基于情感特征的用戶聚類分析
2016-04-12 09:06:14任偉劉循
中國(guó)新通信 2016年5期
任偉 劉循

【摘要】 隨著互聯(lián)網(wǎng)行業(yè)的發(fā)展,各式各樣的網(wǎng)站不斷興起,用戶在網(wǎng)上發(fā)帖留言已經(jīng)成為一種常態(tài),對(duì)用戶的留言進(jìn)行情感分析,分析用戶的情感傾向和主觀情感已經(jīng)變得越來越流行。首先,本文用基于情感詞典的情感分析方法對(duì)用戶的情感進(jìn)行分析,為用戶的每一條回帖計(jì)算其正向情感分值和負(fù)向情感分值得以及計(jì)算其 正向情感詞數(shù)目和負(fù)向情感詞數(shù)目,最后以用戶為單位,計(jì)算均值,得到每個(gè)用戶的情感特征向量,我們根據(jù)用戶的情感特征向量,對(duì)用戶進(jìn)行聚類分析,探究用戶的行為模式有什么不同點(diǎn)和相同點(diǎn)。
關(guān)鍵字:情感分析;KMeans;聚類分析
User cluster analysis based on sentiment feature
REN - wei, LIU- xung (School of Computer, Sichuan University, Chengdu 610065, China)
Abstract: With the development of Internet,all kinds of website becomes popular,users like to leave somemessages on it.That is a good resource for us to analysis sentiment for every user.
This paper uses a dictionary-based method to analysis users sentiment.we calculate thepositive points,negative points,the number of positive word and the number of negative word for every message.then get a mean value of them as a feature vecture for every user.At last,we can use the KMeans algorithe to cluster them and analysis the way when people leave a message.
Keywords:KMeans; cluster; sentiment analysis
一、用戶情感分析
本文采用的是基于情感字典的情感分析方法.
1.1 原理
比如這么一句話:“這手機(jī)的畫面極好,操作也比較流暢。不過拍照真的太爛了!系統(tǒng)也不好。”
① 情感詞
要分析一句話是積極的還是消極的,最簡(jiǎn)單最基礎(chǔ)的方法就是找出句子里面的情感詞,積極的情感詞比如:贊,好,順手,華麗等,消極情感詞比如:差,爛,壞,坑爹等。出現(xiàn)一個(gè)積極詞就+1,出現(xiàn)一個(gè)消極詞就-1。
里面就有“好”,“流暢”兩個(gè)積極情感詞,“爛”一個(gè)消極情感詞。那它的情感分值就是1+1-1+1=2. 很明顯這個(gè)分值是不合理的,下面一步步修改它。
② 程度詞
“好”,“流暢”和‘爛“前面都有一個(gè)程度修飾詞。”極好“就比”較好“或者”好“的情感更強(qiáng),”太爛“也比”有點(diǎn)爛“情感強(qiáng)得多。所以需要在找到情感詞后往前找一下有沒有程度修飾,并給不同的程度一個(gè)權(quán)值。比如”極“,”無比“,”太“就要把情感分值*4,”較“,”還算“就情感分值*2,”只算“,”僅僅“這些就*0.5了。那么這句話的情感分值就是:4*1+1*2-1*4+1=3
③ 感嘆號(hào)
可以發(fā)現(xiàn)太爛了后面有感嘆號(hào),嘆號(hào)意味著情感強(qiáng)烈。因此發(fā)現(xiàn)嘆號(hào)可以為情感值+2. 那么這句話的情感分值就變成了:4*1+1*2-1*4-2+1 = 1
④ 否定詞
明眼人一眼就看出最后面那個(gè)”好“并不是表示”好“,因?yàn)榍懊孢€有一個(gè)”不“字。所以在找到情感詞的時(shí)候,需要往前找否定詞。比如”不“,”不能“這些詞。而且還要數(shù)這些否定詞出現(xiàn)的次數(shù),如果是單數(shù),情感分值就*-1,但如果是偶數(shù),那情感就沒有反轉(zhuǎn),還是*1。在這句話里面,可以看出”好“前面只有一個(gè)”不“,所以”好“的情感值應(yīng)該反轉(zhuǎn),*-1。
因此這句話的準(zhǔn)確情感分值是:4*1+1*2-1*4-2+1*-1 =-1
⑤ 積極和消極分開來
再接下來,很明顯就可以看出,這句話里面有褒有貶,不能用一個(gè)分值來表示它的情感傾向。而且這個(gè)權(quán)值的設(shè)置也會(huì)影響最終的情感分值,敏感度太高了。因此對(duì)這句話的最終的正確的處理,是得出這句話的一個(gè)積極分值,一個(gè)消極分值(這樣消極分值也是正數(shù),無需使用負(fù)數(shù)了)。它們同時(shí)代表了這句話的情感傾向。所以這句評(píng)論應(yīng)該是”積極分值:6,消極分值:7“
⑥ 以分句的情感為基礎(chǔ)
再仔細(xì)一步,詳細(xì)一點(diǎn),一條評(píng)論的情感分值是由不同的分句加起來的,因此要得到一條評(píng)論的情感分值,就要先計(jì)算出評(píng)論中每個(gè)句子的情感分值。這條例子評(píng)論有四個(gè)分句,因此其結(jié)構(gòu)如下([積極分值, 消極分值]):[[4, 0], [2, 0], [0, 6], [0, 1]]
以上就是使用情感詞典來進(jìn)行情感分析的主要流程了,算法的設(shè)計(jì)也會(huì)按照這個(gè)思路來實(shí)現(xiàn)。
1.2 算法設(shè)計(jì)
第一步:讀取評(píng)論數(shù)據(jù),對(duì)評(píng)論進(jìn)行分句。
第二步:查找對(duì)分句的情感詞,記錄積極還是消極,以及位置。
第三步:往情感詞前查找程度詞,找到就停止搜尋。為程度詞設(shè)權(quán)值,乘以情感值。
第四步:往情感詞前查找否定詞,找完全部否定詞,若數(shù)量為奇數(shù),乘以-1,若為偶數(shù),乘以1。
第五步:判斷分句結(jié)尾是否有感嘆號(hào),有嘆號(hào)則往前尋找情感詞,有則相應(yīng)的情感值+2。
第六步:計(jì)算完一條評(píng)論所有分句的情感值,用數(shù)組(list)記錄起來。
第七步:計(jì)算并記錄所有評(píng)論的積極情感值,消極情感值,積極情感詞個(gè)數(shù),消極情感詞個(gè)數(shù)。
二、構(gòu)建用戶情感特征向量
通過上一節(jié)的工作 我們得到了每個(gè)用戶每條的回帖的情感特征向量,即[正向情感得分,負(fù)向情感得分,正向情感詞數(shù)目,負(fù)向情感詞數(shù)目],通過每條發(fā)言的情感特征,我們可以構(gòu)建用戶的整體情感特征,分別計(jì)算用戶的正向情感均值、負(fù)向情感均值,正向情感方差,負(fù)向情感方差,正向情感詞平均數(shù),負(fù)向情感詞平均數(shù),用戶的整體情感特征有助于我們對(duì)用戶的情感進(jìn)行分析,比如均值代表了正向情感或者負(fù)向情感的大致水平,而方差則表示了用戶情感水平的波動(dòng)情況,方差越大,表明用戶的情感變化范圍較大,而正向情感詞平均數(shù)和負(fù)向情感詞平均數(shù)則需要配合情感均值來使用,若是 負(fù)向情感詞平均數(shù) 或者 正向情感詞平均數(shù) 很高 但是 正向情感均值 和 負(fù)向情感均值 缺不高 說明在情感詞時(shí)用了很多否定詞,說明在表達(dá)情感時(shí)比較委婉。反之 若正向情感均值或負(fù)向情感均值 比較高 同時(shí) 正向情感詞平均數(shù) 與負(fù)向情感詞平均數(shù)也比較高 則說明在表達(dá)情感時(shí)顯得比較直接。
三、用戶情感特征分析
我們對(duì)100位用戶的情感特征向量進(jìn)行進(jìn)行分析,首先進(jìn)行相關(guān)性分析,我們利用皮爾遜相關(guān)系數(shù) 來計(jì)算各個(gè)變量之間的相關(guān)性。首先對(duì)每一列數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理 即每一列的數(shù)據(jù)減去該列的均值同時(shí)除以標(biāo)準(zhǔn)差 公式如下
X*=(x-e(x))/sd(x)
然后采用協(xié)方差公式進(jìn)行相關(guān)系數(shù)的計(jì)算
R(x,y)=cor(x*,y*)=x.y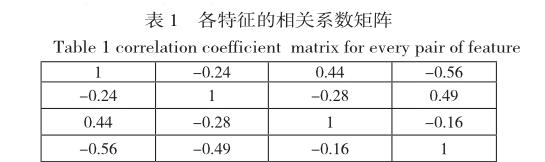
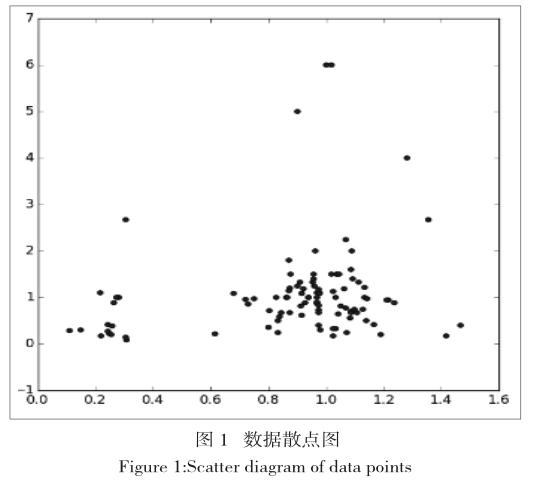
從相關(guān)系數(shù)矩陣中我們可以看出,正向情感得分和正向情感詞數(shù)目,負(fù)向情感得分和負(fù)向情感次數(shù)目 ,正向情感詞數(shù)目 和負(fù)向情感詞數(shù)據(jù) 具有最想的想關(guān)性,但是 跟據(jù)我們的算法 正向情感得分 就是 根據(jù) 正向情感詞數(shù)據(jù)而來的 除非情感詞前面加了否定詞 此時(shí) 說話的語氣會(huì)變得較為委婉無法揣測(cè)真是的情感 如 語句“他成績(jī)不好” 這句話是直接方式的負(fù)向情感的表達(dá) 如果改為 好 還是 成績(jī)還可以呢,所以 此時(shí) 不管是負(fù)向情感得分 還是負(fù)向情感得分 都為0.但是在情感詞數(shù)據(jù)上 則不為0,這說明用戶在說話習(xí)慣上產(chǎn)生了不同,有的人說話比較直接,有人說話比較為委婉,所以我們變換特征向量,即讓用戶情感特征向量的第一列除以第三列,第二列除以第四列,我們將新的特征向量的第一列命名為 正向情感直接系數(shù),第二列命名為負(fù)向情感直接系數(shù),情感直接系數(shù)反應(yīng)了用戶說話的直接程度,越高 說明用戶說話約直接。接下來我們用KMeans聚類算法 對(duì)用戶進(jìn)行聚類,以此來驗(yàn)證我們的想法。在使用KMeas 之前 我們首先用散點(diǎn)圖 來對(duì)數(shù)據(jù)點(diǎn)的分布進(jìn)行觀察。
從圖1中可以看出 數(shù)據(jù)點(diǎn)的分布近似橢圓形,適合用KMeans算法對(duì)數(shù)據(jù)點(diǎn)進(jìn)行聚類(因?yàn)槲覀兪褂脷W式距離來對(duì)數(shù)據(jù)點(diǎn)之間的距離進(jìn)行度量)。同時(shí)有非常明顯的2個(gè)聚類中心,所以在使用KMeans算法時(shí) 我們將聚類的數(shù)目定義為2[1]。
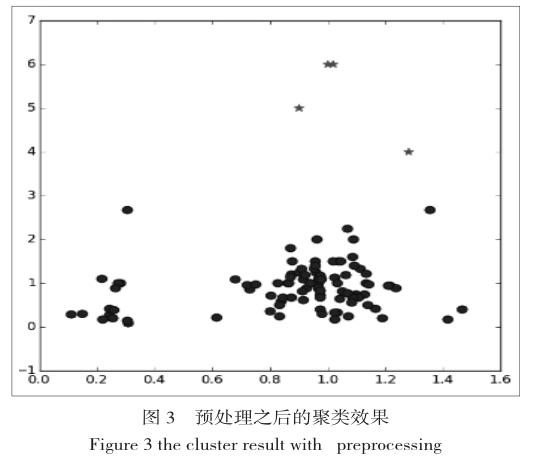
我們不對(duì)數(shù)據(jù)進(jìn)行任何預(yù)處理的工作,直接對(duì)數(shù)據(jù)進(jìn)行聚類,聚類效果如下圖所示。
我們發(fā)現(xiàn)數(shù)據(jù)點(diǎn)被分成了2個(gè)類,Y軸坐標(biāo)比較大的分為了一類,Y軸坐標(biāo)比較小的分為了一類,這是因?yàn)閿?shù)據(jù)點(diǎn)的Y軸坐標(biāo)范圍比X軸范圍大得多,而KMeans算法采用歐式距離來度量數(shù)據(jù)點(diǎn)之間的差異性,而由于Y軸坐標(biāo)的范圍比X軸大的多,所思數(shù)據(jù)點(diǎn)之間的差異主要由Y軸坐標(biāo)決定,所以分類超平面就會(huì)垂直于Y軸。這樣的聚類效果 顯然不是我們想要的。為了使得X軸和Y軸有相同的均值和方差,我們需要對(duì)數(shù)據(jù)繼續(xù)標(biāo)準(zhǔn)化處理,這樣樣本點(diǎn)在X軸和Y軸上的均值都將變?yōu)?,方差變?yōu)?[2]。
對(duì)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理后 我們用散點(diǎn)圖來看下聚類的效果。
可以看到數(shù)據(jù)被分成了2類,我們對(duì)每一類球均值,可以發(fā)現(xiàn) 第一類的均值向量為(0.269,0.59) 第二類的均值向量為(1.16,1.01) 第二類的情感直接系數(shù)比第一類大了許多,說明第一類人說話較為婉轉(zhuǎn),第二類的人說話則更為直接。
四、結(jié)論以及進(jìn)一步的工作
我們通過對(duì)用戶的網(wǎng)絡(luò)留言數(shù)據(jù)進(jìn)行情感分析,得到用戶的情感特征向量,
通過用戶的情感特征向量,對(duì)用戶進(jìn)行聚類分析,通過聚類分析,得到用戶的說話的行為習(xí)慣。但是本文有些地方做的還是不夠細(xì)致。
1、在得到用戶的情感得分矩陣中,我們使用了基于字典的情感分析方法,對(duì)用戶的情感進(jìn)行打分,但是在具體的算法上 顯得較為粗糙,沒有結(jié)合客觀情況進(jìn)行深入分析,如“科比的球技不太好”,這句話利用我們的情感分析算法,得到的情感得分為0,但是這句話其實(shí)表達(dá)了一種負(fù)向情感,因?yàn)檎媸乔闆r是科比的球技很好,所以這句話表達(dá)的應(yīng)該是負(fù)向情感。
2、特征較少,沒有進(jìn)行更深入的特征工程構(gòu)建,只是對(duì)用戶說話的直接與否進(jìn)行對(duì)用戶進(jìn)行分類,所使用的特征有限,應(yīng)該更加深入構(gòu)建用戶的情感特征。
參 考 文 獻(xiàn)
[1]Christopher Bishop.Pattern Recognition and Machine Learning[M].Americn:spring er,2007-10-1.548-662.
[2]Trent Hauck.Sklearn-coobook[M].England:packer publishing,2014-11-4.66-78.
猜你喜歡
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫(yī)學(xué)(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年6期)2016-08-21 13:49:38
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
