一種基于深度神經網絡的話者確認方法
2016-07-19 02:07:22吳明輝胡群威
計算機應用與軟件 2016年6期
吳明輝 胡群威 李 輝
(中國科學技術大學電子科學與技術系 安徽 合肥 230027)
?
一種基于深度神經網絡的話者確認方法
吳明輝胡群威李輝
(中國科學技術大學電子科學與技術系安徽 合肥 230027)
摘要主要研究基于深度神經網絡的話者確認方法。在訓練階段,以語音倒譜特征參數作為輸入,說話人標簽作為輸出有監督的訓練DNN;在話者注冊階段,從已訓練的DNN最后一個隱藏層抽取與說話人相關的特征矢量,稱為d-vector,作為話者模型;在測試階段,從測試語音中抽取其d-vector與注冊的話者模型相比較然后做出判決。實驗結果表明,基于DNN的話者確認方法是可行的,并且在噪聲環境及低的錯誤拒絕率的條件下,基于DNN的話者確認系統性能比i-vector基線系統性能更優。最后,將兩個系統進行融合,融合后的系統相對于i-vector基線系統在干凈語音和噪聲語音條件下等誤識率(EER)分別下降了13%和27%。
關鍵詞話者確認深度神經網絡深度學習
0引言
隨著語音相關技術的發展和成熟,在日常生活中語音的應用越來越廣泛,而語音作為證據在安全方面的應用也日益重要,使得對話者確認技術SV(SpeakerVerification)的需求越來越迫切。話者確認的任務是通過測試給定語音波形信號中包含的說話人個性信息,從而對其聲明的身份進行判決。根據是否限定說話的內容,話者確認分為與文本有關和與文本無關兩種類型。與文本有關的話者確認要求測試語音的內容要與注冊語音的內容相同,所以只能用于某些特殊的領域;而與文本無關的話者確認不要求測試語音和注冊語音的內容相同,所以應用范圍更廣,在本文中主要研究與文本無關的話者確認方法。
一般的話者確認系統可以分為以下三個階段:
(1) 訓練階段:通過大量的語音數據訓練得到通用的背景模型。背景模型的類型有很多種,目前應用較廣的主要是基于高斯混合模型GMM(GaussianMixtureModel)的通用背景模型UBM[1],還有基于聯合因子分析JFA(JointFactorAnalysis)的通用模型[2-4]。
(2) 注冊階段:根據目標說話人的語音數據,結合通用背景模型,獲得與目標說話人相關的話者模型,一般要求目標說話人的語音數據和通用背景模型的訓練語音數據不重疊。
(3) 測試階段:將測試語音經過話者模型和通用背景模型輸出評分,然后與設定的閾值比較,做出判決。
在上述三個階段采用不同的方法,已經產生了很多不同的話者確認系統。目前,主流的話者確認系統是采用i-vector和PLDA結合的方法[5],在這個系統中,主要是利用JFA作為特征提取器,從語音倒譜特征中提取一個與說話人相關的低維向量i-vector,然后通過PLDA進行后續的處理,輸出評分。
近年來,深度神經網絡DNN以其強大的特征表示能力,成功應用于語音識別領域[6]。本文提出在話者確認系統中利用DNN作為特征提取器,通過構建語音倒譜特征到說話人的一個映射,從而建立通用背景模型。在注冊階段,通過注冊語音訓練DNN,然后抽取DNN最后一個隱藏層的輸出,將其定義為d-vector;在測試階段,與基于i-vector的話者確認系統相同,根據目標說話人的d-vector和測試語音的d-vector之間的距離做出判決,接受或拒絕。
為了驗證本文方法的有效性,參考了美國國家標準技術署BIST(NationalInstituteofStandardandTechnology)評測[7]的部分要求,采用等誤識率EER(EqualErrorRate)和DET(DetectionErrorTrade-off)曲線作為評價標準,對NIST語料庫進行測試,實驗表明本文構建的系統取得了較好的性能。
1相關背景介紹
基于i-vector和PLDA的話者確認系統是目前與文本無關話者確認系統中的主流系統。i-vector可以看作是語音倒譜特征在全局差異空間(TotalVariabilitySpace)的一個低維表示,其中包含了大部分的說話人個性信息和少量其他信息。對于一個給定的語音信號,定義均值超矢量如下:
M=m+Tω
(1)
其中m是一個與說話人無關的均值超矢量,通常采用UBM的均值超矢量代替,T是一個低秩矩陣,稱為全局差異矩陣TVM(TotalVariabilityMatrix),ω是一個服從標準正態分布的向量,稱為i-vector。在獲得i-vector以后,再進行PLDA操作,這個和JFA的原理相同,都是進一步將語音中包含的說話人個性信息和通道信息區分開,從而獲得更好的識別效果[8,9]。
在過去的研究中,已經嘗試過將神經網絡用于話者確認系統中,因為神經網絡具有很好的非線性分類能力,所以能夠對語音信號中包含的說話人個性信息進行鑒別。其中自聯想神經網絡AANN(AutoAssociativeNeuralNetwork)[10]采用目標說話人AANN網絡輸出和背景模型UBM-AANN輸出之間的誤差進行網絡重構,被用于話者確認系統中;帶有bottleneck層的多層感知機MLP(Multi-layerperceptions)也曾被用于話者確認系統中[11]。最近,已經有研究將深度神經網絡用于話者確認系統中,如基于卷積神經網絡和玻爾茲曼機的話者確認系統[12,13]。
2基于DNN的話者確認系統
本文提出基于DNN的話者確認系統模型如圖1所示。DNN用于提取語音倒譜特征MFCC中與說話人相關的特征參數,這個方法與文獻[12]類似,但主要的不同是本文采用有監督的訓練方法,并且用DNN代替卷積神經網絡。
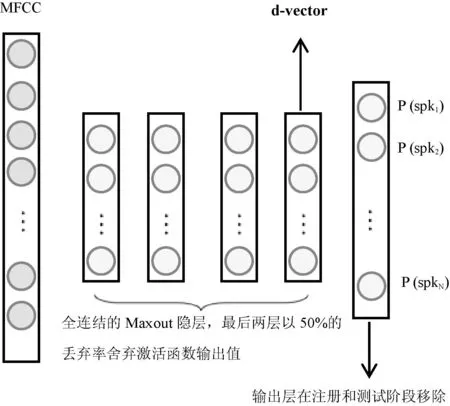
圖1 基于DNN的話者確認系統背景模型
2.1DNN作為特征提取器
本文所提出方法的核心思想就是將DNN用作特征提取器,在i-vector基線系統中采用DNN代替JFA作為背景模型,從語音倒譜特征中提取一個與說話人相關的特征向量[14]。
基于這樣的思想,首先在語音倒譜特征上構建有監督的DNN系統,用于區分訓練集中不同說話人的語音信號。這個背景神經網絡的輸入采用擴展的40幀語音MFCC參數,就是將原始的語音MFCC特征參數進行左右擴展;另外對訓練集中的N個說話人采用一個N維向量進行編號。其中對應說話人維度的值為1,其他維度的值都為0,這些編號稱為說話人的身份標簽,DNN系統的輸出對應為這些標簽,圖1為DNN的拓撲結構圖。
當訓練完DNN以后,使用其最后一個隱藏層輸出作為對說話人信息的一種表示,也就是說,先獲得語音的MFCC參數。然后將這些特征參數輸入到DNN中,用前向傳播算法求出最后一個隱藏層的輸出,即為對說話人的一個新的表示,稱這個輸出為d-vector。選用DNN的最后一個隱藏層作為輸出而不是選用softmax分類器作為輸出的原因有兩個:首先,這樣做可以減小神經網絡的規模,通過舍棄DNN的輸出層,可以在增加訓練數據集時,而不用增加網絡的規模;其次,通過后面的實驗發現這樣提取的特征用于話者確認的性能更好。
2.2注冊和測試
當給定說話人s的一個語料集Xs={Os1,Os2,…,Osn},其中每一條語音可以表示為多幀的特征向量Osi={o1,o2,…,om}。注冊過程描述如下:首先,使用說話人s的每一條語音Osi中的特征向量oj和他的身份標簽去有監督的訓練DNN,將DNN最后一個隱藏層輸出稱為與Osi有關的d-vector;然后,將所有的這些d-vector進行平均處理得到最后的d-vector,稱為與說話人s相關的d-vector。
在測試過程中,首先抽取測試語音的d-vector,然后計算測試語音d-vector和注冊語音的d-vector之間的余弦距離,將這個值與事前設定的閾值作比較進行判決。
2.3DNN的訓練過程
本文采用帶有dropout策略的最大輸出(Maxout)DNN[15,16]作為背景模型。在訓練樣本集較小時,dropout策略可以很好的預防DNN過擬合[16],dropout策略就是在訓練的過程中隨機丟棄一些隱藏層節點的輸出。MaxoutDNN是對dropout策略一種很好的實現,MaxoutDNN不同于標準的MLP,其將每一層輸出分為不重疊的兩組,每一組通過最大化輸出的策略選擇單個激活函數的值作為輸出。在本文中,訓練一個帶有4個隱藏層的DNN,每個隱藏層包含512個節點。前兩層不使用dropout策略,后兩層以50%的概率丟棄激活函數輸出進行DNN的訓練,如圖1所示。使用sigmoid函數作為每一個非線性神經元的激活函數,學習率為0.001。DNN的輸入采用堆疊的40幀的語音MFCC參數,即向左擴展20幀,向右擴展20幀組成的超幀參數,目標向量的維度為800,與訓練集中話者的人數相同。最終的DNN大約有2MB左右的參數,這和最小的i-vector基線系統類似。
3實驗與分析
3.1實驗數據庫
實驗數據來自美國國家標準技術署NIST(NationalInstituteofStandardandTechnology)舉辦的全球說話人評測比賽中的語音數據[7]。NIST語料庫覆蓋了多種傳輸信道情況和話筒類型。以NIST10語料庫為例,其根據語料數據的不同,分成5種訓練條件和4種測試條件,將不同的訓練條件和測試條件組合即可作為不同的測試任務。其中一個組合作為核心任務,所有評測的參賽者都必須要完成核心任務,由于NIST語料庫數據量龐大,本實驗從NIST10語料庫中選擇1000個說話人語料作為測試子集。其中800個說話人語音用作背景模型的訓練,200個說話人語音用作注冊和測試,每個說話人包含30條語音,每條語音的長度大約為3min(VAD后大約2min)。從800個說話人中每人選出10條用作背景模型的訓練,注冊和測試時,每個說話人的前20條語音用作注冊,剩下的用作確認測試。從其他199個人中每人選出10條作為冒認測試,一共進行400 000次測試。
3.2基線系統
在本文中,主要目的是保持模型在較小的規模下仍能夠完成比較好的效果。基線系統采用基于i-vector的話者確認系統,GMM-UBM采用13維的MFCC參數及其一階差分和二階差分進行訓練。使用EER作為評判標準,測試采用不同混合度的UBM和不同的i-vector維度以及不同LDA之后的維度對系統性能的影響,從而評估i-vector系統在什么樣的模型大小下性能最好。其中TVM采用PCA進行初始化,迭代10次,UBM采用6次迭代。
如表1所示,基于i-vector的話者確認系統隨著系統規模的下降,性能也會有所下降,同樣可以看出,在進行了t-norm[17]規整后的性能會明顯優于不進行規整的原始輸出評分。其中最小的i-vector系統包含2M左右的參數,和本文的系統規模類似。
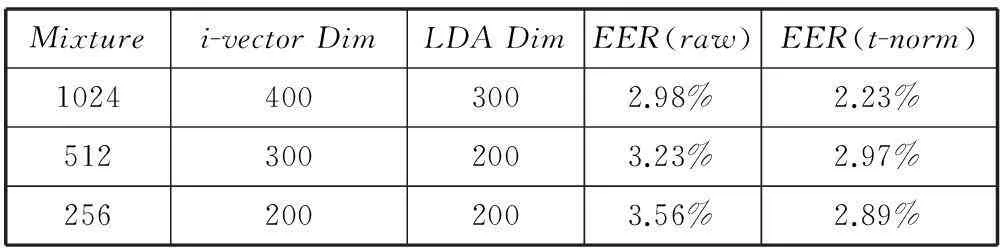
表1 不同參數配置下i-vector系統的性能對比
3.3基于DNN的話者確認系統
如圖2所示,是基于i-vector的基線系統和基于d-vector的話者確認系統的性能比較。通過觀察DET曲線發現在d-vector系統中,未經規整的原始輸出評分要比經過t-norm規整后的評分效果好。而i-vector系統中依然是t-norm之后的評分優于未經規整的評分,這可能是因為經過d-vector系統輸出的評分并不是服從正太分布而是服從重尾分布。因此在以后的工作中需要對d-vector系統輸出評分采用新的評分規整策略。在接下來的實驗中,基于d-vector的實驗都采用原始的評分作為輸出。

圖2 比較t-norm評分規整對兩個系統的影響
從DET曲線中可以看出經過t-norm規整后的i-vector系統的EER為2.84%,而未經規整的d-vector系統EER為4.55%。所以基于i-vector的系統性能要優于d-vector系統,然而在低的錯誤拒絕率時,如圖2右下角所示,基于d-vector系統的性能優于i-vector系統。
同樣也實驗了采用不同的參數配置去訓練DNN,發現不使用dropout策略,EER會上升3%左右。通過增加隱藏層的數量到1024,對于整個系統的性能沒有提高,但當減少隱藏層的節點數目到256時,系統的EER上升到了8%。
3.4注冊數據的影響
在d-vector系統中,在注冊階段沒有統計說話人語料數目對整個系統性能的影響,在這個實驗主要研究每個說話人選用不同數目的語料對基于i-vector的基線系統和基于d-vector的話者確認系統的影響。在注冊階段每個說話人分別選用4、8、12、20條語音進行比較。
通過分析表2中各個情況下的EER,在兩個系統的性能都是隨著注冊語音數目的增加而提高,并且趨勢相同。

表2 不同的注冊語音數目對系統的影響
3.5噪聲魯棒性
在實際的應用中往往訓練階段和實際測試階段環境不匹配,在這個實驗中,主要測試在噪聲環境下,兩個系統性能的比較。背景模型都是在干凈語音下訓練得到,但是在注冊語音和測試語音中都加入了10dB的白噪聲,兩個系統的DET曲線如圖3所示。從圖可以看出,在噪聲情況下,兩個系統的性能都有所下降。但是基于d-vector的系統的性能在噪聲情況下性能下降的幅度較小,并且在低的錯誤拒絕率的條件下基于d-vector的話者確認系統的性能要優于基于i-vector的基線系統的性能。

圖3 比較采用干凈語音和帶噪聲的語音對兩個系統的影響
3.6系統融合
通過上面與i-vector基線系統的比較發現,本文提出的基于d-vector的話者確認系統是可行的,尤其適合于噪聲環境和在要求低的錯誤拒絕率的條件下。然后我們將這兩種系統進行融合,稱為i/d-vector系統。一般融合的策略有很多種,本文只是簡單地將兩個系統的輸出評分進行平均,如圖4和圖5中fusion所示,并且在兩個系統中都采用t-norm進行規整。通過分析圖4和圖5可知,融合后的系統i/d-vector在干凈語音及帶噪聲條件下都優于單個系統的性能,就EER來說,i/d-vector系統相對于i-vector系統在干凈環境下和噪聲環境下分別下降了13%和27%。
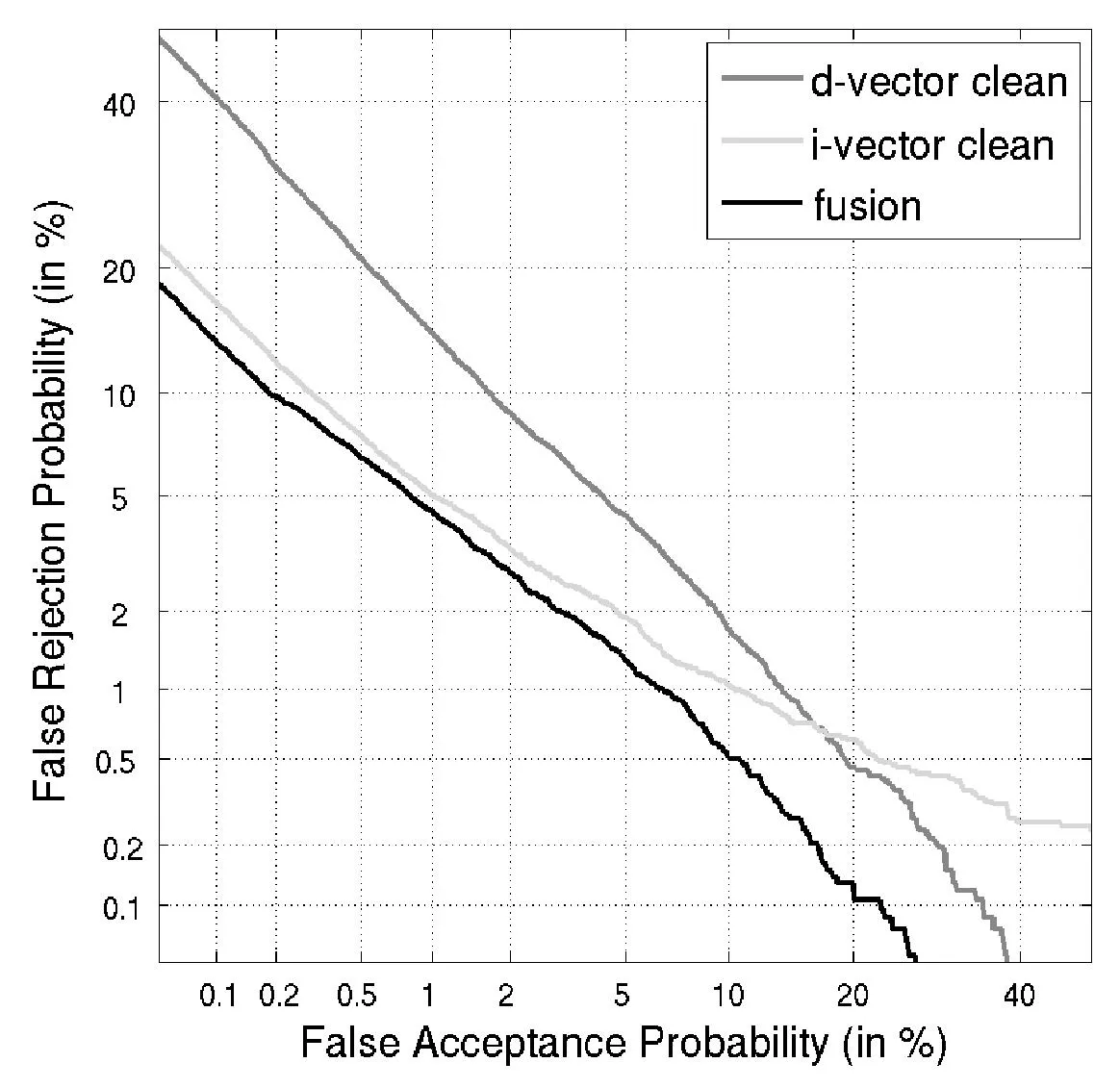
圖4 在干凈語音下比較融合后的系統(fusion)與單個系統的性能

圖5 在噪聲語音下比較融合后的系統(fusion)與單個系統的性能
4結語
本文提出了一種新的基于DNN的話者確認方法,通過采用語音信號的倒譜特征參數訓練DNN來區分說話人,被訓練的DNN用于抽取語音信號中與說話人相關的特征參數。最后將這些特征參數取平均,得到d-vector,然后用于話者確認系統。通過實驗表明基于d-vector的話者確認系統的性能與i-vector基線系統相當,在融合了兩種系統之后發現,融合后的系統優于其任何一個單獨的系統。并且在噪聲環境下,基于d-vector話者確認系統比i-vector基線系統的魯棒性更好;在低的錯誤拒絕率的條件下基于d-vector的話者確認系統優于i-vector基線系統。
接下來的工作主要包括修改現在的余弦評分策略,以及采用新的規整方法對評分進行規整。進一步去探索新的融合策略,如在i-vector和d-vector空間使用PLDA模型等。最終,希望能夠提出一種有效的魯棒性更好的話者確認系統。
參考文獻
[1]ReynoldsDA,QuatieriTF,DunnRB.SpeakerverificationusingadaptedGaussianmixturemodels[J].Digitalsignalprocessing,2000,10(1):19-41.
[2]KennyP,BoulianneG,OuelletP,etal.Jointfactoranalysisversuseigenchannelsinspeakerrecognition[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2007,15(4):1435-1447.
[3]KennyP,BoulianneG,OuelletP,etal.SpeakerandsessionvariabilityinGMM-basedspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2007,15(4):1448-1460.
[4]KennyP,OuelletP,DehakN,etal.Astudyofinterspeakervariabilityinspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2008,16(5):980-988.
[5]DehakN,KennyP,DehakR,etal.Front-endfactoranalysisforspeakerverification[J].Audio,Speech,andLanguageProcessing,IEEETransactionson,2011,19(4):788-798.
[6]HintonG,DengL,YuD,etal.Deepneuralnetworksforacousticmodelinginspeechrecognition:Thesharedviewsoffourresearchgroups[J].SignalProcessingMagazine,IEEE,2012,29(6):82-97.
[7]MartinAF,GreenbergCS.TheNIST2010speakerrecognitionevaluation[C]//Interspeech2010,11thAnnualConferenceoftheInternationalSpeechCommunicationAssociation,Makuhari,Chiba,Japan,2010:2726-2729.
[8]KennyP.BayesianSpeakerVerificationwithHeavy-TailedPriors[C]//Proc.OdysseySpeakerandLanguageRecognitionWorkshop,Brno,CzechRepublic,2010:14.
[9]LarcherA,LeeKA,MaB,etal.Phonetically-constrainedPLDAmodelingfortext-dependentspeakerverificationwithmultipleshortutterances[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2013IEEEInternationalConferenceon.IEEE,2013:7673-7677.
[10]YegnanarayanaB,KishoreSP.AANN:analternativetoGMMforpatternrecognition[J].NeuralNetworks,2002,15(3):459-469.
[11]HeckLP,KonigY,S?nmezMK,etal.Robustnesstotelephonehandsetdistortioninspeakerrecognitionbydiscriminativefeaturedesign[J].SpeechCommunication,2000,31(2):181-192.
[12]LeeH,PhamP,LargmanY,etal.Unsupervisedfeaturelearningforaudioclassificationusingconvolutionaldeepbeliefnetworks[C]//Advancesinneuralinformationprocessingsystems,2009:1096-1104.
[13]StafylakisT,KennyP,SenoussaouiM,etal.PreliminaryinvestigationofBoltzmannmachineclassifiersforspeakerrecognition[C]//ProceedingsOdysseySpeakerandLanguageRecognitionWorkshop,2012.
[14]VarianiE,LeiX,McDermottE,etal.Deepneuralnetworksforsmallfootprinttext-dependentspeakerverification[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2014IEEEInternationalConferenceon.IEEE,2014:4052-4056.
[15]CaiM,ShiY,LiuJ.Deepmaxoutneuralnetworksforspeechrecognition[C]//AutomaticSpeechRecognitionandUnderstanding(ASRU),2013IEEEWorkshopon.IEEE,2013:291-296.
[16]DahlGE,SainathTN,HintonGE.ImprovingdeepneuralnetworksforLVCSRusingrectifiedlinearunitsanddropout[C]//Acoustics,SpeechandSignalProcessing(ICASSP),2013IEEEInternationalConferenceon.IEEE,2013:8609-8613.
[17]AuckenthalerR,CareyM,LloydThomasH.Scorenormalizationfortext-independentspeakerverificationsystems[J].DigitalSignalProcessing,2000,10(1):42-54.
A SPEAKER VERIFICATION METHOD BASED ON DEEP NEURAL NETWORK
Wu MinghuiHu QunweiLi Hui
(Department of Electronic Science and Technology,University of Science and Technology of China,Hefei 230027,Anhui,China)
AbstractIn this paper we mainly investigate the method of using deep neural network (DNN) for speaker verification. At the stage of training, the DNN is trained under supervision using the feature parameter of speech cepstrum as input and the label of speaker as output. At the stage of speaker registration, an eigenvector correlated to the speaker, namely d-vector, is extracted from the last hidden layer of the trained DNN and is used as the model of speaker. At test stage, from testing speech a d-vector is extracted to compare it with the model of the registered speaker and then to make the verification decision. Experimental results show that the DNN-based speaker verification method is feasible. Moreover, under the condition of noisy environment and low error-rejection rate, the DNN-based speaker verification system outperforms the i-vector base line system in performance. Finally, we integrate these two systems, relative to the i-vector base line system, the integrated system reduces the equal error rate (EER) by 13% and 27% for clean speech and noisy speck conditions respectively.
KeywordsSpeaker verificationDeep neural network (DNN)Deep learning
收稿日期:2014-12-14。吳明輝,碩士,主研領域:人工智能與模式識別,語音信號處理。胡群威,碩士。李輝,副教授。
中圖分類號TP3
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.06.039
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
