Spark計算引擎的數據對象緩存優化研究
2016-03-24 00:24:39陳康王彬馮琳
中興通訊技術 2016年2期
陳康 王彬 馮琳


摘要:研究了Spark并行計算集群對于內存的使用行為,認為其主要工作是通過對內存行為進行建模與分析,并對內存的使用進行決策自動化,使調度器自動識別出有價值的彈性分布式數據集(RDD)并放入緩存。另外,也對緩存替換策略進行優化,代替了原有的近期最少使用(LRU)算法。通過改進緩存方法,提高了任務在資源有限情況下的運行效率,以及在不同集群環境下任務效率的穩定性。
關鍵詞:并行計算;緩存;Spark;RDD
Abstract:In this paper, Spark parallel computing cluster for memory is studied. Its main work is about modeling and analysis of memory behavior in the computing engine and making the cache strategy automatic. Thus, the scheduler can recognize a valuable data object to be cached in the memory. A new cache replacement algorithm is proposed to replace least recently used (LRU) and have better performance in some applications. Thus, the performance and reliability of the Spark computing engine can be improved.
Key words:parallel computing; cache; Spark; resilient distributed dataset(RDD)
大數據處理的框架在現階段比較有影響力的是基于Google所發明的MapReduce[1]方法及其Hadoop[2]的實現。當然,在性能上傳統的消息傳遞接口(MPI)[3]會更好,但是在處理數據的方便使用性、擴展性和可靠性方面MapReduce更加適合。使用MapRecuce可以專注于業務邏輯,不必關心一些傳統模型中需要處理的復雜問題,例如并行化、容錯、負載均衡等。
由于Hadoop通過Hadoop分布式文件系統(HDFS)[4]讀寫數據,在進行多輪迭代計算時速度很慢。隨著需要處理的數據越來越大,提高MapReduce性能變成了一個迫切的需求,Spark[5]便是在此種背景下應運而生。
Spark主要針對多輪迭代中的重用工作數據集(比如機器學習算法)的工作負載進行優化,主要特點為引入了內存集群計算的概念,將數據集緩存在內存中,以縮短訪問延遲。
Spark編程數據模型為彈性分布式數據集(RDD)[6]的抽象,即分布在一組節點中的只讀對象集合。數據集合通過記錄來源信息來幫助重構以達到可靠的目的。RDD被表示為一個Scala[7]對象,并且可以從文件中創建它。
Spark中的應用程序可實現在單一節點上執行的操作或在一組節點上并行執行的操作。對于多節點操作,Spark依賴于Mesos[8]集群管理器。Mesos能夠對底層的物理資源進行抽象,并且以統一的方式提供給上層的計算資源。通過這種方式可以讓一個物理集群提供給不同的計算框架所使用。
Spark使用內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。使用這種方法,幾乎可以將所有數據都保存在內存中,這樣整體的性能就有很大的提高。然而目前Spark由于將緩存策略交由程序員在代碼中手動完成,有可能會引起緩存的低效甚至程序出錯,主要原因如下:
(1)程序員如果緩存無用的數據,將會導致內存未被充分利用,降低內存對程序性能的提升;
(2)錯誤的緩存甚至會產生內存溢出等嚴重后果,直接導致程序崩潰出錯;
(3)程序中有具有緩存價值的數據得不到緩存,將使程序不能達到最高效率。
隨著項目變大,代碼量增加,這個問題會變得越來越嚴重。如果使用自動分析的方法,自動完成緩存的工作,無疑會降低程序員負擔以及避免上述的問題。下面將對這方面進行初步研究,通過分析與建模,目的是使內存的使用更加智能有效,并加速任務的運行速度。
1 Spark中緩存優化研究
我們分3個方面對Spark中的緩存進行研究:一個是緩存自動化方法;一個是緩存替換方法改進;最后是程序執行調度順序與緩存的關系。
1.1 Spark中的緩存
Spark通過將RDD數據塊對象緩存在內存中這一方式對MapReduce程序進行性能上的提升改進。以經典的PageRank[9]算法為例,Spark比Hadoop快3倍左右。
以邏輯回歸算法實驗代碼為例,如圖1所示。
可以看出:在使用Spark時,從第2輪迭代計算開始,points的數據可以從緩存中直接讀取出來,因此獲得了極高的加速比。
1.2 數據對象的自動緩存
對于Spark來說,并不是每個RDD都要緩存到內存當中,需要進行篩選保留有價值的RDD存入內存。目前Spark中這種篩選的工作都交由程序員手動完成。以PageRank作為例子,如圖2所示。
代碼中有3個變量,且3個變量都是RDD類型,其中第1行最后的cache操作,會導致links 被緩存到內存,在循環中可以從內存中直接讀取,而ranks和contribs則沒有被緩存,這就是Spark 當前的緩存機制。
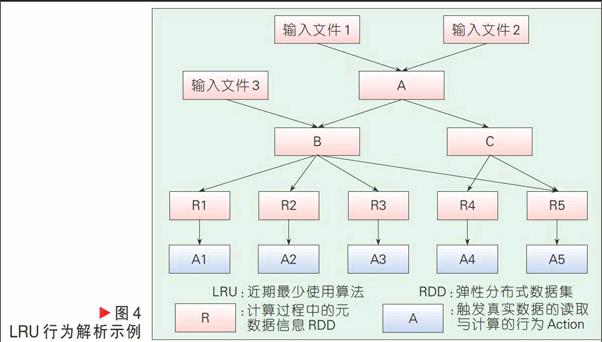
將緩存的工作交由程序員手動完成,對于系統本身的實現來講,是簡化了許多,但是對于程序員來講則是極大的挑戰。對于復雜操作,程序員通常很難直接分析出具有緩存價值的數據對象進行緩存。sortByKey是用來對數據依據其指定的鍵值進行排序的一個常用操作,具體如圖3所示。
