基于上下文詞頻詞匯量指標的新詞發現方法
2016-07-19 02:07:19邢恩軍趙富強
計算機應用與軟件 2016年6期
關鍵詞:方法
邢恩軍 趙富強
1(天津大學管理與經濟學部 天津 300072)2(天津財經大學信息科學與技術系 天津 300222)
?
基于上下文詞頻詞匯量指標的新詞發現方法
邢恩軍1,2趙富強2
1(天津大學管理與經濟學部天津 300072)2(天津財經大學信息科學與技術系天津 300222)
摘要提出一種基于上下文詞頻詞匯量的統計指標。該指標通過修改信息熵公式中參數的定義,即將鄰接字符串在語料集中出現的次數改成鄰接字符串集合的大小,克服了左右信息熵在識別新詞時特征不夠明顯的缺點。同時提出一種遞歸的基于鄰接關系的字符串連接方法,克服了N-gram方法采用固定滑動窗口大小的缺點。實證分析表明該新詞發現方法有較高的準確率,通過選取不同的詞頻詞匯量指標值作為閾值,能夠在發現更多新詞和提高發現新詞的準確率方面進行靈活調整,為新詞發現提供一種實用的方法。
關鍵詞新詞發現上下文信息熵詞頻詞匯量指標
0引言
隨著社會經濟、文化、科技水平的不斷提高,新詞一直在大量且迅速地涌現。新詞發現作為自然語言處理、文本挖掘等研究中的一個基礎環節,對于提高后續信息處理的效果有重要意義[1,2]。
新詞發現方法可以粗略地分為基于語言規則的方法和基于統計學習的方法[3,4]。語言規則的構造與維護需要由語言學家進行,不僅耗費時間而且很難擴展。統計學習的方法主要依賴于大規模的語料,通過計算成詞概率,詞頻、左信息熵、右信息熵等統計特征作為識別新詞的依據。本質上,統計特征是對漢字構詞能力的量化。
在對語料進行切分組合方面,比較常見的是采用N-gram模型,在切分字符串的基礎上,將文本內容按大小為N的滑動窗口操作,形成長度為N的字符串[5,6]。另外還有將新詞發現與分詞工具進行結合,在分詞之后或分詞的同時,依據詞性及其他組合規則進行新詞發現[1,7]。
在統計分析方面,采用的指標和方法比較多樣,比較常見的是詞頻、左右信息熵、獨立成詞概率、構詞規則等。鄒綱[8]等通過統計不同時間段和不同來源所獲取的語料,比較其中的差別得到新詞。羅智勇[9]等通過采用PAT-Array數據結構表示字符串之間的鄰接關系,通過計算候選字符串的左右信息熵、似然比等進行統計分析,從而獲得新詞。賀敏[10]等提出了一種在統計重復串的基礎上,通過判斷上下文鄰接類別,首尾單字位置成詞概率以及雙字耦合度等語言特征,將詞串的外部語言環境和內部構成相結合的新詞識別方法。Wu[10]等使用獨立成詞概率和構詞方式作為判斷新詞的標準。陳飛[12]等利用條件隨機場CRF(conditionrandomfield)可對序列輸入標注的特點,將新詞發現問題轉化為預測已分詞詞語邊界是否為新詞邊界的問題。Sun[13]等提出了利用半馬爾可夫條件隨機場模型結合潛在動態條件隨機場和詞性標注識別新詞的方法。丁建立[14]等提出一種應用免疫遺傳算法的網絡新詞識別方法, 利用漢語詞群現象和詞位的概念提取和注入抗體。Sun[15]等提出了根據查詢日志分析用戶行為習慣并結合詞性詞頻等指標進行新詞發現的方法。
1基于上下文詞頻詞匯量指標的方法
在新詞發現研究中,普遍采用的N-gram方法通過選取不同的滑動窗口大小來限定候選詞的長度,不能很好地適應不同長度的詞語。
左信息熵和右信息熵是常用的判定新詞的統計指標。在實驗中發現,左信息熵和右信息熵較大的漢字或詞其獨立成詞能力較強,一般不會與其他漢字或詞構成新詞,可以作為停用詞的主要候選對象。但是,信息熵公式的特點是傾向于具有最小的鄰接字符串集合的漢字或詞。例如:在實驗中發現,語料庫中“不足為慮”僅出現一次,它的唯一左鄰接字符串為“或許”,其左信息熵為0,僅依據信息熵作為判斷標準的話,“或許不足為慮”作為一個新詞的可能性很高。所以采用信息熵作為統計指標時,必須結合詞頻以及其他一些統計指標。
針對以上兩點不足,本文提出了基于上下文詞頻詞匯量指標的方法。
1.1方法概述
本方法所使用的語料庫是通過爬取網頁并抽取其標題及正文部分構成的。
首先,將文本內容按照標點符號、特殊字符、數字等分割成短句。然后,使用jcseg中文分詞器進行分詞。將分詞結果中的每個字符串、字符串的左鄰接字符串、字符串的右鄰接字符串、詞頻等信息記錄下來。依據上述信息進行統計計算,發現其中出現的新詞。最后針對發現的新詞進行后處理,刪除新詞首尾出現的停用詞,過濾掉某些特定的錯誤組合。
1.2方法采用的數據結構
設字符串s的左鄰接字符串集合為L={l1,l2,…,lm},右鄰接字符串集合為R={r1,r2,…,rn}。cls(li,s)為字符串lis在語料集中出現的次數,csr(s,ri)為字符串sri在語料集中出現的次數。
使用LSR(s,ri)表示字符串sri的左鄰接字符串集合。使用RLS(li,s)表示字符串lis的右鄰接字符串集合。LSR(s,ri)和RLS(li,s)的作用是關聯左右鄰接字符串,保證在后續合成新詞的時候,能夠正確地將s的左鄰接字符串、字符串s和s的右鄰接字符串合并在一起,進而遞歸地結合更多的字符串。
記錄每一個字符串s及相關信息的數據結構如圖1所示。
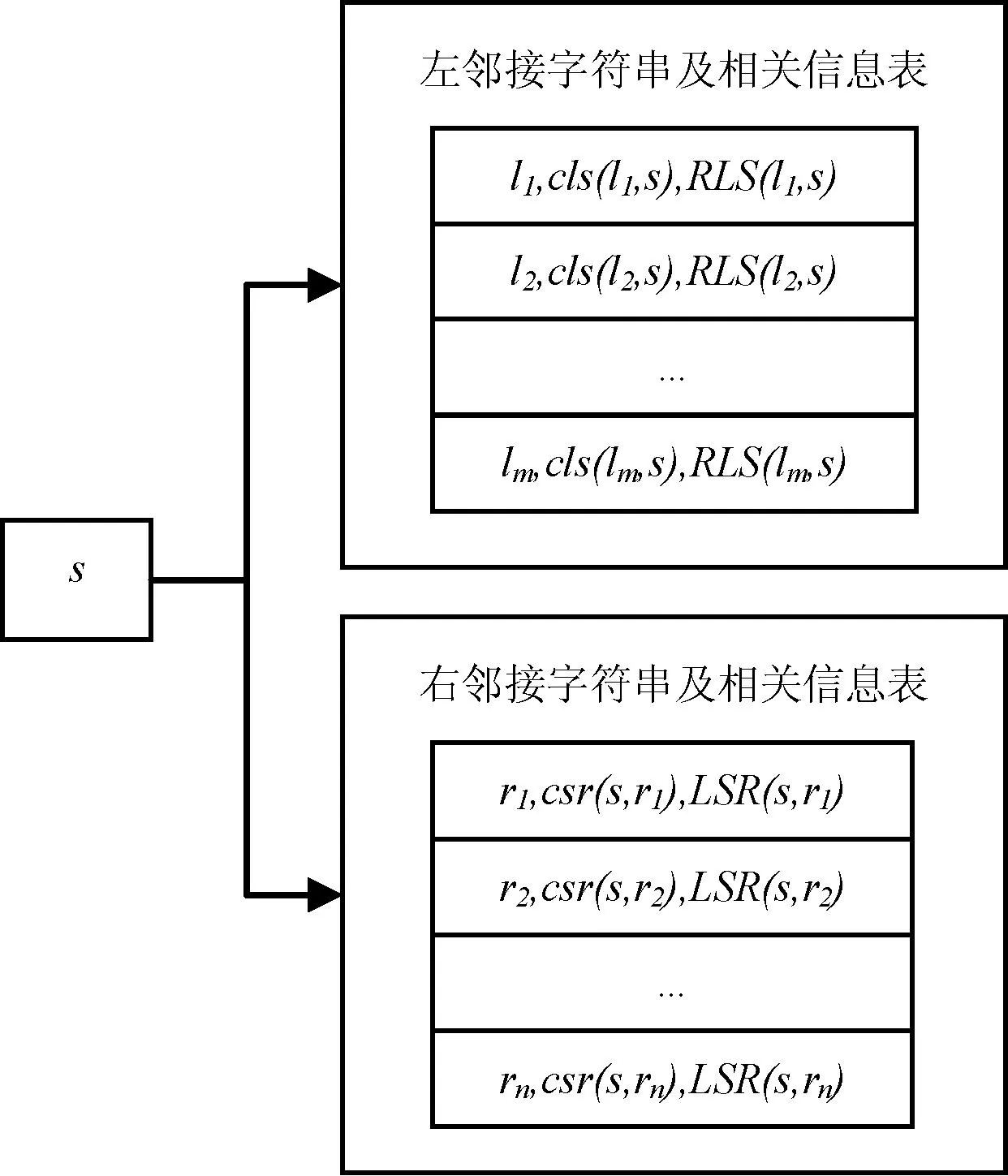
圖1 記錄每個字符串及相關信息的數據結構
1.3左信息熵和右信息熵
左信息熵和右信息熵較大的漢字或詞其獨立成詞能力較強,在本方法中用于選取停用詞。
根據信息熵公式[16,17]:
(1)
字符串s的左信息熵定義為:
(2)
字符串s的右信息熵定義為:
(3)
1.4詞頻詞匯量指標
字符串s的左詞頻詞匯量指標定義為:
(4)
其中k為集合L的大小。每一個左鄰接字符串li對詞頻詞匯量指標的貢獻值為:
(5)
s的右詞頻詞匯量指標定義為:
(6)
其中k為集合R的大小。每一個右鄰接字符串ri對詞頻詞匯量指標的貢獻值為:
(7)
其中,CDL(li,s)和CDR(s,ri)表示字符串s與某個鄰接字符串結合緊密程度的指標。CL(s)和CR(s)對應CDL(li,s)和CDR(s,ri)的均值,表示字符串s與左右鄰接字符串結合緊密程度的指標,即s獨立成詞能力的指標。
2實驗
本文實驗所采用的語料是從搜狐財經、新浪財經、網易財經等13個網站,爬取到的2014年7月14日到8月13日2594個網頁,并抽取其中的文章標題和正文部分。
2.1停用詞的產生
通過計算每一個字符串s的左信息熵HL(s)并對結果進行排序,可以得到如圖2所示結果。

圖2 左鄰接字符串的信息熵
橫軸為按左信息熵排序后的字符串s的索引。縱軸為每個字符串的左信息熵。
以同樣方法計算右信息熵HR(s)并繪圖,可以得到幾乎完全一樣的圖形。
分析數據可以發現,HL(s)=0的字符串,在語料庫中出現次數基本都在3次以下,并且其左鄰接字符串大多只有1個。HL(s)最大的一系列字符串在語料庫中出現次數多,并且其左鄰接字符串比較多,如表1所示。
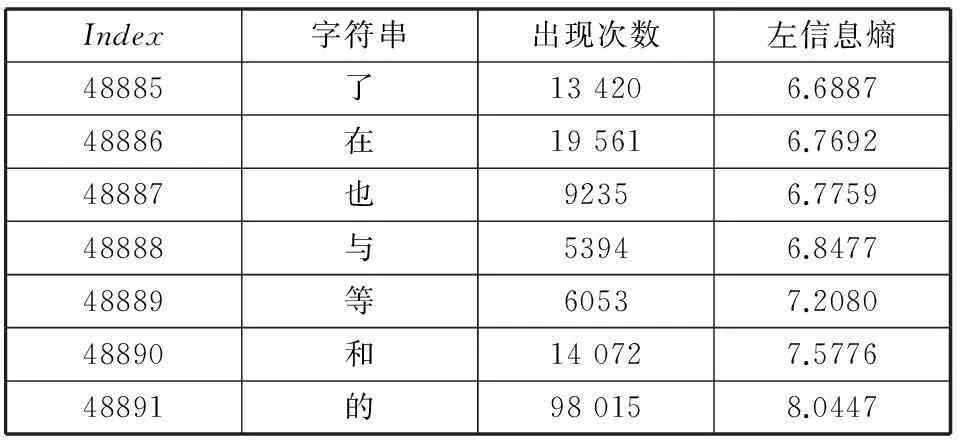
表1 左信息熵最大的幾個字符串
HL(s)取其他值的情況,可以從圖2中看出,其曲線的趨勢比較平緩,沒有特別明顯的特征。這是基于統計學方法進行新詞發現的研究中,采用信息熵作為統計指標的主要缺點。
所以在本方法中左右信息熵僅作為選取停用詞的指標。在本實驗中,選取HL(s)大于6的字符串構成左停用詞表,選取HR(s)大于6的字符串構成右停用詞表。
2.2詞頻詞匯量指標計算結果
采用詞頻詞匯量指標,對相同的語料進行分析,按照CL(s)排序,結果如圖3所示。
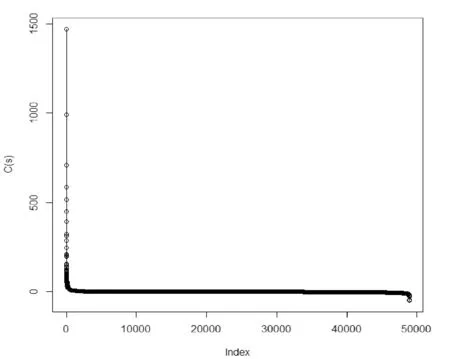
圖3 左鄰接字符串的詞頻詞匯量指標
圖中左側豎直狀的數據表明字符串s與其左鄰接字符串有很高的成詞概率。而圖中下側水平狀的數據表明字符串s與其左鄰接字符串有很低的成詞概率。將圖3和圖2進行對比,可以看出詞頻詞匯量指標比信息熵指標特征更為明顯。
為了觀察方便,僅保留實驗數據中CL(s)數據最密集的部分,重新畫圖,可以得到更清晰的特征,如圖4所示。

圖4 左鄰接字符串的詞頻詞匯量指標
選取特定的CL(s)作為CDL(li,s)和CDR(s,ri)的閾值,進行字符串的合并可獲得新詞。
在實驗中,依次選取了從0到14作為閾值,并對比了實驗結果,并對其中出現的各種可能的錯誤組合原因進行分析。
2.3錯誤組合原因分析
(1) 過濾掉停用詞時造成一些新詞被截斷。這是因為某些字符串即便其信息熵很大,但仍能夠與其他字符串組合成新詞,如: “中信建投”被截斷成“信建投”,因為“中”是停用詞。
(2) 字符串s有大量其他組合,甚至其中有更高頻的組合,造成某些詞的詞頻詞匯量指標降低到小于閾值。如:“封閉回款”被截斷成“封閉回”,是因為“回”的右鄰接字符串有78個,其中高頻組合有“回購”、“回調”等,雖然“回款”的詞頻排在第三位,但其CDR(s,ri)已經降低到了-28.2318,遠遠小于閾值。隨著分詞工具所使用的詞庫不斷豐富,這類錯誤能夠逐漸消失。
(3) 生成多個詞,有正確有錯誤。如:“湘財證券”被分詞程序分成“湘”、“財”、“證券”三個詞,在處理“湘”時能夠得到“湘財”,處理“財”時能夠得到“湘財證券”,而處理“證券”時,能夠得到“財證券”。因為在遞歸向左搜索鄰接字符串時,“財”的CL(s)數值為-2.8804不符合要求。這樣做是為了避免過度搜索,CL(s)過小意味著字符串s與左鄰接字符串的關系不密切,自身獨立成詞能力較高。雖然有CDL(li,s)符合要求,也終止搜索,因為有大量字符串都存在CDL(li,s)較大的鄰接字符串。在后處理過程中,針對這種錯誤情況進行了過濾。
(4) 中文分詞器造成的錯誤。如:字符串“有害物質的”被分詞為“有害物”和“質的”,合并后成為錯誤的新詞。
(5) 由數字造成的錯誤。本文提出的方法在處理過程中把文本按照標點符號、特殊字符、數字等分割成短句,當語料中出現“47號文”、“48號文”這類詞語時,會得出“號文”這類錯誤的新詞。
(6) 由高頻出現的詞匯組合造成的錯誤。本文提出的方法采用最長匹配原則,當遇到高頻的詞匯組合時,會產生一些過長的新詞。如:“第一財經日報記者”、“雪佛蘭產品”,以及類似“習近平總書記”這類“職務+姓名”或“姓名+職務”組成的詞。在后處理過程中,針對這種錯誤情況進行過濾。
2.4后處理
針對新詞的后處理包含兩部分內容:
(1) 刪除新詞首尾出現的停用詞。在計算得出新詞后,需要根據停用詞表刪除掉左右停用詞。
(2) 過濾掉某些特定的錯誤組合。針對上述錯誤組合原因分析中出現的第3種錯誤情況,在后處理時,找出結果中具有包含關系的所有新詞,根據組成新詞的每個部分的CDL(li,s)和CDR(s,ri)進行判斷,將錯誤的新詞過濾掉。針對上述錯誤原因分析中出現的第6種錯誤情況,統計出常見的表示各種稱謂的詞語補充到停用詞表中,在刪除左右停用詞時將其處理掉。由于這種處理可能會造成結果中出現重復的新詞,所以需要將重復詞過濾掉。
2.5實驗結果
對新詞的正確率進行統計,結果如表2所示。
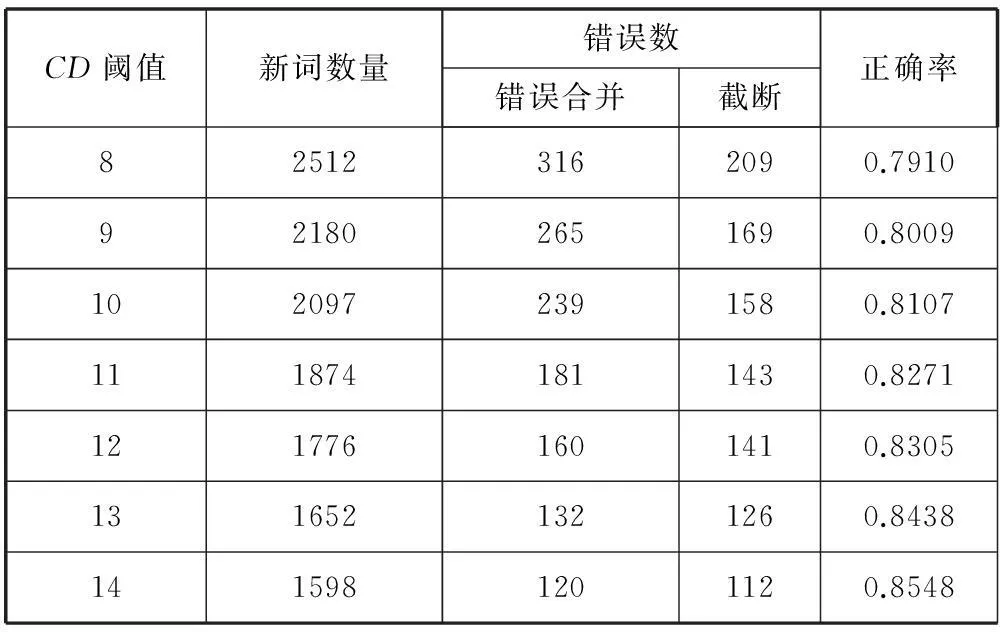
表2 不同參數下的實驗結果
本實驗結果所采用的閾值是依據圖4中所顯示的特征選擇的,處于曲線的過渡部分。從結果可以看出,隨著閾值的增大,所發現的新詞數量持續減少,而正確率持續增加。通過采用不同的閾值,能夠在發現更多新詞和提高新詞的準確率方面進行靈活調整。
3結語
針對新詞發現研究中常用的N-gram方法和信息熵指標的不足,本文提出了基于上下文詞頻詞匯量指標的方法,并且對實驗結果進行了分析。本方法沒有N-gram方法中窗口大小的限制,詞頻詞匯量指標結合了左右鄰接字符串的詞頻和左右鄰接字符串的數量兩個關鍵數據,顯示出非常明顯的特征。本方法與領域無關,對新詞的長度沒有限制,僅采用一個統計指標就能取得較好的效果。
下一步的工作主要是針對實驗中發現錯誤組合情況優化算法,以及結合更多的統計指標改善新詞發現的正確率。另外,可能的進一步工作是改造本方法,使其能夠不依賴分詞工具直接進行新詞發現。
參考文獻
[1]PengFC,FengFF,McCallumA.Chinesesegmentationandnewworddetectionusingconditionalrandomfields[C]//InternatioalConferenceonComputationalLinguistics.Stroudsburg,2004.
[2]SproatR,EmersonT.FirstinternationalChinesewordsegmentationbakeoff[C]//ProceedingsoftheSecondSIGHANWorkshoponChineseLanguageProcessing,2003.
[3] 張海軍,史樹敏,朱朝勇,等.中文新詞識別技術綜述[J].計算機科學,2010,37(3):6-10.
[4]NieJY,HannanML,JinW.UnknownworddetectionandsegmentationofChineseusingstatisticalandheuristicknowledge[J].CommunicationsofCOLIPS,1995,5(1):47-57.
[5] 曹艷,杜慧平,劉竟,等.基于詞表和N-gram算法的新詞識別實驗[J].情報科學,2007,25(11):1687-1691.
[6]GaoJF,GoodmanJ,LiMJ,etal.TowardaunifiedapproachtostatisticallanguagemodelingforChinese[J].ACMTransactionsonAsianLanguageInformationProcessing,2002,1(1):3-33.
[7]ZhangK,LiuQ,ZhangH,etal.AutomaticrecognitionofChineseunknownwordsbasedonrolestagging[C]//ProceedingsofthefirstSIGHANworkshoponChineselanguageprocessing-Volume18.AssociationforComputationalLinguistics,2002:1-7.
[8] 鄒綱,劉洋,劉群,等.面向Internet的中文新詞語檢測[J].中文信息學報,2004,18(6):1-9.
[9] 羅智勇,宋柔.基于多特征的自適應新詞識別[J].北京工業大學學報,2007,33(7):718-725.
[10] 賀敏,龔才春,張華平,等.一種基于大規模語料的新詞識別方法[J].計算機工程與應用,2007,43(21):157-159.
[11]WuA,JiangZ.Statistically-EnhancedNewwordidentificationinarule-basedChinesesystem[C]//ProceedingsoftheSecondChineseLanguageProcessingWorkshop.HongKong,China,2000:46-51.
[12] 陳飛,劉奕群,魏超,等.基于條件隨機場方法的開放領域新詞發現[J].軟件學報,2013,24(5):1051-1060.
[13]SunX,HuangDG,SongHY,etal.Chinesenewwordidentification:ALatentDiscriminativeModelwithGlobalFeatures[J].JournalofComputerScienceandTechnology,2011,26(1):14-24.
[14] 丁建立,慈祥,黃劍雄.一種基于免疫遺傳算法的網絡新詞識別方法[J].計算機科學,2011,38(1):240-245.
[15]SunR,JinP,LaiJ.AmethodfornewwordextractiononChineselarge-scalequerylogs[C]//2012EighthInternationalConferenceonComputationalIntelligenceandSecurity.IEEE,2011:1256-1259.
[16]BordaM.Fundamentalsininformationtheoryandcoding[M].Springer,2011.
[17]HanTS,KobayashiK.Mathematicsofinformationandcoding[M].AmericanMathematicalSociety,2002.
A NOVEL APPROACH FOR CHINESE NEW WORD IDENTIFICATION BASED ONCONTEXTUALWORDFREQUENCY-CONTEXTUALWORDCOUNT
Xing Enjun1,2Zhao Fuqiang2
1(College of Management and Economics,Tianjin University,Tianjin 300072,China)2(Department of Information Science and Technology,Tianjin University of Finance and Economics,Tianjin 300222,China)
AbstractThis article presents a statistic index which is based on contextual word frequency-contextual word count (WF-CWC). WF-CWC, by modifying the definition of the parameters in information entropy formula, i.e., changing the occurrence frequency of adjacent strings in corpus to the size of the adjacent strings collection, overcomes the defect of left and right information entropies being not significant in characteristics when identifying new words. Meanwhile, this paper presents a recursive and adjacent relation-based string concatenation method, which overcomes the disadvantage of the fixed sliding window size in N-gram model. Empirical analysis indicates that this new word identification method has higher accuracy. Through selecting different WF-CWC as the thresholds, it can make flexible adjustment in finding more new words or improve the accuracy of new words identification, and this provides a practical approach for new words identification.
KeywordsNew word identificationInformation entropy of contextContext word frequency-context word count
收稿日期:2015-01-09。國家自然科學基金青年基金項目(6100 4056);天津自然科學基金資助項目(15JCYBJC16000);天津市哲學社會科學研究規劃基金資助項目(TJTJ15-002)。邢恩軍,講師,主研領域:文本挖掘。趙富強,副教授。
中圖分類號TP391.1
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.06.016
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
