基于KECA的化工過程故障監測新方法
2016-05-11 02:15:14齊詠生張海利高學金王普內蒙古工業大學電力學院內蒙古呼和浩特0005北京工業大學電子信息與控制工程學院北京004教育部數字工程研究中心北京004
化工學報 2016年3期
關鍵詞:安全
齊詠生,張海利,高學金,王普(內蒙古工業大學電力學院,內蒙古 呼和浩特 0005;北京工業大學電子信息與控制工程學院,北京 004;教育部數字工程研究中心,北京 004)
?
基于KECA的化工過程故障監測新方法
齊詠生1,3,張海利1,高學金2,3,王普2,3
(1內蒙古工業大學電力學院,內蒙古 呼和浩特 010051;2北京工業大學電子信息與控制工程學院,北京 100124;3教育部數字工程研究中心,北京 100124)
摘要:針對化工過程數據復雜、非線性的特點,提出一種基于核熵成分分析(KECA)的化工過程故障監測算法。首先,KECA算法按照Renyi熵值的大小選取特征值及特征向量,相比傳統的KPCA監測算法,其保留主元個數更少,可以有效減少運算量。同時,仿真研究表明KECA算法選取的主元具有角度結構特性,據此,提出一種新的統計量——CS(Cauchy-Schwarz)統計量,其對應到核特征空間中即為向量間的角度余弦值,可以較好表述不同概率密度分布之間的相似度。最后,將KECA和KPCA算法分別應用于TE(Tennessee Eastman)過程,結果表明KECA在故障檢測延遲與檢出率相比KPCA都有很大的優勢。
關鍵詞:安全;過程控制;主元分析;故障監測;KECA;CS統計量
2015-12-14收到初稿,2015-12-16收到修改稿。
聯系人及第一作者:齊詠生(1975—),男,博士,副教授。
引 言
化工過程工藝復雜且常伴隨高溫高壓等極端條件,原材料及產品具有易燃易爆、有毒有害等特點,且生產裝置呈現大型化和連續化。一旦出現異常或事故就會破壞正常生產過程,不但可能影響生產進度,還有可能危及人們的生命安全,造成巨大的損失。所以,對化工過程進行故障監測研究就顯得非常重要[1-4]。近年來,將多元統計分析應用于化工過程監控中,形成了多元統計過程監控(multivariate statistical process monitoring,MSPM)。其基本思想是通過構造一組維數較低的不相關的隱變量來概括高維數據所攜帶的信息。常見的多元統計過程監控方法有主元分析(principal component analysis,PCA)[5]、偏最小二乘算法(partial least squares,PLS)[6]、獨立主元分析(independent component analysis,ICA)[7]以及這些算法的一些改進算法等。
多元統計監控[8]的核心思想是通過數據投影的方法將輸入空間劃分為特征空間和殘差空間達到數據降維的效果,檢測平方預測誤差(squared prediction error,SPE)、Hotelling T2(T2)等統計量是否超越控制限來判斷過程是否發生異常情況。其中,PCA算法應用最為廣泛,它可以有效將含噪聲且相關的高維數據以保留原始數據的最大方差的原則投影到低維空間。然而,PCA算法的前提是假設數據為線性[9-10],它對于非線性過程的監控效果并不十分理想。Scholkopf等[11]提出了核主元分析(KPCA),KPCA是通過非線性映射將原輸入空間映射到高維特征空間,然后在這個高維特征空間內進行主元分析,從而把輸入空間中的非線性問題轉化為特征空間中的線性問題[12-13]。
Jenssen[14]在KPCA的基礎上提出KECA算法用于數據轉換和數據降維,在提取數據特征上表現出了其獨特的優越性。KECA算法通過將輸入空間投影到KPCA主軸上實現數據的轉換和降維,它與KPCA最大的不同是通過對輸入空間熵值的貢獻大小來選取主元[15],因此,KECA算法選取的主元不一定對應于核矩陣較大的特征值和特征向量,且結果顯示KECA選取的主元具有一定的角度結構,即不同類別數據的主元分別聚集在不同的坐標軸 附近。
本文將KECA算法應用于過程故障監測中,基于KECA選取主元的角度結構,定義了一種新的統計量表達這種角度結構,與KPCA監控算法的SPE統計量和Hotelling T2統計量相比,具有一定的優勢。
1 KECA算法
給定N維樣本x,p(x)是概率密度函數,則其Renyi熵計算公式為[16]

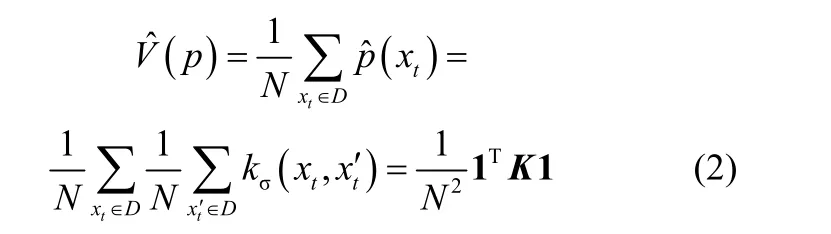
式中,K為N×N的核矩陣;1為元素均為1 的N×1的向量。Renyi熵估計可由核矩陣的特征值和特征向量來表示,將核矩陣進行特征分解D為特征值矩陣D =為特征向量矩陣,計算得到式(3)

將N維數據通過Ф映射到由k個KPCA主軸張成的子空間Uk上,選取對Renyi熵貢獻較大的前k個特征值和特征向量,不一定是特征值較大的前k個,可以得到轉換后的數據
樣本外數據投影到Uk上的計算公式為


KECA算法可以表述為使核空間數據均值向量的平方歐氏距離與轉換后數據均值向量的平方歐氏距離之差盡可能小。為了能夠更多保留原始數據的信息,在數據降維時采用熵值貢獻率來確定選取主元的個數。

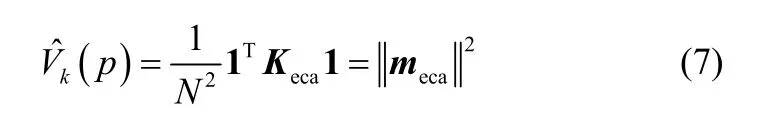

KECA算法實質是一種數據轉換方法,它可以最大限度保留核空間數據均值向量的歐氏距離。對TE過程的21種故障均選取3個主元,降維后數據保留原始數據在核特征空間均值向量的比值可達到99%。而KPCA需要選取大約26個主元,其方差貢獻率方能達到80%以上。
2 新的監控統計量——CS統計量
CS散度測度衡量兩種概率密度函數p1(x)和p2(x)之間的“距離”,表示的是兩種概率密度函數之間的相似度[17-18],計算公式如下其中,0≤DCS<∞,當且僅當p1(x)= p2(x)時取得最小值。
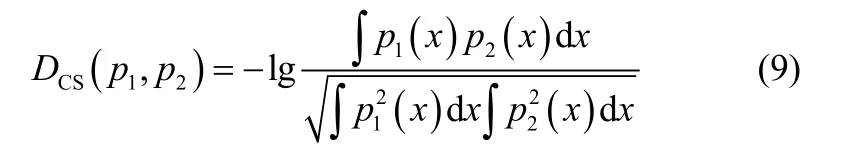
概率密度分布函數之間的CS散度測度可以表示為核空間均值向量之間角度的余弦值[18]。例如,概率密度函數p1( x )和p2( x )之間的CS散度測度為

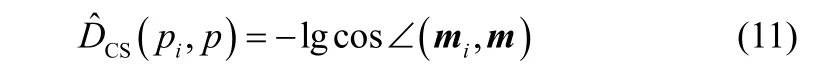
在此,
3 基于KECA的故障監測模型
3.1 建立離線模型
(1)將正常數據與故障數據組成新的建模數據,并對其按正常數據的均值及方差進行標準化
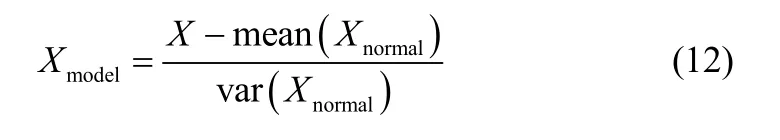
(2)給定核函數(本文采用高斯核)及核參數,利用建模數據進行KECA建模,選取較大熵值對應的特征值及特征向量,對投影后的正常數據求均值m。
需要注意的是,本文需要建立21個模型,每個模型數據由正常數據和一種故障數據組成,因此,不同的模型具有不同的控制限。
3.2 在線監測
(1)將測試數據同樣按上述正常數據的均值及方差進行標準化,然后進行核空間映射,計算,計算與m之間的角度余弦值,即CS統計量。
(2)通過判斷CS統計量是否超過控制限來確定工業過程是否產生了故障。
4 結果及分析
采用TE過程的數據進行仿真,TE過程共52個變量,21個故障。訓練數據及測試數據均包括1組正常數據及21組故障數據。訓練數據每隔3 min采樣一次,共采樣500次計時25 h,采樣點個數為500。其中,對于21組故障數據,1 h后引入故障,即故障前20個采樣點屬于正常數據,仿真只采用剩下的480個故障數據點進行建模,前20個正常數據點不予考慮。因此訓練數據共22組,包括1組500× 52的正常數據及21組480×52的故障數據[19-20]。
同樣,測試數據中也有1組正常數據和21組故障數據,每隔3 min采樣一次,共采樣500次計時48 h,采樣點個數為960,其中,對于故障數據,8 h后引入故障,即從第161個采樣點開始為故障數據點。因此,測試數據包括1組正常數據及21組故障數據,其維數為960×52,其中故障數據維數為800×52[19-20]。
仿真過程選取的核函數為高斯核函數,保留主元個數為3,保留了超過99%的熵值信息,而KPCA保留主元個數約為26,方差貢獻率約為80%,在此,分別將KECA及KPCA方法用于故障3、10、15、21,故障監測結果如下,由于T2統計量的故障監測效果不如SPE統計量,故僅選擇了SPE統計量與CS統計量進行比較。
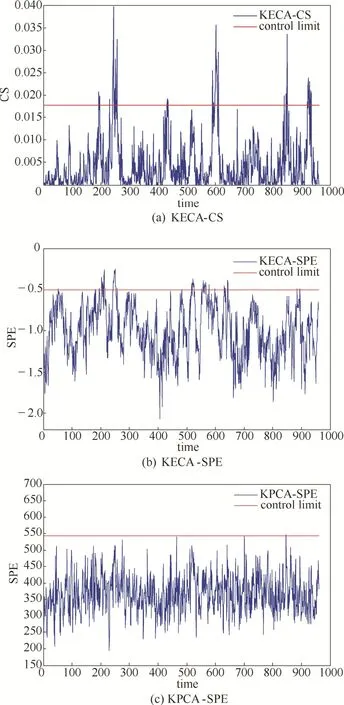
圖1 故障3的監測結果Fig.1 Monitoring charts of fault 3 for KECA-CS, KECA-SPE and KPCA-SPE
基于KECA-CS、KECA-SPE[21]及KPCA-SPE方法對故障3的故障監測結果如圖1所示。大多故障檢測算法都不能夠有效地將該故障檢測出來,KPCA算法的仿真結果較為混亂,且統計量幾乎一直在控制限以下。KPCA-SPE及KECA-SPE算法在整個測試過程,統計量都沒有明顯的變化,并不能有效地將故障3檢測出來,而采用KECA-CS算法,則可以很清楚地看到有兩個比較明顯的峰值點遠遠超出了控制限,且正常時刻的統計量沒有超限,能夠有效地檢測出故障3。這是因為KECA在數據特征提取上較KPCA算法有優勢,且CS統計量很好地表示了KECA算法所揭露的數據間的角度結構,因此能夠有效地將故障數據及正常數據分離開。
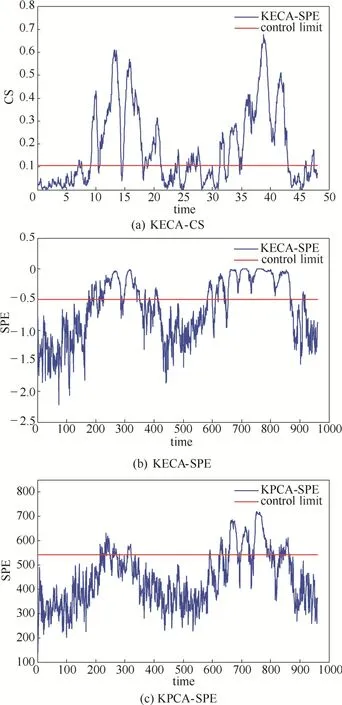
圖2 故障10的監測結果Fig.2 Monitoring charts of fault 10 for KECA-CS, KECA-SPE and KPCA-SPE
故障10的仿真結果如圖2所示。3個圖中均有兩個比較明顯的峰值,其中KPCA-SPE方法僅超過控制限一小部分,而KECA-CS方法超過控制限的部分要遠遠多于另外兩種方法。同時,KECA-CS方法檢測出故障的時間也要比另兩種提前,即檢測延遲少。KECA算法提取正常數據及故障數據間的角度信息,CS統計量將其很好地表示出來,有利于故障監測。因此,KECA-CS方法要優于另兩種。
故障15及20的故障監測結果分別如圖3、圖4所示。對于故障15,KPCA-SPE方法幾乎不能檢測出故障,KECA-SPE方法則可以明顯檢測出故障,而KECA-CS不僅能明顯檢測出故障,時間也遠遠早于其他方法。KECA算法提取并由CS統計量表示的角度信息提高了故障監測的敏感性。對于故障20,3種方法均能有效檢測故障,不同之處在于KECA-CS方法在故障引入120 min處檢測出故障,而KPCA-SPE及KECA-SPE方法則在270 min處方能檢測出故障,很明顯,KECA-CS方法檢測故障要提前很多。總之,對于上述幾種故障,相比KPCA-SPE及KECA-SPE方法,KECA-CS方法具有更好的故障監測效果。

圖3 故障15的監測結果Fig.3 Monitoring charts of fault 15 for KECA-CS, KECA-SPE and KPCA-SPE

圖4 故障20的監測結果Fig.4 Monitoring charts of fault 20 for KECA-CS, KECA-SPE and KPCA-SPE
為衡量算法對TE過程的故障監測能力,使用檢測延遲(detection latency,DL)[20]、檢出率(fault detection rate,FDR)和誤報率(false alarm rate,FAR)[21]。其中檢測延遲為算法檢測出故障的時間與實際故障發生時間的差值,檢出率為檢出故障數與故障樣本總數的比值,誤報率誤報為故障數與正常樣本總數的比值,計算公式如式(13)~式(15)所示。TE過程21種故障的檢測延遲、檢出率及誤報率計算結果見表1,表明了本文算法的有效性。對KECA算法,幾乎所有故障的檢測延遲都少于KPCA算法,且故障3、4、10、11、15、20故障檢出率都明顯高于KPCA算法,兩種方法的誤報率都較低,相差較小。KECA-CS方法在檢測工業過程中的微小故障上具有更高的敏感性,TE過程數據的仿真證明了KECA-CS算法在故障實時監測上的可行性及有效性。


表1 TE過程21種故障的檢測延遲和故障檢出率Table 1 Detection latency (DL) and fault detection rate (FDR) for all 21 faults in TE process
5 結 論
將KECA算法用于TE過程的故障監測。首先,引入Renyi信息熵并以熵值大小選取主元,在數據降維的過程中減少了信息的丟失,既實現了主元選取個數較少,又使降維后數據仍保留了原始數據在核特征空間99%以上的信息熵值。其次,KECA算法選取出的主元具有一定的角度結構,這是在KPCA算法中所沒有的。在該角度結構的基礎上應用一種新的CS統計量,能夠較好表述不同類數據之間概率密度分布的相似度。通過分別將KECA及KPCA算法應用于TE過程對比發現,KECA算法在檢測延遲及檢出率方面具有較為顯著的優勢。實驗仿真結果表明,基于KECA的過程故障監測算法是行之有效的。
References
[1] 周東華, 李鋼, 李元. 數據驅動的工業過程故障診斷技術: 基于主成分分析與偏最小二乘的方法 [M]. 北京: 科學出版社, 2011: 1-9.
ZHOU D H, LI G, LI Y. Industrial Process Fault Diagnosis Technology of Data Driven: Based on Principal Component Analysis and Partial Least Squares Method [M]. Beijing: Science Press, 2011: 1-9.
[2] 馬賀賀, 胡益, 侍洪波. 基于馬氏距離局部離群因子方法的復雜化工過程故障檢測 [J]. 化工學報, 2013, 64 (5): 1674-1682. DOI: 10.3969/j.issn.0438-1157.2013.05.024.
MA H H, HU Y, SHI H B. Fault detection of complex chemical processes using Mahalanobis distance-based local outlier factor [J]. CIESC Journal, 2013, 64(5): 1764-1682. DOI: 10.3969/j.issn.0438-1157.2013.05.024.
[3] 韓敏, 張占奎. 基于改進核主成分分析的故障檢測與診斷方法 [J].化工學報, 2015, 66 (6): 2139-2149. DOI: 10.11949/j.issn.0438-1157. 20141378.
HAN M, ZHANG Z K. Fault detection and diagnosis method based on modified kernel principal component analysis [J]. CIESC Journal, 2014, 66(6): 2139-2149. DOI: 10.11949/j.issn.0438-1157.20141378.
[4] 宋冰, 馬玉鑫, 方永鋒, 等. 基于LSNPE算法的化工過程故障檢測 [J]. 化工學報, 2014, 65 (2): 620-627. DOI: 10.3969/j.issn.0438-1157.2014.02.036.
SONG B, MA Y X, FANG Y F, et al. Fault detection for chemical process based on LSNPE method [J]. CIESC Journal, 2014, 65(2): 620-627. DOI: 10.3969/j.issn.0438-1157.2014.02.036.
[5] GARCIA-ALVAREZ D, FUENTE M J, SAINZ G I. Fault detection and isolation in transient states using principal component analysis [J]. Journal of Process Control, 2012, 22(3): 551-563. DOI: 10.1016/j. jprocont.2012.01.007.
[6] YIN S, DING S X, HAGHANI A, et al. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process [J]. Journal of Process Control, 2012, 22(9): 1567-1581. DOI: 10.1016/j.jprocont.2012.06.009.
[7] 徐圓, 劉瑩, 朱群雄. 基于多元時滯序列驅動的復雜過程故障預測方法應用研究 [J]. 化工學報, 2013, 64 (12): 4290-4295. DOI: 10.3969/j.issn.0438-1157.2013.12.003.
XU Y, LIU Y, ZHU Q X. A complex process fault prognosis approach based multivariate delayed sequences [J]. CIESC Journal, 2013, 64(12): 4290-4295. DOI: 10.3969/j.issn.0438-1157.2013.12.003.
[8] XIONG L, LIANG J, QIAN J X. Multivariate statistical process monitoring of an industrial polypropylene catalyzer reactor with component analysis and kernel density estimation [J]. Chinese Journal of Chemical Engineering, 2007, 15(4): 524-532. DOI: 10.1016/S1004-9541(07)60119-0.
[9] NOMIKOS P, MACGREGOR J F. Multivariate SPC charts for monitoring batch processes [J]. Technometrics, 1995, 37: 41-59. DOI: 10.2307/1269152.
[10] DONG D, MCAVOY T J. Nonlinear principal component analysis-based on principal curves and neural networks [J]. Computer & Chemical Engineering, 1996, 20(1): 65-78. DOI: 10.1016/0098-1354(95)00003-K.
[11] SCHOLKOPF B, SMOLA A, MULLER K. Nonlinear component analysis as a kernel eigenvalue problem [J]. Neural Computation, 1998, 10: 1299-1319. DOI: 10.1162/089976698300017467.
[12] LEE J M, YOO C K, CHOI S W, et al. Nonlinear process monitoring using kernel principal component analysis [J]. Chemical Engineering Science, 2004, 59: 223-234. DOI:10.1016/j.ces.2003.09.012.
[13] CHO J H, LEE J M, CHOI S W, et al. Fault identification for process monitoring using kernel principal component analysis [J]. Chemical Engineering Science, 2005, 6: 279-288. DOI:10.1016/j.ces.2004.08.007.
[14] JENSSEN R. Kernel entropy component analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(5): 847-860. DOI: 10.1109/TPAMI.2009.100.
[15] JIANG Q C, YAN X F, Lü Z M, et al. Fault detection in nonlinear chemical processes based on kernel entropy component analysis and angular structure [J]. Korean Journal of Chemical Engineering, 2013, 30(6): 1181-1186. DOI: 10.1007/s11814-013-0034-7.
[16] RENYI A. On Measures of Entropy and Information [C/OL]// Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability. Oakland: University of California Press, 1961, 1: 547-561. http://projecteuclid.org/euclid.bsmsp/1200512181.
[17] JENSSEN R, PRINCIPE J C, ERDOGMUS D. The Cauchy-Schwarz divergence and Parzen windowing: connections to graph theory and Mercer kernel [J]. Journal of the Franklin Institute, 2006, 343(6): 614-629. DOI: 10.1016/j.jfranklin.2006.03.018.
[18] JENSSEN R, ELTOFT T. A new information theoretic analysis of sum-of-squared-error kernel clustering [J]. Neurocomputing, 2008, 72(1/2/3): 23-32. DOI: 10.1016/j.neucom.2008.03.017.
[19] LAU C K , GHOSH K, HUSSAIN M A, et al. Fault diagnosis of Tennessee Eastman process with multi-scale PCA and ANFIS [J]. Chemometrics and Intelligent Laboratory Systems, 2013, 120: 1-14. DOI: 10.1016/j.chemolab.2012.10.005.
[20] MAHADEVAN S, SHAH A L. Fault detection and diagnosis in process data using one-class support vector machines [J]. Journal of Process Control, 2009, 19: 1627-1639. DOI: 10.1016/j.jprocont.2009. 07.011.
[21] YANG Y H, LI X L, LIU X Z, et al. Wavelet kernel entropy component analysis with application to industrial process monitoring [J]. Neurocomputing, 2015, 147: 395-402. DOI: 10.1016/j.neucom. 2014.06.045.
研究論文
Received date: 2015-12-14.
Foundation item: supported by the National Natural Science Foundation of China (61174109, 61364009) and the Natural Science Foundation of Inner Mongolia (2015MS0615).
Novel fault monitoring strategy for chemical process based on KECA
QI Yongsheng1,3, ZHANG Haili1, GAO Xuejin2,3, WANG Pu2,3
(1Institute of Electric Power, Inner Mongolia University of Technology, Hohhot 010051, Inner Mongolia, China;2School of Electric and Information and Control Engineering, Beijing University of Technology, Beijing 100124, China;
3Engineering Research Center of Digital Community, Ministry of Education, Beijing 100124, China)
Abstract:A chemical process fault monitoring algorithms based on kernel entropy component analysis (KECA) is presented for the complexity and nonlinear of industrial chemical process data. The number of principal components selected by the KECA algorism is much less than the KPCA algorism, which can effectively reduce computational complexity. This is achieved by selections onto eigenvalue and eigenvector based on the value of Renyi entropy. Research shows that KECA reveals angular structure relating to the Renyi entropy of the input space data set. A new statistic—Cauchy-Schwarz divergence measure, namely the cosine value between vectors in kernel space, is proposed, which describes the similarity between different PDFs (probability density functions). It is shown that KECA has great advantages in detection latency and fault detection rate in comparing to KPCA by applying them to TE (Tennessee Eastman) process respectively.
Key words:safety; process control; principal component analysis; fault monitoring; KECA; CS statistic
DOI:10.11949/j.issn.0438-1157.20151899
中圖分類號:TP 277
文獻標志碼:A
文章編號:0438—1157(2016)03—1063—07
基金項目:國家自然科學基金項目(61174109,61364009);內蒙古自治區自然科學基金項目(2015MS0615)。
Corresponding author:QI Yongsheng, qyslyt@163.com
猜你喜歡
中國科技博覽(2016年18期)2016-10-19 09:59:34
科技視界(2016年21期)2016-10-17 20:00:16
科技視界(2016年20期)2016-09-29 11:59:36
科技視界(2016年20期)2016-09-29 10:54:27
