傾向性評分匹配在非隨機(jī)對照研究中的應(yīng)用*
2016-06-24 02:48:30中山大學(xué)公共衛(wèi)生學(xué)院醫(yī)學(xué)統(tǒng)計與流行病學(xué)系510080焦明旭菁郝元濤
中國衛(wèi)生統(tǒng)計 2016年2期
中山大學(xué)公共衛(wèi)生學(xué)院醫(yī)學(xué)統(tǒng)計與流行病學(xué)系(510080) 焦明旭 張 曉 劉 迪 顧 菁郝元濤
?
傾向性評分匹配在非隨機(jī)對照研究中的應(yīng)用*
中山大學(xué)公共衛(wèi)生學(xué)院醫(yī)學(xué)統(tǒng)計與流行病學(xué)系(510080) 焦明旭 張 曉 劉 迪 顧 菁△郝元濤
非隨機(jī)對照研究與隨機(jī)對照研究相比研究對象入選標(biāo)準(zhǔn)相對寬松,外推性更佳,因此在人群研究中應(yīng)用廣泛[1]。但由于無法隨機(jī)化,混雜因素在處理組和對照組之間的分布可能不均衡,導(dǎo)致處理因素和結(jié)局的關(guān)系受混雜因素干擾。在數(shù)據(jù)的分析階段,非隨機(jī)對照研究對混雜因素的控制可通過分層分析或多因素分析,但如果組間特征差異過大,則可能對研究結(jié)果產(chǎn)生無法以分析方法彌補(bǔ)的偏倚[2],且當(dāng)混雜因素數(shù)量過多時以上方法也存在局限性。
傾向性評分匹配(propensity score matching,PSM)可有效降低混雜效應(yīng),均衡處理組和對照組之間的差異,從而利用非隨機(jī)分組數(shù)據(jù)來估測處理因素和結(jié)局的關(guān)系,研究處理效應(yīng)[3]。近年來國外PSM應(yīng)用廣泛,在Pubmed數(shù)據(jù)庫中以“propensity scor*”為檢索詞,從1987年到2012年共檢索到4835篇論文,尤其在過去十年論文數(shù)量成倍增長,從2002年42篇增長到2013年1118篇[4]。但PSM有其特定使用條件,且基于傾向性評分有多種匹配方法,國內(nèi)鮮有研究對此做出說明。本文將結(jié)合案例介紹PSM的概念、應(yīng)用條件、匹配方法、優(yōu)缺點(diǎn)及應(yīng)用。
基本概念
傾向性評分(propensity score,PS)由Rosenbaum 和Rubin提出,定義為在混雜因素存在條件下,研究對象進(jìn)入處理組的條件概率[5]。PSM基于傾向性評分將處理組和對照組個體進(jìn)行匹配,通過計算兩組的平均處理效應(yīng)來表示結(jié)局差異。
傾向性評分的函數(shù)模型為P(X)=P(T =1|X),其中P(X)為傾向性評分理論值,T為處理變量,T =1表示樣本接受處理,為協(xié)變量即混雜因素。如果處理組研究對象為i,那么P(Xi)=P(T =1 |Xi);對照組研究對象為j,則那么P(Xj)=P(T =1 |Xj),因此只要傾向性評分相同或相近,即P(Xi)=P(Xj),則Xi=Xj,可認(rèn)為兩組混雜因素相同,以此保證對照均衡性。根據(jù)評分進(jìn)行匹配,沒有匹配的個體將被剔除。配比時需規(guī)定匹配精度,如PS值相差<0.01[2]。傾向性評分在在隨機(jī)試驗(yàn)中是已知的,但在非隨機(jī)對照研究中未知[6]。目前用于估計傾向性評分的方法有l(wèi)ogistic回歸、Probit回歸、分類與回歸樹等機(jī)器方法[7]。
應(yīng)用條件
PSM有兩個應(yīng)用條件:(1)條件獨(dú)立性,(2)組間評分分布具有足夠大的重疊區(qū)域。
1.條件獨(dú)立性
條件獨(dú)立性是指觀察對象對處理的選擇只受所考慮的協(xié)變量的影響,不受未考慮協(xié)變量的影響。假設(shè)協(xié)變量X不影響是否接受處理,則結(jié)局Y也不受處理因素分配T的影響,如果代表處理組結(jié)局,代表對照組結(jié)局,那么條件獨(dú)立性表示為:
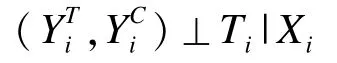
條件獨(dú)立性只是一種假設(shè),而非可以直接檢驗(yàn)的標(biāo)準(zhǔn),與研究項(xiàng)目自身的特征有關(guān)。如果未考慮的協(xié)變量影響受試對象對處理的選擇,則不符合條件獨(dú)立性,通過PSM所得結(jié)果就值得懷疑。
2.組間評分分布具有足夠大的重疊區(qū)域
PSM通過處理組和對照組的評分進(jìn)行匹配,因此樣本量夠大而且協(xié)變量取值相近,才能使兩組的評分分布存在較大的重疊區(qū)域。在重疊區(qū)域外的觀察數(shù)據(jù)將被剔除,這些無法匹配的處理組數(shù)據(jù)會增加抽樣偏倚的可能性,因此為了估測研究的偏倚程度,應(yīng)當(dāng)充分分析被剔除個體的數(shù)據(jù)。
方 法
在傾向性評分的基礎(chǔ)上可采用多種匹配方法進(jìn)行匹配。不同方法具有各自特性,且方法的選擇會影響到對處理效應(yīng)的估計[8]。本文將著重介紹最近鄰匹配法、卡鉗匹配法、分層匹配法、核匹配與局部線性匹配法、回歸分析法以及與馬氏匹配相結(jié)合的匹配法。
1.最近鄰匹配法(nearest-neighbor matching)
最近鄰匹配法是PSM最基本也是最常用的方法,此方法將處理組和對照組傾向性評分中最接近的個體進(jìn)行匹配,且根據(jù)對照組個體是否可以重復(fù)匹配給處理組,又分為有替代匹配和無替代匹配。有替代匹配中對照組個體一般與不超過5個處理組個體匹配,若對照組中存在2個及以上的相同評分的個體,則按隨機(jī)的原則進(jìn)行選擇[2]。當(dāng)處理組個體全部匹配后,匹配結(jié)束。此法簡便易懂,常為研究者所選用,但當(dāng)匹配的兩組評分差異很大時該方法仍會進(jìn)行匹配,此時匹配效果較差。
2.卡鉗匹配法(caliper matching)
卡鉗匹配是在最近鄰匹配法的基礎(chǔ)上設(shè)定卡鉗值,即只有兩組觀察對象傾向性評分之差在卡鉗值范圍內(nèi)才能進(jìn)行匹配[9]。此法解決了最近鄰匹配法所存在的問題,但可能使大量觀察對象落在卡鉗值范圍外而被剔除,導(dǎo)致無法充分有效利用數(shù)據(jù),并產(chǎn)生抽樣偏倚。
3.分層匹配法(stratification matching)
分層匹配法根據(jù)某個重要變量,將兩組劃分為不同的層,分別計算每層的PS并進(jìn)行匹配,匹配后再將數(shù)據(jù)合并,以保證兩組研究人群中該變量分布完全相同[1]。此方法可保證兩組變量的平衡性,但如果匹配因素過多,則實(shí)際操作困難。分層匹配也可根據(jù)PS分層,以避免了混雜變量過多的問題[5]。
4.核匹配(kernel matching)和局部線性匹配法(local linear matching)
核匹配和局部線性匹配都屬于非參數(shù)匹配,對每個處理組個體,利用所有對照組個體的傾向性評分和結(jié)局變量的信息,以傾向性評分的差距為權(quán)重,計算加權(quán)后的對照個體效應(yīng)值,作為該處理個體的“反事實(shí)”匹配對象,所謂“反事實(shí)”就是不接受處理的假想情形。核匹配法類似于常數(shù)項(xiàng)回歸,假設(shè)如果Pi是處理組個體的傾向性評分,Pj是對照組個體j的傾向性評分,核匹配法的權(quán)重可表示如下:
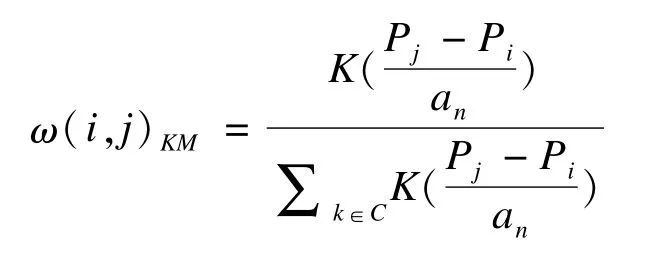

此類匹配方法避免了兩組評分分布重疊范圍小這一問題,將所有數(shù)據(jù)考慮在內(nèi),穩(wěn)定性更好。
5.回歸分析法
回歸分析法是傾向性評分和傳統(tǒng)回歸分析法相結(jié)合的一種方法。求得每個研究對象的傾向性評分后,評分作為協(xié)變量,以分組作為分析變量引入回歸模型,分析結(jié)果變量在協(xié)變量的影響下與分組變量的因果關(guān)系[5]。
6.基于馬氏距離的匹配法
馬氏距離由印度統(tǒng)計學(xué)家Mahalanobis提出,表示m維空間中兩個點(diǎn)之間的協(xié)方差距離,不受量綱的影響,還可以排除變量之間相關(guān)性的干擾[2]。處理組個體i與對照組個體j之間的馬氏距離d(i,j)可用以下公式計算:
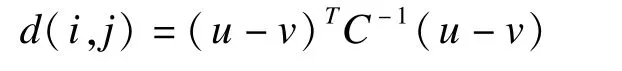
其中u和v分別代表處理組和對照組中配比變量的值,C是對照組全部對象配比變量配比的協(xié)方差陣[1]。PSM和馬氏距離結(jié)合后可增加個別重點(diǎn)變量的平衡能力。但此方法實(shí)現(xiàn)過程較為復(fù)雜,而且當(dāng)計算馬氏距離變量數(shù)量過多時也不宜應(yīng)用。
上述匹配方法的實(shí)現(xiàn)可基于諸多統(tǒng)計軟件,如R、SAS和STATA。以R為例,MatchIt,Matching,party 和rpart等包均可用于實(shí)現(xiàn)最近鄰匹配、卡鉗匹配、核匹配等匹配方法,其中以MatchIt應(yīng)用(多用于最近鄰匹配)最為廣泛。
PSM的優(yōu)缺點(diǎn)
1.優(yōu)點(diǎn)
PSM作為半?yún)?shù)方法,在處理模型函數(shù)形式上限制更少,對于誤差項(xiàng)的分布假設(shè)也更少,增加了處理組和對照組合理匹配的可能性。與傳統(tǒng)方法相比,在應(yīng)對多混雜因素或分層等問題時,使匹配具有了可能性,運(yùn)算量也大大減小,為研究提供高效合適的匹配。PSM可以保證研究客觀性,利用相似的協(xié)變量分布情況來構(gòu)建處理和對照組而不對研究結(jié)局產(chǎn)生影響[4]。
2.缺點(diǎn)
PSM只有當(dāng)不存在未觀測到的影響分組因素,且兩組評分分布重疊范圍夠大時才能保證結(jié)果的正確性,且根據(jù)重疊范圍來剔除對照組個體會造成偏倚,因此要求樣本量足夠大。此外,PSM多應(yīng)用于結(jié)局為分類變量研究[5],如果存在缺失值,傾向性評分同樣無法處理。當(dāng)重要混雜因素?zé)o法測量或者未知時,此方法也難以應(yīng)用[11]。
應(yīng) 用
國內(nèi)研究多將PSM用于臨床非隨機(jī)對照研究中治療方式的效果評價,如柯陽等[12]利用PSM評價治療巴塞羅那B期肝細(xì)胞癌的方法,發(fā)現(xiàn)PSM可以有效提高非隨機(jī)分組資料間協(xié)變量的均衡性;韓競等[13]利用PSM評價伽馬刀對垂體腺瘤的療效,同樣說明了PSM可以平衡組間的協(xié)變量。近些年隨著PSM越來越廣泛的應(yīng)用,也有研究者提出對該方法的應(yīng)用并非完全正確[14]。本文將通過以下案例來介紹PSM的基本步驟。
一項(xiàng)丹麥的研究利用多項(xiàng)醫(yī)學(xué)注冊數(shù)據(jù),比較不同胰島素促泌劑與二甲雙胍在治療有或無心肌梗塞史II型糖尿病患者中的死亡率和心血管風(fēng)險[15]。但各種藥物組的基本情況、共患疾病和合用心血管藥物的情況并不具有可比性,即協(xié)變量分布不均,故采用PSM均衡組間協(xié)變量。
PSM分四步:(1)計算傾向性評分,研究中基于基線信息中可能的混雜因素(年齡,性別,治療時間,充血性心衰,心律失常,周圍血管病,腦血管疾病和慢性肺病)對治療方法(某種胰島素促泌劑或二甲雙胍)建立logistic回歸方程,計算每例患者的PS得分;(2)采用最近鄰匹配,即二甲雙胍組為基準(zhǔn)組,分別選取其他各治療組中最近得分個體進(jìn)行匹配;(3)對匹配前、后的數(shù)據(jù)分別比較患者在重要的協(xié)變量方面是否均衡,匹配前兩組協(xié)變量差異比較的P值均小于0.05,匹配后P值均大于0.1,可見與匹配前相比匹配后協(xié)變量在組間實(shí)現(xiàn)均衡化;(4)采用Cox生存分析同時校正部分經(jīng)匹配仍不完全均衡的因素,發(fā)現(xiàn)所研究的六種胰島素促泌劑在全死因死亡和心血管事件死亡方面的保護(hù)效應(yīng)均不如二甲雙胍。
建 議
分析非隨機(jī)對照研究所得數(shù)據(jù)過程中,最大的阻礙就是混雜因素[16]。PSM作為一種均衡基線混雜因素的方法,與傳統(tǒng)方法相比有其獨(dú)特的優(yōu)勢,使得非隨機(jī)對照研究數(shù)據(jù)得以有效分析。除了在臨床研究中的廣泛應(yīng)用外,在公共衛(wèi)生領(lǐng)域,PSM在基于人群的健康干預(yù)研究和效果評價中也有廣泛的應(yīng)用前景。
但并非任何非隨機(jī)對照研究都可以使用PSM,如在樣本量比較小的情況下,該方法無法解決協(xié)變量實(shí)質(zhì)性失衡這一問題[17],因此要根據(jù)實(shí)際情況和PSM的使用條件來應(yīng)用。有研究表明,采用PSM的觀察性研究與隨機(jī)對照試驗(yàn)相比,處理因素對結(jié)局的影響會被放大,但差異無統(tǒng)計學(xué)意義[18]。此外PSM可采用多種匹配方法,每種方法都有其自身特征,研究者需根據(jù)每種方法所適應(yīng)的情況來應(yīng)用。從科學(xué)的角度而言,并沒有一種絕對好的方法,但無論采用何種方法,都需正確評估研究發(fā)現(xiàn)的前提,并認(rèn)真正確的分析和報告。
參考文獻(xiàn)
[1]詹思延.流行病學(xué)進(jìn)展.北京:人民衛(wèi)生出版社,2010,12:358-376.
[2]李智文,等.傾向評分配比在流行病學(xué)設(shè)計中的應(yīng)用.中華流行病學(xué)雜志,2009,30(5):514-517.
[3]Austin PC.The performance of different propensity-score methods for estimating differences in proportions(risk differences or absolute risk reductions)in observational studies.Stat Med,2010,29(20):2137-2148.
[4]Borah BJ,et al.Applications of propensity score methods in observational comparative effectiveness and safety research:where have we come and where should we go?J Comp Eff Res,2014,3(1):63-78.
[5]胡紅林,傾向評分法在醫(yī)學(xué)研究中的應(yīng)用和分析,華中科技大學(xué),2009.
[6]Austin PC.An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies.Multivariate Behav Res,2011,46(3):399-424.
[7]吳美京,等.傾向性評分法中評分值的估計方法及比較.中國衛(wèi)生統(tǒng)計,2013(3):440-444.
[8]Kheterpal S,et al.Development and validation of an acute kidney injury risk index for patients undergoing general surgery:results from a national data set.Anesthesiology,2009.110(3):505-15.
[9]鄔順全,吳騁,賀佳.傾向性評分匹配法在多分類數(shù)據(jù)中的比較和應(yīng)用.中國衛(wèi)生信息管理雜志,2013(5):448-451.
[10]Heckman J J,et al.Sources of selection bias in evaluating social programs:an interpretation of conventional measures and evidence on the effectiveness of matching as a program evaluation method.Proc Natl Acad Sci U S A,1996,93(23):13416-20.
[11]Groenwold,R.H.,[Propensity scores in observational research].Ned Tijdschr Geneeskd,2013,157(29):A6179.
[12]柯陽,等.傾向性評分匹配法對巴塞羅那B期肝細(xì)胞癌兩種治療方法的再評價.中華醫(yī)學(xué)雜志,2014,94(10):747-750.
[13]韓競,王彤,郭軍.傾向性評分方法及其在伽瑪?shù)吨委煷贵w腺瘤療效評價中的應(yīng)用,2011,4757-4761.
[14]Pattanayak C W.D.B.Rubin,E.R.Zell.Propensity score methods for creating covariate balance in observational studies].Rev Esp Cardiol,2011,64(10):897-903.
[15]Schramm T K,et al,Mortality and cardiovascular risk associated with different insulin secretagogues compared with metformin in type 2 diabetes,with or without a previous myocardial infarction:a nationwide study.Eur Heart J,2011,32(15):1900-1908.
[16]Austin,P.C.,Type I error rates,coverage of confidence intervals,and variance estimation in propensity-score matched analyses.Int J Biostat,2009,5(1):Article 13.
[17]Biondi-Zoccai G,et al.Are propensity scores really superior to standard multivariable analysis?Contemp Clin Trials,2011,32(5):731-40.
[18]Dahabreh I J,et al.Do observational studies using propensity score methods agree with randomized trials?A systematic comparison of studies on acute coronary syndromes.Eur Heart J,2012,33(15):1893-901.
(責(zé)任編輯:鄧 妍)
*基金項(xiàng)目:美國中華醫(yī)學(xué)基金會(CMB#11-074)
通信作者:△顧菁,E-mail:gujing5@ mail.sysu.edu.cn
猜你喜歡
體育科技文獻(xiàn)通報(2022年3期)2022-05-23 13:46:54
天津外國語大學(xué)學(xué)報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
兒童故事畫報(2019年5期)2019-05-26 14:26:14
民用飛機(jī)設(shè)計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學(xué)報(2017年2期)2017-07-05 08:13:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
