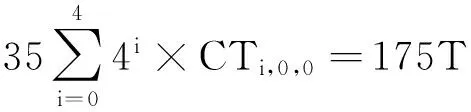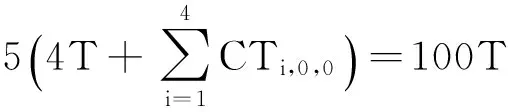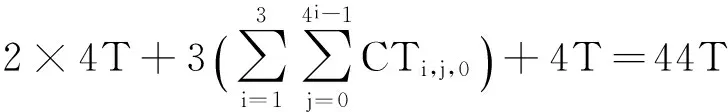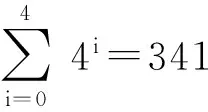多層次細粒度并行HEVC幀內模式選擇算法
2016-06-30 07:33:21馬宜科張勇東
計算機研究與發展 2016年4期
張 峻 代 鋒 馬宜科 張勇東
1(中國科學院智能信息處理重點實驗室 (中國科學院計算技術研究所) 北京 100190)2(中國科學院大學 北京 100049) (zhangjun01@ict.ac.cn)
多層次細粒度并行HEVC幀內模式選擇算法
張峻1,2代鋒1馬宜科1張勇東1
1(中國科學院智能信息處理重點實驗室 (中國科學院計算技術研究所)北京100190)2(中國科學院大學北京100049) (zhangjun01@ict.ac.cn)
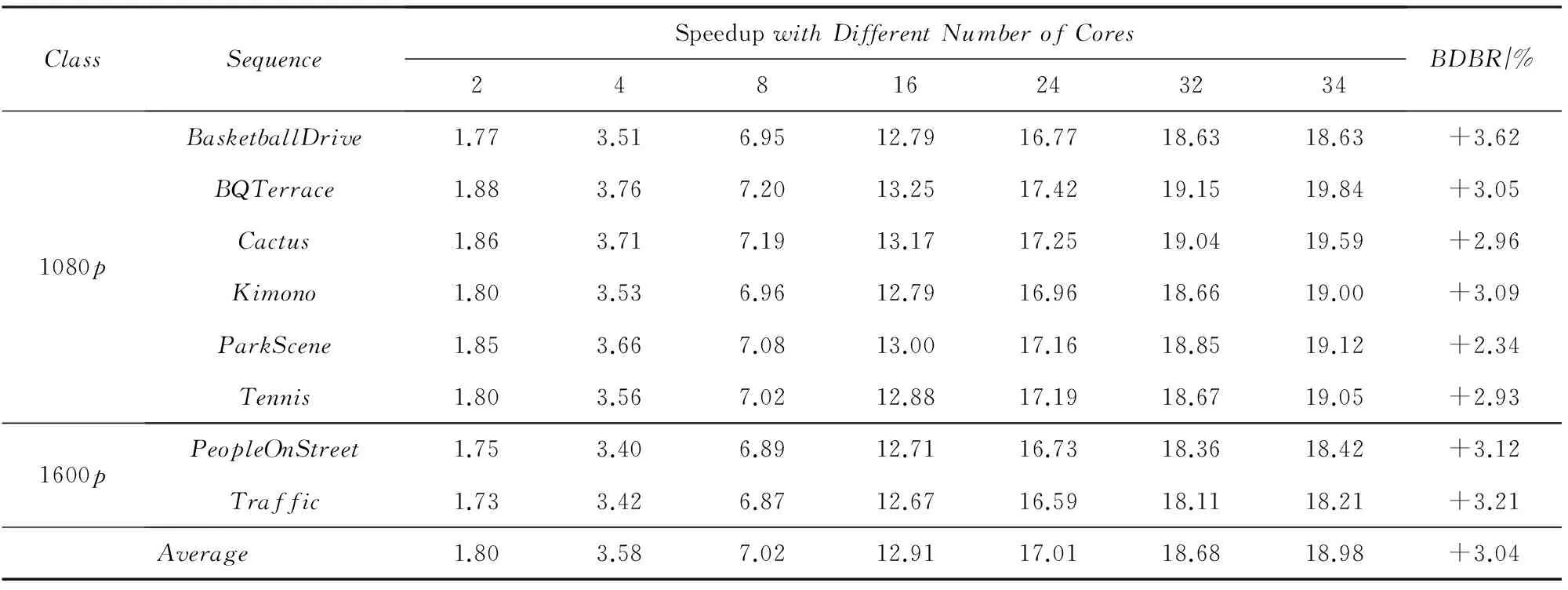
摘要在眾核平臺上并行加速是解決高效視頻編碼(high efficiency video coding, HEVC)標準編碼復雜度高的有效方法.傳統的粗粒度并行方案如Tiles和WPP未能在并行度和編碼質量之間取得較好的平衡,對編碼質量影響較大或者并行度不高.充分挖掘HEVC幀內模式選擇中的并行性,提出了一種在CTU內使用的多層次細粒度的幀內模式選擇算法.具體說來,對幀內模式選擇過程進行了子任務劃分,分析并消除了相鄰編碼塊之間多種阻礙并行計算的數據依賴關系,包括幀內預測參考像素依賴、預測模式依賴和熵編碼依賴等,實現了同一個CTU內所有層次的細粒度編碼塊的代價計算和模式選擇并行進行.將算法在Tile-Gx36平臺上實現,實驗結果表明此并行算法與HEVC參考代碼HM相比能獲得18倍的整體編碼加速比而且編碼質量損失較小(碼率上升3%).
關鍵詞高效視頻編碼;幀內預測;眾核;并行模式選擇;細粒度
高效視頻編碼(highefficiencyvideocoding,HEVC)[1-2]標準的壓縮效率超越以往所有標準,比目前最流行的H.264AVC提高1倍.雖然HEVC仍然屬于基于塊的混合編碼框架,但是其各個編碼階段都有了增強和改進,其中最重要的變化就是采用了更加靈活的編碼結構和高級的編碼工具,這也導致HEVC的編碼模式搜索空間非常大.為了保證編碼質量,編碼器要進行大量的計算以尋找率失真代價較小的編碼模式,即模式選擇(modedecision,MD),編碼復雜度非常高.隨著多核和眾核處理器的發展[3],在并行計算平臺上并行化HEVC編碼將是滿足其計算能力需求實現實時編碼的有效手段[4-12].與以往所有標準不同,HEVC標準本身就采納了多種便于并行編解碼的工具,如WPP(wavefrontparallelprocessing)[9],Tiles[10],MER(motionestimationregion)[11],可見并行計算對于HEVC及今后視頻編碼領域的重要性.
目前HEVC并行相關的研究工作主要集中于計算量較大的幀間MD尤其是運動估計(motionestimation,ME)模塊[7-8,11],對幀內MD并行的研究則相對較少.隨著幀間MD的并行化,幀內MD逐漸成為了速度瓶頸.在文獻[13]中,在幀間MD被加速了近15倍之后,I幀的平均編碼時間大大超過了PB幀的平均編碼時間,是其4~5倍,限制了編碼器的整體效率,因此對幀內MD的并行加速同樣重要.
現有的對HEVC幀內MD并行的研究較少,而且算法的并行度不夠高[14-16],HEVC標準支持的Tiles和WPP也未能在并行度和編碼質量取得較好的平衡.針對這些問題,本文提出了一種在編碼樹單元(codingtreeunit,CTU)內使用的并行幀內MD算法:本文對幀內MD過程進行了子任務劃分,深入分析并解除了各個子任務在相鄰編碼塊之間存在的數據依賴性,包括幀內預測參考像素依賴、PU預測模式依賴、熵編碼概率模型依賴和概率建模依賴,實現了每個子任務對整個CTU里面多層次細粒度的編碼塊并行處理,最終實現了CTU內并行幀內MD.
1背景及研究現狀
本節介紹與本文工作相關的一些背景.首先介紹HEVC幀內模式選擇基本概念,然后對已有的一些并行幀內模式選擇算法進行了介紹和分析.
1.1HEVC幀內模式選擇
在HEVC編碼標準中,一幀視頻圖像被均勻地劃分成CTU,CTU的大小可以為64×64,32×32或16×16,典型且不失一般性,本文以下默認CTU大小為64×64.如圖1所示,每一個CTU四叉樹遞歸地劃分為4個相同大小的子單元,該四叉樹的每一個葉子節點叫作一個編碼單元(codingunit,CU);每個CU也會采用四叉樹遞歸劃分,每一個葉子節點叫作變換單元(transformunit,TU).此外,從圖1可見,每個CU有多種預測單元(predictionunit,PU)劃分模式,能更靈活地進行預測編碼.HEVC的幀內預測模式也比H.264復雜很多,共35種模式.CTU,CU,PU,TU包含的單一亮度或色度分量信息分別記為CTB(codingtreeblock),CB(codingblock),PB(predictionblock),TB(transformblock).
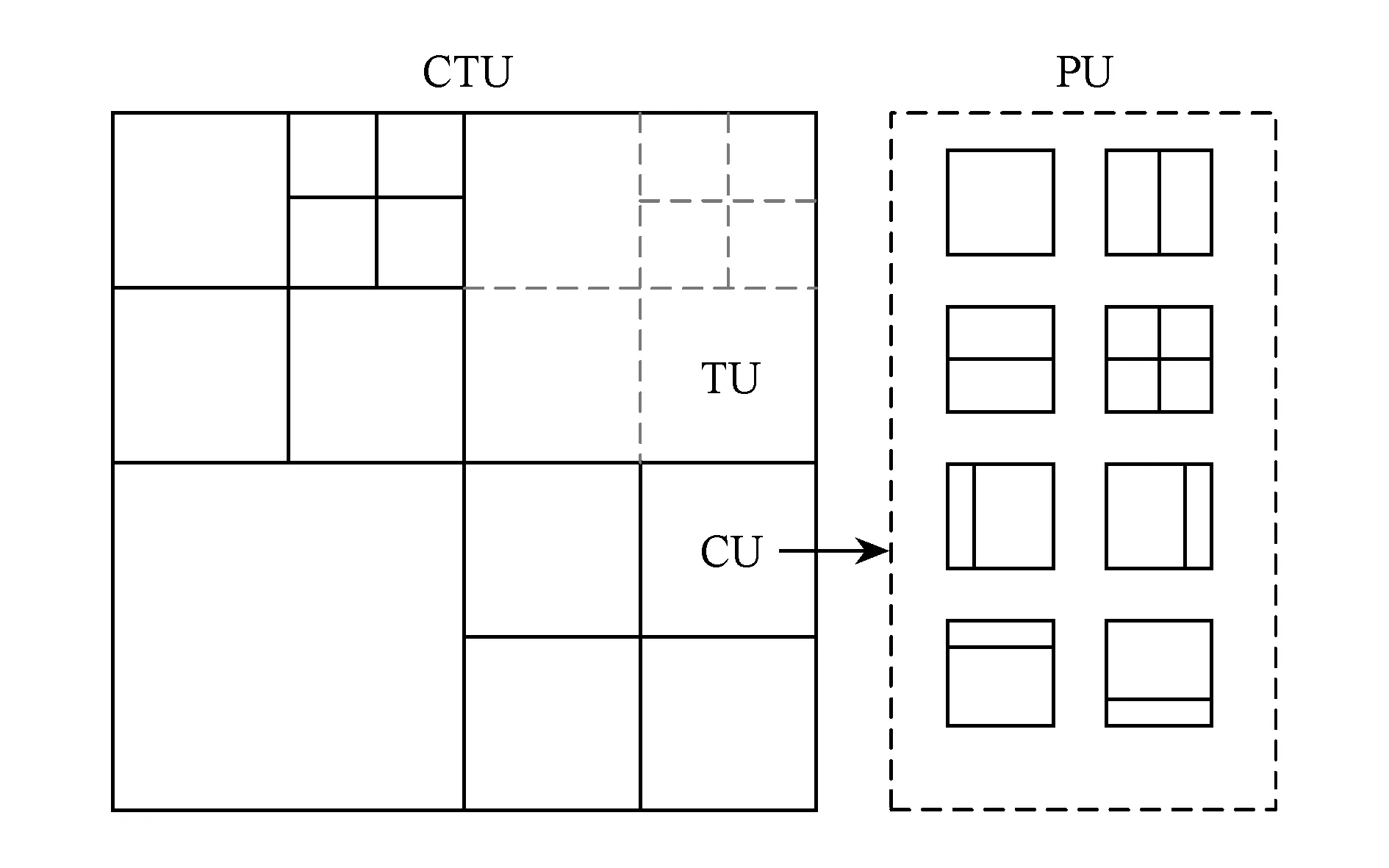
Fig. 1 Flexible coding structures in HEVC.圖1 HEVC標準中靈活的編碼結構
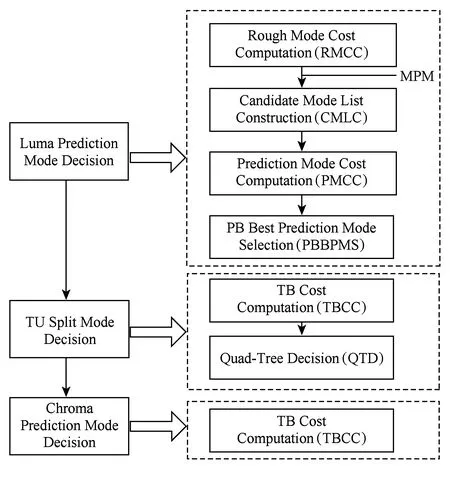
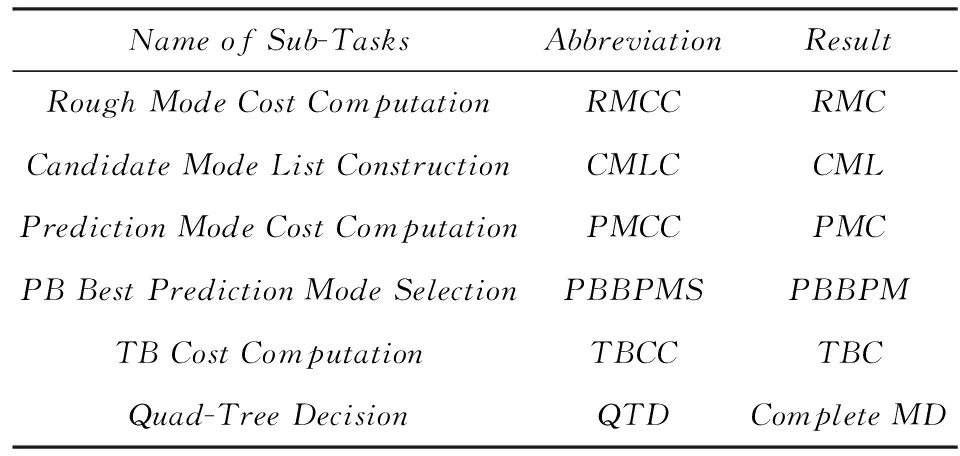
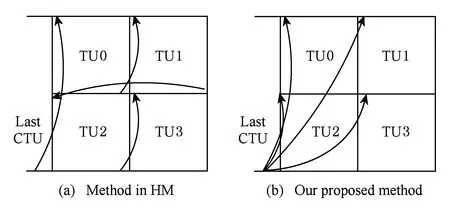
在HEVC幀內MD過程中,對于一個CTU來說,它可以采用四叉樹遞歸劃分的方式劃分出更小的CU,最小為8×8.對于8×8CU有2N×2N和N×N兩種PU劃分方式,其他CU只有2N×2N的PU劃分.N×N劃分情況下包含4個亮度PB和1個色度PB,2N×2N劃分時包含1個亮度PB和1個色度PB,每個PB有一個預測模式.對一個幀內編碼CU來說,色度PB和亮度PB的預測模式可以是不同的,TU劃分模式對亮度和色度是相同的,因此一個幀內編碼CU的模式可由亮度PB預測模式、色度PB預測模式和TU劃分模式來表征,如式(1)所示.幀內MD即對CTU里面的每個CU從式(1)所表示的模式空間中尋找率失真代價最小的模式組合,并且據此決策出整個CTU的最佳CU四叉樹劃分方式.在HEVC的參考軟件HM中,一個CTU里面CU的MD計算是按深度優先遍歷順序進行的,如圖2所示,為簡便起見只畫了3層,每個節點表示一個CU.
CU模式(亮度PB預測模式,色度PB預測模式,

(1)
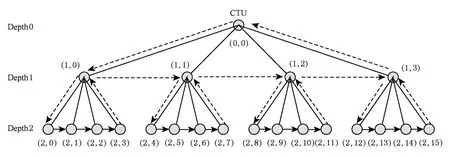
Fig. 2 Depth-first serial processing order of CUs in a CTU of HM.圖2 HM中一個CTU里CU的深度優先串行處理順序
1.2相關研究工作
由于采用了靈活的編碼結構和復雜的預測模式,幀內MD計算量非常大.為了加快幀內MD,許多研究工作[17-19]提出了快速算法.快速算法能在一定程度上減小計算復雜度,但是獲得的加速比有限,距離實時編碼仍然有很大的差距.
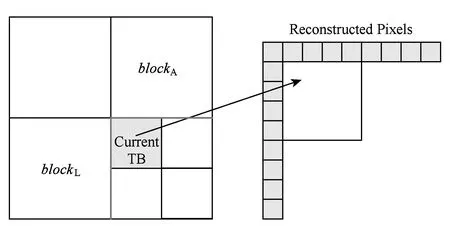
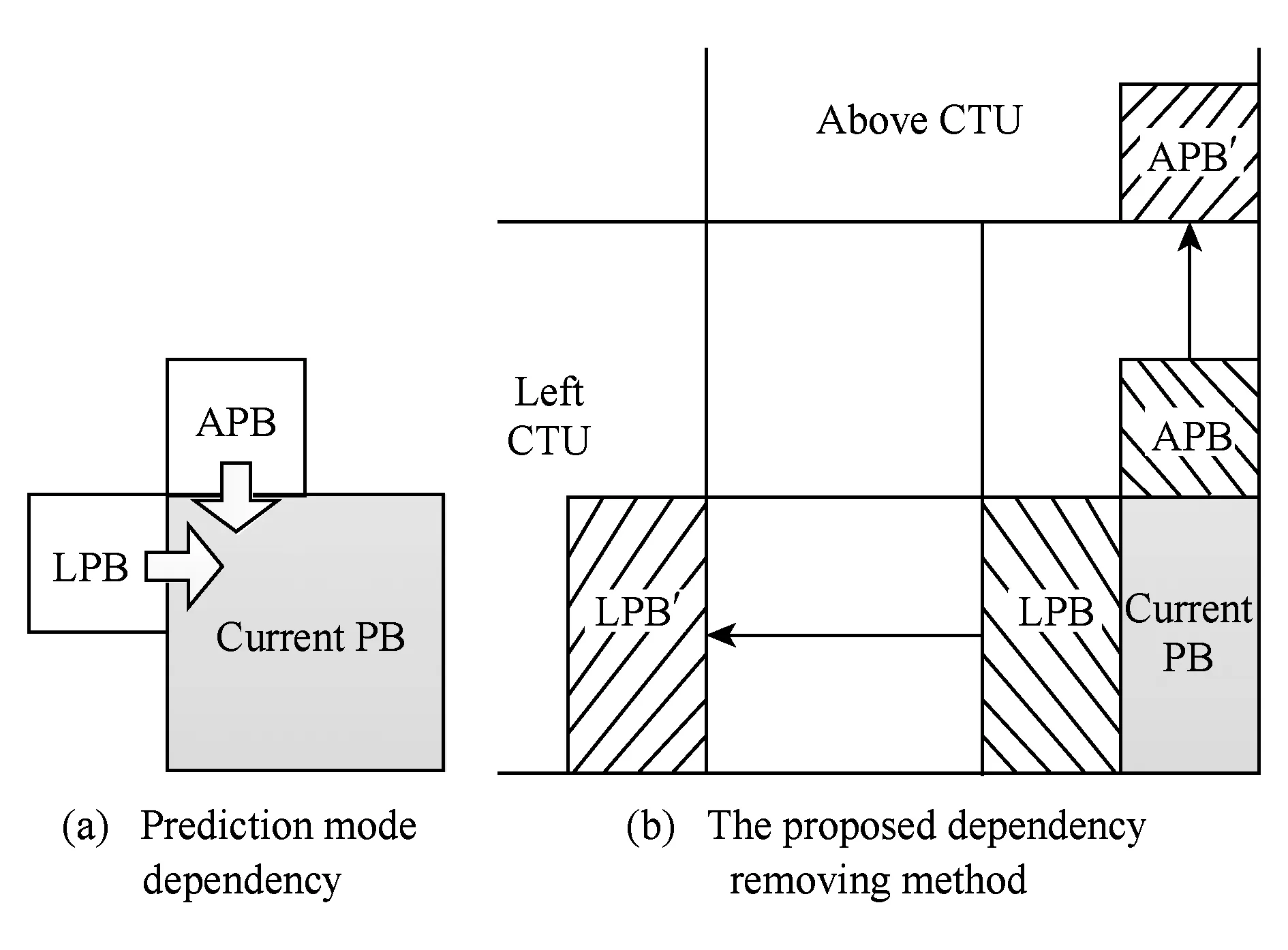
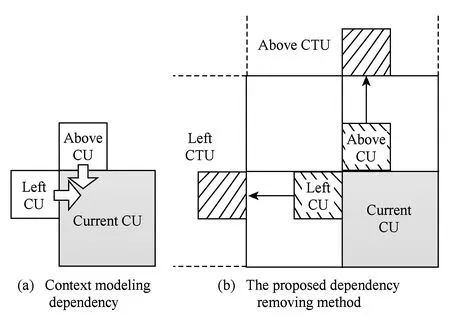
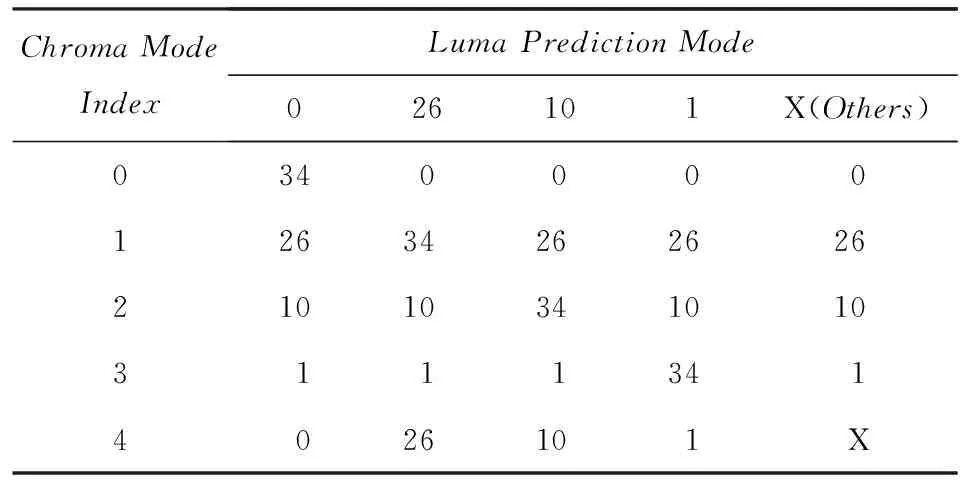
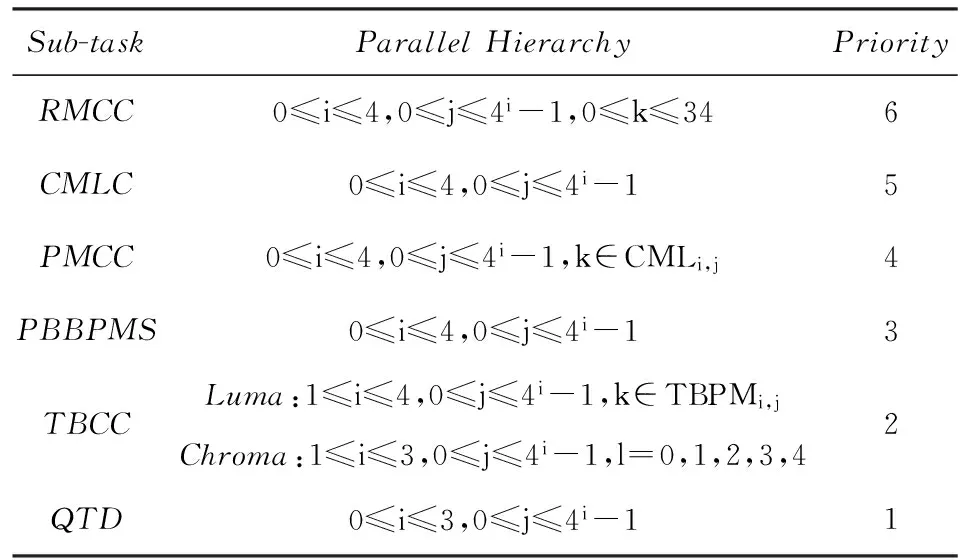
并行計算是提高HEVC編碼速度的有效手段,標準本身采納了幾種粗粒度的并行化工具.Tiles將一幀圖像縱橫劃分成若干可以獨立進行編碼的子圖像,子圖像之間無依賴關系,所以可以并行處理.Tiles劃分對并行編碼比較容易實現且并行度比較靈活,缺點是對編碼效率影響較大,經測試[20],將1080p的視頻均勻劃分成6×3的Tiles用于幀內MD,在intra_main配置下實際平均加速比為12,BDBR[21]達到5%左右.HEVC采用的另一種并行方案為WPP,由于其盡可能地保持了數據依賴關系,所以對編碼質量影響較小,但是并行度卻不高.對一個寬度為W個CTU、高度為H個CTU的視頻幀來說,如果滿足條件2(H-α-1) (2) 對于720p和1080p的視頻序列滿足α=2,所以1080p的視頻TPD只能到8[22]. 在另外一些并行幀內MD的研究中,文獻[14-15]都使用前向無環圖描述CTU之間的依賴關系,實現了CTU之間的并行處理,但本質仍屬于WPP,文獻[14]平均獲得了5倍的加速比,文獻[15]則使用分類器決策出最佳CTU的大小,通過較小的CTU大小能獲得較高的加速比,平均達到10倍.在文獻[16]中,該文作者提出了一種在TU四叉樹劃分時4個子節點并行幀內預測的算法,但是由于幀內預測仍依賴于重構像素,理論并行度只能達到4. 從以上內容可以看出,現有的幀內MD并行算法主要是粗粒度并行(Tiles,WPP),文獻[16]屬于細粒度并行但是并行度不高.針對它們存在的問題,本文提出了一種在CTU內使用的多層次細粒度的并行幀內MD算法,在保證編碼質量的前提下獲得了更高的并行度.多層次體現在不同深度的CU,PU,TU可以并行處理,細粒度則體現在最小計算單元為一個TB. 2多層次細粒度并行幀內模式選擇 本節提出了一種在CTU內使用的多層次細粒度并行幀內MD算法.本文首先對CU幀內MD過程進行了子任務劃分,深入分析并解除了各個子任務在相鄰CU,PU,TU間存在的數據依賴關系,實現了各個子任務在整個CTU范圍的并行處理,最終實現了各個層次的所有CU并行模式選擇. 2.1子任務劃分 對于一個CU的模式選擇,為了減小計算量,HM對式(1)表示的模式空間的搜索分階段進行,先選擇亮度PB預測模式,然后選擇TU劃分模式,再選擇色度PB的預測模式,如圖3所示. Fig. 3 The flowchart of intra MD for a CU in HM encoder.圖3 HM編碼器中對一個CU的幀內MD流程圖 對于亮度PB預測模式選擇,先對所有35種模式進行代價粗算(roughmodecostcomputation,RMCC),代價記作RMC,包括PB預測值與原始值之間的殘差變換絕對值(sumofabsolutetransformeddifferences,SATD)和預測模式編碼位數,從中選擇一定數量RMC最小的預測模式,與當前PB的最可能預測模式(mostprobablemode,MPM)一起構造候選模式列表(candidatemodelistconstruction,CMLC),記作CML,對CML里的每一個模式都去計算率失真代價(predictionmodecostcomputation,PMCC),代價記作PMC,選擇PMC最小的預測模式作為當前PB的最佳預測模式(PBbestpredictionmodeselection,PBBPMS),記作PBBPM.然后對TU劃分模式進行決策,主要計算量是亮度TB的率失真代價計算(TBcostcomputation,TBCC),代價記作TBC,使用TBC進行TU四叉樹決策(quad-treedecision,QTD).最后選擇色度預測模式,主要計算是色度TB的TBCC計算.為便于后續引用,在表1對上述子任務以及相應的計算結果進行了歸納. Table 1 Sub-Tasks and Their Output Results 如圖2所示,在串行幀內MD時,由于CU的MD計算是按照深度優先遍歷順序去串行進行的,所以對于表1中的每個子任務,在串行MD時它們在CTU范圍內的執行路徑也是按四叉樹深度優先遍歷順序去進行的.本文提出的并行算法將每個子任務在CTU范圍內進行多層次細粒度的并行,每個子任務都能并行處理一個CTU里面的所有CU,PU或TU,即并行處理四叉樹中的所有節點,一個節點對于不同的子任務表示一個CU,PU或TU. 2.2數據依賴性分析與消除 對于每個子任務,要在一個CTU范圍內進行并行MD計算,而相鄰塊之間有多種數據依賴關系,這些數據依賴會阻礙子任務在CTU范圍內的并行計算.經過本文的分析,有4種數據依賴需要解除: 1) 幀內預測時重構像素依賴.此依賴關系出現在幀內預測時,如圖4所示,在一個PB或TB進行代價計算時,需要進行幀內預測,即參考相鄰塊已經重構出來的像素對自身進行預測.對于一個M×M的TB來說,需要參考周圍的4M+1個重構像素,分別來自于其左、上、左下、右上和左上方向已經編碼重構完成的相鄰圖像區域. Fig. 4 Reconstructed pixels dependencies during intra prediction.圖4 幀內預測時重構像素依賴 在本文的并行算法中,RMCC,PMCC,TBCC在一個CTU里面要對所有PB或TB并行進行代價計算,需要進行幀內預測,如果一個PB或TB要參考的重構像素跟它位于同一個CTU,那么重構像素是不可用的,因為相鄰塊也同時在進行模式選擇,并未重構完成.如圖4所示,blockL,blockA和當前塊位于同一個CTU進行并行處理,那么當前塊所依賴的blockL和blockA的重構像素不可用.要想并行計算,幀內預測參考像素的依賴關系必須要解除. 為了解除這種相關性,本文提出使用原始像素代替重構像素進行幀內預測.為了更準確地模擬實際的編碼過程,在對一個PB或TB進行參考像素構造的過程中,雖然所有原始像素都是可用的,但依然按照標準遵循Z掃描順序來決定某一個像素是不是可用,對于不可用的像素則調用替換(substitution)過程去生成.另外,對參考像素的濾波操作也同樣按照標準進行.由于原始像素是始終可用的,相鄰PB或TB之間不會再有重構像素的依賴問題,所以同一個CTU里面所有PB和TB都可以并行地進行幀內預測. 2) 編碼預測模式時MPM計算依賴.為了提高壓縮效率,HEVC在編碼幀內預測模式時需要參考相鄰(左邊和上邊)PB的預測模式,構造出一個長度固定為3的MPM列表,如圖5(a)所示.如果左PB(leftPB,LPB)和上PB(abovePB,APB)的預測模式不可用或者相同,則還會加入DC、planar、垂直、水平等模式.令(xc,yc)表示當前PB的左上角在當前圖像幀中的坐標,LPB定義為覆蓋點L(xc-1,yc)的PB,APB定義為覆蓋點A(xc,yc-1)的PB. Fig. 5 Prediction mode dependency among adjacent PUs and the proposed dependency removing method.圖5 相鄰PU預測模式依賴和本文提出的依賴性消除方法 在本文的并行算法中,RMCC,CMLC,PMCC要對CTU內所有PB并行地進行MPM計算,如果當前PB與參考的LPB或APB位于同一個CTU里面,即如式(3)所示,其中(xn,yn)對于LPB或APB分別為(xc-1,yc)或(xc,yc-1),那么LPB和APB的預測模式是不可用的,因為它們也同時在進行模式選擇,預測模式還未得到. 為了解除此依賴關系,如果當前PB和LPB或APB位于同一個CTU,那么本文使用已經編碼過的CTU里面距離LPB和APB最近的對應PB來代替它,記作LPB′和APB′,如圖5(b)所示,用LPB′和APB′的預測模式代替LPB和APB的預測模式去構造MPM.LPB′定義為覆蓋點L′(xc-xc% 64-1,yc)的PB,APB′定義為覆蓋點A′(xc,yc-yc% 64-1)的PB,其中“%”表示取余運算,64表示CTU大小.由于CTU是按照掃描順序進行編碼的,所以左CTU和上CTU里面的信息一定是可以使用的,這樣,同一個CTU里面PU的預測模式依賴關系就被解除了,可以并行進行預測以及代價計算: (3) 3) 概率模型(contextmodel,CM)繼承依賴.HEVC中使用上下文自適應的二進制算術編碼(contextadaptivebinaryarithmeticcoding,CABAC)進行語法元素的熵編碼.CABAC的主要過程包括語法元素的二進制化、概率建模、算術編碼和CM更新.為了提高編碼效率,在編碼的過程中CM會自適應動態更新,以更好地反映圖像的局部區域特性,獲得更高的壓縮比.在HM模式選擇過程中,熵編碼器會使用CM去估計編碼產生的位數以計算編碼代價,CM是模擬實際編碼過程動態更新的,Z掃描順序更小的塊的MD完成之后會將CM傳遞給Z掃描順序大于它的塊使用,如圖6(a)所示,TU1使用的CM是TU0計算之后的結果,這樣就在相鄰塊之間產生了CM的繼承依賴. Fig. 6 CMs inheritance in HM and our proposed method.圖6 HM中的CM繼承依賴和本文提出的方法 在本文的并行算法中,RMCC,PMCC,TBCC,QTD任務要并行地對一個CTU內的所有CU,PU或TU進行代價計算,而由于相鄰CU,PU,TU之間存在CM的繼承依賴問題而導致無法并行,要想實現并行代價計算,必須要解決此依賴關系. 為了解除同一個CTU內CM繼承依賴,本文提出以下解決方法:同一個CTU內的所有CUPUTU使用同一套CM,該CM來自于上一個已編碼的CTU經過訓練之后的結果.如圖6(b)所示,為了簡潔,一個CTU內只畫出4個TU.通過這種CM繼承方式,一個CTU里面所有的CUPUTU都有了自己的CM,所以可以并行處理. Fig. 7 Coding depth dependency among adjacent CUs and our proposed dependency removing method.圖7 CU之間依賴和提出的依賴性消除方法 4) 概率建模依賴.為了提高編碼效率,CABAC編碼二進制符號(binarysymbol,bin)時需要進行概率模型選擇(也叫概率建模),概率模型即當前bin是01的概率,概率建模即從可選的概率模型里選擇出最能反映當前bin概率估計的模型.為了能得到較精確的概率估計,概率建模會依賴于當前bin序號、編碼深度、色度或亮度、周圍編碼信息等.HEVC在編碼語法元素split_cu_flag時,會根據當前CU的深度和其左CU、上CU的劃分深度進行概率模型選擇,如圖7(a)所示.假設左CU編碼深度為depthL,上CU編碼深度為depthA,當前CU的深度為depth,那么當前CU的split_cu_flag的概率模型序號如式(4)所示,其中“>”為邏輯運算符.cu_skip_flag的概率建模與此類似.在本文的并行算法中,QTD要對CTU內所有CU并行地進行代價計算和模式選擇,由于相鄰CU之間在概率建模時有編碼模式依賴,所以要并行處理,這種依賴關系必須要解除.為了解除此類數據依賴性,本文采用和解除MPM計算依賴性類似的方法,即如果參考的CU和當前CU位于同一個CTU,則使用已編碼的相鄰CTU中的對應CU來代替它,如圖7(b)所示.另外,TB的語法元素cbf在概率建模時會依賴當前TB在CU中的劃分深度信息,但是在本文的算法中,整個CTU里面的所有TB會并行計算代價TBCC,并無CU概念,所以TB在CU中的深度無法得到.對于這個依賴關系,本文的解決方法是:對于4×4的TB,深度設置為1,其他TB的深度設置為0. (4) 以上對阻礙并行計算的多種數據依賴關系進行了分析和消除.需要注意的是本文提出的數據依賴性消除算法只在模式選擇階段使用,為了保證編碼結果符合標準且保證編碼質量,當一個CTU的模式選擇完成之后,即確定了CU劃分方式、PU劃分方式、PU預測模式和TU劃分方式之后,在進行實際熵編碼的過程中需要對量化系數和預測模式編碼進行修正,即按照標準規定去參考相鄰塊的重構像素進行幀內預測,對殘差重新進行變換和量化得到量化系數,MPM的構造也按標準規定參考相鄰的PB,CABAC的概率模型繼承和概率建模也按標準規定進行.這個修正的過程是需要串行計算的. 2.3并行策略 在解除了以上多種數據依賴關系之后,下面給出本文提出的多層次細粒度并行算法的并行策略,為了便于表達,進行如下符號定義: CU,PU,TU分別表示在一個CTU里面的編碼單元、預測單元、變換單元;CB,PB,TB分別表示一個CU,PU,TU包含的亮度或色度分量塊;depthi表示當前單元(CU,PU,TU)或分量塊(CB,PB,TB)相對于CTU的四叉樹劃分深度,其中0≤i≤4;zorderj表示第depthi層深度的某一個單元的Z掃描順序序號,其中0≤j≤4i-1;modek表示一個幀內預測模式,其中0≤k≤34. 對表1中的各子任務,分別在CTU內進行如下數據級劃分和并行: 1)RMCC.對于亮度PB的RMCC任務,主要工作是計算PB的幀內預測和SATD的計算.本文提出的并行策略:一個CTU里面所有的亮度PB的所有預測模式都并行進行RMCC,表示為RMCi,j,k=RMCC(PB(depthi,zorderj),modek),其中0≤i≤4,0≤j≤4i-1,0≤k≤34,i,j,k并行. 2)CMLC.在一個亮度PB的RMCC完成之后,需要從中選出一定數量RMC最小的模式,然后與當前PB的MPM一起組成該PB的候選模式列表CML.本文提出的并行策略:CTU內所有亮度PB并行進行CMLC操作,表示為CMLi,j=CMLC(PB(depthi,zorderj)),其中0≤i≤4,0≤j≤4i-1,i,j并行. 3)PMCC.當一個亮度PB的CML構造之后,要從中選出一個最好的模式作為當前PB的預測模式.當前PB在其CML里面的每一個模式都計算出一個率失真代價PMC,為了減少計算量,只有64×64的PB進行一層TB劃分,其他的PB都直接作為一個TB計算.本文提出的并行策略:CTU里面所有的PB在其CML里面的所有模式并行,表示為PMCi,j,k=PMCC(PB(depthi,zorderj),modek),0≤i≤4,0≤j≤4i-1,k∈CMLi,j,i,j,k并行,其中對于PB(depth0,zorder0),劃分為4個子塊并行計算. 4)PBBPMS.當一個亮度PB的PMC計算完成之后,需要從中選擇最小PMC對應的預測模式作為PB的最終預測模式,記為PBBPM.本文提出的并行策略:CTU內所有亮度PB并行進行PBBPMS操作,記為PBBPMi,j=PBBPMS(PB(depthi,zorderj)),0≤i≤4,0≤j≤4i-1,i,j并行. 5)TBCC.選出亮度PB最佳預測模式之后,需要決策每個CU的最佳TU劃分,因此要計算一個CU所包含的所有TB的率失真代價.本文提出的并行策略:整個CTU里面所有TB并行地進行率失真代價TBC計算,表示為TBCi,j,k=TBCC(TB(depthi,zorderj),modek),由于亮度TB最大為32,所以1≤i≤4,0≤j≤4i-1,k∈TBPMi,j,i,j,k并行,其中TBPMi,j表示TB(depthi,zorderj)所需計算的預測模式.由于本文使用原始像素取代重構像素來進行幀內預測,所以任何一個TB對于同一個預測模式其預測值是完全相同的.因為同一個TB可能會被多個PB同時覆蓋,所以同一個TB在一個模式下只需要計算一次即可,減少了計算量.假如最大TU劃分層次為3層,那么TB(depthi,zorderj)會被PB(depthi,zorderj),PB(depthi-1,zorder)和PB(depthi-2,zorder)同時覆蓋,故TBPMi,j是它們最佳模式的并集,即: TBPMi,j={PBBPMi,j,PBBPM,PBBPM}. (5) 對于色度PB的預測模式選擇,色度PB在亮度PB預測模式一定的情況下有5種預測模式需要計算,如表2所示.本文直接將這5種模式全部并行計 Table2TheRelationshipofPredictionModeBetweenLuma andChromaComponentsinaCU 表2 色度分量預測模式與亮度分量預測模式的對應關系 算:TBCi,j,l=TBCC(TB(depthi,zorderj),model),其中1≤i≤3,0≤j≤4i-1,l=0,1,2,3,4,model表示需要計算的預測模式,i,j,l并行. 6)QTD.此任務的主要工作是根據前面所述任務的計算結果,決策出CU的最終模式.因為在PBBPMS中已經得到了亮度PB的預測模式,在TBCC中已經得到了亮度和色度的TBC,所以QTD的主要工作就是決策出當前CU最優的TU劃分和最優色度預測模式,并且計算出當前CU的率失真代價,完成模式選擇過程.本文提出的并行策略:一個CTU里面的所有CU并行進行QTD:QTD(CU(depthi,zorderj)),其中 0≤i≤3,0≤j≤4i-1,i,j并行. 2.4理論并行度分析 為了對所提并行幀內MD算法的理論并行度進行近似分析,進行2點假設:1)對于RMCC,PMCC,TBCC子任務,主要計算量是幀內預測和變換量化,它們的計算時間與計算單元的面積成正比,且與預測模式無關;CMLC,PBBPMS,QTD的主要操作是結果的比較和選擇,計算量較小且與計算單元面積無關.2)對于同一類子任務由于解除了相鄰數據單元之間的數據相關性,所有的數據單元都可以同時被計算,因此理論并行度由整個CTU串行計算時間和計算量最大的數據單元的計算時間決定.基于以上2點假設,各子任務分析如下: 1)RMCC階段.令CTi,j,k表示RMCC(PB(depthi,zorderj),modek)的計算時間,令T=CT0,0,0,那么整個CTU里所有PB的RMCC串行計算時間近似為 2)PMCC階段.令CTi,j,k表示PMCC(PB(depthi,zorderj),modek)的計算時間,令T=CT1,0,0,經統計亮度PB的CML里面平均含有5個模式,所以整個CTU里所有PB的PMCC的串行計算時間近似為 最大計算量任務的計算時間為T,所以TPD=100. 3)TBCC階段.令CTi,j,k表示TBCC(TB(depthi,zorderj),modek)的計算時間,令T=CT1,0,0,假設TU最多劃分3層,在串行MD過程中整個CTU里所有TB的TBCC串行計算時間為 最大計算量任務的計算時間為T,所以TPD=44. 從以上分析可以看出,本文提出的并行幀內MD算法的理論并行度很高,適用于眾核平臺. 3實現和實驗結果 基于HEVC參考代碼HM13.0[23],本文使用多線程實現本文所提出的并行模式選擇算法.本文修改了代碼中模式選擇模塊(TEncCu∷xCompressCU及相關函數)使之并行化,其他的模塊保持不變.本文重點是提出一種適用于眾核平臺的高并行度算法,主要關注算法的并行度和對編碼質量的影響,所以并未對單核性能進行指令、內存等任何優化.實驗采用的計算平臺為TILE-Gx36眾核平臺,共有36個處理核心,單核主頻1.2GHz. 3.1實現方法 為了減少頻繁創建和銷毀線程帶來的開銷,本文使用線程池實現本文算法.在編碼器剛啟動時創建一定數量所需線程,線程池中所有的線程在編碼器整個生命周期內一直存在.為了減小線程切換帶來的性能影響和增加實驗的可重現性,所有的線程都綁定在一個固定的核上且每個核只綁定一個線程.0號核不予使用,1號核綁定主線程,其余34個核用于線程池里的工作線程.線程池中維護一個任務鏈表,所有需要處理的任務都插入鏈表,空閑的工作線程自動從鏈表首取走任務進行處理.主線程的主要工作就是往鏈表里面放任務,實際去完成任務計算的是工作線程. 在本文的實現中,定義了6種類型的任務:RMCC,CMLC,PMCC,PBBPMS,TBCC,QTD,由于這些任務之間對于同一個數據單元存在先后處理順序的依賴關系,所以本文定義了任務的優先級,如表3所示.優先級越大的任務表示越應該優先被計算,因為其他類型的任務可能會使用它的計算結果,在放入任務鏈表時會根據優先級大小順序存放,優先級越大的任務在任務鏈表中排序越靠前.另外,為了保證塊越大的任務先被計算,在每一種任務類型里面,塊越大的任務即深度越小的任務優先級越大.對于不同數據單元,計算任務之間則沒有依賴關系,不同種類的子任務之間可以并行. Table 3 Sub-Tasks with Their Parallel Hierarchy and Priority 3.2實驗結果 為了驗證本文提出的并行幀內MD算法的有效性,包括編碼加速比和對編碼質量的影響,本文用基準編碼器HM和本文并行化的編碼器分別對6個1080p和2個1600p的高分辨率視頻使用HM提供的配置文件intra_main進行了編碼,每個序列使用了前100幀,根據文獻[20]對每個序列分別使用4個不同的量化參數(quantizationparameter,QP):22,27,32,37.加速比按照式(6)計算,其中Enc_Timer和Enc_Timep分別表示基準編碼器HM和并行編碼器的編碼時間,編碼效率的下降使用BDBR[21]來衡量.為了驗證并行算法的可伸縮性即加速比與核數的關系,對每個序列都使用了不同數量的工作線程進行編碼.實驗結果如表4所示,其中的核數是用于工作線程的核數,加速比是對4個QP取平均的結果.從表4可以看出,本文提出的并行幀內模式選擇算法在使用34個核時對所有序列平均能獲得18以上的加速比,平均BDBR為 3.04%.部分序列的率失真曲線如圖8所示. (6) Fig. 8 Rate distortion curves for some test sequences.圖8 部分序列的率失真曲線圖 Fig. 9 Speedup vs number of cores for our proposed method and WPP (TPD).圖9 算法加速比和WPP(TPD)與核數關系 圖9給出使用不同數量的核數(2,4,8,16,24,32,34)得到的所有序列的平均加速比與核數之間的關系曲線圖,并且與1080p和1600p的WPP的理論值進行了對比.從圖9可以看出,本文所提出的算法在核數增多時有更高的加速比,適用于眾核計算平臺;當核數較少時加速效果比較明顯,但是隨后曲線逐漸趨于平坦,且加速比與核數之比遠小于1,離算法的TPD有較大的差距.造成這種現象的原因可能有3點: 1) 并行計算數據單元劃分不均衡.在本文的算法中,不同大小的PU和TU計算量相差較大,如果假設計算量與塊面積成正比,那么第0層TU的TBCC計算量近似是第1層TU的TBCC的4倍.任務劃分不均衡會導致處理器核的計算負載不均衡,造成CPU核的饑餓等待,影響并行度. 2) 由于所有的并行任務都放在一個公共鏈表里面,所有線程都會競爭此資源以取得任務.隨著核數的增加,線程之間在取任務和放任務的競爭會越來越激烈,勢必會造成很大的線程同步開銷. 3) 算法只進行了模式選擇計算的并行化,其他的部分仍然串行執行,雖然占的比例很小,但是會對整體的并行度造成上限制約.另外,編碼階段的修正過程也是串行執行,也會影響實際的加速比. 對于編碼質量的下降,主要原因是代價計算的準確性不高,這是本文所采取的多種數據依賴性消除算法的綜合作用結果. 由于本文提出的并行算法是在局部區域CTU內進行,所以可以和其他全局粗粒度并行方法如WPP和Tiles結合使用,能進一步提高并行度. 4總結 本文提出了一種在CTU內使用的多層次細粒度的并行HEVC幀內模式選擇算法,一個CTU內所有不同層次的CU,PU,TU以及所有預測模式可以并行地進行代價計算和模式選擇.本文分析了存在的多種數據依賴性并提出了有效的依賴性解除方法.實驗結果表明本文提出的方法能達到18倍以上的編碼加速比并且編碼質量損失較小,比傳統的粗粒度并行方案更能適用于眾核平臺. 參考文獻 [1]BrossB,HanWJ,OhmJR,etal.JCTVC-L1003:Highefficiencyvideocoding(HEVC)textspecificationdraft10 (forfdis&lastcall)[C/OL]. 2013 [2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC-L1003-v34.zip [2]SullivanGJ,OhmJR,HanWJ,etal.Overviewofthehighefficiencyvideocoding(HEVC)standard[J].IEEETransonCircuitsandSystemsforVideoTechnology, 2012, 22(12): 649-1668 [3]PengXiaoming,GuoHaoran,PangJianmin.Multi-coreprocessor-technology,tendencyandchallenge[J].ComputerScience, 2012, 39(11A): 320-326 (inChinese)(彭曉明, 郭浩然, 龐建民. 多核處理器——技術、趨勢和挑戰[J]. 計算機科學, 2012, 39(11A):320-326) [4]YanChenggang.Researchonkeytechniquesforparallelvideocodingonmany-coreprocessor[D].Beijing:InstituteofComputingTechnology,ChineseAcademyofSciences, 2014 (inChinese)(顏成鋼. 面向眾核處理器的并行視頻編碼關鍵技術研究 [D]. 北京: 中國科學院計算技術研究所, 2014) [5]ChoiK,JangES.Leveragingparallelcomputinginmodernvideocodingstandards[J].IEEEMultimedia, 2012, 19(3): 7-11 [6]ZhangYongdong,YanChenggang,DaiFeng,etal.EfficientparallelframeworkforH.264/AVCdeblockingfilteronmany-coreplatform[J].IEEETransonMultimedia, 2012, 14(1): 510-524 [7]YanChenggang,ZhangYongdong,DaiFeng,etal.HighlyparallelframeworkforHEVCmotionestimationonmany-coreplatform[C] //Procofthe23rdDateCompressionConf(DCC2013).Piscataway,NJ:IEEE, 2013: 63-72 [8]YanChenggang,ZhangYongdong,XuJizheng,etal.EfficientparallelframeworkforHEVCmotionestimationonmany-coreprocessors[J].IEEETransonCircuitsandSystemsforVideoTechnology, 2014, 24(12): 2077-2089 [9]ClareG,HenryF,PateuxS.JCTVC-F274:WavefrontparallelprocessingforHEVCencodinganddecoding[C/OL]. 2011 [2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/6_Torino/wg11/JCTVC-F274-v2.zip [10]FuldsethA,HorowitzM,XuS,etal.JCTVC-F335:Tiles[C/OL]. 2011[2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/6_Torino/wg11/JCTVC-F335-v2.zip [11]ZhouMinhua.JCTVC-H0082:ConfigurableandCU-grouplevelparallelmerge/skip[C/OL]. 2012[2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/8_San%20Jose/wg11/JCTVC-H0082-v2.zip [12]ChiCC,MauricioAM,JuurlinkB,etal.ParallelscalabilityandefficiencyofHEVCparallelizationapproaches[J].IEEETransonCircuitsandSystemsforVideoTechnology, 2012, 22(12): 1827-1838 [13]ZhangJun,DaiFeng,MaYike,etal.HighlyparallelmodedecisionmehtodforHEVC[C] //Procofthe30thPictureCodingSymp(PCS2013).Piscataway,NJ:IEEE, 2013: 281-284 [14]ZhaoYanan,SongLi,WangXiangwen,etal.EfficientrealizationofparallelHEVCintraencoding[C]//Procof2013IEEEIntConfonMultimediaandExpoWorkshops(ICMEW2013).Piscataway,NJ:IEEE, 2013: 1-6 [15]YanChenggang,ZhangYongdong,DaiFeng,etal.EfficientparallelHEVCintra-predictiononmany-coreprocessor[J].ElectronicsLetters, 2014, 50(11): 805-806 [16]JiangJie,GuoBaolong,MoWei,etal.Block-basedparallelintrapredictionschemeforHEVC[J].JournalofMultimedia, 2012, 7(4): 289-294 [17]ChoiK,ParkSH,JangES.JCTVC-F092:CodingtreepruningbasedCUearlytermination[C/OL]. 2011[2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/6_Torino/wg11/JCTVC-F092-v3.zip [18]ChoS,KimM.FastCUsplittingandpruningforsuboptimalcupartitioninginHEVCintracoding[J].IEEETransonCircuitsandSystemsforVideoTechnology, 2013, 23(9): 1555-1564 [19]LealdaSilvaT,daSilvaCruzL,AgostiniLV.HEVCintramodedecisionaccelerationbasedontreedepthlevelsrelationship[C]//Procofthe30thPictureCodingSymp(PCS2013).Piscataway,NJ:IEEE, 2013: 277-280 [20]BossenF.JCTVC-L1100:Commontestconditionsandsoftwarereferenceconfigurations[C/OL]. 2013 [2014-11-01].http://phenix.int-evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC-L1100-v1.zip [21]BjontegaardaG.VCEG-M33:Calculationofaveragepsnrdifferencesbetweenrd-curves[C/OL]. 2001 [2014-11-01].https://github.com/gabrieldiego/tg/blob/master/ref/VCEG-M33.doc [22]ZhangShaobo,ZhangXiaoyun,GaoZhiyong.ImplementationandimprovementofwavefrontparallelprocessingforHEVCencodingonmany-coreplatform[C] //Procof2014IEEEIntConfonMultimediaandExpoWorkshops(ICMEW2014).Piscataway,NJ:IEEE, 2014: 1-6 [23]JCTVC.HEVCtestmodel:HM13.0[CP]. [2014-11-01]https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/branches/HM-13.0-dev ZhangJun,bornin1987.ReceivedhisBEdegreefromXidianUniversityin2009andreceivedhisPhDdegreefromtheInstituteofComputingTechnology,ChineseAcademyofSciencesin2015.Hisresearchinterestsincludevideocodingandimageprocessing. DaiFeng,bornin1979.ReceivedhisMSandPhDdegreesfromtheInstituteofComputingTechnology,ChineseAcademyofSciences,Beijing,China,in2008.AssociateprofessorwiththeMultimediaComputingGroup,AdvancedResearchLaboratory,InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing.MemberofChinaComputerFederation.Hisresearchinterestsincludevideocoding,videoprocessingandcomputationalphotography(fdai@ict.ac.cn). MaYike,bornin1980.ReceivedhisMSandPhDdegreesintheInstituteofComputingTechnology,ChineseAcademyofSciences,Beijing,China,in2011.MemberofChinaComputerFederation.Hisresearchinterestsincludecomputerarchitecture,parallelalgorithmandcomputationalphotography(ykma@ict.ac.cn). ZhangYongdong,bornin1973.ReceivedhisPhDdegreeinelectronicengineeringfromTianjinUniversity,Tianjin,China,in2002.ProfessorwiththeInstituteofComputingTechnology,ChineseAcademyofSciences,Beijing,China.SeniormemberofChinaComputerFederation.Hisresearchinterestsincludemultimediacontentanalysisandunderstanding,multimediacontentsecurity,videocoding,andstreamingmediatechnology(zhyd@ict.ac.cn). Multi-LevelandFine-GrainedParallelHEVCIntraModeDecisionMethod ZhangJun1,2,DaiFeng1,MaYike1,andZhangYongdong1 1(Key Laboratory of Intelligent Information Processing (Institute of Computing Technology, Chinese Academy of Sciences), Chinese Academy of Sciences, Beijing 100190)2(University of Chinese Academy of Sciences, Beijing 100049) AbstractThe coding mode space of high efficiency video coding (HEVC) is extremely large so it needs huge amount of computations for HEVC encoders to do mode decision (MD). Parallelizing HEVC encoding on many-core platforms is an efficient and promising approach to fulfill the high computational demands. Traditional coarse-grained parallelizing schemes such as Tiles and wavefront parallel processing (WPP) either cause too much quality loss or can’t afford a high parallelism degree. In this paper, the potential parallelism in HEVC intra MD process is exploited, and a multi-level and fine-grained highly parallel intra MD method which works in a coding tree unit (CTU) is proposed. Specifically, the intra MD process in a CTU is divided into six types of sub-tasks, and the data dependencies among adjacent blocks that hinder parallel processing are analyzed and removed, including intra prediction dependency, prediction mode dependency and entropy coding dependency; consequently the MD computation for all fine-grained coding blocks of different levels within the same CTU can be computed concurrently. The proposed parallel MD method is implemented on Tile-Gx36 platform. Experimental results show that the proposed parallel MD method gets an overall speed up of more than 18x with acceptable quality loss (about 3% bit-rate increasing), compared with the non-parallel baseline HM. Key wordshigh efficiency video coding (HEVC); intra prediction; many-core; parallel mode decision; fine-grained 收稿日期:2014-12-31;修回日期:2015-04-27 基金項目:國家自然科學基金項目(61379084,61402440);中國科學院科研裝備研制項目(YZ201321) 中圖法分類號TP391 ThisworkwassupportedbytheNationalNaturalScienceFoundationofChina(61379084,61402440)andtheInstrumentDevelopingProjectoftheChineseAcademyofSciences(YZ201321).