手機游戲大數據實時計算框架研究與實踐
2016-05-14 04:35:02陳杰蘇洋唐勇龐濤
移動通信 2016年5期
關鍵詞:大數據
陳杰 蘇洋 唐勇 龐濤

【摘 要】為了滿足移動終端游戲的精準運營需求,需要收集用戶行為數據,實時分析業務狀態,深度挖掘市場價值。基于Kafka、Flume、Storm、Redis等開源技術,構建了手機游戲大數據實時計算系統,實現了海量實時數據的采集、存儲、計算和查詢,并在現網實際系統中得到了成功應用。
【關鍵詞】大數據 實時計算 開源 手機游戲
doi:10.3969/j.issn.1006-1010.2016.05.017 中圖分類號:TP399 文獻標識碼:A 文章編號:1006-1010(2016)05-0079-06
引用格式:陳杰,蘇洋,唐勇,等. 手機游戲大數據實時計算框架研究與實踐[J]. 移動通信, 2016,40(5): 79-84.
1 引言
在移動互聯網時代,以手機游戲為代表的移動應用得到了飛速的發展。為了實現精細化運營,迫切要求針對海量數據能夠實現實時計算結果以及秒級響應速度。以移動終端手機游戲平臺為例,需要處理的流式數據主要包括手機游戲用戶的PV/UV數值、頁面瀏覽情況、手機游戲內容查找/登錄/支付情況等,這些均要求實時數據的計算和分析,以便可以動態地獲取用戶訪問數據,展示手機游戲平臺實時流量的變化情況和用戶行為習慣等。面對海量的業務數據量,傳統的窮舉所有可能條件的查詢組合或者窮舉條件組合的方法失效。
基于分布式處理機制和實時計算架構,將計算過程移至查詢階段,才能滿足互聯網業務海量數據計算和快速查詢響應的需求。
2 實時計算處理流程
對互聯網業務的海量數據(主要為日志流)的實時計算可劃分為三大主要階段:數據采集、實時計算處理分析和實時查詢展示階段。
在數據采集階段,通常采用主要互聯網公司提供的開源的海量數據采集工具,滿足每秒數百MB的日志數據采集和傳輸要求,如Facebook的Scribe、LinkedIn的Kafka、Cloudera的Flume,淘寶的TimeTunnel、Hadoop的Chukwa等。
在數據實時計算分析階段,首先將數據采集并存儲在DBMS(Database Management System,數據庫管理系統)中,然后通過查詢和DBMS進行交互。但對于現階段大量存在的實時數據,比如手機游戲交易/支付的數據,一般采用流計算技術。
在實時流計算框架方面,Yahoo推出的開源架構S4,Twitter使用的Storm,以及業界較為常見的Esper、Streambase、HStreaming等相關技術架構,均基于分布式并行計算(節點間的并行、節點內的并行)和熱點數據的緩存處理等技術,提供實時計算服務。
在實時查詢展示階段,按照前端展示或者計算結果存儲位置的不同可分為:1)直接提供數據讀取服務,定期采用進程的內存鏡像到磁盤或數據庫全內存方法;2)采用Redis、Memcache、MongoDB、BerkeleyDB等內存數據庫提供數據實時查詢的半內存方法等。
3 手機游戲大數據實時計算
本文提出了手機游戲大數據實時計算架構,采用Kafka+Flume集群完成實時數據采集,利用Storm框架完成數據實時計算,采用Redis+HBase模式構建查詢服務,滿足了數據本地磁盤存儲的安全性和長久性,實現基于內存提升查詢速度。
3.1 實時計算架構
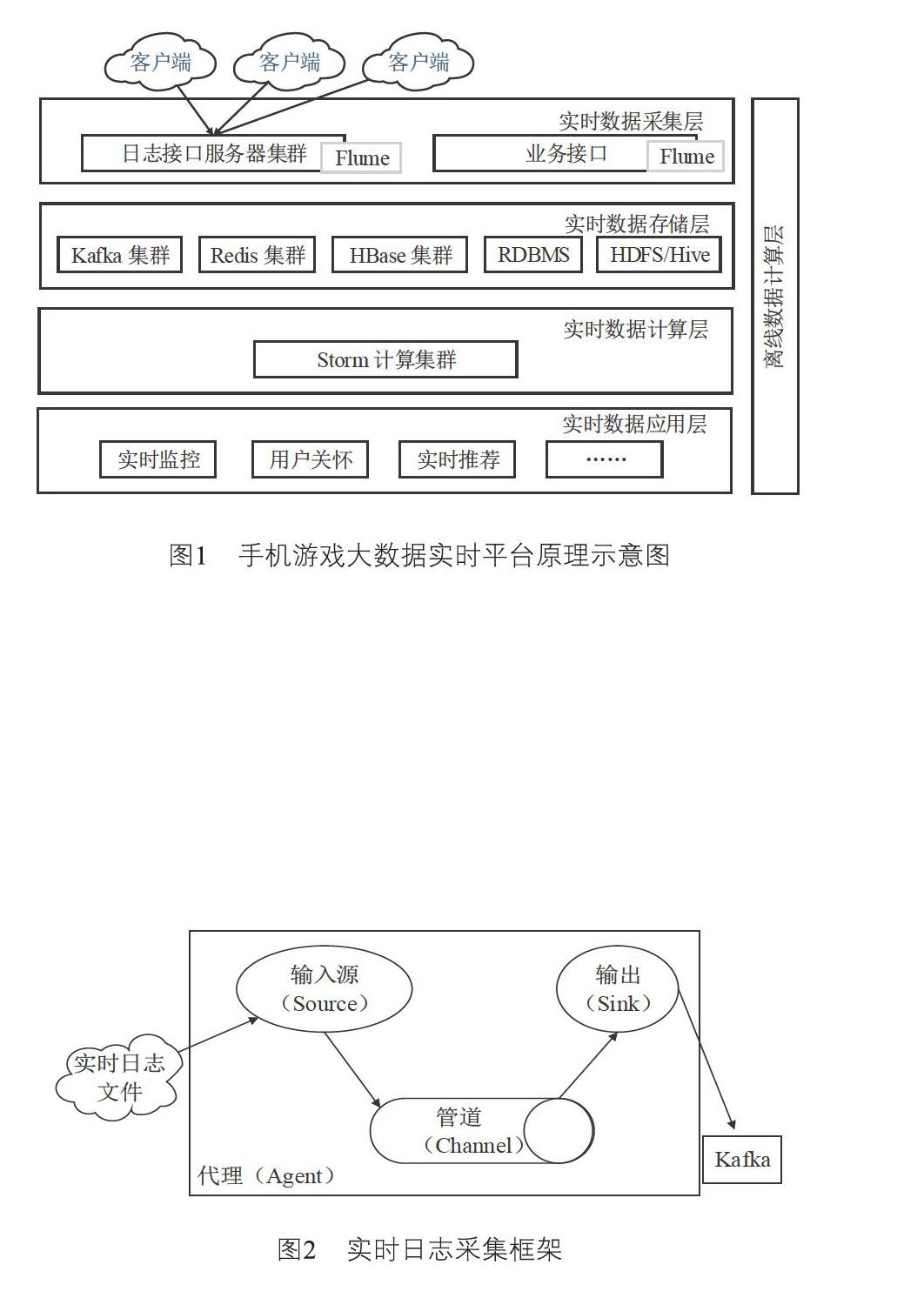
穩定可靠且高效的底層架構是實時計算的必要基礎。圖1給出了手機游戲大數據實時計算平臺的總體框架,如圖所示包含數據采集、數據存儲、數據處理、數據應用四個層級。
數據采集對象主要是全體日志數據。按照統一規則整合,為數據應用提供實時數據。手機游戲日志主要包括兩大來源,一是日志服務器集群實時上傳的日志;二是業務接口后臺服務器實時打印的日志。實時日志采集框架如圖2所示:
將Flume部署在上述兩大類日志源服務器上,作為海量日志實時采集的框架。如圖2所示,Flume NG節點由Source、Channel、Sink三部分組成。Channel將Source和Sink連接起來。Flume的Source將外部數據源傳遞的數據封裝成Flume數據模型的最小單位event。該數據源主要是業務接口實時產生的日志文件,使用操作系統原生類型exec來執行命令:tail-f/pathname/filename.xxx采集。此方式簡單可靠,適合采集業務接口實時打印的日志。同時還需要打開Source的restart開關,當進程由于某種原因僵死后,可以自動重啟。手機游戲行為數據由客戶端統計SDK和業務接口產生。為了更好地區分有效日志與程序調試或其它用途的內容,約定了統一的實時日志前綴“[REALDATA]”來減少Flume Agent的日志量,提高了日志采集效率。
數據存儲層提供了實時數據處理層需要的類分布式存儲,主要采用了分布式消息隊列(Apache Kafka)和Apache Zookeeper。通過Flume NG節點的Sink配置a2.sinks.k1.type=org.apache.flume.sink.KafkaSink,采集數據并實時存放在Kafka中。
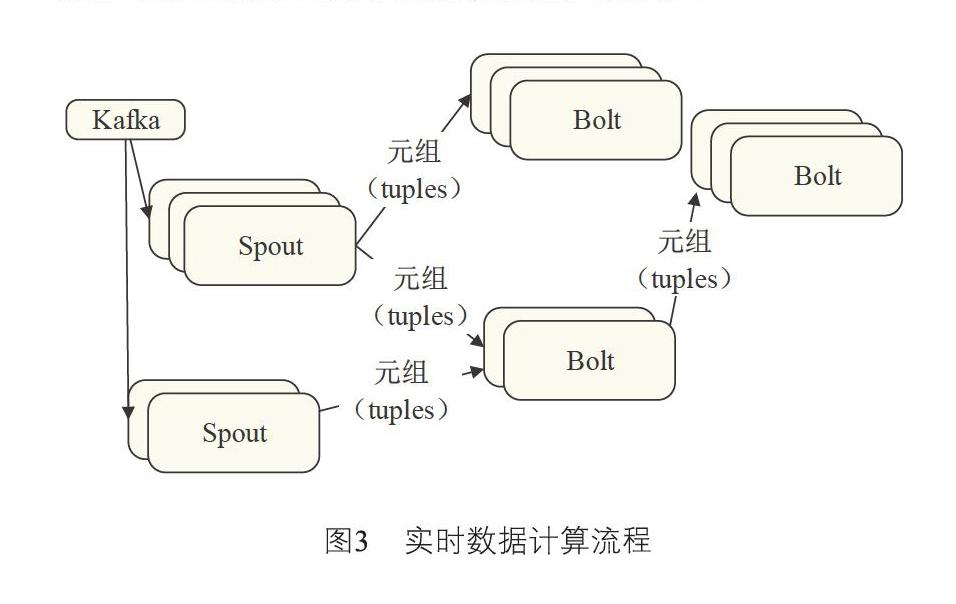
數據實時處理層采用Storm實時從Kafka獲取數據。在Storm中,首先需要設計一個用于實時計算的圖狀結構拓撲。拓撲將被提交給集群,由集群中的主控節點分發代碼,將任務分配給工作節點執行。一個拓撲中包括Spout和Bolt兩種角色,Spout發送消息,負責從Kafka中將數據流以tuple元組的形式發送出去;Bolt則負責轉換這些數據流,完成計算、過濾等操作。Bolt自身也可以隨機將數據發送給其他Bolt。由Spout發射出的tuple是不可變數組,對應著固定的鍵值對。相關的組件架構和數據流如圖3所示:
Storm計算后的數據結果將被實時地寫入Redis緩存、Mysql、HDFS、HBase中。其中寫入Redis的數據用于實時展示運算結果,寫入Mysql、HDFS中的數據用于后續的離線計算任務,寫入HBase的數據可當作中間結果使用。
在實時數據應用層,將根據業務的需要來開發各類實時應用,比如手機游戲分發平臺實時用戶數、下載量、收入等。
3.2 實時計算方法
要實現大數據實時計算,僅有框架是不行的,還必須為每個業務設計一套專用的處理流程和算法。與離線計算相比,實時計算在算法上需要考慮的情況更復雜,這是因為實時計算所用到的存儲資源遠不如離線數據,但處理的時間限制要比離線計算嚴格,這都要求實時計算算法必須做更多的優化來提升計算的效率。
以下將以中國電信愛游戲基地手機游戲業務的海量計數需求為例,設計和優化相關實時計算算法。目前愛游戲手機游戲業務包含近千萬的用戶下載、手機游戲啟動和付費數據,實時追蹤這些數據是必須的,這也是個性化推薦、付費預測和用戶畫像等業務的前提。為此,急需設計一種算法可實時查看任意用戶近24小時的下載次數、啟動次數、付費次數等業務指標。
(1)簡化方案
簡化方案示意圖如圖4所示:
圖中藍色、黃色和綠色表示不同的用戶,此方案為每個用戶保存一份付費信息,它包含兩個數據結構:
a)歷史付費列表(簡稱“歷史”),該列表中每個元素包含一個時間戳和一個整數,分別代表過去24小時中某一秒鐘的啟動數據并按時間排序。該列表最多可包含24×3600=86400個元素,但一般情況不會超過100個。
b)累計付費數據(簡稱“累計量”),代表截止到最后一次付費時的付費次數。
如圖4所示,假設藍色用戶對應的數據是[(t1,a1), (t2,a2), …, (tn,an)]和A。這表示t1時刻的用戶付費次數是a1,t2時刻是a2,以此類推,累計量是A。當用戶付費數據不斷進入消息隊列時,處理進程(或者線程)P1, P2…會實時讀取到這些信息并修改對應用戶的數據。如P1讀取到t時刻藍色用戶的付費記錄時,會進行下面的操作:
a)得到當前時刻ct;
b)對數據庫中藍色用戶加鎖,加鎖成功后讀取數據,假設為[(t1,a1), (t2,a2), …, (tn,an)],累計量為A;
c)累計量遞增:A=A+1;
d)歷史量更新:如果ct=tn,[(t1,a1), (t2,a2), …, (tn,an+1)],否則更新為[(t1,a1), (t2,a2), …, (tn,an), (ct,1)];最后刪除時間戳小于ct-24×3600的元素,刪除的同時從累計量中減去對應時刻的啟動量;
e)將新的歷史和累計量輸出至數據庫并釋放鎖。
此方案可正確得到每個用戶24小時內的付費次數,并且只要在資源(計算、存儲和網絡)充足的情況下,數據庫中用戶的付費次數是實時更新的。此方案也是分布式實時計算中最簡單、最常見的一種。
(2)優化方案
簡化方案中需要對數據庫加鎖,無論加鎖的粒度有多細,都會影響計算效率。要想提高實時處理效率,減少鎖是非常重要的。一種常見的做法是將并行操作串行化,MapReduce中的Reduce,將key相同的數據交給同一個Reducer處理。基于此原理將方案改造如圖5所示:
新增一個key的HASH處理,保證相同的用戶可以落到相同的處理程序上。由于不存在資源競爭,處理過程不需要對數據庫加鎖。此方案可大大提高計算效率,整個計算過程變為:
b)讀取藍色用戶數據,設為[(t1,a1), (t2,a2), …, (tn,an)],累計量為A;
c)累計量遞增:A=A+1;
d)歷史量更新:如果ct=tn, [(t1,a1), (t2,a2), …, (tn,an+1)],否則更新為[(t1,a1), (t2,a2), …, (tn,an), (ct,1)];最后刪除時間戳小于ct-24×3600的元素,刪除的同時從累積量中減去對應時刻的啟動量;
e)將新的歷史和累計量直接輸出至數據庫。
步驟b)和e)省去了鎖操作,整個系統的并發和吞吐量均大大提高。但此方案的缺點是存在單點隱患。一旦P1由于某些原因失效,則藍色用戶的數據將得不到及時處理,計算結果將無法實時保障。
在上述計算步驟b)和e)中總是把歷史和累計量從數據庫中讀寫。但在實際應用中只關心實時累計值,而歷史數據僅用于計算累計值,并不需要實時持久化。為此,在最終方案中,區別對待歷史和累計量,將歷史和累計量都緩存在計算進程中,定期更新歷史數據到數據庫,而累計量則實時更新。最終改良優化的方案如圖6所示:
計算過程為:
b)如果本地沒有藍色用戶信息,從數據庫中讀取藍色用戶數據;否則直接使用本地緩存信息。假設為[(t1,a1), (t2,a2), …, (tn,an)],累計量為A;
d)將新的累積量輸出至數據庫,如果滿足一定條件(距離上次時間間隔足夠遠,或者積累的消息達到一定量),則將歷史數據輸出至數據庫。
最終方案可大大降低數據庫壓力、I/O和序列化反序列化次數,從而提高效率。此方案對系統的穩定性要求更高,一旦P1失效則緩存數據將永久丟失。
(3)存儲模糊化處理方案
在數據存儲時,假設時間戳和整型均為long型(8字節),按照簡化方案估算,每個用戶所需要保存的歷史數據大小為100×(8+8)=1600字節≈1.56kB,1000萬用戶的總量將有15G。若考慮到數據庫和本地緩存,則系統存儲量至少要30G,由此存在較大的空間浪費。
在優化過程中,為了降低歷史的存儲密度,將精度定義為小時級別,這樣每個用戶歷史數據為24個,數據量為384字節,1000萬用戶的數據總量為3.6G,數據庫和緩存的總存儲量不超過8G。更近一步,使用一個字節保存當前小時段,使用包含24個long型的數組表示付費次數,則數據量將固定在196個字節,總存儲量不超過4G。步驟如下:
a)得到當前時刻精確到小時的部分ct;
b)如果本地沒有藍色用戶信息,從數據庫中讀取藍色用戶數據;否則直接使用本地緩存信息。假設為[time, a1, a2, …, a24],累計量為A;
c)累計量遞增:A=A+1;
d)歷史量更新:令當前小時段為hour,如果ct=time,[time, a1, a2, …, ahour+1, …, a24],否則更新為[ct, a1, a2, …, 1, …, a24];最后將時間坐標小于ct-24的元素置為0,同時A減去對應時刻的付費數;
e)將新的累積量輸出至數據庫,如果滿足一定條件(距離上次時間間隔足夠遠,或者積累的消息達到一定量),則將歷史數據輸出至數據庫。
存儲模糊化處理示意圖如圖7所示:
4 應用效果
4.1 實時業務監控
為了實時監控手機游戲平臺的訪問、下載、收入等情況,將實時統計好的數據包存放在Redis中,然后搭建web監控系統,圖形化展示多維度的實時數據。同時針對重要的業務接口,監控每分鐘的連接數等指標,及時發現異常日志并報警,可有效識別出攻擊和惡意用戶點擊行為。經實際測算,每秒平均運算量超3000條,峰值超10 000條,日處理日志總數超3億條。
4.2 用戶實時關懷
為了提醒用戶的消費行為,需要實時計算所有用戶每一次的付費行為。如當用戶的付費總額達到某一閾值,或首次在平臺、渠道進行付費時,該系統會立刻給用戶發送關懷短信,提醒用戶的消費行為,或提醒其參加抽獎等營銷活動。
該功能上線后,新增付費用戶的注冊轉化率提升3.3%,手機游戲平臺投訴用戶下降明顯,萬投比下降8.2。
5 結束語
本文采用Kafka+Flume集群完成實時數據采集、采用Storm框架完成數據實時計算、采用Redis+HBase模式構建實時查詢服務,構建了手機游戲大數據實時計算系統。在實時計算方面,為了滿足千萬級業務數據的實時查詢需求,設計了兩種算法。一是需要數據加鎖的簡化計算方案,二是為了提高效率,去除數據鎖的并行操作分布式串行化處理的優化方案,同時還進行了數據分層處理優化,降低了數據庫壓力。在數據存儲方面,結合模糊化處理方式優化數據存儲,將存儲資源要求減少到常規的12%。本項目成果在中國電信愛游戲基地平臺得到了成功應用,每秒平均運算量超3000條,峰值超10 000條,日處理日志總數超3億條。該框架可為其他業務平臺大數據實時計算提供良好的參考和借鑒。
參考文獻:
[1] 蘇洋,劉曉軍,唐勇,等. 游戲大數據平臺研究與實踐[J]. 電信科學, 2014(10): 21-26.
[2] 周江,王偉平,孟丹,等. 面向大數據分析的分布式文件系統關鍵技術[J]. 計算機研究與發展, 2014(2): 382-394.
[3] 胡宇舟,范濱,顧學道,等. 基于Storm的云計算在自動清分系統中的實時數據處理應用[J]. 計算機應用, 2014(S1): 96-99.
[4] 唐云善,楊志. 一種高效的大數據實時性解決方案[J]. 計算機與數字工程, 2014(4): 678-684.
[5] 趙輝,楊樹強,陳志坤,等. 基于MapReduce模型的范圍查詢分析優化技術研究[J]. 計算機研究與發展, 2014(3): 606-617.
[6] 張華,王東輝,吳烜. 流式計算的分布式框架的應用[J]. 信息與電腦:理論版, 2014(10): 142-143.
[7] 黃馥浩. 基于Storm的微博互動平臺的設計與實現[D]. 廣州: 中山大學, 2013.
[8] 高鵬. 當新媒體遇到“大數據”[J]. 廣播與電視技術, 2012(10): 38.
[9] 劉林林. 大數據時代數據分析與信息安全[J]. 網絡安全技術與應用, 2013(12): 59.
[10] 呂明育. Hadoop架構下數據挖掘與數據遷移系統的設計與實現[D]. 上海: 上海交通大學, 2013.
[11] 謝超. 大數據下的數據分析平臺架構[J]. 程序員, 2011(8): 55-58. ★
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
