Hadoop云平臺下基于LATE改進的推測執(zhí)行算法
2016-05-10 12:27:58高弘博張豐滿翟嘉伊
紡織科學與工程學報 2016年2期
關鍵詞:作業(yè)
盧 慧,高弘博,張豐滿,王 梅, 翟嘉伊,肖 震
(1.成都紡織高等專科學校軟件測試中心,四川 成都 611731;2.中國建設銀行武漢數(shù)據(jù)中心,湖北 武漢 430070)
?
Hadoop云平臺下基于LATE改進的推測執(zhí)行算法
盧慧1,高弘博1,張豐滿1,王梅1, 翟嘉伊1,肖震2
(1.成都紡織高等專科學校軟件測試中心,四川 成都 611731;2.中國建設銀行武漢數(shù)據(jù)中心,湖北 武漢 430070)
摘要:為解決Hadoop云平臺下推測執(zhí)行算法的不足,基于LATE算法提出一種新的任務進度計算方法,并且采用更細粒度的方式選擇執(zhí)行備份任務的節(jié)點。實驗結果表明,該算法能夠更精準的選定掉隊者任務并選擇合適的執(zhí)行節(jié)點,縮短作業(yè)的執(zhí)行時間,提高云平臺的效率。
關鍵詞:Hadoop云平臺LATE算法掉隊者任務
隨著Internet和Web技術的高速發(fā)展,大數(shù)據(jù)時代已經來臨,如何從大數(shù)據(jù)中獲取有價值的信息,成為科研機構和業(yè)界的研究熱點[1-3]。Hadoop是一個分布式云計算平臺, 其核心思想源自于Google公司的MapReduce編程模型和GFS文件系統(tǒng)模型。由于Hadoop的代碼開源,目前各大IT公司均采用其作為云計算運行框架,并結合應用需求進行改進,針對海量數(shù)據(jù)的處理取得了良好的效果。但是在實際的使用中,Hadoop云計算還存在著一些不足[4-5]。
為了進一步提高Hadoop集群的運行效率,減小作業(yè)的完成時間,Hadoop系統(tǒng)提供了一種推測執(zhí)行機制。但是在實際使用中,集群中機器存在一定的異構性,針對異構的集群環(huán)境,Hadoop的調度算法還有待改進。通常在同構環(huán)境下該機制的確起到了一定效果,但是在實際的生產環(huán)境中,由于集群異構等問題,會出現(xiàn)straggler問題[6]。該機制不但沒有起到提高作業(yè)效率的作用,反而由于過多的執(zhí)行備份任務占用了過多的資源,影響了整體作業(yè)的執(zhí)行效率。
近年來,相關學者針對Hadoop云平臺下推測執(zhí)行機制提出一些新的調度算法,其中文獻[7]提出了一種基于LATE的推測執(zhí)行算法,該算法采用任務帶寬的方式計算任務的剩余時間,并且加入了節(jié)省集群資源的策略。但是該算法使用任務的平均速度計算任務的剩余完成時間,會造成掉隊者任務的誤判斷,并且沒有考慮執(zhí)行備份任務的節(jié)點的質量。隨著Hadoop使用場景的擴展,相關學者隨之提出了各種改進的資源調度算法。改進算法的設計目標因需求而異,主要包括降低作業(yè)執(zhí)行時間、提升系統(tǒng)吞吐率、滿足作業(yè)時間限制、提升數(shù)據(jù)本地性以及適應異構環(huán)境等[8-11]。改進算法的目標不同,且針對的資源調度層次不同,有的是針對作業(yè)層改進,有的是針對任務層改進,所以沒有一個固定的指標。
針對上述問題,本文提出一種基于LATE改進的推測執(zhí)行算法,實現(xiàn)更精準的定位掉隊者任務并選擇更合適的節(jié)點執(zhí)行備份任務。
1Hadoop推測執(zhí)行算法
1.1推測執(zhí)行過程
推測執(zhí)行算法的思路是以空間換時間,同時啟動多個相同任務然后選取先執(zhí)行完畢的任務的結果,這樣可以提高任務計算速度。推測執(zhí)行算法的核心在于選擇需要推測執(zhí)行的任務以及選擇在執(zhí)行推測備份任務的節(jié)點[12]。
在Hadoop默認的推測執(zhí)行算法中,為了判定掉隊者任務即執(zhí)行進度低于平均水平的任務,TaskTracker會實時記錄其運行的任務的進度,并周期性的發(fā)送給JobTracker。
為了避免落隊者任務影響整體作業(yè)的運行效率,Hadoop提出了Speculative task機制。該機制的思想如下:在任務運行后,開始對任務的運行進度進行實時預測,如果有任務的進步明顯落后與所有任務的平均水平,則判定這類任務為掉隊者任務,從而對此任務重新申請資源,針對此任務執(zhí)行一個備份任務。
推測執(zhí)行算法分別針對Map任務和Reduce任務提出了進度估算方式。針對Map任務,任務的進度即為當前處理的數(shù)據(jù)量與輸入文件數(shù)據(jù)量的比值。而針對Redcue任務,則將Redcue任務的三個階段的等值劃分,即Copy、sort、reduce三個階段各占進度的1/3。算法根據(jù)公式(1)計算一個任務的進度,其中 是一個范圍為0到1的正數(shù),代表任務的進度值。M為Map任務已經處理的數(shù)據(jù)量,N為Map任務輸入文件的數(shù)據(jù)量。K為Reduce任務已完成的階段數(shù)。

(1)
通過上述方式即可估算出一個任務的進度,如當一個Redcue任務正處于sort階段并且已經拷貝了大概一半的數(shù)據(jù)時,該任務的進度按照公式計算為(1/3)×(1+1/2)=1/2。推測執(zhí)行算法通過公式(2)計算所有運行任務進度的平均值,根據(jù)公式(3)判定任務是否為掉隊者任務。如果任務的進度值滿足公式(3),其中Threshols默認設為0.2,則認為該任務落后于所有任務的平均進度,判定該任務為掉隊者任務。如果判定為掉隊者任務,那么當有TaskTracker請求任務時,則會針對掉隊者任務執(zhí)行其備份任務。
(2)
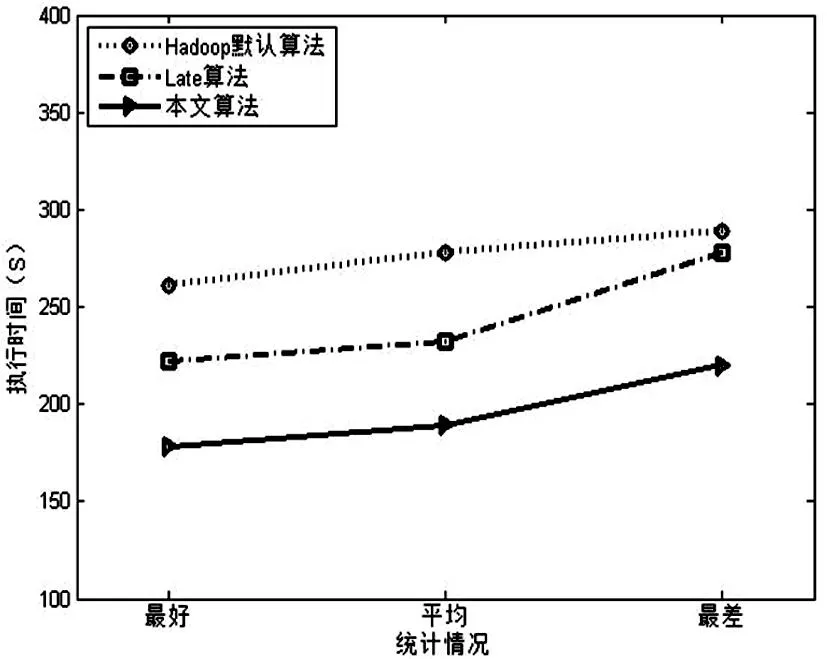
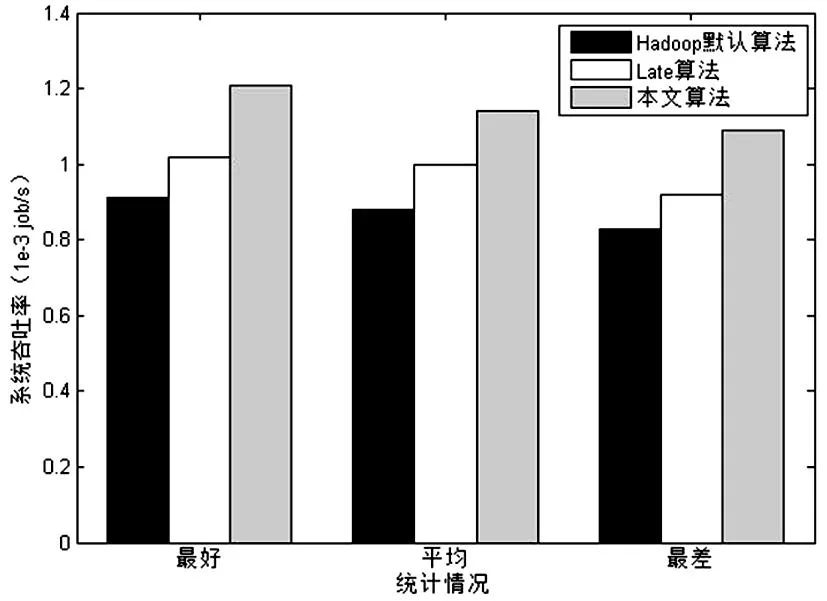
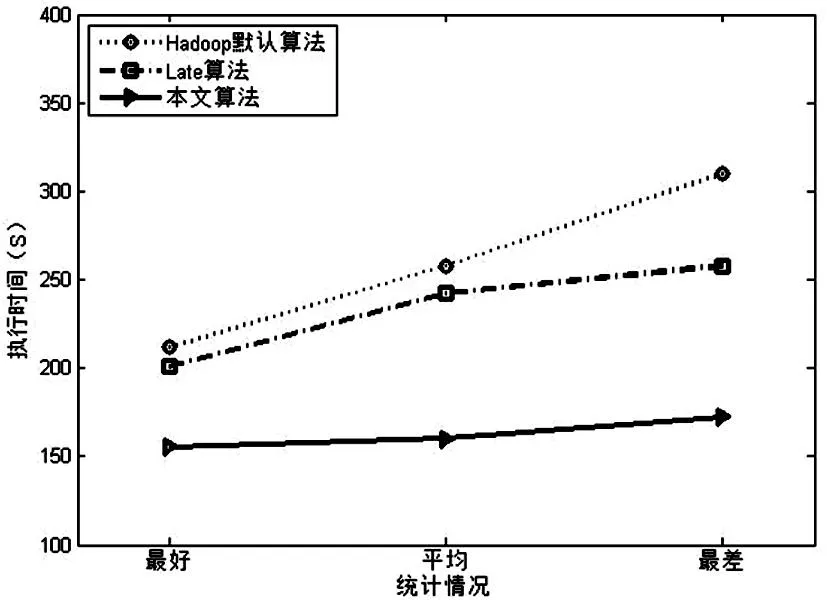
ProgressScorei (3) 1.2Late調度算法 LATE算法是在Hadoop默認推測執(zhí)行算法的基礎上,針對異構集群提出的一種改進算法,其思想是減少默認推測執(zhí)行算法中執(zhí)行備份任務的數(shù)目,從而降低推測執(zhí)行帶來的不必要的資源消耗。 根據(jù)任務的執(zhí)行進度推測出任務的完成時間,LATE算法中優(yōu)先執(zhí)行那些能夠在最快時間內完成的備份任務。在LATE算法中設置了如下三個參數(shù),來實現(xiàn)控制備份任務執(zhí)行數(shù)目。 1)SpeculateCap:備份任務總數(shù)的閥值。若同一時間內系統(tǒng)中運行的備份任務的總數(shù)大于該閥值,則不能進行備份任務的執(zhí)行; 2)SlowNodeThreshold:慢節(jié)點判斷的閥值。若節(jié)點的處理速率小于該閥值,則判定節(jié)點為慢節(jié)點。 3)SlowTaskThresHold:掉隊者任務判斷的閥值。若任務的執(zhí)行速率小于該閥值,則判定任務為掉隊者任務。 LATE算法中根據(jù)公式(4)計算任務的運行速率 ,其中 按照Hadoop默認推測執(zhí)行算法計算,T是任務已經運行的時間。然后根據(jù)公式(5)計算任務的剩余時間。 (4) (5) LATE算法的工作流程如下: 1)如果有一個節(jié)點請求新的任務,判斷全局備份任務數(shù)是否大于SpeculateCap值,若大于該值則返回結束推測執(zhí)行算法,否則進行下一步。 3)對正在執(zhí)行的任務(不包括已經在備份執(zhí)行的任務)計算其預計完成時間并排序,選擇預計完成時間最小且任務執(zhí)行速率低于SlowTaskThresHold的任務,執(zhí)行其備份任務。 2算法描述 2.1估算任務進度 本文算法受到文獻[7]的啟發(fā),利用TaskTracker記錄的任務運行歷史信息,計算各作業(yè)的任務階段耗時比例。并且加入自校正的思想,即當有新的任務運行完后,會及時的針對該任務所屬的作業(yè)進行階段耗時比例的更新。SMAR算法相對于LATE算法能夠更合理的估算出任務各階段的耗時比例,但是由于其沒有考慮不同類型作業(yè)的特性、處理數(shù)據(jù)的大小,會造成估算結果的不準確。本文利用任務運行歷史信息的進行了更小粒度的計算,針對每個作業(yè)進行階段耗時比例預估計算。 每個TaskTracker需要在任務成功運行后記錄其執(zhí)行階段的相關信息,根據(jù)任務的類型分為兩種:Map任務的執(zhí)行階段相關信息MapTaskInfo(JobId,TaskId,MP1,MP2),Reduce任務的執(zhí)行階段相關信息ReduceTaskInfo(JobId,TaskId,RP1,RP2,RP3)。其中JobID和TaskID分別是任務所屬作業(yè)的全局ID號、作業(yè)中該任務的ID號。MP1、MP2分別代表Map任務的map階段和combine階段的耗時比例,RP1、RP2、RP3分別代表Reduce任務的copy、sort和reduce階段的耗時比例。每當TaskTracker向JobTracker周期發(fā)送心跳信息時,會將TaskTracker上新完成的任務的執(zhí)行階段信息一并發(fā)送。JobTracker在接受到心跳信息后,會在歷史記錄模塊中添加這些新完成任務的信息,然后更新各任務的階段耗時比例值,用于任務進度的判斷。 每當TaskTracker中有任務運行結束后,會將該任務的運行情況記錄為MapTaskInfo或RedcueTaskInfo記錄在本地磁盤上,然后發(fā)送給TaskTracker。例如MapTask1運行完畢,會將(001,001,0.65,0.35)記錄下來并發(fā)送給TaskTracker。TaskTracker則會周期性的向JobTrakcer發(fā)送心跳信息,JobTracker受到心跳信息后會解析出任務的MapTaskInfo和ReduceTaskInfo。解析出后根據(jù)作業(yè)ID對各個作業(yè)的Map任務、Reduce任務的階段耗時比進行更新。由于在未有任務完成之前,MP1、MP2、RP1、RP2、RP3采用默認值1、0、0.6、0.3、0.1。當每次JobTrakcer收到心跳信息且MapTaskInfo和ReduceTaskInfo中有內容時則進行階段耗時比例的更新操作。更新操作的具體方式是對同一作業(yè)的Map任務和Redcue任務的同一階段的耗時進行平均值處理。例如MapTask1運行結束后,由于開始沒有其他任務運行結束,則JobTrakcer會對MapTask1對應的001作業(yè)的Map任務的階段耗時比值進行更新,更新為MP1=(1+0.65)/2=0.83,MP2=(0+0.35)/2=0.17。 通過對歷史信息的分析與自學習更新操作,可以更加精確的確定各個作業(yè)的不同階段比例耗時。 那么在此基礎上,我們可以更精準的計算任務的進度。將Map任務和Reduce任務的進度分開計算,公式如下: MapProcessScorej= (6) (7) (8) 通過公式(6)、(7)可以分別計算出Map中任務和Reduce任務的進度。公式中的任務各階段耗時比例值由JobTracker通過對任務的歷史信息自學習計算得到,N是任務要處理數(shù)據(jù)中鍵值對的數(shù)目,M是已經處理了的數(shù)據(jù)的數(shù)目。最后,通過根據(jù)作業(yè)類型由公式(8)可以確定任務的進度。 2.2定位掉隊者任務 在Hadoop推測執(zhí)行算法中,若一個任務的進度值低于所有運行任務進度的平均值,且差值大于一個固定的閾值,則此任務判定為掉隊者任務。在LATE算法中通過任務運行的速率對任務的運行時間進行預估,選擇剩余時間最大的任務進行備份執(zhí)行。但是其沒有考慮實際運行中任務的不同批次問題。例如一個map任務task1已經運行了90%,預估的剩余時間為100s,同時運行著map任務task2,其實在task1任務運行了一段時間后才獲得資源開始調度,運行進度只有30%,預估剩余時間為200s。那么按照LATE算法則會選擇task2進行備份執(zhí)行。這種不考慮任務運行批次的調度方式是不符合實際情況的,不能真正的定位到需要備份執(zhí)行的strggler任務。本文通過結合任務速率和任務剩余預估時間兩個因素,從而完成掉隊者任務的判定。 CA153是人乳腺癌患者的組織碎片及細胞質中提取的糖類抗原物質,屬于乳腺癌相關抗原, 對乳腺癌患者隨診有一定意義,主要用于治療后監(jiān)測乳腺癌患者的疾病復發(fā)和轉移。有研究表明[9],較高水平的CA153可作為乳腺癌可靠的預后標記,與晚期和復發(fā)直接相關。此外,在乳腺癌患者中,CA153的持續(xù)升高與HER2陽性相關。CA153也可用于轉移性乳腺癌的輔助診斷, 乳腺癌術后CA153陽性率可達80%,肝、骨處轉移可引起血清CA153顯著升高。CA153對早期乳腺癌的敏感性及特異性較差,可潛在地用于檢測高危人群乳腺癌的發(fā)生。 在計算任務的運行速率時,本文只考慮正在運行階段的運行速率。因為已完成的階段已經沒有預估價值,而未進入的階段則由于過于復雜且有隨機性是無法預估的。所以本文只考慮正在運行階段的速率。 ProgressSpeed=ProgressScore/T (9) 計算完任務的運行速率之后,需要完成任務剩余時間的預估。剩余時間最長(且運行速率小于平均速率)的節(jié)點將會獲得最高的優(yōu)先級被執(zhí)行備份任務。 一個任務的剩余運行時間是所有未完成階段的剩余運行時間之和,本文將任務的剩余運行時間劃分為正在運行階段的剩余時間和未運行階段的剩余時間兩部分。如果一個任務正運行在階段cp(current phase),則cp階段剩余時間由其剩余處理數(shù)據(jù)量和該階段運行速率決定。然而,cp階段之后的各階段fp(follow phase)的剩余時間很難預估,因為任務還未進入這些階段。因此,我們使用階段平均進程速率預估fp階段的剩余時間。階段平均運行速率是指進入該階段的所有進程速率的平均值。如果某階段沒有任何任務已經進入,我們不計算其階段的時間,這對所有任務都是公平的。由于每個任務處理的數(shù)據(jù)量不一樣,計算fp階段的剩余時間需要考慮本任務的數(shù)據(jù)量和已進入該階段任務的數(shù)據(jù)量的比例。可以通過公式求導出任務的剩余運行時間: (10) 掉隊者任務的選擇流程如下: 1)按公式算任務的運行速率,如果運行速率低于所有任務的平均速率,則進行下一步; 2)計算任務的剩余運行時間,將任務按剩余時間由大到小排序; 3)將剩余時間最大的任務判定為掉隊者任務。 2.3選擇執(zhí)行備份任務節(jié)點 在判定完掉隊者任務后,需要對掉隊者任務進行備份執(zhí)行,即在另外一個節(jié)點上重新執(zhí)行該任務。但是由于在異構的環(huán)境下,重新執(zhí)行掉隊者任務的節(jié)點的性能可能比當前節(jié)點的性能更差,則會導致備份任務依舊會是一個掉隊者任務。這樣不僅不會提升作業(yè)的執(zhí)行時間,反而會消耗系統(tǒng)的可用資源。所以在選擇執(zhí)行備份任務節(jié)點的時候應該過濾掉這種節(jié)點,下文稱之為慢節(jié)點。 在實際運行環(huán)境中,由于Map任務和Reduce任務運行的特點和階段都不相同,所以節(jié)點執(zhí)行Map任務和Reduce任務的速率也是不同的。LATE算法中僅僅在判定節(jié)點的快慢時沒有對任務的類型進行區(qū)分,這樣對導致備份任務的執(zhí)行效率。本文針對此問題將慢節(jié)點區(qū)分為:Map任務慢節(jié)點和Redcue任務慢節(jié)。 假設一個TaskTracker上運行的Map任務數(shù)為 MapNum,運行的Reduce任務數(shù)為 ReduceNum。根據(jù)公式(11)、(12)可以分別計算出該TaskTracker上Map任務和Reduce任務的平均運行速率。 (11) (12) 假設系統(tǒng)中運行的TaskTracker的總數(shù)為TTNum,可以根據(jù)公式(13)、(14)分別計算出整個集群中Map任務和Reduce任務的平均運行速率。 (13) (14) 3實驗及結果分析 3.1實驗環(huán)境 本實驗集群的硬件采用10臺商用測試服務器,其分別部署在三個機架上,采用1gbps以太網連接。 其中,每臺服務器上部署了OpenStack云計算管理系統(tǒng),并且采用KVM軟件負責劃分虛擬機資源。每個虛擬機配置 2個虛擬核,4gb內存,40GB磁盤空間。由于其具備異構的特點,所以通過在每臺服務器上劃分不同數(shù)目的虛擬機來模擬異構的運行環(huán)境,具體如表1所示。 表1 集群虛擬機配置表 3.2不同負載性能驗證 本節(jié)通過在異構Hadoop集群中運行三種不同類型的作業(yè),對Hadoop默認推測算法、LATE算法、本文提出的ISSL算法進行了實驗,并對比分析了實驗結果,驗證了本文算法在異構環(huán)境下能夠減小作業(yè)的執(zhí)行時間、有效提升系統(tǒng)吞吐WordCount、Sort、Grep是Hadoop中最典型的三類作業(yè),可以代表Hadoop中最常用的各類作業(yè)。本節(jié)分別針對這三類類型不同的作業(yè),對Hadoop默認推測執(zhí)行算法、LATE算法和本文算法進行實驗。每一類實驗都運行6次,為了減小隨機因素的影響,本文對每次實驗用例結果的最好、最差、平均情況都進行了統(tǒng)計。由于每次實驗中作業(yè)類型相同且輸入數(shù)據(jù)量相等,本文和文獻[12]采用同樣的方式度量系統(tǒng)的吞吐率,即系統(tǒng)每秒處理作業(yè)的數(shù)量。 3.2.1WordCount測試 WordCount作業(yè)用于計算輸入文件中各單詞的出現(xiàn)的次數(shù),是Hadoop中最常處理的作業(yè)。本實驗測試用例的輸入文件大小為8GB,每隔30s提交一個WordCount作業(yè),一共提交6次。 圖1是三種算法執(zhí)行Wordcount作業(yè)的實驗結果,其中(a)是三種算法的作業(yè)執(zhí)行時間的結果對比圖,(b)是三種算法執(zhí)行時系統(tǒng)吞吐量的結果對比圖。通過實驗結果可以發(fā)現(xiàn),本文提出的ISSL算法的在平均情況下,作業(yè)執(zhí)行時間比Late算法、Hadoop默認算法降低了10%,而且相對于Late算法、Hadoop默認執(zhí)行算法分別提升了5%、6%的系統(tǒng)吞吐率。 在WordCount作業(yè)中,本文算法針對作業(yè)的執(zhí)行時間及系統(tǒng)吞吐量兩個方面并沒有獲得很明顯的提升。因為作業(yè)處理的是純文本文件,間接數(shù)據(jù)和最終輸出的數(shù)據(jù)會比較小,所以WordCount作業(yè)大部分時間用于在map階段,即CPU密集型作業(yè)。一旦Map任務運行結束,Reduce任務只需要很短的時間。因此,wordcount作業(yè)的性能由Map任務的執(zhí)行效率決定。由于wordcount作業(yè)中map任務的平均執(zhí)行時間只有70s,在快的節(jié)點上執(zhí)行和在慢的節(jié)點上執(zhí)行差異不大,所以導致提升度比較小。 (a)作業(yè)執(zhí)行時 (b)系統(tǒng)吞吐量 3.2.2Sort測試 Sort作業(yè)主要是對點擊率排序等,其和wordcount作業(yè)有著很大的不同,其Map任務會產生的大量中間數(shù)據(jù)會通過網絡傳遞到Reduce任務節(jié)點,同時Reduce任務產生的結果數(shù)據(jù)也比較大,并需要寫到磁盤上。因此,Sort作業(yè)屬于I/O密集型作業(yè)。測試用例采用的得數(shù)據(jù)集是點擊率文件,大小為30GB。每一個sort作業(yè)有100個reduce任務,本文每個150s提交一個作業(yè),一共提交3次。 下頁圖2是三種算法執(zhí)行Sort作業(yè)的實驗結果,其中(a)是三種算法的作業(yè)執(zhí)行時間的結果對比圖,其中(b)是三種算法執(zhí)行時系統(tǒng)吞吐量的結果對比圖。本文提出額ISSL算法的作業(yè)平均執(zhí)行時間低于LATE算法19%,低于Hadoop默認算法37%。并且本文提出的ISSL算法相對于LATE算法、Hadoop默認算法分別提高了15%、32%的系統(tǒng)吞吐量。 在作業(yè)執(zhí)行時間和系統(tǒng)吞吐量兩個方面,本文算法ISSL在處理sort作業(yè)時相較于Wordcount作業(yè)都獲得了很大的提升,主要是由于sort作業(yè)中reduce任務的工作量大于map任務,mao任務只占據(jù)了整個作業(yè)執(zhí)行時間的一小部分。在map和reduce階段,本文算法有更多的機會執(zhí)行高效的推測任務,導致更高的吞吐量。 (a)作業(yè)執(zhí)行時間 (b)系統(tǒng)吞吐量 3.2.3Grep測試用例 Grep作業(yè)主要是在輸入文件中通過正則匹配找到包含指定串的表達式,當表達式出現(xiàn)的比較頻繁時,Grep作業(yè)類似于Sort作業(yè),是一個I/O密集型作業(yè);當表達式出現(xiàn)很稀疏時,Grep作業(yè)者類似wordcount作業(yè),是一個CPU密集型作業(yè)。本用例的測試輸入文件大小為23g,每個150s提交一個作業(yè),一共提交3次。 圖3是三種算法執(zhí)行Grep作業(yè)的實驗結果,其中(a)是三種算法的作業(yè)執(zhí)行時間的結果對比圖,(b)是三種算法執(zhí)行時系統(tǒng)吞吐量的結果對比圖。通過實驗結果可以發(fā)現(xiàn),在平均情況下,相對于LATE算法、Hadoop默認執(zhí)行算法,本文提出的ISSL分別降低了39%、48%的作業(yè)執(zhí)行時間,提升了38%、42%的系統(tǒng)吞吐量。 在Grep作業(yè)中,map任務工作量大于Sort作業(yè)中map任務的工作量,平均執(zhí)行時間是sort任務的1.3倍。因此,推測執(zhí)行針對map任務可以取得更好的效果。 (a)作業(yè)執(zhí)行時間 (b)系統(tǒng)吞吐量 通過上述三種不同類型的實驗,可以發(fā)現(xiàn)本文算法相對于Hadoop默認推測執(zhí)行算法、LATE算法,均能有效的降低作業(yè)的執(zhí)行時間,提升系統(tǒng)的吞吐率。這些性能的提升主要是由于本文算法通過新的進度估算方式提升了掉隊者任務的判定準確性,這樣會避免系統(tǒng)執(zhí)行不必要的備份任務,浪費系統(tǒng)的資源。同時,本文算法相對于LATE算法在選擇執(zhí)行備份任務的節(jié)點時進行了更細粒度的區(qū)分,使不同類型的任務在最適合的快節(jié)點上執(zhí)行,從而提升了備份任務的執(zhí)行效率,減小整個作業(yè)的執(zhí)行時間。并且,在多次試驗中最差、平均、最壞的情況下,本文算法的性能都優(yōu)于Hadoop默認算法、LATE算法,證明本算法是非常穩(wěn)定的。 4結束語 伴隨大數(shù)據(jù)時代的到來,Hadoop云平臺的使用場景不斷擴展,通過對Hadoop資源調度框架的研究本文構建了資源預估模型,在此基礎上對作業(yè)調度算法的推測執(zhí)行算法進行了改進。由于Hadoop的不斷發(fā)展,下一步將針對實時調度及數(shù)據(jù)放置策略等進行研究。 參考文獻 [1]K Kambatla, A Pathak, and H. Proc. of the First Workshop on Hot Topics in Cloud Computing: Pucha.Towards optimizing hadoop provisioning in the cloud[C]. Washington DC, 2009. [2]林闖,蘇文博,孟坤,等. 云計算安全:架構、機制與模型評價[J]. 計算機學報,2013(9):1765-1784. [3]孟小峰,慈祥. 大數(shù)據(jù)管理:概念、技術與挑戰(zhàn)[J]. 計算機研究與發(fā)展,2013(1):146-169. [4]H. Chang, M. Kodialam, R. Kompella, T. Lakshman, et al. INFOCOM 2011 Proceedings IEEE :Scheduling in mapreduce-like systems for fast completion time[C]. Inforcm,2011. [5]欒亞建,黃翀民,龔高晟,等. Hadoop平臺的性能優(yōu)化研究[J]. 計算機工程,2010(14):262-266. [6]Daewoo Lee,Jin-Soo Kim,Seungryoul Maeng. Large-scale incremental processing with MapReduce[J]. Future Generation Computer Systems,2013,10:130-139. [7]Huo Tang, Junqing Zhou, Kenli Li, et al. A MapReduce task scheduling algorithm for deadline constraints[J]. Cluster Computing,2013,164:109-112. [8]Wei Dai,Mostafa Bassiouni. An improved task assignment scheme for Hadoop running in the clouds[J]. Journal of Cloud Computing,2013,21:231-240. [9]Ezerra A,Hernndez P,Espinosa A,et a1.Proc of the 20th European MPI Use Group Meeting :Job scheduling for optimizing data locality in Hadoop clusters[C]. ACM Press,2013. [10]Zhuo Tang, Junqing Zhou, Kenli Li,et al. A MapReduce task scheduling algorithm for deadline constraints[J]. Cluster Computing,2013:164-173. [11]Z Guo, G Fox, M Zhou. IEEE International Conference :Improving Resource Utilization in MapReduce[C]. Washington DC ,2012. [12]N Maheshwari, R Nanduri, V Varma. Future Generation Computer Systems :Dynamic energy efficient data placement and cluster reconfiguration algorithm for MapReduce framework[C]. IEEE Computer Society,2012. Improved Speculated Scheduling Algorithm Based on LATE of Hadoop Cloud Platform LUHui1,GAOHong-bo1,ZHANGFeng-man1,WANGMei1,ZHAIJia-yi1,XIAOZhen2 (1.SoftwareTestingCenter,ChengduTextileCollege,Chengdu611731;2.WuhanDataCenter,ChinaConstructionBank,Wuhan430070) Abstract:In order to improve the limitation of speculated scheduling algorithm of Hadoop cloud platform, a new task process algorithm based on LATE was proposed and notes of backup task were selected by adopting more fine-grained way. The experiment results showed that such algorithm could more accurately select the stragglers and choose proper executing mote, shorten executing time and improve the efficiency of cloud platform. Key words:Hadoopcloud platformLATE algorithmstraggler 中圖分類號:TP393 文獻標識碼:A 文章編號:1008-5580(2016)02-0200-07 基金項目:基于云計算的蜀錦蜀繡綜合服務平臺(2012FZ0081) 收稿日期:2015-12-20 第一作者:盧慧(1970-),女,碩士,高級講師,研究方向:云計算、大數(shù)據(jù)分析、物聯(lián)網。




猜你喜歡
小主人報(2022年1期)2022-08-10 08:28:44
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
作文成功之路·小學版(2020年7期)2020-08-24 08:19:30
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年7期)2020-01-02 10:10:44
趣味(數(shù)學)(2018年12期)2018-12-29 11:24:10
小學生作文(中高年級適用)(2017年10期)2017-11-13 06:01:00
能源(2016年2期)2016-12-01 05:10:46
故事大王(2016年7期)2016-09-22 17:30:08
