二次改進遺傳算法與3DNoC低功耗映射
2016-06-30 07:46:23張大坤宋國治林華洲任淑霞
計算機研究與發展 2016年4期
張大坤 宋國治 林華洲 任淑霞
(天津工業大學計算機科學與軟件學院 天津 300387)(Zhandakun2013@163.com)
二次改進遺傳算法與3DNoC低功耗映射
張大坤宋國治林華洲任淑霞
(天津工業大學計算機科學與軟件學院天津300387)(Zhandakun2013@163.com)
摘要隨著集成電路技術的迅速發展,芯片的集成度不斷提高,片上眾多處理單元間的高效互連成為關鍵問題,因而相繼出現了片上系統(system-on-chip, SoC)和二維片上網絡(two-dimensional network-on-chip, 2D NoC).當二維片上網絡在多方面達到瓶頸時,三維片上網絡(three-dimensional network-on-chip, 3D NoC)應運而生.三維片上網絡已引起學術界和產業界的高度重視,三維片上網絡低功耗映射是其中的1個關鍵問題.之前的研究曾提出過一種基于改進遺傳算法的3D NoC低功耗映射算法,并收到了良好的仿真效果.但當問題規模變大時,計算量隨之增大、運行效率明顯降低.針對這一問題,對3D NoC中面向功耗優化的二次改進遺傳算法任務映射機制進行研究,提出了一種新的3D NoC低功耗映射算法,并對該映射算法進行了仿真實驗.實驗結果表明,在種群規模較大的條件下,該算法不僅能夠繼續降低功耗,而且能夠大幅度地減少映射算法的運行時間.
關鍵詞三維片上網絡;低功耗映射;改進遺傳算法;二次改進遺傳算法;貪心算法
1958年世界誕生了第1個集成電路,隨著集成電路規模的不斷增大,片上系統(system-on-chip,SoC)應運而生,而且SoC的處理單元(processingelements,PE)數不斷增加,為高效地連接數量巨大的PE,產生了二維片上網絡(two-dimensionalnetwork-on-chip, 2DNoC)這種主流的片上互連架構.而2DNoC在面積、功耗、布局布線以及封裝密度等方面都已達到了瓶頸,三維片上網絡(three-dimensionalnetwork-on-chip, 3DNoC)應運而生.自2005年第1篇以3DNoC為主題的學術論文發表以來[1],3DNoC以其更短的全局互連、更高的性能、更低的互連損耗、更高的封裝密度以及更小的體積等諸多優勢成為1個重要的研究方向[2-3].降低功耗是3DNoC所面臨的1個關鍵問題,從多種途徑降低3DNoC的功耗非常必要.映射決定知識產權(intellectualproperty,IP)核在3DNoC上的位置,通過改進映射算法能夠有效地降低3DNoC的功耗.因此,3DNoC低功耗映射已逐漸成為3DNoC領域的研究熱點.3DNoC映射問題和任務調度問題相似,都是NP難解問題[4].有許多研究者嘗試應用各種算法解決3DNoC映射問題,其中,美國賓夕法尼亞州立大學Charles[5]采用遺傳算法研究了考慮到熱感知和通信感知的3DNoC映射問題;南京大學王佳文[6-8]、湯普森河大學的Elmiligi等人[9]、航空電子系統綜合技術重點實驗室Ge等人[10]均嘗試過采用遺傳算法解決3DNoC映射問題,并取得了相應的研究成果.本文將對3DNoC中面向功耗優化的二次改進遺傳算法任務映射機制進行研究.
13DNoC低功耗映射問題
1.1基本概念
3DNoC低功耗映射就是在給定通信軌跡圖和拓撲結構圖的基礎上,研究如何將IP核映射到3DNoC的資源節點上,使得整個3DNoC的通信量最小,達到降低通信功耗的目的.為了描述3DNoC映射問題,給出如下定義:
定義1. 通信軌跡圖CTG(N,C).設CTG(N,C)為有向圖,其中N為頂點集,節點ni∈N表示1個IP核;C為邊集,有向邊ci j∈C表示節點ci到節點cj的邊,wi j表示邊ci j的權重.
定義2. 拓撲結構圖TAG(T,E).設TAG(T,E)為有向圖,其中,T為PE集合,ti∈T表示1個PE;E為邊集,有向邊ei j表示節點ti到節點tj的邊[11-12].
1.23DNoC映射算法評估標準
目前尚沒有一致公認的面向3DNoC映射問題的評估標準.3DNoC作為解決片上系統通信問題的解決方案.其中,網絡吞吐量與平均延遲都是重要的性能指標;3DNoC映射算法的設計也應當考慮功耗問題,過高的功耗可能會對網絡產生致命的影響;3DNoC的三維立體結構,會引發網絡內部發熱不均的問題,發熱過高可能會導致整個網絡的癱瘓;對于實時性要求相對高的應用,最大網絡延時也應作為網絡性能的重要指標.文獻[13-14]提出了評價映射算法優劣的4個重要性能指標:
1) 平均網絡延遲.3DNoC的出現主要是為了解決SoC內資源節點之間的通信問題,因此,平均網絡延遲是衡量3DNoC設計質量的重要指標,平均網絡延遲間接地決定了3DNoC的吞吐率.
2) 最大網絡延遲.目前大多數針對3DNoC的延時模型都是平均延時模型,然而在出現擁塞的狀況下,決定整個網絡通信效率的往往是最大延遲,當最大延遲超過了其容錯上限,將導致整個網絡無法正常工作.因此,最大延遲也是3DNoC評估的重要指標.
3) 平均功耗.3DNoC在傳遞消息的過程中會發生能量的消耗,平均功耗能夠反映3DNoC在傳送數據時功耗性能.
4) 發熱與負載均衡.3DNoC由于其結構特性,內部節點容易出現發熱過高的情況,過熱點的產生將影響整個芯片的性能.過熱點區域位于網絡邊緣容易散熱,可以降低過熱點區域對整個網絡性能的影響.因此,在網絡設計時盡可能地將過熱點區域分散到網絡邊緣.
1.33DNoC功耗模型
1.3.13DNoC功耗計算公式
3DNoC中的功耗主要來自2方面:路由節點上的功耗和鏈路上的功耗.路由節點上的功耗主要是路由節點內部存儲、交換、路由內部連線和路由選擇所產生的能耗;鏈路上的功耗指的是路由數據經過路由節點之間鏈路時所產生的能耗.文獻[11]給出了3DNoC的功耗模型,節點ti發送1個微片(flit)到節點tj消耗的能量表示為
(1)
其中,μ表示節點ti到節點tj經過的路由器個數,μH和μV分別是節點ti到節點tj經過的水平方向和垂直方向的邊數(跳步),ERbit表示1個微片通過 1個路由器時所消耗的能量,ELHbit和ELVbit分別表示1個微片通過1條水平方向和垂直方向的線路時的耗能.文獻[14]給出的ELHbit和ELVbit的計算公式為
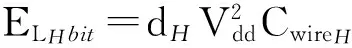
(2)
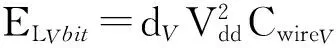
(3)
其中,dH和dV分別表示水平方向和垂直方向線路的長度,Vdd表示供電電壓,CwireH和CwireV分別表示水平方向和垂直方向線路的電容.
1.3.2映射目標函數
3DNoC映射就是尋找IP核與PE的1個對應關系.在給定通信軌跡圖CTG和拓撲結構圖TAG的條件下尋找1個映射函數M(·):N→T,使得總功耗最低(用Emin表示),其目標函數如下:
(4)
且滿足條件:
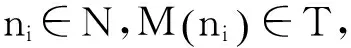
(5)

(6)
對于確定的拓撲結構,ERbit,ELHbit和ELVbit是確定的.由文獻[11]可知,線路上的功耗與線路的長度成正比,所以,2個通信節點之間的線路長度是影響3DNoC功耗的關鍵要素.由于硅穿孔(throughsiliconvia,TSV)技術的出現,3DNoC在垂直方向的線路長度遠遠小于水平方向的長度,因此,傳輸同樣的數據量,在垂直方向的功耗遠遠小于水平方向的功耗.
2基于改進遺傳算法的3DNoC低功耗映射
本文作者曾對3DNoC映射問題進行了研究,提出一種基于改進遺傳算法(improvedgeneticalgorithm,IGA)的3DNoC低功耗映射算法(簡稱IG映射算法)[15],現對其進行簡單回顧.
2.1問題簡介
如引言所述,用遺傳算法解決3DNoC映射問題已取得一些研究成果[5-11],從映射出發降低3DNoC功耗是1個有效的途徑.遺傳算法根據問題的目標函數構造1個適應值函數,產生由多個解構成的初始種群,根據適應值的優劣選擇種群中的個體進行遺傳操作產生新的種群,當進化達到終止條件后,選擇適應值好的個體作為問題的解.算法的實現主要分為如下5個步驟:
算法1. 遺傳算法.
Step1. 遺傳算法在運行之前要將解空間的數據表示成算法運行時可用的基因數據,由于每個IP核只能映射到1個PE上,因此,在映射問題中采用整數編碼.
Step2. 隨機產生1個初始種群,種群中每個個體都對應映射算法的1個解.
Step3. 根據問題的目標函數構造適應值函數,計算種群中每個個體的適應值.
Step4. 根據適應值的優劣不斷地進行選擇和繁殖操作,以得到下一代種群.
Step5. 達到終止條件后,選擇適應值最好的個體作為算法的最終解.
基本遺傳算法的初始種群是隨機生成的,這使得初始種群存在個體分布不均勻、初始種群質量偏低的問題.作者提出的IG映射算法是將貪心算法與遺傳算法相結合,用以解決3DNoC低功耗映射問題,相對于傳統遺傳算法具有更優的搜索能力.
2.2IG映射算法的核心思想
IG映射算法是貪心算法與遺傳算法的組合,即采用貪心算法生成初始種群的遺傳算法,貪心算法思想主要體現在生成初始種群個體上.用貪心算法生成初始種群個體主要分為3個步驟:
算法2. 貪心算法.
Step1. 隨機地將任務圖中的1個節點(即IP核)映射到3DNoC的第1個位置(把所有IP核從1到N進行編號,N為任務圖上IP核的個數,n代表任意1個IP核;把所有PE從1到M進行編號,M為3DNoC上PE的個數,m代表任意1個PE).
Step2. 分別計算將所有IP核集合中可用數字放入所有PE集可用位置后的適應值,用n,m,fit表示未使用數字n放入3DNoC的第m個位置使得適應值fit最大,將n,m,fit放入集合F中,從F中選擇fit最大的3組,隨機地從這3組中選擇一組n,m,fit,將n放到3DNoC的第m個位置,把n從可用的IP核集合中刪除,把m從3DNoC的可用位置集合中刪除.
Step3. 重復Step2,直到沒有未使用的數字(IP核集合為空),即任務圖中的所有節點都已映射到3DNoC上.
生成初始種群后,采用遺傳算法進行遺傳操作,得到最優個體,然后用最優個體生成仿真器能夠識別的通信模式文件,仿真器讀取通信模式文件進行仿真得到映射功耗.仿真結果表明,IG映射算法可以有效地降低功耗,從總體趨勢上看,隨著處理單元數目的增加,功耗降低的幅度逐漸增大,在種群規模為200、處理單元為120的情況下,總功耗可降低14.42%[15].
3二次改進遺傳算法與3DNoC低功耗映射研究
3.1問題的提出與算法描述
3.1.1問題的提出
2.2節中的IG映射算法是采用貪心算法生成初始種群中的每個個體,使初始種群的質量整體得到了提升,有效地降低了功耗.但該算法在生成初始種群時,單個個體生成的計算量較大,在確定1個IP核映射到3DNoC上時,會計算所有未映射到3DNoC上的IP核放到3DNoC上所有可用位的適應值,而且生成每個個體都要進行同樣的運算,所以該算法在生成初始種群時運行效率明顯低于基本遺傳算法.針對這一問題,對3DNoC中面向功耗優化的二次改進遺傳算法任務映射機制進行研究,提出了一種基于改進貪心算法和遺傳算法的3DNoC低功耗映射策略,并稱其為基于二次改進遺傳算法(doubleimprovedgeneticalgorithm,I2G)的3DNoC低功耗映射算法并稱之為I2G映射算法.
3.1.2I2G映射算法的核心思想
IG映射算法是用一般的貪心算法生成初始種群,而I2G映射算法則采用改進貪心算法生成初始種群.I2G映射算法中采用的改進貪心算法與IG映射算法中采用的貪心算法的區別在于:
1) 2.2節中貪心算法在Step1,隨機地將1個IP核(用n表示)映射到3DNoC的第1個位置(數字n可重復出現),而改進貪心算法中在第1個位置上放置的IP核(n)不可重復出現(n=1,2,…,N).
2) 2.2節中貪心算法在Step2,是從集合F中找出3組fit最大的n,m,fit,隨機地從中選1組,而改進貪心算法只選取fit值最大的1組n,m,fit,將n放到3DNoC的第m個位置,把n從可用的IP核集合中刪除,把m從3DNoC的可用位置集合中刪除;重復2)直到IP核集合為空,即表示生成了1個個體.
3) 2.2節中貪心算法可以生成任意多個個體,而改進貪心算法只能生成N個個體(N為任務圖規模).因此,改進貪心算法會對所有已生成的個體進行變異操作生成一定數量的鄰居個體,最后從所有生成的個體中選取一定數量的個體作為初始種群.
I2G映射算法的具體實現詳見3.2.3節.
3.2種群個體向量表示與初始種群生成
3.2.1種群個體向量表示
由于每個PE都可以向其他任意1個PE發送數據,CTG中的IP核可以映射到任意1個可用的PE上.因此,在3DNoC映射中種群個體采用整數編碼,假設個體X=(x1,x2,…,xn),n為CTG的IP核個數,xi為IP核編號,個體X的編碼為1到n的1種排列,通過對編碼進行解碼即可得到1種映射方案.1個簡單的16節點視頻對象平面解碼器芯片(videoobjectplanedecoder,VOPD)的通信軌跡圖如圖1所示[16],以此圖為例來說明種群個體的向量表示.圖1中箭頭附近的數字表示節點間的通訊量,單位是MBps.
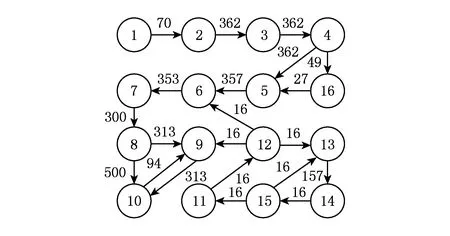
Fig. 1 VOPD communication trace diagram.圖1 VOPD 通信軌跡圖
VOPD中的IP核用數字1,2,…,16表示,將VOPD映射到2×3×3的3DNoC上,3DNoC上的每個PE用數字t1到t18表示,t1到t6表示第1層,t7到t12表示第2層,t13到t18表示第3層,如圖2所示.個體X=(2,3,4,1,16,5,7,6,11,15,14,12,13,10,8,9),表示將IP核集(2,3,4,1,16,5,7,6,11,15,14,12,13,10,8,9)分別映射到處理單元t1到t16上,映射結果如圖3所示.將所有IP核映射到3DNoC上之后,計算3DNoC上所有節點之間的通信總量,用遺傳算法根據3DNoC上的通信總量計算其適應值,通信總量越大,適應值越小,用遺傳算法根據適應值大小進行遺傳操作.

Fig. 2 3D NoC topological structure圖2 3D NoC拓撲結構
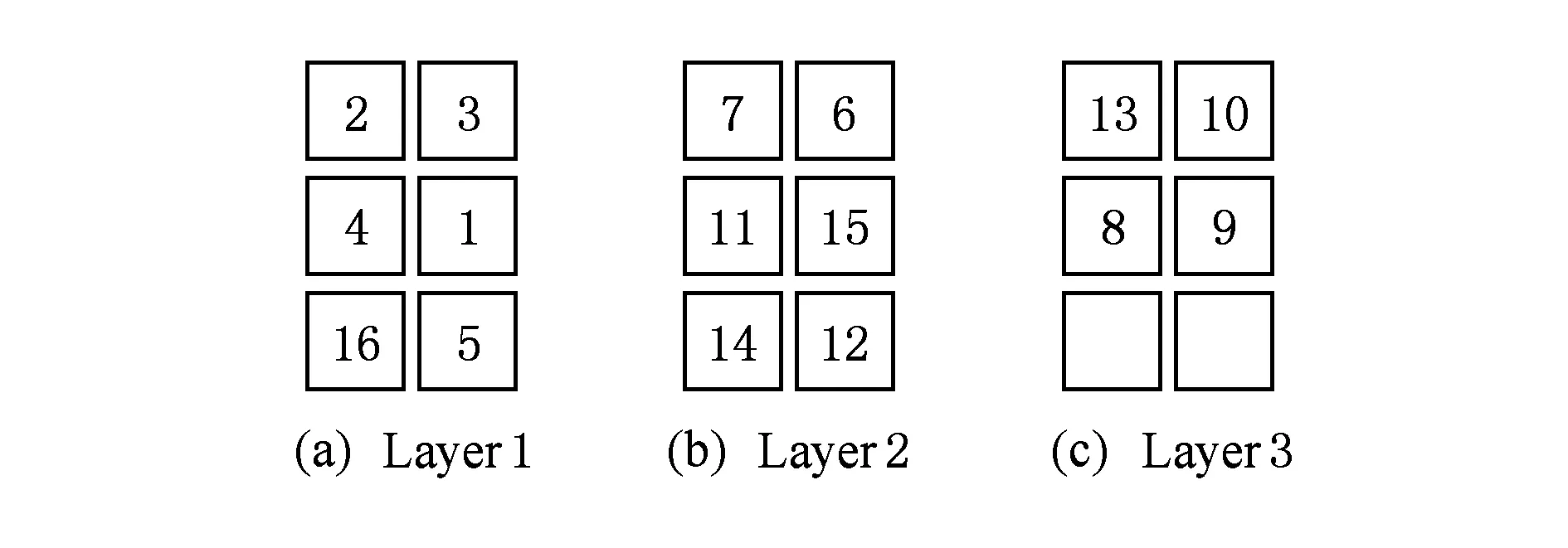
Fig. 3 Mapping result圖3 映射結果
3.2.2應用改進貪心算法生成初始種群
應用本文提出的改進貪心算法生成初始種群(Pop)的主要過程如下:
算法3. 改進貪心算法.
Step1. 將數字i放到個體X的第1個位置(i=1,2,…,N,當選取每個i后,重復Step2到Step5,每次循環都生成1個個體).
Step2. 初始化可用集合P={1,2,…,N},N為CTG的IP核個數,將i從可用集合P中刪除.
Step3. 遍歷可用集合P中的數字n,將n放入個體X的所有可用位置,計算放入這些位置后X的適應值,從這些適應值中找到最大的適應值fit,記下n放到使得X適應值最大的位置m,把n,m,fit存到集合F中.
Step4. 遍歷集合F,找到fit值最大的1個元素n,m,fit,把n放到個體X的第m個位置,并把n從可用集合P中刪除.
Step5. 重復Step3和Step4,直到可用集合P=?,當P=?時,表示產生了新個體X,把X加入臨時種群tempPop中.
Step6. 重復上述Step5,生成N個個體.
Step7. 將個體X中的任意2個坐標數字交換(即變異操作),生成1個新個體Y,即X的鄰居個體.用此方法生成20個X的鄰居個體放入臨時種群tempPop中.
Step8. 從臨時種群tempPop中選取一定規模適應值最大的個體放入Pop中.
3.2.3I2G映射算法實現
1) 低功耗映射實現流程
算法4.I2G映射算法.
Step1. 采用改進貪心算法生成初始種群(詳見3.2.2節).
Step2. 用遺傳算法對初始種群進行進化操作,得到算法的最優解.
Step3. 根據最優解生成仿真平臺能夠識別的通信模式(trafficpattern)文件.
Step4. 仿真平臺讀取通信模式文件進行仿真,得到3DNoC低功耗映射仿真結果.
2) 通信模式文件的生成過程
算法5. 通信模式文件生成.
Step1. 將CTG(N,C)里的邊集C,根據改進遺傳算法得到最優個體X,轉換成TAG的邊集E.例如:最優個體X=(2,3,4,1,8,5,7,6),邊c12,邊c12的權重w12=100,映射到TAG上后得到邊e41,邊e41的權重w41=100.統計所有邊的通信量之和wSum.
Step2. 生成隨機數1≤r≤n,如果第r條邊為e13,則在通信模式文件中寫入1 3,如果通信量等于0,則循環查找下一條邊,直到找到通信量大于0的邊,在通信模式文件中寫入該條邊的信息,將該條邊的通信量減1.
Step3. 重復Step2,直到所有邊的通信量為0.
4仿真實驗與結果分析
4.1仿真平臺與參數設計
4.1.1仿真平臺選擇
仿真實驗是在Ubuntu13操作系統下,采用C++語言編寫算法的實現程序,在codeblocks12.11環境下,采用AccessNoxim0.2作為仿真軟件進行映射算法的仿真(AccessNoxim0.2對主流的2DNoC仿真軟件noxim進行了改進,改進后可以用于3DNoC的仿真實驗).
4.1.2拓撲結構與路由選擇
1) 拓撲結構的選擇
3DMesh具有結構規則、布線簡單、網絡節點位置平等且在垂直方向互連采用TSV技術減小了總體布線長度等優點,實驗中采用了3DMesh結構.
2) 路由選擇
XYZ路由算法易于理解與實現,是主流的路由算法,實驗中采用了該路由算法.
4.1.3參數設置
1) 算法的參數設置.種群規模為200,遺傳迭代次數為100,交叉率為0.9,變異率為0.02.
2) 仿真軟件的參數設置.數據包采用無記憶泊松分布(memorylessPoissondistribution)方式注入,數據包的注入率(packetinjectionrate)設為0.02;仿真軟件統計循環5 000次的總功耗;數據包的大小介于2個微片到10個微片之間;路由器每個通道的緩存大小設為8個微片.
4.1.4硬件運行環境
整個仿真實驗的硬件環境是:CPU為Intel?CoreTMi3-2120,主頻為3.30GHz,內存為4GB的微型計算機.
4.2仿真實驗結果分析
采用C++語言編寫了基于IG映射算法[15]和基于I2G映射算法的3DNoC低功耗映射程序,在上述環境下進行了仿真實驗.
4.2.1經典任務圖的功耗對比
1) 針對VOPD的功耗對比
首先針對2個經典的通信軌跡圖VOPD和DVOPD(doublevideoobjectplanedecoder)進行仿真實驗.其中,VOPD中有16個節點,如圖1所示,將VOPD映射到2×2×4的3DNoC上.仿真實驗中,分別采用IG映射算法和I2G映射算法對該任務圖進行映射操作,用得到的最優解生成通信模式文件,仿真器AccessNoxim通過讀取通信模式文件進行映射仿真,得到映射功耗.用實驗數據分別對2種映射算法得到的最小功耗、平均功耗和最大功耗進行了比較,如圖4所示:
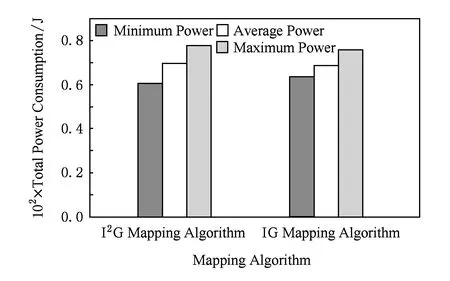
Fig. 4 Comparison of two mapping algorithms’ power consumption for VOPD.圖4 針對VOPD的2種映射算法功耗對比
分析針對VOPD的2種映射算法仿真結果可見,在最低功耗方面I2G映射算法低于IG映射算法,即采用I2G映射算法的功耗更低,但是降低的幅度較小;而在平均功耗和最大功耗方面,I2G映射算法的功耗高于IG映射算法的功耗,I2G映射算法與IG映射算法的唯一區別就是生成初始種群時采用的貪心策略不同.對任務圖分別進行實驗,由實驗結果可知:I2G映射算法與IG映射算法相比,最低功耗降低了2.02%、平均功耗增加了2.15%、最高功耗增加了1.54%.其中,I2G映射算法的功耗高于基于IG映射算法[16]的功耗,這是由于VOPD只有16個節點(節點過少),采用改進貪心策略得到的初始種群容易陷入局部最優.
2) 針對DVOPD的功耗對比
通信軌跡圖DVOPD有32個節點,如圖5所示[16],圖5中箭頭附近的數字表示節點間的通訊量,單位是MBps.實驗中將DVOPD映射到2×2×4的3DNoC上,針對通信軌跡圖DVOPD分別用2種映射算法進行了仿真實驗.
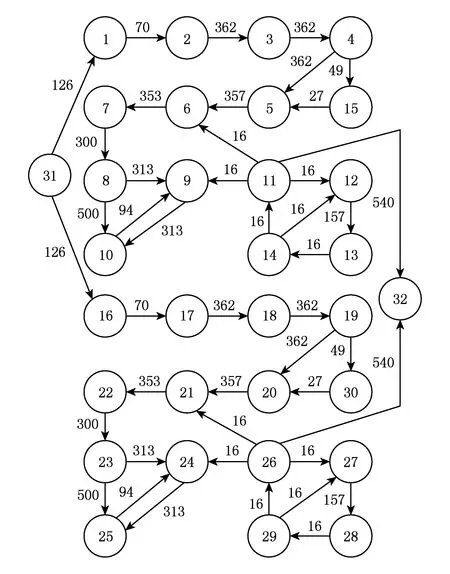
Fig. 5 DVOPD task communication diagram.圖5 DVOPD任務通信圖
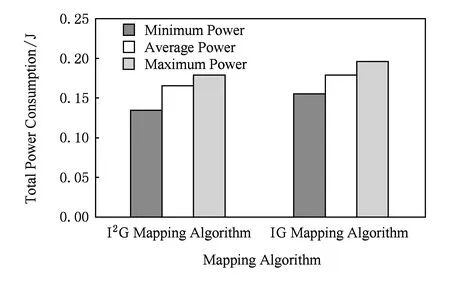
Fig. 6 Comparison of two mapping algorithms’ power consumption for DVOPD.圖6 針對DVOPD的2種映射算法功耗對比
實驗中對任務通信圖DVOPD分別采用IG映射算法和I2G映射算法的仿真結果如圖6所示.I2G映射算法得到的仿真結果明顯優于IG映射算法的仿真結果:I2G映射算法與IG映射算法相比,最低功耗降低了13.37%、平均功耗降低了9.18%、最高功耗降低了7.48%.功耗降低顯著,這是由于DVOPD有32個節點,任務規模較大,采用改進貪心策略得到的初始種群不容易陷入局部最優.由以上實驗和分析可見,當任務圖規模增大時,I2G映射算法的優勢更為明顯.
4.2.2經典任務圖映射算法運行時間對比
IG映射算法和I2G映射算法的運行時間對比如圖7所示.由圖7可見,I2G映射算法的運行時間明顯少于IG映射算法的運行時間.對于VOPD,由于任務圖規模較小,生成每個個體所用的時間較短,因此I2G算法的運行時間減少幅度較小,比IG映射算法減少了19.11%(I2G映射算法的運行時間為3.619s、IG映射算法的運行時間為4.474s);而對于DVOPD,I2G映射算法的運行時間比IG映射算法的運行時間[15]減少幅度增大、減少了68.90%(I2G映射算法的運行時間為5.444s、IG映射算法的運行時間為17.503s).
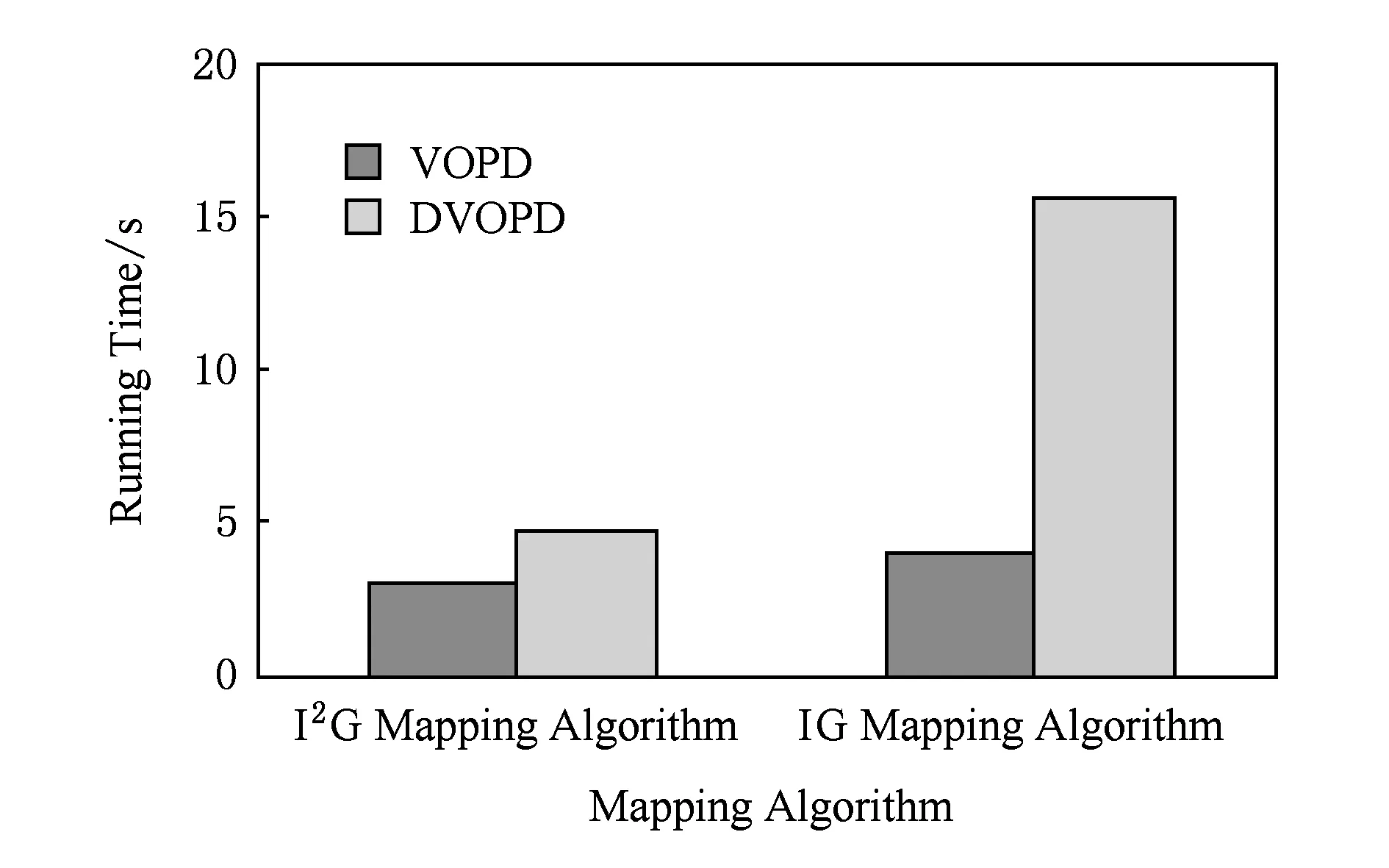
Fig. 7 Comparison of two mapping algorithms’ running time.圖7 2種映射算法運行時間對比
4.2.3200種群規模下隨機任務圖的功耗對比
1) 仿真實驗數據
采用任務生成器TGFF[17]生成隨機任務圖,針對不同IP核數的CTG、種群規模為200時,分別采用IG映射算法和I2G映射算法求解10次,得到的功耗如表1和表2所示(對仿真實驗數據從低到高進行了排序).
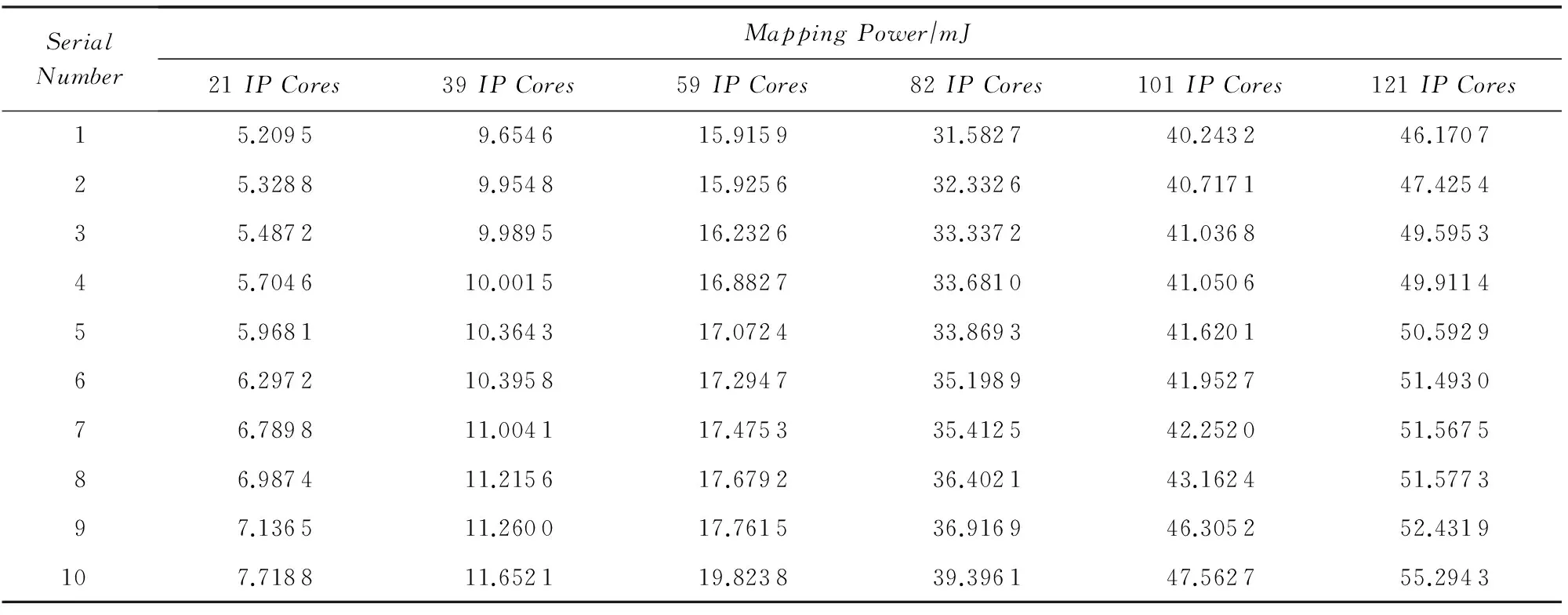
Table 1 Experimental Results of Ten Simulation for IG Mapping Algorithm
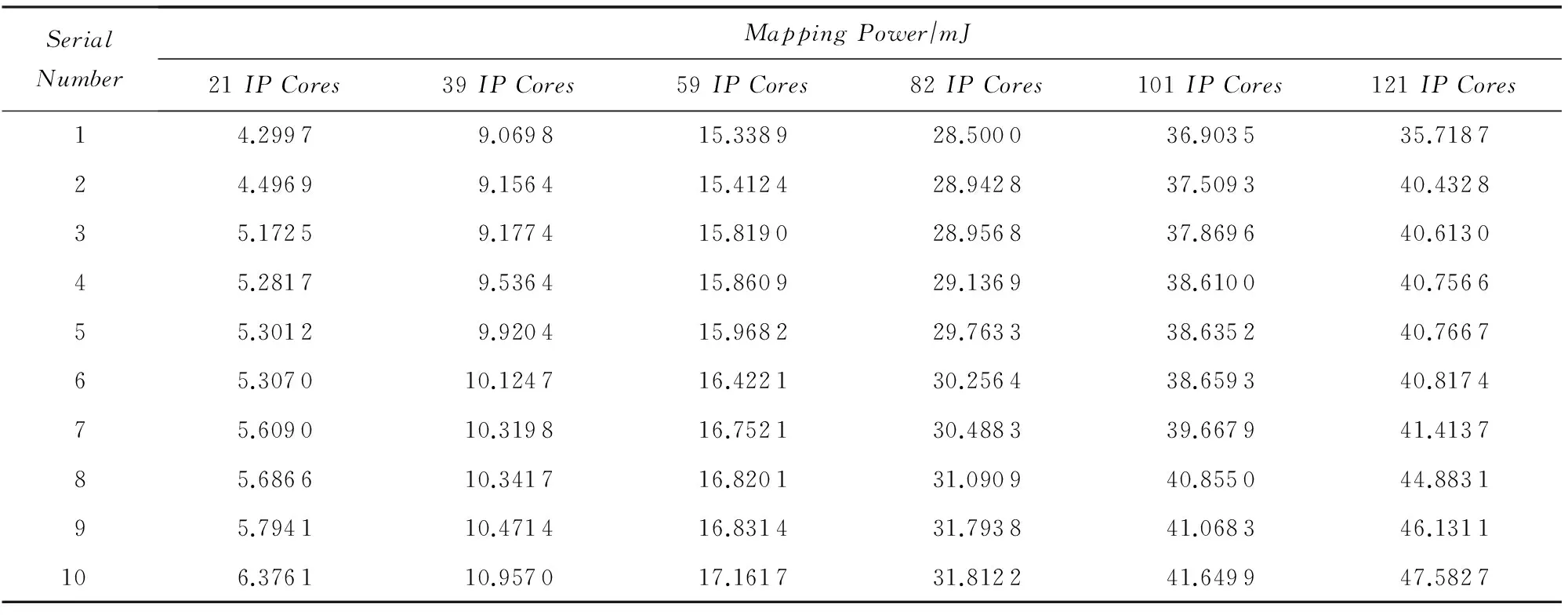
Table 2 Experimental Results of Ten Simulation for I2G Mapping Algorithm
2) 最低功耗比較
當IP核數較少時,I2G映射算法相對于IG映射算法的最低功耗降低幅度較小,在10%以內.其中,21個IP核時,I2G映射算法比IG映射算法的功耗低了17.46%,這是由于IP核數目較少,容易導致2種算法均陷入局部最優,因此出現了在21個IP核時I2G映射算法的功耗降低幅度較大.從整體趨勢來看,隨著IP核數的增加,功耗降低幅度增加,如圖8所示.當IP核數為121時,I2G映射算法比IG映射算法功耗降低了22.64%.
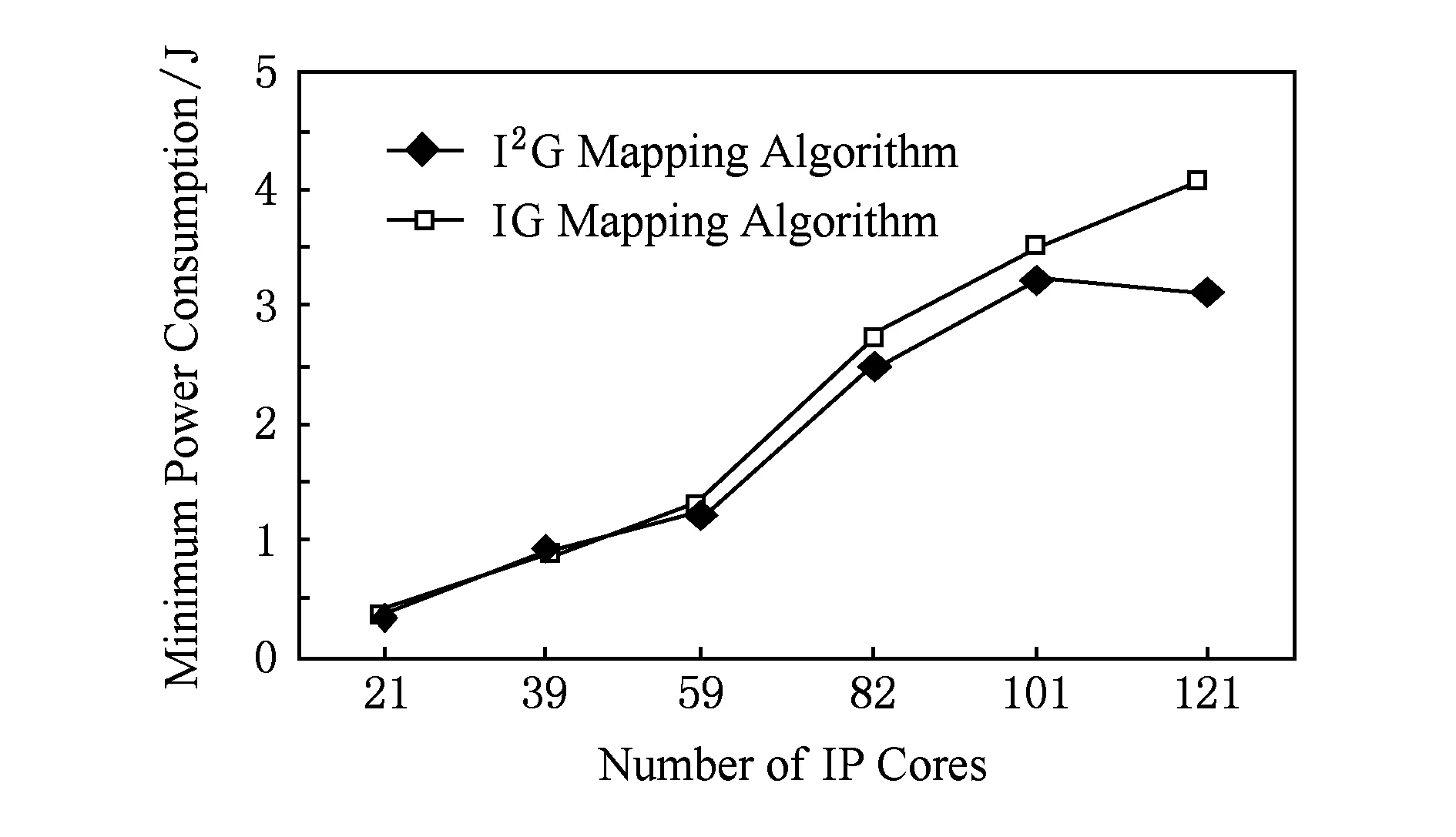
Fig. 8 Comparison of two mapping algorithms’ minimum power consumption.圖8 2種映射算法最低功耗對比
3) 最高功耗對比
當IP核個數為21時,I2G映射算法相對于IG映射算法最高功耗降低了17.40%.當IP核個數為82時,I2G映射算法比IG映射算法的最高功耗降低了19.25%(為所做實驗的最大降低幅度),如圖9所示.當IP核數為121時,I2G映射算法相比IG映射算法最高功耗降低了13.95%.

Fig. 9 Comparison of two mapping algorithms’ maximum power consumption.圖9 2種映射算法最高功耗對比
4) 平均功耗對比
當IP核數為21時,I2G映射算法比IG映射算法平均功耗降低了14.85%;當IP核數為82時,I2G映射算法比IG映射算法平均功耗降低了13.61%;當IP核數為121時,I2G映射算法相比IG映射算法平均功耗降低了17.18%(為所做實驗的最大值),如圖10所示:

Fig. 10 Comparison of two mapping algorithms’ average power consumption.圖10 2種映射算法平均功耗對比
4.2.4種群規模200隨機任務圖運行時間對比
種群規模為200時2種映射算法的運行時間對比如圖11所示.由圖11可見,I2G映射算法比IG映射算法的運行時間顯著減少;當IP核數為59時,I2G映射算法比IG映射算法的運行時間減少了74.05%.
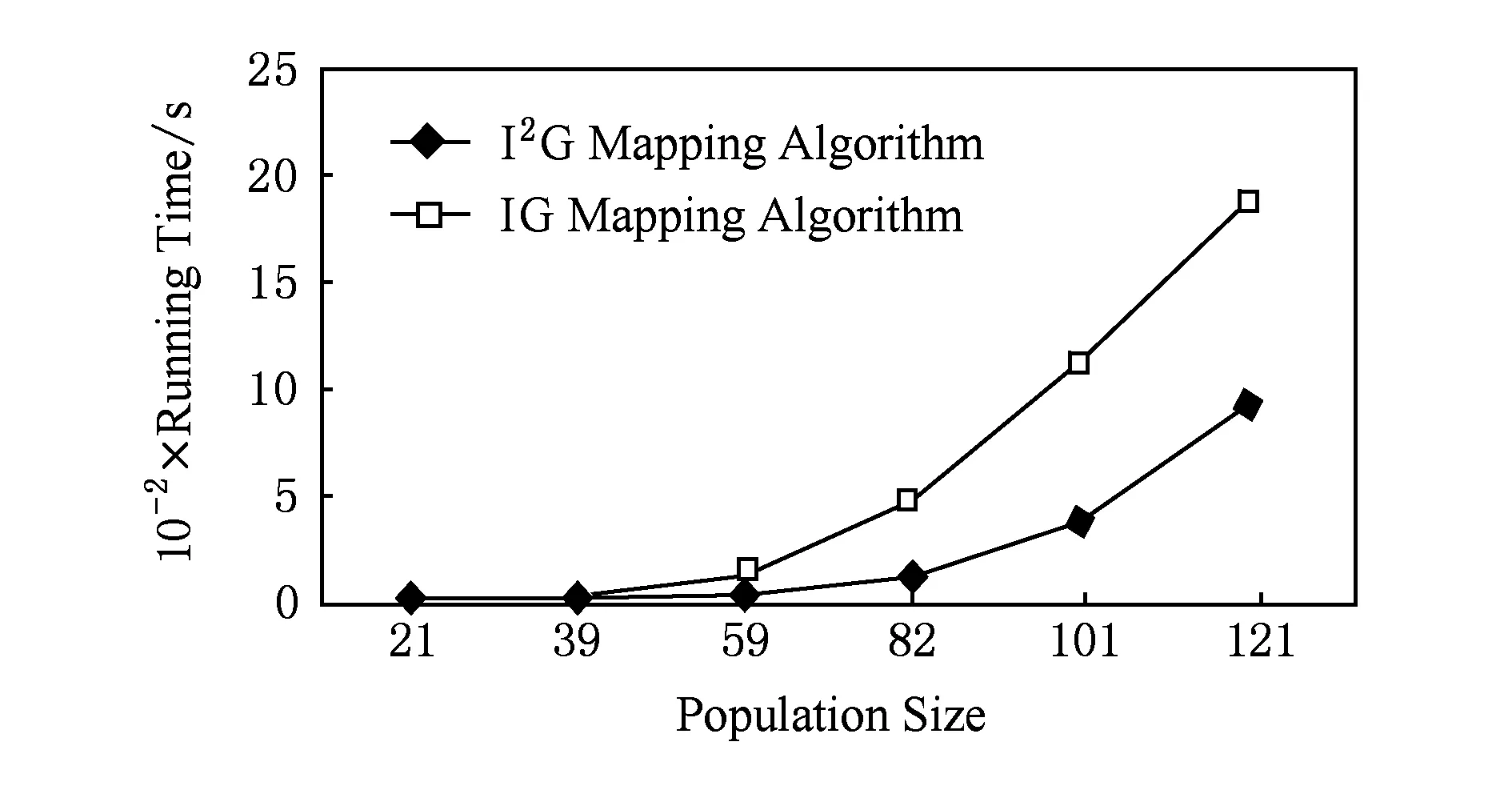
Fig. 11 Comparison of two mapping algorithms’ running time with a population size of 200.圖11 種群規模為200的2種映射算法運行時間對比
4.2.5300種群規模隨機任務圖功耗與時間對比
1) 2種映射算法功耗對比
種群規模為300時,2種映射算法平均功耗的比較如圖12所示.IP核數為121時,I2G映射算法比IG映射算法的功耗降低了13.48%.
2) 2種映射算法運行時間對比
種群規模為300時I2G映射算法與IG映射算法運行時間對比如圖13所示.IP核數為121時,I2G映射算法比IG映射算法的運行時間減少了85.56%.
4.2.6隨機任務圖不同種群規模下運行時間對比
2種映射算法在IP核數為82時,種群規模不同時的運行時間對比如圖14所示.當種群規模為600時,I2G映射算法比IG映射算法運行時間減少了89.98%(此時功耗降低16.36%).隨著種群規模的增大,I2G映射算法的運行時間比IG映射算法的運行時間減少幅度逐漸增大;隨著種群規模的增加,IG映射算法的運行時間大幅度增加,而I2G映射算法的運行時間變動幅度很小(這是由于I2G映射算法采用了改進貪心策略生成初始種群,因此,種群規模對映射算法的運行時間影響很小).
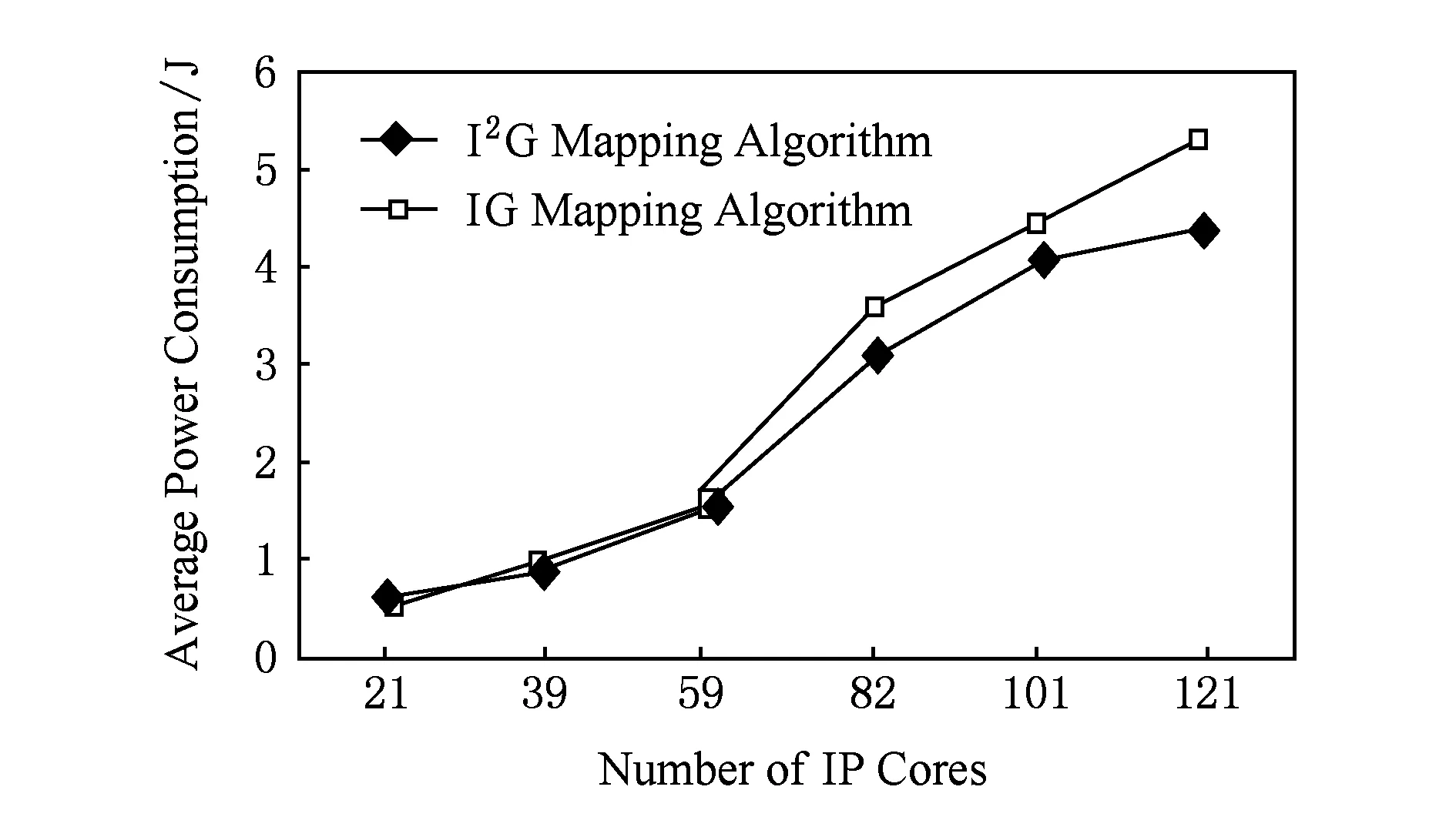
Fig. 12 Comparison of two mapping algorithms’ average power consumption with a population size of 300.圖12 種群規模為300時2種映射算法平均功耗對比
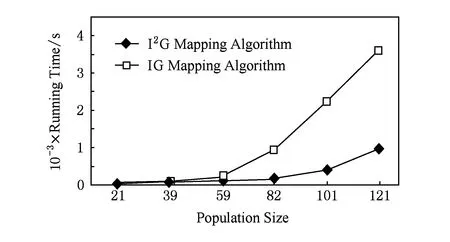
Fig. 13 Comparison of two mapping algorithms’ average power consumption with a population size of 300.圖13 種群規模為300時2種映射算法平均功耗對比
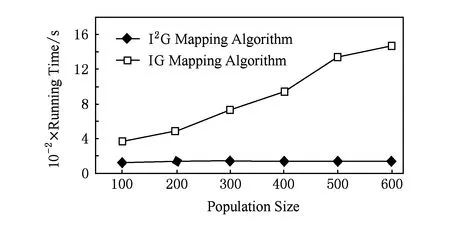
Fig. 14 Comparison of two mapping algorithms’s running time with different population sizes and 82 IP cores.圖14 IP核數82時不同種群規模2種映射算法運行時間對比
4.2.7映射算法收斂速度對比
針對VOPD的收斂速度對比如圖15所示,從迭代開始IG映射算法得到的適應值要遠遠大于基本遺傳算法和I2G映射算法,而且在之后的進化過程中,IG映射算法得到的適應值變化很小,這說明在任務圖規模較小時,IG映射算法容易陷入局部最優.
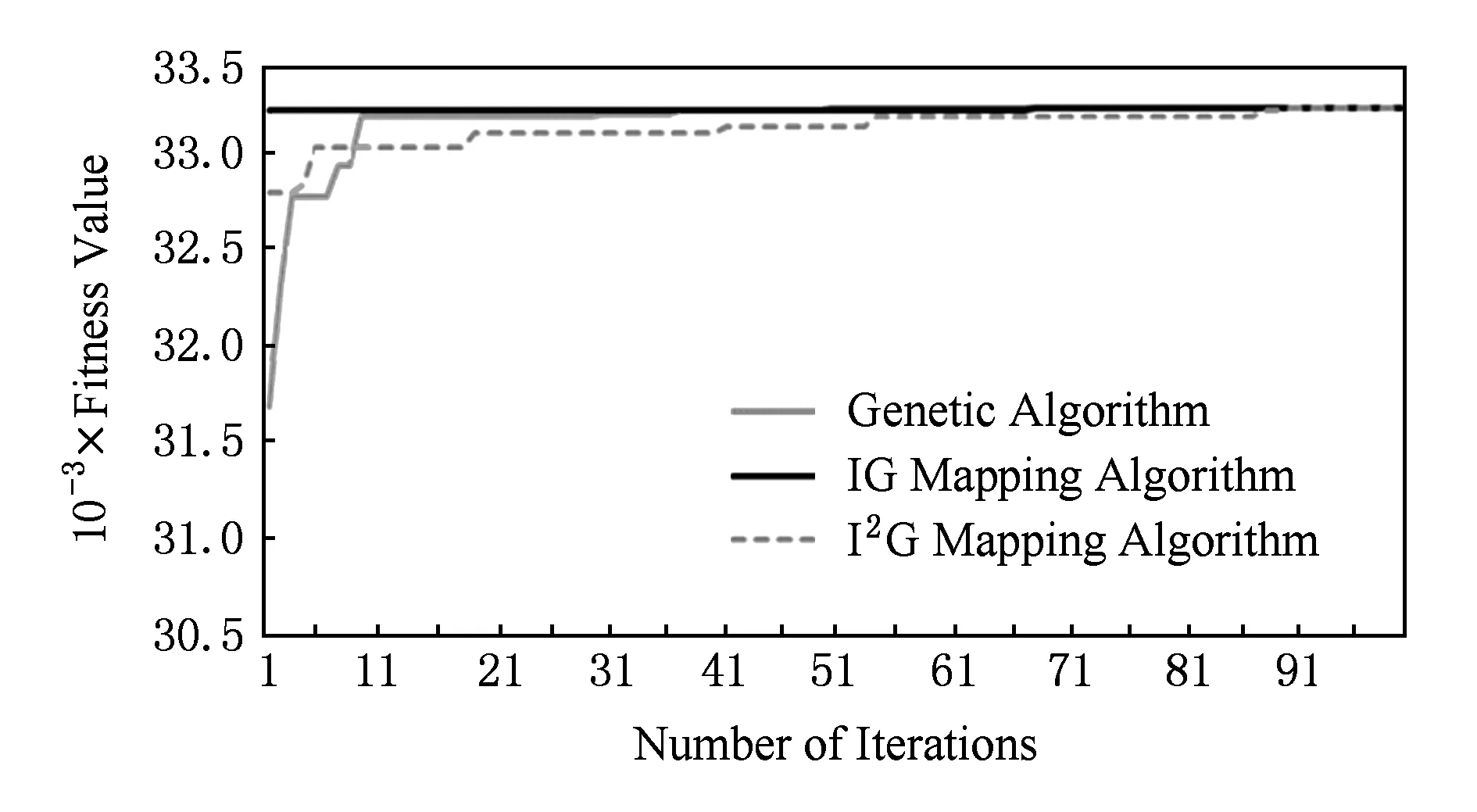
Fig. 15 Convergence speed for two VOPD mapping algorithms.圖15 針對VOPD的2種映射算法的收斂速度對比
針對DVOPD在100次的迭代過程中收斂速度對比如圖16所示,基本遺傳算法的收斂速度比較慢,最終得到的適應值要小于另外2種映射算法;IG映射算法的收斂速度比基本遺傳算法快,但是比I2G映射算法慢;I2G映射算法在算法運行初期得到的最大適應值要比IG映射算法小,而算法運行后期I2G映射算法收斂速度更快,而且得到的適應值更大.
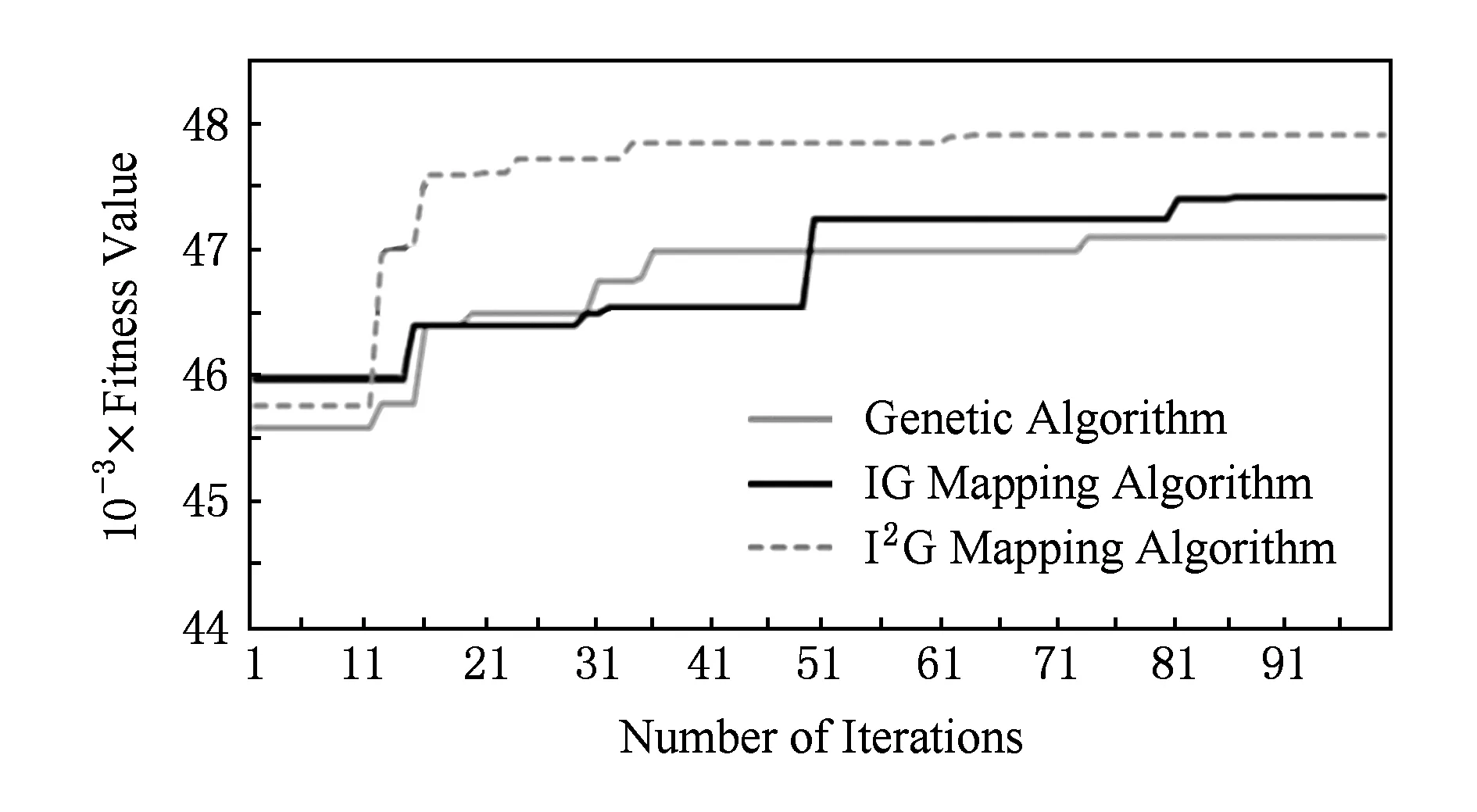
Fig. 16 Convergence speed for two DVOPD mapping algorithms.圖16 針對DVOPD的2種映射算法的收斂速度對比
5結論與展望
5.1結論
針對IG映射算法運行時間較長的問題,本文提出了基于I2G算法的3DNoC低功耗映射算法(簡稱I2G映射算法).仿真結果表明,隨著種群規模的增大,I2G映射算法在功耗繼續保持降低的前提下,運行時間大幅度地減少.特別是,當IP核數為82、種群規模為600時,I2G映射算法與IG映射算法相比,平均功耗降低了16.36%,運行時間減少了89.98%.仿真實驗表明,本文所提出的I2G映射算法效果顯著.
5.2展望
1) 本文采用XYZ路由算法進行了I2G映射算法的仿真實驗,在今后的研究中將對動態路由策略下的映射問題進行研究.
2) 發熱是3DNoC設計中需要考慮的重要問題,隨著研究的深入,我們將在映射算法研究中加入發熱等方面因素的考慮.
3) 隨著專用3DNoC需求的增多,出現了許多異構3DNoC架構,例如基于異構布局、位移交換和基于樹圖的3DNoC架構. 目前,針對異構3DNoC架構的映射算法的研究還處于起步階段,還有很大的發展空間. 在未來的研究中,可以充分利用異構特征,針對不同類型的任務通信圖采用不同的映射算法來提高3DNoC的映射效率并降低系統的功耗.
4) 目前有一種映射方法是將任務圖映射到子網絡上,并將子網絡用定位的方式在片上網絡中找到相應大小的區域,最后將任務圖映射到該區域. 采用這樣的映射方式,多個任務的映射可同時進行. 但由于任務通信圖與子網絡上處理單元大小存在不一致性,往往造成子網絡上處理單元的浪費。減少處理單元的浪費將是一個值得研究的課題.
參考文獻
[1]LeeK,LeeSJ,KimD,etal.Networks-on-chipandnetworks-in-packageforhigh-performanceSoCplatforms[C] //Procofthe2005ConfonAsianSolid-StateCircuits.NewYork:ACM, 2005: 485-488
[2]PavlidisVF,FriedmanEG. 3-Dtopologiesfornetworks-on-chip[J].IEEETransonVeryLargeScaleIntegrationSystems, 2007, 15(10): 1081-1090
[3]DavisWR,WilsonJ,MickS,etal.Demystifying3DICs:Theprosandconsofgoingvertical[J].IEEEDesign&TestofComputers, 2005, 22(6): 498-510
[4]JohnsonDS,GareyM.ComputersandIntractability:AGuidetotheTheoryofNP-Completeness[M].SanFrancisco,CA:Freeman&Co, 1979
[5]CharlesAQ.Thermal-awaremappingandplacementfor3-DNoCdesigns[C] //Procofthe2005IntConfonSOC.NewYork:ACM, 2005: 25-28
[6]WangJiawen. 3DNockeytechnologyresearch[D].Nanjing:NanjingUniversity, 2012 (inChinese)(王佳文. 3DNoC關鍵技術研究[D]. 南京: 南京大學, 2012)
[7]WangJiawen,LiLi,WangZhongfeng,etal.Energy-efficientmappingfor3DNoCusinglogisticfunctionbasedadaptivegeneticalgorithms[J].ChineseJournalofElectronics, 2014, 23(2): 254-262
[8]WangJiawen,LiLi,HongBingpan,etal.Latency-awaremappingfor3DNoCusingrank-basedmulti-objectivegeneticalgorithm[C] //Procofthe2011ConfonASIC.NewYork:ACM, 2011: 413-416
[9]ElmiligiH,GebaliF,El-Kharashi,etal.Power-awaremappingfor3DNoCdesignsusinggeneticalgorithms[J].ProcediaComputerScience, 2014, 34: 538-543
[10]GeFen,FengGui,YuShuang,etal.Power-andthermal-awaremappingfor3Dnetwork-on-chip[J].InformationTechnologyJournal, 2013, 12(23): 7297-7304
[11]WangXiaohang,LiuPeng,YangMei,etal.Energyefficientrun-timeincrementalmappingfor3Dnetworks-on-chip[J].JournalofComputerScienceandTechnology, 2013, 28(1): 54-71
[12]ZhangZhen.Researchofmappingmethodsfor3D-mesh-orientedCMPnetworksonchip[D].Guangzhou:GuangdongUniversityofTechnology, 2012 (inChinese)(張振. 基于3D-MESH的CMP片上網絡映射方法研究[D]. 廣州: 廣東工業大學, 2012)
[13]QianYue,LuZhonghai,DouQiang,etal.CommunicationperformanceanalysisoftheNoCsin2Dand3Darchitectures[J].ComputerEngineering&Science, 2011, 33(3): 34-40 (inChinese)(錢悅, 魯中海, 竇強, 等. 片上網絡二維和三維結構的通信性能分析[J]. 計算機工程與科學, 2011, 33(3): 34-40)
[14]MatsutaniH,KoibuchiM,AmanoH.Tightly-coupledmulti-layertopologiesfor3-DNoCs[C] //Procofthe2007ConfonParallelProcessing.NewYork:ACM, 2007: 75-79
[15]LinHuaZhou,ZhangDaKun,HuangCui.Researchonlow-powermappingforthree-dimensionalnetwork-on-chipbasedonimprovedgeneticalgorithm[J].ComputerEngineering&Application, 2016, 52(1): 81-88 (inChinese)(林華洲, 張大坤, 黃翠. 基于改進遺傳算法的3DNoC低功耗映射研究[J]. 計算機工程與應用, 2016, 52(1): 81-88)
[16]PradipKS,SantanuC.Asurveyonapplicationmappingstrategiesfornetwork-on-chipdesign[J].JournalofSystemsArchitecture, 2013, 59(1): 60-76
[17]DickRP,RhodesDL,WolfW.TGFF:Taskgraphsforfree[C] //Procofthe1998ConfonHardware/SoftwareCodesign.NewYork:ACM, 1998: 97-101

ZhangDakun,bornin1960.ReceivedherPhDdegreeincomputertechnologyfromNortheasternUniversity.ProfessoratTianjinPolytechnicUniversity.Hermainresearchinterestsinclude3Dnetworks-on-chip,bigdatavisualizationanalysis,andvirtualreality.

SongGuozhi,bornin1977.ReceivedhisPhDdegreefromQueenMary,UniversityofLondon,UK.AssociateprofessoratTianjinPolytechnicUniversity.Hismainresearchinterestsinclude3Dnetworks-on-chip,heterogeneouswirelessnetworkintegration,andqueueingtheory(guozhi.song@gmail.com).

LinHuazhou,bornin1990.MScandidate.Hisresearchinterestsinclude3Dnetworks-on-chip(linhuazhou90@126.com).

RenShuxia,bornin1973.ReceivedherPhDdegreefromTianjinUniversity.Associateprofessor.Herresearchinterestsinclude3Dnetworks-on-chip,datamining,andbigdataanalysis(t_rsx@126.com).

2014年《計算機研究與發展》高被引論文TOP10
數據來源:中國知網,CSCD;統計日期:2016-02-16
DoubleImprovedGeneticAlgorithmandLowPowerTaskMappingin3DNetworks-on-Chip
ZhangDakun,SongGuozhi,LinHuazhou,andRenShuxia
(School of Computer Science & Software Engineering, Tianjin Polytechnic University, Tianjin 300387)
AbstractWith the rapid development of integrated circuit technology, the number of integrated components on a chip continues to increase. Efficient interconnection between the processing units on chip becomes a key issue. Therefore firstly system-on-chip (SoC) and then two-dimensional networks-on-chip (2D NoC) have been proposed to cope with this problem. But now even the 2D NoC has reached a bottleneck in many aspects, so the design of Three-Dimensional networks-on-chip (3D NoC) is inevitable. 3D NoC has attracted the attention of the researchers from both Academia and industry. One of the key issues of 3D NoC is low-power mapping. We have previously proposed a 3D NoC low-power mapping algorithm based on improved genetic algorithm with good results. But when the scale of the problem gets larger, the amount of calculation increases gradually and operation efficiency is reduced significantly. To solve this problem, this paper proposes a new 3D NoC task mapping algorithm with power optimization based on a double improved genetic algorithm, and the simulation experiments are conducted to validate the algorithm. The results show that under the conditions of a large population size, the 3D NoC task mapping algorithm cannot only reduce the power, but also reduce the running time significantly.
Key words3D network-on-chip (3D NoC); low-power mapping; improved genetic algorithm; double improved genetic algorithm; Greedy algorithm
收稿日期:2015-07-23;修回日期:2016-01-22
基金項目:國家自然科學基金項目(61272006)
中圖法分類號TP391
ThisworkwassupportedbytheNationalNaturalScienceFoundationofChina(61272006).
