典型大數據計算框架分析
2016-03-24 00:19:15趙晟姜進磊
中興通訊技術 2016年2期
趙晟 姜進磊

摘要:認為大數據計算技術已逐漸形成了批量計算和流計算兩個技術發展方向。批量計算技術主要針對靜態數據的離線計算,吞吐量好,但是不能保證實時性;流計算技術主要針對動態數據的在線實時計算,時效性好,但是難以獲取數據全貌。從可擴展性、容錯性、任務調度、資源利用率、時效性、輸入輸出(IO)等方面對現有的主流大數據計算框架進行了分析與總結,指出了未來的發展方向和研究熱點。
關鍵詞:大數據分類;大數據計算;批量計算;流計算;計算框架
Abstract:Big data computing technologies have two typical processing modes: batch computing and stream computing. Batch computing is mainly used for high-throughput processing of static data and does not produce results in real time. Stream computing is used for processing dynamic data online in real time but has difficulty providing a full view of data. In this paper, we analyze some typical big data computing frameworks from the perspective of scalability, fault-tolerance, task scheduling, resource utilization, real time guarantee, and input/output (IO) overhead. We then points out some future trends and hot research topics.
Key words:big data; big data computing; batch computing; stream computing; computing framework
近年來,隨著互聯網進入Web 2.0時代以及物聯網和云計算的迅猛發展,人類社會逐漸步入了大數據時代。根據維基百科的描述,所謂的大數據,是指所涉及的數據量規模巨大,無法通過人工在合理時間內達到截取、管理、處理、并整理成為人類所能解讀的信息。大數據在帶來發展機遇的同時,也帶來了新的挑戰,催生了新技術的發展和舊技術的革新。例如,不斷增長的數據規模和數據的動態快速產生要求必須采用分布式計算框架才能實現與之相匹配的吞吐和實時性,而數據的持久化保存也離不開分布式存儲。
圖1展示了大數據應用的一般架構,其中的核心部分就是大數據計算框架和大數據存儲。大數據存儲提供可靠的數據存儲服務,在此之上搭建高效、可擴展、可自動進行錯誤恢復的分布式大數據計算框架,計算依賴存儲,兩者共同構成數據處理的核心服務。由于文獻[1]已經對大數據存儲進行總結,詳述了文件系統、數據庫系統、索引技術,因此文中將重點對大數據計算框架進行分析。
1 大數據計算技術面臨的
問題與挑戰
大數據計算技術采用分布式計算框架來完成大數據的處理和分析任務。作為分布式計算框架,不僅要提供高效的計算模型、簡單的編程接口,還要考慮可擴展性和容錯能力。作為大數據處理的框架,需要有高效可靠的輸入輸出(IO),滿足數據實時處理的需求。當前大數據處理需要解決如下問題和挑戰,這些問題和挑戰也是對大數據計算框架進行分析的重要指標。
(1)可擴展性:計算框架的可擴展性決定可計算規模,計算并發度等指標。現有計算框架通常采用主從模式的架構設計,便于集群的管理和任務調度,但主節點會成為系統的性能瓶頸,限制了可擴展性。另外,在現有彈性計算集群部署中,不斷動態添加、刪除計算節點,快速平衡負載等也對系統可擴展性提出挑戰。
(2)容錯和自動恢復:大數據計算框架需要考慮底層存儲系統的不可靠性,支持出現錯誤后自動恢復的能力。用戶不需要增加額外的代碼進行快照等中間結果的備份,只需要編寫相應的功能函數,就可以在有輸入的條件下得到預期的輸出,中間運行時產生的錯誤對使用人員透明,由計算框架負責任務重做。
(3)任務調度模型:大數據計算平臺中往往存在多租戶共同使用,多任務共同執行的情況。既要保證各用戶之間使用計算資源的公平性,又要保證整個系統合理利用資源,保持高吞吐率,還要保證調度算法足夠簡單高效,額外開銷小。因此調度器設計需要綜合大量真實的任務運行結果,從全局的角度進行設計。
(4)計算資源的利用率:計算資源的利用率代表機器能夠實際創造的價值。數據中心運轉時,能耗問題非常突出,設備和制冷系統都在消耗能源。由于不合理的架構設計,導致集群中非計算開銷大,計算出現忙等待的現象時有發生。高效的計算框架需要和硬件環境共同作用達到更高的計算資源利用率。
(5)時效性:數據的價值往往存在時效性,隨著時間的推移,新數據不斷產生,舊數據的利用價值就會降低。離線批量處理往往導致運算的時間長,達不到實時的數據處理。流計算方案減少了響應的時間,但是不能夠獲得數據的全貌。因此增量計算的方法是當今的一個解決思路。
(6)高效可靠的IO:大數據計算中,IO開銷主要分為兩部分,序列化反序列化時數據在硬盤上讀寫的IO開銷,不同節點間交換數據的網絡IO開銷。由于硬盤和網絡的IO讀寫速率遠遠低于內存的讀寫速率,導致整個任務的執行效率降低,計算資源被浪費。在現有的計算機體系結構下,盡可能使用內存能夠有效提高處理的速度,但是預取算法的合理性和內存的不可靠性都是需要考慮的問題。
2 大數據批量計算技術
大數據批量計算技術應用于靜態數據的離線計算和處理,框架設計初衷是為了解決大規模、非實時數據計算,更加關注整個計算框架的吞吐量。MapReduce低成本、高可靠性、高可擴展的特點降低了大數據計算分析的門檻,自Google提出以來,得到了廣泛應用。在此基礎上,人們設計出眾多的批處理計算框架,從編程模型、存儲介質等角度不斷提高批處理的性能,使其適應更多的應用場景。
(1)MapReduce計算框架:MapReduce計算框架通過提供簡單的編程接口,在大規模廉價的服務器上搭建起一個計算和IO處理能力強大的框架,并行度高,容錯性好,其開源項目Hadoop已經形成完整的大數據分析生態系統,并在不斷改進。可擴展性方面,通過引入新的資源管理框架YARN,減輕主節點的負載,集群規模提高,資源管理更加有效。任務調度方面,提出如公平調度[2]、能力調度[3]、延遲調度[4]等調度器,更加關注數據中心內資源使用的公平性、執行環境的異構性和高吞吐的目標。另外也采用啟發式方法進行預測調度,能夠實時跟蹤節點負載變化,提供更優的執行序列和資源分配方案。容錯性方面,MapReduce框架本身支持任務級容錯,任務失敗后會重新計算,但是對于Master節點的容錯一直忽略,現有的解決方法采用備份的方式解決,通過共享存儲同步數據,采用網絡文件系統(NFS)或者Zookeeper的方式來支持共享存儲。另外,MapReduce也已經添加了多平臺支持,可以部署在圖像處理單元(GPU)等高性能計算環境中。
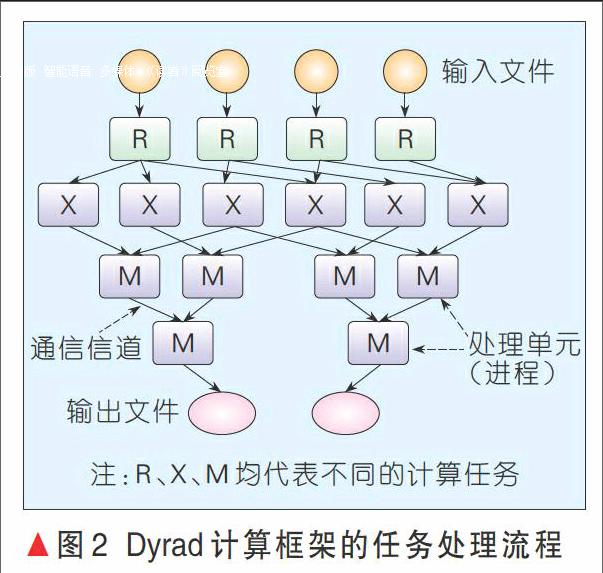
(2)Dryad計算框架:Dryad是構建微軟云計算基礎設施的核心技術。編程模型相比于MapReduce更具一般性——用有向無環圖(DAG)描述任務的執行,其中用戶指定的程序是DAG圖的節點,數據傳輸的通道是邊,可通過文件、共享內存或者傳輸控制協議(TCP)通道來傳遞數據,任務相當于圖的生成器,可以合成任何圖,甚至在執行的過程中這些圖也可以發生變化,以響應計算過程中發生的事件。圖2給出了整個任務的處理流程。Dryad在容錯方面支持良好,底層的數據存儲支持數據備份;在任務調度方面,Dryad的適用性更廣,不僅適用于云計算,在多核和多處理器以及異構集群上同樣有良好的性能;在擴展性方面,可伸縮于各種規模的集群計算平臺,從單機多核計算機到由多臺計算機組成的集群,甚至擁有數千臺計算機的數據中心。Microsoft借助Dryad,在大數據處理方面也形成了完整的軟件棧,部署了分布式存儲系統Cosmos[5],提供DryadLINQ編程語言,使普通程序員可以輕易進行大規模的分布式計算。
(3)Spark計算框架:Spark是一種高效通用的分布式計算框架,采用基于DAG圖的編程模型,提供了豐富的編程接口。不同于MapReduce只能通過串聯多個任務實現復雜應用,Spark可以在DAG圖中劃分不同的階段,完成復雜應用的定義。在計算效率方面,Spark將結果以及重復使用的數據緩存在內存中,減少了磁盤IO帶來的開銷,更適用于機器學習等需要迭代計算的算法;在容錯性方面,Spark表現突出,數據以彈性分布式數據集(RDD)[6]的形式存在,依靠Lineage的支持(記錄RDD的演變),能夠以操作本地集合的方式來操作分布式數據集。當RDD的部分分區數據丟失時,它可以通過Lineage獲取足夠的信息來重新運算和恢復丟失的數據分區。通過記錄跟蹤所有RDD的轉換流程,可以保證Spark計算框架的容錯性。資源管理及任務調度方面,Spark借助Mesos或者YARN來進行集群資源的管理,部署在集群中使用。Spark發展至今,已經形成了完整的軟件棧,在Spark的上層,已經能夠支持可在分布式內存中進行快速數據分析的Shark[7]、流計算Spark Streaming、機器學習算法庫Mllib、面向圖計算的GraphX等。
(4)GraphLab計算框架:圖計算框架GraphLab的提出是為了解決大規模機器學習問題。相比于信息傳遞接口(MPI),GraphLab提供了更簡單的編程接口,抽象的圖模型使用戶不必關注進程間的通信。相比于MapReduce計算框架,GraphLab更適合處理各數據之間依賴程度強、數據與數據之間需要頻繁計算和信息交互的場景。GraphLab提出的圖計算理論和方法不僅解決了集群中圖處理的擴展問題,也解決了單機系統中大規模的圖計算問題,可形成完整的面向機器學習的并行計算框架。但是,對于大規模自然圖的處理,GraphLab仍然存在負載極不均衡、可擴展性差等缺點,因而GraphLab團隊進一步提出了PowerGraph[8]。PowerGraph并行的核心思想是根據邊的規模對頂點進行分割并部署在不同的機器上,由于不需要將同一個節點所對應的所有邊的信息載入單機的內存中,因而消除了單機內存的約束。在系統的容錯性方面,PowerGraph采用檢查點技術,未來也考慮使用節點的副本冗余來提高容錯性,能夠在提高計算效率的同時完成快速恢復。
3 大數據流計算技術
大數據批量計算技術關注數據處理的吞吐量,而大數據流計算技術更關注數據處理的實時性,能夠更加快速地為決策提供支持。大數據的流計算技術是由復雜事件處理(CEP)發展而來的,現在流計算的典型框架包括Storm、S4、Samza、Spark Streaming等。
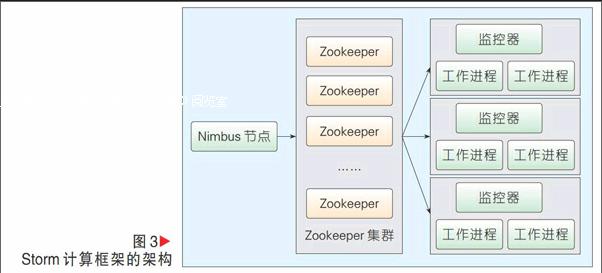
(1)Storm計算框架:Storm提供了可靠的流數據處理,可以用于實時分析、在線機器學習、分布式遠程過程調用(RPC),數據抽取、轉換、加載(ETL)等。Storm運行用戶自定義的拓撲,不同于MapReduce作業,用戶拓撲永遠運行,只要有數據進入就可以進行相應的處理。Storm采用主從架構,如圖3所示,主節點中部署Nimbus,主要負責接收客戶端提交的拓撲,進行資源管理和任務分配。從節點上運行監控器,負責從節點上工作進程也就是應用邏輯的運行。可擴展性方面,Storm借助于Zookeeper很好地解決了可擴展性的問題,集群非常容易進行橫向擴展,便于統一的配置、管理和監控。容錯性方面,使用 ZeroMQ 傳送消息,消除了中間的排隊過程,使得消息能夠直接在任務之間流動,其注重容錯和管理,實現了有保障的消息處理,保證每一個元組都會通過整個拓撲進行處理,未處理的元組,它會自動重放,再次進行。Storm的缺點是:集群存在負載不均衡的情況;任務部署不夠靈活,不同的拓撲之間不能相互通信,結果不能共用。
(2)S4計算框架:S4是Yahoo發布的開源流計算平臺,它是通用的、可擴展性良好、具有分區容錯能力、支持插件的分布式流計算平臺。S4采用分散對稱的架構,沒有中心節點,計算框架更加易于部署和維護。在計算過程中,每個計算節點都在本地內存中進行處理,避免了IO給計算帶來的巨大瓶頸。S4的核心思想是將整個任務處理分為多個流事件,抽象成為一個DAG圖,每個事件對應DAG圖中的一條有向邊,并用(K,A)的形式表示,其中K和A分別表示對應事件的鍵和屬性。這種表示類似MapReduce中的鍵/價值設計,適合多個處理進行連接。S4的結構如圖4所示,它采用Zookeeper來管理集群,提高了集群的可擴展性。在通信層,提供備用節點,如果有節點失敗,處理框架會自動切換到備用節點,但是在內存中的數據會發生丟失。主從備份雖然在一定程度上提高了容錯能力,但是相對較弱。同時通信層還使用一個插件式的架構來選擇網絡協議,通過TCP和用戶數據報協議(UDP)之間的權衡來提高網絡IO的速率。S4框架的主要缺點是:持久化相對簡單,數據存在丟失的風險;節點失敗切換到備份節點之后,任務都需要重做;缺乏自動負載均衡的相關能力。
(3)Samza計算框架:Samza是Linkedin開源的分布式流處理框架,其架構如圖5所示,由Kafka[9]提供底層數據流,由YARN提供資源管理、任務分配等功能。圖5也給出了Samza的作業處理流程,即Samza客戶端負責將任務提交給YARN的資源管理器,后者分配相應的資源完成任務的執行。在每個容器中運行的流任務相對于Kafka是消息訂閱者,負責拉取消息并執行相應的邏輯。在可擴展性方面,底層的Kafka通過Zookeeper實現了動態的集群水平擴展,可提供高吞吐、可水平擴展的消息隊列,YARN為Samza提供了分布式的環境和執行容器,因此也很容易擴展;在容錯性方面,如果服務器出現故障,Samza和YARN將一起進行任務的遷移、重啟和重新執行,YARN還能提供任務調度、執行狀態監控等功能;在數據可靠性方面,Samza按照Kafka中的消息分區進行處理,分區內保證消息有序,分區間并發執行,Kafka將消息持久化到硬盤保證數據安全。另外,Samza還提供了對流數據狀態管理的支持。在需要記錄歷史數據的場景里,數據實時流動導致狀態管理難以實現,為此,Samza提供了一個內建的鍵/價值數據庫用來存儲歷史數據。
(4)Spark Streaming計算框架:Spark是當前迭代式計算的典型代表,在前面的批量計算中已經介紹了Spark在大數據計算、數據抽象和數據恢復等方面的成果。如今Spark也在向實時計算領域發展,2013年發表于頂級會議SOSP上的論文介紹了Spark在流計算中取得的最新成果。Spark Streaming是建立在Spark上的應用框架,利用Spark的底層框架作為其執行基礎,并在其上構建了DStream的行為抽象。利用DStream所提供的應用程序編程接口(API),用戶可以在數據流上實時進行count、join、aggregate等操作。Spark Streaming的原理是將流數據分成小的時間片斷,以類似批量處理的方式來處理這小部分數據。DStream同時也是Spark Streaming容錯性的一個重要保障。
4 框架比較
隨著數據的爆炸式增長,大數據計算平臺在數據分析和處理中扮演著越來越重要的角色。本文分析了現有大數據處理面臨的挑戰和問題,詳細分析了批處理和流處理相關計算框架的特點和重點解決的問題,結合存儲、應用介紹了它們的核心創新點和軟件棧,這些框架的總結和對比如表1所示。
5 結束語
應用推進了技術的發展和革新,目前業界在不斷提高大數據計算框架的吞吐量、實時性、可擴展性等特性以應對日益增長的數據量和數據處理需求,大數據計算框架依然是現在以及未來一段時間內的研究熱點。未來的發展趨勢是:隨著商業智能和計算廣告等領域的發展,更強調實時性的流計算框架將得到更加廣泛的關注;能夠縮短批量計算處理時間的Percolator[10]、Nectar[11]、Incoop[12]等增量計算模式將獲得進一步的發展和應用;批量計算和流計算模式將進一步融合以減少框架維護開銷。而實際上,現在的Spark計算框架除了支持離線批處理任務以外,已經能夠通過Spark Streaming支持在線的實時分析。
除了計算框架本身的改進,消除磁盤IO和網絡IO對計算效率的影響也是重要的研究方向之一。這方面,內存計算已經取得了不錯的應用效果。例如,PACMan[13]用內存緩存輸入數據,從而加速了MapReduce的執行;文中提到的Spark也是盡可能將所有的數據放在內存中,從而減少磁盤隨機讀寫的IO開銷,提高任務的執行效率。由于內存資源始終是寶貴的,難以滿足大數據的存儲需求,因此在很多情況下將仍然充當緩存的角色,需要進一步探究更為高效的緩存管理算法。另一方面,非易失性存儲(NVM)器件的發展將對計算機系統的存儲架構帶來革命性的變化,如何充分利用新存儲介質及其存儲架構的特性提升計算效率也將是未來大數據計算框架研究的重要話題。
總之,應用的推動和技術的進步將會產生新的問題。作為大數據應用的核心,對于挖掘數據價值起著重要作用的計算框架將會面臨更多的挑戰,亟待解決。
參考文獻
[1] 孟小峰, 慈祥. 大數據管理: 概念, 技術與挑戰[J]. 計算機研究與發展, 2013, 50(1): 146-169
[2] ZAGARIA M, BORTHAKUR D, SARMA J S, et al. Job Scheduling for Multi-User MapReduce Clusters [R]. USA: EECS Department, University of California, 2009
[3] Hadoop.[EB/OL].[2013-08-24]. http://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html# Overview
[4] ZAHARIA M, KONWINSKI A, JOSEPH A D, et al. Improving MapReduce Performance in Heterogeneous Environments[C]// 8th USENIX Symposium on Operation Systems Design and Implementation(OSDI). USA: ASM, 2008: 7
[5] CHAIKEN R, JENKINS B, LARSON P, et al. SCOPE: Easy and Efficient Parallel Processing of Massive Data Sets [J]. Proceedings of the VLDB Endowment, 2008, 1(2): 1265-1276
[6] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for in-Memory Cluster Computing[C] //Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. USA: USENIX Association, 2012: 2-2
[7] XIN R S, ROSEN J, ZAHARIA M, et al. Shark: SQL and Rich Analytics at Scale[C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of data. USA: ACM Press,2013: 13-24
[8] GONZALEZ J E, LOW Y, GU H, et al. PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs[C]//Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USA: USENIX Association, 2012: 17-30
[9] KREPS J, NARKHEDE N, RAO J. Kafka: A Distributed Messaging System for Log Processing[C]//Proceedings of the 6th International Workshop on Networking Meets Databases (NetDB). USA: ACM Press, 2011
[10] PENG D, DABEK F. Large-Scale Incremental Processing Using Distributed Transactions and Notifications[C]// Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USA: USENIX Association, 2010: 1-15
[11] GUNDA P K, RAVINDRANATH L, THEKKATH C A, et al. Nectar: Automatic Management of Data and Computation in Datacenters[C]// Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USA: USENIX Association, 2010:75-88
[12] BHTOTIA P, WIDER A, RODRIGUES R, et al. Incoop: MapReduce for incremental computations[C]//Proceedings of the 2nd ACM Symposium on Cloud Computing. USA: ACM, 2011: 7
[13] ANANTHANARAYANAN G, GHODSI A, WANG A, et al. PACMan: Coordinated Memory Caching for Parallel Jobs[C]//9th USENIX Symposium on Networked Systems Design and Implementation(NSDI). USA: USENIX Association, 2012
