后的參數P(m)如表2所示,由于不同的孩子節點數量值較多,此處只給出占比例較大的部分。參數k的值為0.46。

表2 參數P(m)
將量化后的參數代入傳播模型進行仿真,得到生成的博文轉發樹結構特性數據集合,共22 364棵博文轉發樹,仿真結果如圖11-圖13所示。

圖11 博文轉發樹大小分布仿真結果圖12 博文轉發樹寬度分布仿真結果
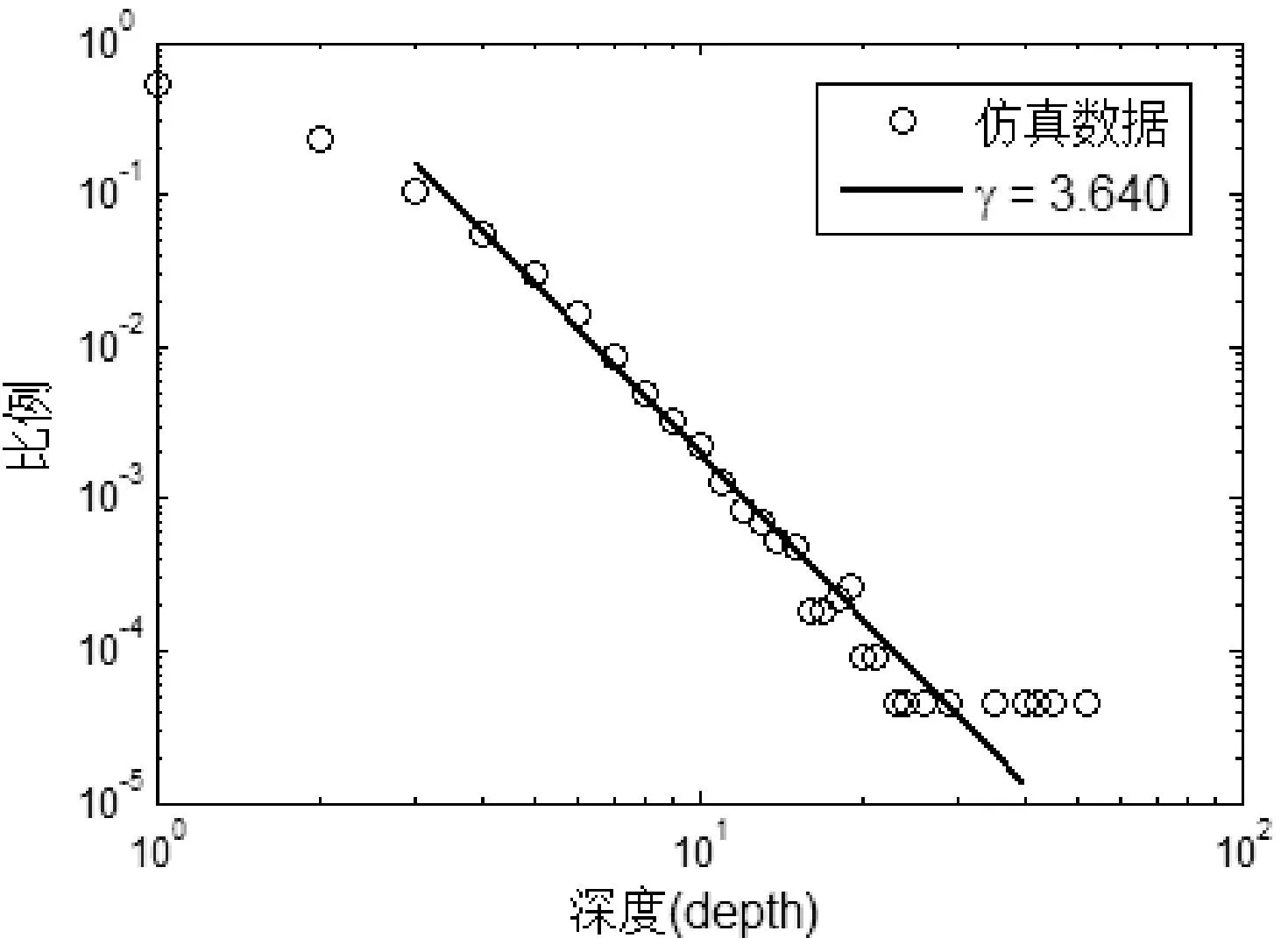
圖13 博文轉發樹深度分布仿真結果
仿真實驗采用的是Matlab工具,從圖11-圖13可以看出博文轉發樹的大小、寬度和深度分布均服從冪律分布,在這里采用與4.1節部分同樣的方法對數據進行了線性擬合。線性擬合采用的冪律分布函數為:p(X=x)=c·x-γ,其中c,γ∈R+,x∈N+,置信度設為95%。仿真得到的博文轉發樹大小、寬度和深度冪律指數依次為1.412、1.464和3.640,這與真實博文轉發樹中的冪律指數(實際博文轉發樹大小、寬度、深度冪律指數依次為1.447、1.507和3.976)分布較為吻合,這說明該傳播模型能較準確的模擬真實的信息傳播情況。
6結語
本文以2013年3月底中國大陸爆發的甲型H7N9流感疫情為主題背景,微博數據集合來源于新浪微博,利用博文之間的轉發關系,構造了每一條原創博文的博文轉發樹,分析了H7N9疫情期間新浪微博中信息傳播的結構特性。對博文轉發樹的四項結構特征屬性進行研究發現博文轉發樹具有密度大、深度小的結構特性,博文最終的流行程度受博文轉發樹寬度的影響,微博信息傳播在不同的傳播階段表現出了相似的傳播特性。根據真實數據集合表現出的結構特性,結合Galton-Watson分支過程構建了一種新的微博信息傳播模型,使用該模型進行仿真得到的結果較準確地反映了信息傳播的結構特性。這些發現能夠為微博平臺中信息傳播預測、輿情監控引導和應急事件響應提供有價值的信息。
參考文獻
[1] 新浪微博關鍵數據:月活躍用戶[EB/OL].http://tech.qq.com/a/20140315/004999.htm.
[2]ZhengbiaoGuo,ZhitangLi,HaoTu.SinaMicroblog:AnInformation-drivenOnlineSocialNetwork[C]//InternationalConferenceonCyberworlds,2011:160-167.
[3]DongWang,HosungPark,GaogangXie,etal.AGenealogyofInformationSpreadingonMicroblogs:aGalton-Watson-basedExplicativeModel[C]//ProceedingsofIEEEINFOCOM,2013:2391-2399.
[4]EytanBakshy,ItamarRosenn,CameronMarlow,etal.TheRoleofSocialNetworksinInformationDiffusion[C]//Proceedingsofthe21stInternationalConferenceonWorldWideWeb,2012:519-528.
[5]PengyiFan,PeiLi,ZhihongJiang,etal.MeasurementandAnalysisofTopologyandInformationPropagationonSina-Microblog[C]//IEEEInternationalConferenceonIntelligenceandSecurityInformatics,2011:396-401.
[6]DavidLiben-Nowell,JonKleinberg.TracinginformationflowonaglobalscaleusingInternetchain-letterdata[J].ProceedingsoftheNationalAcademyofSciencesoftheUnitedStatesofAmerica,2008,105(12):4633-4638.
[7]KristinaLerman,RumiGhosh.InformationContagion:AnEmpiricalStudyoftheSpreadofNewsonDiggandTwitterSocialNetworks[C]//ProceedingsoftheFourthInternationalAAAIConferenceonWeblogsandSocialMedia,2010:90-97.
[8]BongwonSuh,LichanHong,PeterPirolli,etal.WanttobeRetweeted?LargeScaleAnalyticsonFactorsImpactingRetweetinTwitterNetwork[C]//IEEESecondInternationalConferenceonSocialComputing,2010:177-184.
[9]StefanStieglitz,LinhDangxuan.PoliticalCommunicationandInfluencethroughMicroblogging-AnEmpiricalAnalysisofSentimentinTwitterMessagesandRetweetBehavior[C]//Proceedingsofthe45ndHawaiiInternationalConferenceonSystemSciences,2012:3500-3509.
[10]KateStarbird,LeysiaPalen.(How)WilltheRevolutionbeRetweeted?InformationDiffusionandthe2011EgyptianUprising[C]//ProceedingsoftheACM2012conferenceonComputerSupportedCooperativeWork,2012:7-16.
[11]JessicaLi,ArunVishwanath,HRaghavRao.RetweetingthefukushimanuclearRadiationDisaster[J].CommunicationsoftheACM,2014,57(1):78-85.
[12]YanQu,PhilipFeiWu,XiaoqingWang.OnlineCommunityResponsetoMajorDisaster:AStudyofTianyaForuminthe2008SichuanEarthquake[C]//Proceedingsofthe42ndHawaiiInternationalConferenceonSystemSciences,2009:1-11.
[13]YanQu,ChenHuang,PengyiZhang,etal.MicrobloggingafteraMajorDisasterinChina:ACaseStudyofthe2010YushuEarthquake[C]//ProceedingsoftheACM2011conferenceonComputersupportedcooperativework,2011:25-34.
[14]MarceloMendoza,BarbaraPoblete,CarlosCastillo.TwitterUnderCrisis:CanwetrustwhatweRT?[C]//ProceedingsoftheFirstWorkshoponSocialMediaAnalytics,2010:71-79.
[15]WojciechGaluba,KarlAberer,DipanjanChakraborty,ZoranDespotovic,WolfgangKellerer.OuttweetingtheTwitterers-PredictingInformationCascadesinMicroblogs[C]//Proceedingsof3rdWorkshoponOnlineSocialNetworks,2010:1-9.
[16]JaewonYang,JureLeskovec.ModelingInformationDiffusioninImplicitNetworks[C]//IEEEInternationalConferenceonDataMining,2010:599-608.
[17]MeeyoungCha,AlanMislove,KrishnaPGummadi.Ameasurement-drivenanalysisofinformationpropagationintheflickrsocialnetwork[C]//Proceedingsofthe18thinternationalconferenceonWorldwideweb,2009:721-730.
[18]RaviKumar,MohammadMahdian,MaryMcGlohon.DynamicsofConversations[C]//Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,2010:553-556.
[19]GaltonF,WatsonHW.Ontheprobabilityoftheextinctionoffamilies[J].InMendelianHeredity,AnnalofMathematicalStatistics,1944,4:385.
[20]WilliamJReed,BarryDHughes.Onthedistributionoffamilynames[J].PhysicaAStatisticalMechanicsanditsApplications,2003,319(7):579-590.
STUDY ON CHARACTERISTICS OF MICROBLOGGING INFORMATIONDISSEMINATIONUNDERH7N9FLUBACKGROUND
Liu BaoliDong RongshengCai Guoyong
(Guangxi Key Laboratory of Trusted Software,Guilin University of Electronic Technology,Guilin 541004,Guangxi,China)
AbstractWe researched and developed the microblogging crawler system—WeiboCrawler independently. Aiming at the type A H7N9 flu epidemic broken out in March 2013, by using this system we captured the dataset correlated with this topic from Sina microblogging, including user information, original and forwarded microblogs information. Taking the original microblog as the root node, we constructed the microblogs forwarding tree (MFT) with recursion method based on forwarding relationship. To describe the process of information dissemination clearly and strictly, we gave the formal definition on the microblogs forwarding tree, and then studied the microblogging information dissemination process and the structural characteristics of MFT in size, depth and width, etc. Result showed that the distribution of MFT structural characteristics is in line with long-tailed distribution, the MFT has the characteristics of small depth and large density, the popularity of microblogs depends on the width of the MFT but has nothing to do with the depth of MFT. At different stages of microblogs forwarding, the information disseminations show similar characteristics. Considering the characteristics of information dissemination on microblogging platform and the structural characteristic of MFT, and combining the Galton-Watson branching process, we presented a new information flow dissemination model and simulated the three structural characteristics of MFT in size, depth and width with the model, we found that this model can quite accurately reflect the structural characteristics of information dissemination.
KeywordsForwardingInformation disseminationStructural characteristicsSocial networksDissemination model
收稿日期:2014-12-04。廣西自然科學基金項目(2011GXNSFA01 8156);廣西高等學校高水平創新團隊及卓越學者計劃;桂林電子科技大學創新團隊項目。劉寶立,碩士生,主研領域:社會計算,數據挖掘,形式化技術。董榮勝,教授。蔡國永,教授。
中圖分類號TP391
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.06.075
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中華詩詞(2019年7期)2019-11-25 01:43:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
