基于云計(jì)算平臺的動態(tài)增量密度算法研究
2016-07-19 02:12:33孟海東任敬佩
計(jì)算機(jī)應(yīng)用與軟件 2016年6期
關(guān)鍵詞:定義
孟海東 任敬佩
(內(nèi)蒙古科技大學(xué)信息工程學(xué)院 內(nèi)蒙古 包頭014010)
?
基于云計(jì)算平臺的動態(tài)增量密度算法研究
孟海東任敬佩
(內(nèi)蒙古科技大學(xué)信息工程學(xué)院內(nèi)蒙古 包頭014010)
摘要針對傳統(tǒng)密度聚類算法處理海量數(shù)據(jù)時(shí)間復(fù)雜度高且不適合處理動態(tài)數(shù)據(jù)等問題,提出一種利用參考點(diǎn)和MapReduce模型進(jìn)行動態(tài)增量聚類的密度算法。其創(chuàng)新點(diǎn)在于,該算法實(shí)現(xiàn)了一種能夠處理海量動態(tài)數(shù)據(jù)的聚類算法,保證了增量聚類與重新聚類結(jié)果的一致性,并具有可擴(kuò)展性的特點(diǎn)。實(shí)驗(yàn)結(jié)果證明:該算法降低了參數(shù)敏感性,提高了密度算法的聚類效率和資源利用率,適合大數(shù)據(jù)分析。
關(guān)鍵詞參考點(diǎn)增量聚類MapReduce動態(tài)密度算法
0引言
目前對于傳統(tǒng)密度聚類算法改進(jìn)的研究主要用包括數(shù)據(jù)場[1]、網(wǎng)格[2,3]、增量[4-6]、并行[7]和MapReduce等方法。其中研究最多的是基于MapReduce模型的并行密度聚類算法來提高算法的聚類效率和資源利用率。由于隨著數(shù)據(jù)量的增長,利用云計(jì)算處理大數(shù)據(jù)進(jìn)行聚類已成為熱點(diǎn)。文獻(xiàn)[8]提出了一種基于MapReduce層次的密度聚類算法HDBSCAN,降低了參數(shù)的敏感性,提高了算法的效率;文獻(xiàn)[9]利用MapReduce模型與粒子群優(yōu)化方法提出了DPDPSO算法,降低了內(nèi)存的依賴,同時(shí)也提高了DBSCAN算法的運(yùn)行時(shí)間;文獻(xiàn)[10]利用MapReduce機(jī)制,實(shí)現(xiàn)區(qū)域查詢和候選隊(duì)列處理,提高了算法的聚類效率;文獻(xiàn)[11-14]通過Hadoop平臺實(shí)現(xiàn)了DBSCAN算法的改進(jìn),提高了算法的加速比和可伸縮性;文獻(xiàn)[15,16]利用云計(jì)算平臺提出了增量DBSCAN聚類算法,實(shí)現(xiàn)局部挖掘知識與原先整體挖掘知識進(jìn)行類簇相似性合并,形成最終的挖掘知識。
以上都是基于靜態(tài)密度聚類,因而本文提出一種利用參考點(diǎn)作為初始中心點(diǎn)并使用MapReduce模型進(jìn)行并行計(jì)算的動態(tài)DBSCAN算法DICURDA(Dynamic and Incremental Clustering Using References and Density Algorithm)。DICURDA算法基于MapReduce模型實(shí)現(xiàn)了并行密度算法。利用虛擬的參考點(diǎn)反應(yīng)了數(shù)據(jù)空間的點(diǎn)分布特征,并在增量聚類過程中利用參考點(diǎn)和密度算法實(shí)現(xiàn)了動態(tài)聚類,降低了在增量聚類過程中參數(shù)的敏感和時(shí)間復(fù)雜度,以及對核心點(diǎn)的I/O次數(shù)。
1DICURDA聚類算法
1.1概念
設(shè)在云計(jì)算平臺處理的大數(shù)據(jù)中,原始數(shù)據(jù)集為V(v1,v2,…,vn),聚類中心點(diǎn)為Ci(i=1,2,…,k);增量數(shù)據(jù)集為△V(△v1,△v2,…,△vn),增量中心點(diǎn)△Ci(i=1,2,…,k)。
定義1(點(diǎn)的密度)在集群的各個(gè)節(jié)點(diǎn)中,對空間中的任意點(diǎn)p,給定區(qū)域半徑R,如果點(diǎn)p到其他點(diǎn)pi(i=1,2,…,n)距離dppi小于等于R的個(gè)數(shù)為ρp,則稱點(diǎn)p的密度為ρp,記作ρp(p,R)。
ρp=∑χ(dppi-R)
(1)
定義2(點(diǎn)密度距離)給定密度閾值T,設(shè)密度點(diǎn)距離δp,則:
(2)
如果ρp≥T,則稱為高密度點(diǎn),記作H(ρp,δp);反之,稱為稀疏密度點(diǎn),記作L(ρp,δp)。
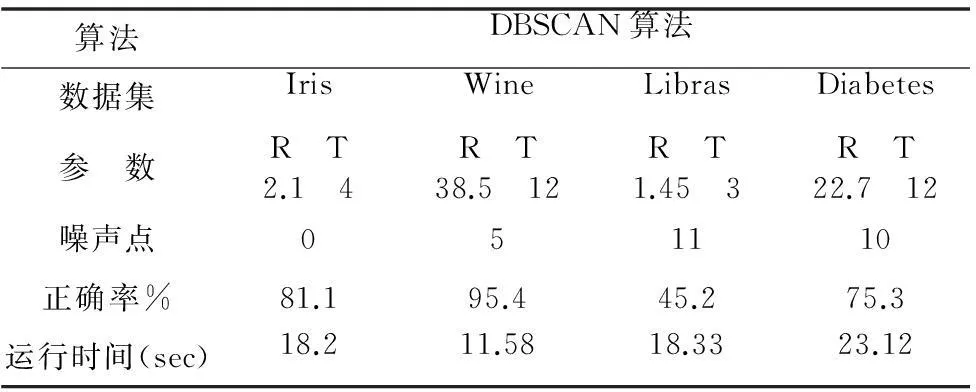
定義3(參考點(diǎn))給定一個(gè)距離閾值D,根據(jù)定義2可知,若某點(diǎn)為稀疏密度點(diǎn)H(ρp,δp)且δp 定義4(核心點(diǎn))給定一個(gè)距離閾值D,根據(jù)定義2可知,高密度點(diǎn)H(ρp,δp),如果δp>D,則稱點(diǎn)p為核心點(diǎn)。 定義5(直接密度可達(dá))在給定的對象集V中,由定義2可知,高密度點(diǎn)H(ρp,δp)與H(ρq,δq),如果δq 定義6(密度可達(dá))在給定的對象集V中,存在點(diǎn)pi(i=1,2,…,n),由定義2可知,稀疏密度點(diǎn)L(ρpi,δpi),高度密度點(diǎn)H(ρq,δq),如果δq 定義7(噪聲點(diǎn))在給定的對象集V中,由定義2可知,稀疏密度點(diǎn)L(ρp,δp),如果δp>D,則p為噪聲點(diǎn)。 定義8V(v1,v2,…,vn)初始聚類過程中對象簇Ci(i=1,2,…,k)設(shè)為全局參數(shù),則Ci(i=1,2,…,k)是△V(△v1,△v2,…,△vn)的聚類的參考點(diǎn)(核心點(diǎn))。 參考點(diǎn)即是核心點(diǎn),因?yàn)樵诔跏季垲惤Y(jié)果中獲得的參考點(diǎn)都是符合定義4的點(diǎn)的集合。 定義9(簇合并)設(shè)參考點(diǎn)p和q所屬簇分別為Cp和Cq,如果點(diǎn)p到點(diǎn)q的距離小于或等于R,即: Dis(p,q)≤R (3) 則Cp和Cq合并為簇Cpq。 證明:設(shè)點(diǎn)p與點(diǎn)q為參考點(diǎn),由定義2和定義3可知,如果ρp>T且δp>D,p則為核心點(diǎn),當(dāng)Dis(p,q)≤R時(shí),則q屬于ρp(p,R)內(nèi)的密度點(diǎn);由定義5和定義6可知,如果點(diǎn)q是H(ρq,δq),則對象q到p是直接密度可達(dá);如果點(diǎn)q是L(ρpi,δpi),則對象q到p是密度可達(dá);因此,簇Cp和Cq可以合并為簇Cpq。 例如:設(shè)點(diǎn)的區(qū)域半徑R=10,密度閾值T=5,距離閾值D=9,P(p1,p2,…,pn)是二維空間中任意數(shù)據(jù)點(diǎn)如圖1所示,則: 圖1 二維空間數(shù)據(jù)點(diǎn)分布 根據(jù)定義1可從圖1與圖2中看出,p1、p2、p3、p4、p5的密度點(diǎn)分別為ρp1(9,10)、ρp2(11,10)、ρp3(4,10)、ρp4(1,10)、ρp5(7,10),具體如圖2所示;根據(jù)定義2,由于p1、p2、p4的密度大于T=7,則p1、p2、p5是高密度的點(diǎn),分別記作H(9,8.93)、H(11,8.97)、H(7,9.21);反之,p3、p4為稀疏密度點(diǎn),分別記作L(4,3.23)、L(1,22.92),具體如圖2所示。根據(jù)定義3和定義4可知,p1、p2、p5為高密度點(diǎn),δp1、δp2為參考點(diǎn),δp5大于D=9,則為參考點(diǎn)且為核心點(diǎn);p3、p4為稀疏點(diǎn),且δp3 圖2 二維數(shù)據(jù)點(diǎn)的Pi(ρpi,δpi)分布 圖3 DICURDA算法的簇合并 1.2DICURDA算法設(shè)計(jì) 根據(jù)1.1節(jié)中概念定義的敘述,DICURDA算法的聚類過程中,設(shè)噪聲點(diǎn)對象簇為Oi(i=0,1,…),增量噪聲點(diǎn)對象簇為△Oi(i=0,1,…);根據(jù)上述中定義,在數(shù)據(jù)集V可以實(shí)現(xiàn)對象簇Ci(i=1,2,…,k)。隨著數(shù)據(jù)集的動態(tài)的增長,當(dāng)增量數(shù)據(jù)集為△V時(shí),實(shí)現(xiàn)增量數(shù)據(jù)集△V的聚類過程,聚類結(jié)果新簇為△Ci(i=1,2,…,k)。ICURD算法的實(shí)現(xiàn)過程主要分為以下兩個(gè)過程: (1) 初始聚類過程 ① 對于數(shù)據(jù)集V(v1,v2,…,vn)中的每個(gè)數(shù)據(jù)點(diǎn),根據(jù)定義1計(jì)算出每個(gè)點(diǎn)的密度ρvi(vi,R)(i=1,2,…,n)。 ② 根據(jù)定義2,計(jì)算出每個(gè)數(shù)據(jù)點(diǎn)的δvi(i=1,2,…,n)。 ③ 根據(jù)定義3,判斷每個(gè)數(shù)據(jù)點(diǎn)是否為參考點(diǎn)的條件如下:根據(jù)定義4判斷該點(diǎn)是否是核心點(diǎn),如果是,則標(biāo)記為單標(biāo)記的簇,同時(shí),密度范圍內(nèi)的點(diǎn)標(biāo)記為同樣的簇標(biāo)識;如果不是核心點(diǎn),則根據(jù)定義5和定義6,判斷是否滿足直接密度可達(dá)和密度可達(dá)條件,如果符合條件,則把該密度范圍內(nèi)的點(diǎn)標(biāo)記為符合該條件的分配給相應(yīng)的簇中。 ④ 直到數(shù)據(jù)集V(v1,v2,…,vn)中的每個(gè)數(shù)據(jù)點(diǎn)全部被標(biāo)識后,根據(jù)定義7,判斷是否存在噪聲點(diǎn),若存在,則標(biāo)記為Oi(i=0,1,…)。 ⑤ 把各個(gè)簇內(nèi)各維坐標(biāo)值累計(jì)求均值,結(jié)果輸出Ci(i=1,2,…,k)。 (2) 增量聚類過程 ① 設(shè)原始數(shù)據(jù)中心點(diǎn)(根據(jù)定義8)Ci(i=1,2,…,k)為△V(△v1,△v2,…,△vn)進(jìn)行聚類的參考點(diǎn)(設(shè)為全局變量。 ② 計(jì)算△V(△v1,△v2,…,△vn)中△v1的ρ(△v1,R),如果是參考點(diǎn),則計(jì)算該點(diǎn)到每個(gè)Ci(i=1,2,…,k)的距離,根據(jù)“就近原則”(到給定參考點(diǎn)最短距離)分配給相應(yīng)的簇;如果不是參考點(diǎn),根據(jù)初始聚類的過程進(jìn)行聚類,實(shí)現(xiàn)新的簇△Ci(i=k+1,k+2,…)。 ③ 根據(jù)定義7,判斷△Ci(i=k+1,k+2,…)中是否存在噪聲點(diǎn),若存在,生成△Oi(i=0,1,…);反之,生成新簇。 ④ 對于其它的增量△vi(i=2,3,…,n),依次循環(huán)執(zhí)行②、③。 ⑤ 結(jié)果輸出聚類簇△Ci(i=1,2,…,k)。 當(dāng)前強(qiáng)化信息化手段在農(nóng)村經(jīng)濟(jì)管理中的應(yīng)用,是農(nóng)村經(jīng)濟(jì)管理現(xiàn)狀的現(xiàn)實(shí)性要求,也是農(nóng)村經(jīng)濟(jì)大繁榮大發(fā)展的必然性選擇,更是農(nóng)村經(jīng)濟(jì)管理者提升自身管理能力和管理水平的工作創(chuàng)新。只有農(nóng)村經(jīng)濟(jì)管理者站在信息化時(shí)代視域推進(jìn)信息化手段與管理工作的高度融合,才能提高農(nóng)村經(jīng)濟(jì)管理工作的水平和效率,從而更好地引導(dǎo)廣大農(nóng)民發(fā)家致富。 2DICURDA算法MapReduce的實(shí)現(xiàn) 設(shè)初始數(shù)據(jù)集V(v1,v2,…,vn),增量數(shù)據(jù)集為△V(△v1,△v2,…,△vn),則ICURD算法MapReduce的實(shí)現(xiàn)如下: ① 將數(shù)據(jù)集V(v1,v2,…,vn)進(jìn)行分割,劃分為p(節(jié)點(diǎn)個(gè)數(shù))塊數(shù)據(jù)子集,并分配給p個(gè)子節(jié)點(diǎn)。 ② 在各個(gè)子節(jié)點(diǎn)中,根據(jù)初始聚類過程計(jì)算出Ci(i=2,3,…,n)。 ③ 在Reduce過程中,根據(jù)定義9,把Ci(i=2,3,…,n)中符合條件的簇進(jìn)行合并;并根據(jù)定義7判斷是否存在噪聲點(diǎn),若存在,則刪除。 ④ 把各個(gè)簇內(nèi)各維坐標(biāo)值累加求均值,結(jié)果輸出Ci′(i = 2,3,…,n)。 ⑥ 在各個(gè)節(jié)點(diǎn)中,根據(jù)增量的聚類過程計(jì)算出△Ci(i=1,2,…,k)。 ⑦ 在Reduce過程中,根據(jù)定義9,把△Ci(i=1,2,…,k)中符合條件的簇進(jìn)行合并;并根據(jù)定義7判斷是否存在噪聲點(diǎn),若存在,則刪除。 ⑧ 把各個(gè)簇內(nèi)各維坐標(biāo)值累計(jì)求均值,結(jié)果輸出。 3實(shí)驗(yàn)結(jié)果分析 3.1實(shí)驗(yàn)平臺、測試數(shù)據(jù)集和評價(jià)指標(biāo) 本文所有實(shí)驗(yàn)環(huán)境搭建的平臺的組成為:2臺2GHz Intel Xeon CPU、2 GB內(nèi)存和4臺2 GHz Intel Xeon CPU、1 GB內(nèi)存的PC構(gòu)成的。操作系統(tǒng)均為Ubuntu Linux 10.10,Hadoop版本選用1.1.2;Java開發(fā)包為JDK1.7版本,程序開發(fā)工具為Eclipse-standard-kepler-SR1-linux,算法使用Java實(shí)現(xiàn)。 實(shí)驗(yàn)數(shù)據(jù)集采用了UCI數(shù)據(jù)集下Synthetic_Control,分別構(gòu)造了原始數(shù)據(jù)集為0.5、1、2、4、8、16 GB與增量為0.1、0.2、0.3、0.4、0.5 GB的60維不同大小的數(shù)據(jù)集來驗(yàn)證算法的可擴(kuò)展性與時(shí)效性。為了驗(yàn)證算法的有效性,通過Iris數(shù)據(jù)集(數(shù)據(jù)對象150,屬性4),Wine(數(shù)據(jù)對象178,屬性13)數(shù)據(jù)集,Libras數(shù)據(jù)集(數(shù)據(jù)對象360,屬性90),Diabetes(數(shù)據(jù)對象768,屬性8)進(jìn)行了實(shí)驗(yàn),同時(shí)利用節(jié)點(diǎn)個(gè)數(shù)的不同驗(yàn)證了算法的可伸縮性。 在實(shí)驗(yàn)中,為了測試DICURDA算法的性能,本文采用了以下評價(jià)指標(biāo):時(shí)效性、可伸縮性和有效性。 3.2實(shí)驗(yàn)結(jié)果 3.2.1DICURDA算法的時(shí)效性 為了驗(yàn)證DICURDA算法在實(shí)際應(yīng)用中的效果,在實(shí)驗(yàn)中,根據(jù)已給定的上述數(shù)據(jù)集,設(shè)原始數(shù)據(jù)集V為:0.5、1、2、4、8、16 GB,則增量數(shù)據(jù)集為△V為(0.1、0.2、0.3、0.4、0.5GB;根據(jù)給定數(shù)據(jù)集中結(jié)果聚類的個(gè)數(shù),設(shè)R=42.25,T=10,D=42.23,則對增量△V利用DBSCAN與DICURDA算法進(jìn)行了比較,如圖4所示。 圖4 DBSCAN算法與DICURDA算法的時(shí)效性對比 從圖4可以看出,在獲得同樣正確的聚類個(gè)數(shù)的條件下,DICURDA算法比DICURDA算法的時(shí)效性高;其主要原因?yàn)椋?)DICURDA算法在進(jìn)行增量的聚類過程中已經(jīng)獲得了參考點(diǎn),節(jié)省計(jì)算每個(gè)點(diǎn)密度的時(shí)間;2)當(dāng)數(shù)據(jù)點(diǎn)不符合增量聚類過程時(shí),重新初始聚類過程的數(shù)據(jù)點(diǎn)是少量的。所以,DICURDA算法的時(shí)效性比DBSCAN算法較高。 3.2.2DICURDA算法的有效性 為了進(jìn)一步驗(yàn)證算法的有效性,文章根據(jù)不同的數(shù)據(jù)集,在已給定正確聚類個(gè)數(shù)的情況下,設(shè)不同類型的數(shù)據(jù)集作為是原始數(shù)據(jù)集與增量數(shù)據(jù)集;根據(jù)不同類型的數(shù)據(jù)集,設(shè)置了不同R、T與D不同的參數(shù)值進(jìn)行了實(shí)驗(yàn),具體如表1、表2所示。 表1 DBSCAN算法運(yùn)行結(jié)果 表2 DICURDA算法運(yùn)行結(jié)果 由表1與表2對比可知,DBSCAN算法參數(shù)設(shè)置比DICURDA算法的參數(shù)少,噪聲點(diǎn)的個(gè)數(shù)也相對于DICURDA算法比較少。然而,DICURDA算法的正確率比較高,運(yùn)行時(shí)間快;其主要原因?yàn)椋?)DICURDA算法參數(shù)設(shè)置降低了云計(jì)算過程中由于數(shù)據(jù)分片不均勻?qū)е路诸愬e(cuò)誤的概率;2)在云計(jì)算動態(tài)的增量聚類規(guī)約過程中,參數(shù)D提高聚類的效率與精度;3)DICURDA算法的初始過程為下面的動態(tài)聚類提供了參考點(diǎn),同時(shí)降低了增量聚類參數(shù)的敏感性。 3.2.3DICURDA算法的可伸縮性 為了更一步測試DICURDA算法的性能,算法采用原始數(shù)據(jù)集分別測試了不同節(jié)點(diǎn)下算法的運(yùn)行時(shí)間,進(jìn)一步驗(yàn)證了算法的可伸縮性,具體如圖5所示。 圖5 DICURDA算法的可伸縮性 從圖5可以發(fā)現(xiàn),算法的時(shí)效性不僅與數(shù)據(jù)集的大小有關(guān),而且還與實(shí)驗(yàn)平臺的數(shù)據(jù)節(jié)點(diǎn)密切系相關(guān)。當(dāng)數(shù)據(jù)節(jié)點(diǎn)較少時(shí),時(shí)效性呈現(xiàn)出線性變化的特點(diǎn);當(dāng)隨著數(shù)據(jù)節(jié)點(diǎn)的不斷增多,算法的執(zhí)行效率變化越快。同時(shí)證明,該算法適合于大數(shù)據(jù)的處理。 3.2.4聚類效果比較 DICURD算法的參數(shù)R、D與T與DBSCAN算法的參數(shù)R與T有著相似的特點(diǎn),并具有該算法的優(yōu)越性;并且DICURD算法雖然初始參數(shù)同樣難以確定。但是,對于DICURD算法來講,一旦初始參數(shù)決定在以后的增量聚類過程中,則降低了參數(shù)的敏感性。同時(shí)該算法是一個(gè)不斷的學(xué)習(xí)過程,對未知樣本的分析提高了精度,具有接近線性的時(shí)間復(fù)雜性,能夠動態(tài)地處理產(chǎn)生的新數(shù)據(jù),并保持了前后聚類結(jié)果的一致性。整體來講,DICURD算法優(yōu)于DBSCAN算法。 4結(jié)語 DICURDA算法是基于密度的一種算法。本文利用云計(jì)算平臺實(shí)現(xiàn)了DICURDA算法,無需保留原始數(shù)據(jù)就可以在增量過程中進(jìn)行數(shù)據(jù)挖掘,節(jié)省了時(shí)間。本文從時(shí)效性、有效性與可伸縮性等不同角度分析了該算法可行性。然而,由于在初始聚類過程中仍然需要輸入?yún)?shù),所以,對于參數(shù)的設(shè)定仍需要進(jìn)一步研究。 參考文獻(xiàn) [1] 楊靜,高嘉偉,梁吉業(yè).基于數(shù)據(jù)場的改進(jìn)DBSCAN聚類算法[J].計(jì)算機(jī)科學(xué)與探索,2012,51(6):903-911. [2] Loh W K,Moon Y S.Fast Density-Based Clustering Using Graphics Processing Units[J].Ieice Transactions on Information and Systems,2014,97(7):1349-1352. [3] Wu Minghui,Zhang Hongxi,Jing Canghon.Cluster Algorithm Based on Edge Density Distance[J].Computer Science,2014,24(6),245-249. [4] Li Hui Pi Dechang,Jiang Min.An incremen tal density clustering algorithm for cha otic time series[J].International Journal of Applied Mathematics and Statistics,2013,47(4):380-389. [5] 孟靜,吳錫生.一種基于聚類和快速計(jì)算的異常數(shù)據(jù)挖掘算法[J].計(jì)算機(jī)工程,2013(8):60-63,68. [6] Singh Sumeet Awekar,Amit.Incremental shared nearest neighbor density-based clustering[C]//International Conference on Information and Knowledge Management,Proceedings.San Francisco,CA,United states.2013,31(2):1533-1536. [7] Li Lingjuan,Xi Yang.Research on clustering algorithm and its parallelization strategy[C]//Proceedings-2011 International Conference on Computational and Information Sciences.Chengdu,Sichuan,China.2011,5(2):325-328. [8] 郗洋.基于云計(jì)算的并行聚類算法研究[D].南京郵電大學(xué),2011. [9] 虞倩倩.基于數(shù)據(jù)劃分的DBSCAN算法研究[D].江南大學(xué),2013. [10] Xie YongHong,Ma Ya Hui,Zhou Fang.PDBSCAN:Parallel DBSCAN for Large-Scale Clustering Applications[J].Journal of Donghua University (English Edition),2012,7(4):76-79. [11] Fu Xiufen,Hu Shanshan.Research of parallel DBSCAN clustering algorithm based on Map Reduce[J].International Journal of Database Theory and Application,2014,7(2):41-48. [12] Dai BiRu,Lin IChang.Efficient map/reduce-based DBSCAN algorithm with optimized data partition[C]//Proceedings 2012 IEEE 5th International Conference on Cloud Computing,CLOUD 2012.Honolulu,HI,United states.2012,4(2):59-66. [13] Kim Y,Shim K,Kim M S.DBCURE-MR:An efficient density-based clustering algorithm for large data using MapReduce[J].Information Systems,2014,12(4):15-35. [14] He Y B,Tan H Y,Luo W M.MR-DBSCAN:a scalable MapReduce-based DBSCAN algorithm for heavily skewed data[J].Frontier Sof Computer Science,2014,32(8):83-89. [15] Fu XiuFeng,Wang Yaguang.Research andapplication of DBSCAN algorithm based on Hadoop platform[J].Lecture Notes in Computer Science,2014,83(5):73-87. [16] Goyal Navneet Goyal Poonam,Mohta Mayank P.A multi-purpose density based clustering framework[J].Communications in Computer and Information Science,2011,168(3):538-540. RESEARCH ON DYNAMIC AND INCREMENTAL DENSITY ALGORITHM BASED ON CLOUD COMPUTING PLATFORM Meng HaidongRen Jingpei (School of Information Engineering,Inner Mongolia University of Science and Technology,Baotou 014010,Inner Mongolia,China) AbstractFor the problem of traditional density clustering algorithm that it is highly time complex and is not suitable for processing dynamic data when processing massive data,we proposed a density algorithm which uses reference points and MapReduce model for dynamic and incremental clustering.The creativity of it relies on that the algorithm realises a clustering algorithm capable of processing massive dynamic data,it guarantees the consistency of incremental clustering and re-clustering results,and has the characteristic of scalability as well.Experimental results demonstrated that the algorithm decreased the sensitivity of the parameter,improved the clustering efficiency and resource utilisation of density algorithm,and was suitable for big data analysis. KeywordsReference pointsIncremental clusteringMapReduceDynamic density algorithm 收稿日期:2014-12-11。內(nèi)蒙古自然科學(xué)基金項(xiàng)目(2012MS0611)。孟海東,教授,主研領(lǐng)域:數(shù)據(jù)挖掘技術(shù),礦業(yè)系統(tǒng)工程。任敬佩,碩士生。 中圖分類號TP311 文獻(xiàn)標(biāo)識碼A DOI:10.3969/j.issn.1000-386x.2016.06.004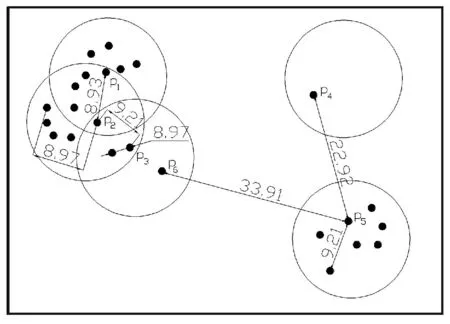

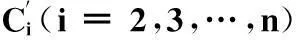


 猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年3期)2021-06-09 06:09:14中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:38中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年2期)2021-03-19 08:54:04海峽姐妹(2020年9期)2021-01-04 01:35:44華人時(shí)刊(2020年13期)2020-09-25 08:21:32VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26山東青年(2016年1期)2016-02-28 14:25:25汽車維護(hù)與修理(2015年6期)2015-02-28 12:16:55當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年3期)2021-06-09 06:09:14中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:38中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年2期)2021-03-19 08:54:04海峽姐妹(2020年9期)2021-01-04 01:35:44華人時(shí)刊(2020年13期)2020-09-25 08:21:32VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26山東青年(2016年1期)2016-02-28 14:25:25汽車維護(hù)與修理(2015年6期)2015-02-28 12:16:55當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
