基于保留部分頻域鏡像分量的聲源定位算法
2016-07-19 02:14:40蔡衛平劉瑞娟
計算機應用與軟件 2016年6期
關鍵詞:信號
蔡衛平 劉瑞娟 周 琳
1(九江職業技術學院電氣工程學院 江西 九江 332007)2(東南大學信息科學與工程學院 江蘇 南京 210096)
?
基于保留部分頻域鏡像分量的聲源定位算法
蔡衛平1劉瑞娟1周琳2
1(九江職業技術學院電氣工程學院江西 九江 332007)2(東南大學信息科學與工程學院江蘇 南京 210096)
摘要針對傳統的SRP-PHAT(Steered Response Power with Phase Transform)聲源定位算法容易受噪聲影響而導致定位性能降低的問題,提出一種頻域補零且保留部分鏡像分量的改進算法。該算法首先通過傅里葉變換將接收信號變換到頻域,然后在高頻端補零至20倍幀長,同時保留部分鏡像分量。在此基礎上計算麥克風對接收信號的互功率譜密度函數,作傅里葉逆變換得到相位變換加權的廣義互相關(GCC-PHAT)函數。保留的鏡像分量拓寬了信號頻域,使GCC-PHAT函數的峰更為尖銳,累加后得到的SRP-PHAT函數的空間譜峰也就更加尖銳,從而提高定位性能。實驗表明,相比于傳統算法,改進算法能顯著提高定位成功率。
關鍵詞相位變換聲源定位鏡像分量
0引言
由于噪聲和混響的影響,在真實環境中實現較高精度的聲源定位仍然是比較困難的,尤其是小型陣列,受陣列孔徑及陣元個數的限制,定位精度較低。在已有的聲源定位算法中,以多重信號分類MUSIC(MultipleSignalClassification)算法[5]為代表的高分辨率譜估計算法理論上可以達到很高的精度,但是該算法不能處理高度相關的信號,混響將使得定位性能急劇下降。文獻[6]提出導引響應功率SRP-PHAT聲源定位算法。該算法的定位原理是根據接收信號計算假想聲源位置處的導引響應功率,使其取最大值的點即為聲源位置估計。SRP-PHAT算法在混響環境中具有較強的魯棒性,但是計算復雜度較高,為提高算法的實時性,研究人員提出了多種減少其計算量的方法[7-9]。SRP-PHAT算法在低信噪比、強混響條件下的定位性能仍然較低,對此,研究人員也提出了多種改進方法。文獻[10]提出了最大似然定位算法,該算法在低信噪比、弱混響條件下能較大幅度提高定位性能,而在高信噪比或強混響條件下定位性能與SRP-PHAT接近。針對分布式陣列的特點,文獻[11]提出加權SRP-PHAT算法,利用各陣元接收信號質量的不同,對于信號質量較好的陣元賦予較大權重,從而提高定位性能。文獻[12]則提出了更為簡單的加權算法。文獻[11,12]的算法只能用于分布式陣列,小型陣列中,各陣元接收信號質量幾乎沒有差別,加權算法不能提高定位性能。文獻[13]提出了基于歸一化算術平均的寬帶SRP算法,該算法改善了噪聲環境下的定位性能,但不適用于有混響的室內環境。
SRP-PHAT函數可表達成所有麥克風對的廣義互相關GCC-PHAT(GeneralizedCrossCorrelationwithPhaseTransform)函數之和[6]。由于采用了相位變換PHAT(PhaseTransform)加權,GCC-PHAT函數應該有尖銳的峰,從而SRP-PHAT函數有尖銳的空間譜峰,但是由于噪聲,實際的空間譜峰變得較寬,又由于反射聲的存在,其產生的虛假譜峰與直達聲的譜峰相互疊加,使得SRP-PHAT函數的最大值所在位置偏離了真實聲源的位置,導致定位誤差。根據上述分析,本文提出一種改進的SRP-PHAT算法。該算法將麥克風對接收信號的互功率譜拓寬,使得其相應的互相關函數更加尖銳,累加后得到SRP-PHAT函數的空間譜峰也就更加尖銳,從而提高定位精度。
1信號模型
假設麥克風陣列的陣元個數為M,用s(n)表示聲源信號,則在真實環境中,第m個陣元的接收信號為:
xm(n)=hm(n)*s(n)+bm(n)
(1)
其中hm(n)為聲源到第m個陣元的房間沖擊響應,“*”表示線性卷積,bm(n)表示第m個陣元的背景噪聲。式(1)中的卷積運算表征了陣元接收信號中既有聲源信號的直達聲也有多次反射聲。假設聲源信號與噪聲不相關,各通道的背景噪聲也不相關。
2SRP-PHAT算法
2.1SRP-PHAT的原理
如前文所述,SRP-PHAT函數可表達成所有麥克風對的GCC-PHAT函數之和,即:
(2)
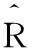
(3)
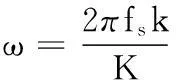
ζ=[cosφcosθ, cosφsinθ, sinφ]T
(4)
用rm=[x,y,z]T表示第m個麥克風的直角坐標矢量,c表示空氣中的聲速(約為342m/s),則:
(5)
聲源位置估計為:
(6)
其中Q為聲源空間。
2.2SRP-PHAT的實現
竹林機械化經營是一個全新的課題,不僅要有理念上的轉變,也要有模式和方法的創新。目前,雖然對上述3種模式進行了初步的探索與實踐,但由于試驗時間較短,樣地面積和規模都較小,其成果應用仍有許多局限性。為此,需要業界朋友集思廣益,群策群力,以期早日形成具有共性的機械化經營模式,為竹產業的振興和可持續發展做出新貢獻。
(7)
3改進的SRP-PHAT算法
如前文所述,由于噪聲和混響的影響,SRP-PHAT函數的空間譜峰變寬,容易相互疊加,導致聲源位置估計誤差。眾所周知,互相關函數與互功率譜是一對傅里葉變換,令:
(8)
(9)

(10)
(11)
相應的真實聲源位置估計為:
(12)
4實驗與分析
4.1實驗環境
為了比較改進算法與原算法的性能,我們利用在真實環境中錄制的數據庫AV16.3[16]來做聲源定位實驗。AV16.3是在會議室中錄制的,包括多種情景,專門供聲源定位研究人員使用。本實驗取單個靜止聲源的一組數據,編號為“seq01_1p_0000”,錄制場景如圖1所示。

圖1 說話人區域與麥克風陣列的位置
圖1中的陰影部分為聲源所在區域,說話人分別在16個位置說一段話。麥克風陣列為具有八個陣元的均勻圓陣,半徑為0.1m,放置于會議桌上。由于陣列孔徑較小,滿足遠場條件,即只估計聲源的到達方向角DOA(DirectionofArrival),麥克風陣列與DOA矢量的關系如圖2所示。

圖2 麥克風陣列與DOA矢量
圖2中,坐標原點位于陣列圓心,xoy平面就是陣列所在平面,小黑點表示麥克風,DOA矢量由坐標原點指向聲源,其單位矢量就是式(4)所描述的ζ。說話人為男性,說英語,信號采樣頻率fs=16kHz。信號幀長512點(32ms),幀重疊率50%,加漢寧(Hanning)窗,去掉靜音間隙后,總計有5646幀信號用于聲源定位實驗。水平角θ的搜索范圍為-180°~180°,仰角φ的搜索范圍為0°~90°,步長均為1°。
4.2性能評價準則
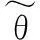
(13)
(14)
(15)
4.3實驗結果
我們用傳統的SRP-PHAT算法和本文提出的改進算法處理前文描述的真實數據。為便于描述,改進算法記為SRP-PHAT-PZ。IDIAP提供了實現傳統SRP-PHAT算法的MATLAB程序,其實現方法如2.2節所述,可直接使用該程序得到傳統算法的實驗結果。我們修改IDIAP的程序實現改進算法。IDIAP的程序中,設置L=20,為便于比較,本文仍然采用該參數值。對于水平角,γ取1°~180°,對于仰角,γ取1°~90°,步長均為1°。兩種算法的定位成功率如圖3所示。
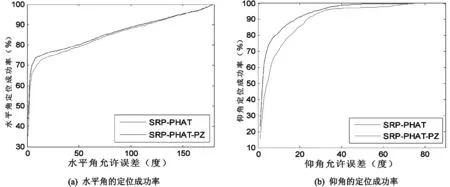
圖3 兩種算法的定位成功率比較
由圖3可見,在不同的允許誤差下,改進算法的定位成功率都比傳統算法的要高,其中仰角的定位成功率提高幅度更大。比較實用的允許誤差角度通常為幾度到十幾度[10],表1給出了幾種典型的允許誤差角度下,兩種算法定位成功率的具體數據。
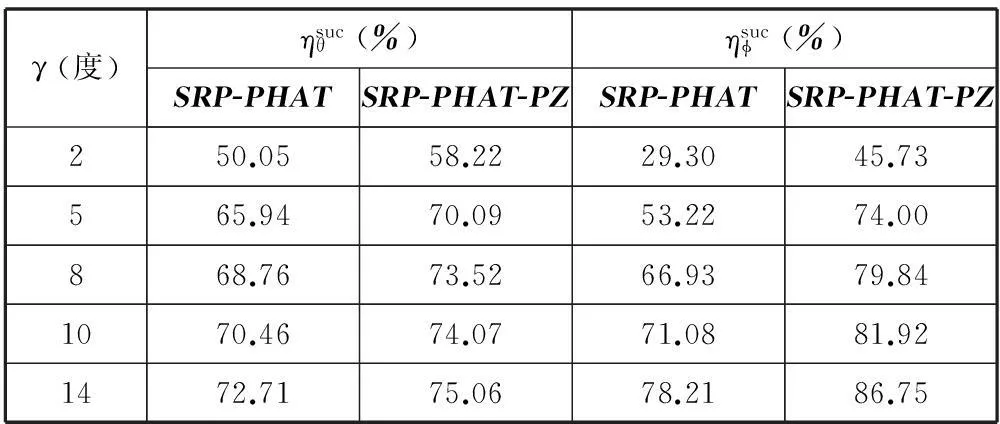
表1 在典型的允許誤差角度下,兩種算法的定位成功率比較
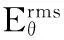

表2 在典型的允許誤差角度下,兩種算法的均方根誤差比較
5結語
SRP-PHAT算法能實現真實環境中的聲源定位,但是在信噪比較低、混響較強的環境中,其定位性能仍然不高。本文提出一種保留部分頻域鏡像分量的改進算法。采用在信號高頻端補零的方法來提高時域采樣率,在此過程中保留了部分頻域鏡像分量,從而拓寬了互功率譜的頻帶寬度,使得互相關函數的峰更加尖銳。SRP-PHAT函數可表示為所有麥克風對接收信號的GCC-PHAT函數之和,更為尖銳的GCC-PHAT函數使得SRP-PHAT函數中真實聲源對應的空間譜峰與反射聲對應的譜峰不容易重疊,避免譜峰位置偏移。實驗表明,本文提出的算法比傳統算法的定位成功率有較大幅度提高,同時減小了估計的均方根誤差。
參考文獻
[1]FaubelF,GeorgesM,KumataniK,etal.Improvinghands-freespeechrecognitionincarthroughaudio-visualvoiceactivitydetection[C]//ProceedingofJointWorkshoponHands-freeSpeechCommunicationandMicrophoneArrays.Edinburgh,UK:IEEE,2011:70-75.
[2]SunL,ChengQ.Real-timemicrophonearrayprocessingforsoundsourceseparationandlocalization[C]//ProceedingofIEEE47thAnnualConferenceonInformationSciencesandSystems(CISS).Baltimore,MD,USA:IEEE,2013:1-6.
[3]TourbabinV,RafaelyB.Theoreticalframeworkforthedesignofmicrophonearraysforrobotaudition[C]//ProceedingofIEEEInternationalConferenceonAcoustics,Speech,andSignalProcessing(ICASSP).Vancouver,Canada:IEEE,2013:4290-4294.
[4]SeewaldLA,JrLG,VeronezMR,etal.CombiningSRP-PHATandtwoKinectsfor3Dsoundsourcelocalization[J].ExpertSystemswithApplications,2014,41(16):7106-7113.
[5]DmochowskiJP,BenestyJ,AffesS.BroadbandMUSIC:opportunitiesandchallengesformultiplesourcelocalization[C]//IEEEWorkshoponApplicationsofSignalProcessingtoAudioandAcoustics.NewPaltz,NY,USA:IEEE,2007:18-21.
[6]DibiaseJH.Ahigh-accuracy,low-latencytechniquefortalkerlocalizationinreverberantenvironmentsusingmicrophonearrays[D].Providence:DivisionofEngineeringatBrownUniversity,2000.
[7]ZhaoY,ChenX,WangB.Real-timesoundsourcelocalizationusinghybridframework[J].AppliedAcoustics,2013,74(12):1367-1373.
[8]OualilY,FaubelF,KlakowD.Afastcumulativesteeredresponsepowerformultiplespeakerdetectionandlocalization[C]//ProceedingofEuropeanSignalProcessingConference(EUSIPCO).Marrakech,Morocco:IEEE,2013:1-5.
[9]NunesLO,MartinsWA,LimaMVS,etal.ASteered-responsepoweralgorithmemployinghierarchicalsearchforacousticsourcelocalizationusingmicrophonearrays[J].IEEETransactionsonSignalProcessing,2014,62(19):5171-5183.
[10]ZhangC,FlorencioD,BaDE,etal.Maximumlikelihoodsoundsourcelocalizationandbeamformingfordirectionalmicrophonearraysindistributedmeetings[J].IEEETransactionsonmultimedia,2008,10(3):538-548.
[11]MungamuruB,AarabiP.Enhancedsoundlocalization[J].IEEETransactionsonSystems,Man,andCybernetics-partB:Cybernetics,2004,34(3):1526-1540.
[12] 蔡衛平,黃印君,陸澤櫞.基于分布式麥克風陣列的聲源定位算法[J].計算機應用與軟件,2014,31(5):132-135.
[13]SalvatiD,DrioliC,ForestiGL.Incoherentfrequencyfusionforbroadbandsteeredresponsepoweralgorithmsinnoisyenvironments[J].IEEESignalProcessingLetters,2014,21(5):581-585.
[14]KnappCH,CarterGC.Thegeneralizedcorrelationmethodforestimationoftimedelay[J].IEEETransactionsonAcoustics,Speech,andSignalProcessing,1976,24(4):320-327.
[15]DmochowskiJP,BenestyJ,AffesS.Ageneralizedsteeredresponsepowermethodforcomputationallyviablesourcelocalization[J].IEEETransactionsonAudio,Speech,andLanguageProcessing,2007,15(8):2510-2526.
[16]LathoudG,OdobezJM,Gatica-perezD.AV16.3:anaudio-visualcorpusforspeakerlocalizationandtracking[R].Martigny:IDIAPResearchInstitute,2004.
SOUND SOURCE LOCALISATION ALGORITHM BASED ON RETAINING PARTIALMIRRORCOMPONENTSINFREQUENCYDOMAIN
Cai Weiping1Liu Ruijuan1Zhou Lin2
1(School of Electrical Engineering,Jiujiang Vocational and Technical College,Jiujiang 332007,Jiangxi,China)2(School of Information Science and Engineering,Southeast University,Nanjing 210096,Jiangsu,China)
AbstractTo deal with the problem of the sound source localisation algorithm of traditional steered response power with phase transform weighting (SRP-PHAT) that its localisation performance is easily degraded due to noise influence, in this paper we propose an improved algorithm which pads the zeros in frequency domain and retains partial mirror components as well. First, the algorithm transforms the received signals to frequency domain through fast Fourier transform (FFT), and then pads the zeros to reach 20 times of the frame length in high-frequency band while preserving part of the mirror components. On this basis, the cross power spectral density function of the microphone pair on received signals can be estimated, and the corresponding generalised cross correlation with phase transform weighting (GCC-PHAT) function can be obtained by taking inverse fast Fourier transform (IFFT). The retained mirror components broaden the signal spectrum so that the peak of GCC-PHAT function becomes sharper. Consequently, the spatial spectrum peak of SRP-PHAT function, which is the accumulation of GCC-PHAT functions for all of the microphone pairs, becomes sharper, thus the localisation performance is improved. Experiments show that compared with conventional algorithms, the proposed algorithm can considerably enhance the success rates of sound source localisation.
KeywordsPhase transformSound source localisationMirror components
收稿日期:2015-01-18。國家自然科學基金青年基金項目(61201 345)。蔡衛平,副教授,主研領域:陣列信號處理。劉瑞娟,講師。周琳,副教授。
中圖分類號TP391.4
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.06.077
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
