基于粗糙集理論的影響高校學生成績因素研究
2016-02-27 02:01:17蔡興雨程智煒
計算機技術與發展 2016年11期
蔡興雨,徐 怡,2,程智煒
(1.安徽大學 計算機科學與技術學院,安徽 合肥 230601;2.安徽大學 計算智能與信號處理教育部重點實驗室,安徽 合肥 230039)
基于粗糙集理論的影響高校學生成績因素研究
蔡興雨1,徐 怡1,2,程智煒1
(1.安徽大學 計算機科學與技術學院,安徽 合肥 230601;2.安徽大學 計算智能與信號處理教育部重點實驗室,安徽 合肥 230039)
成績是衡量教師教學質量以及學生學習效果的重要指標。由于影響學生學習成績的因素眾多,教師和學生不能清楚地認識影響成績的關鍵因素。一方面,教師無法對教學方法做出有針對性的改進,以提高教學質量;另一方面,學生無法對學習方法做出有針對性的改進,以提高學習成績。為了幫助高校教師及學生準確分析影響學習成績的關鍵因素,設計了用于調查影響高校學生學習成績因素的調查問卷,向該校大一至大四的學生分發調查問卷并收集數據,然后利用粗糙集理論的基于信息熵的啟發式屬性約簡算法,找出影響高校學生學習成績的關鍵因素,之后利用基于粗糙集理論的改進的基于分辨矩陣的屬性值約簡算法,挖掘出影響高校學生學習成績的關鍵因素和成績之間的依賴關系,導出規則集。通過實驗驗證了該規則集的有效性。研究成果可以幫助高校教師和學生了解影響成績的關鍵因素,從而改進教師的教學方法和學生的學習方法。
高校學生;成績影響因素;粗糙集;規則提取;屬性約簡
0 引 言
學生成績在衡量高校教師教學質量以及學生學習效果中意義重大,從成績中可以看出教師是否完成教學目標,學生對知識的了解和掌握程度是否達到較滿意的水平。所以無論是高校教師希望改善教學質量還是學生希望進一步掌握知識,提高成績都是非常重要的,而影響高校學生學習成績的因素眾多,在面對這么多的因素時,學生和老師可能無法找出哪些是關鍵性的影響因素,進而無法有針對性地做出努力以有效提高學生成績。目前對影響學生學習成績關鍵因素的研究多是通過調研的方法獲取數據,然后利用統計的方法進行分析,很少利用數據挖掘的方法對調研數據做深刻的分析,找出隱藏在數據中的規律性知識。因此,文中設計了影響高校學生學習成績因素的調查問卷,向該校大一至大四的學生分發調查問卷并收集數據,然后利用粗糙集理論的屬性約簡算法和規則提取算法,挖掘出影響高校學生學習成績的關鍵因素以及這些關鍵因素和成績之間的依賴關系,導出規則集,并通過實驗驗證了規則集的有效性。文中的研究成果可以幫助高校教師和學生了解影響成績的關鍵因素,從而改進教師的教學方法和學生的學習方法。
文中所采用的粗糙集(Rough Set,也稱Rough集、粗集)理論[1-2]是Pawlak教授在1982年提出的一種能夠定量分析處理不精確、不一致、不完整知識與信息的數學工具。該理論最初的原型來源于比較簡單的信息模型,它的基本思想是通過關系數據庫分類歸納形成概念和規則,通過等價關系的分類以及分類對于目標的近似實現知識發現。粗糙集理論能處理模糊和不確定的知識,在保持分類能力不變的前提下,通過知識約簡,導出決策和分類規則。所以文中利用粗糙集對收集的300份中有效的279份成績樣本先進行屬性約簡,然后進行規則提取,得出了影響高校學生成績的關鍵因素。
1 基本概念
文中用到的相關概念介紹如下[3]:
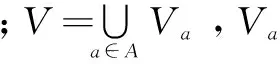
定義2:信息系統S=(U,A,V,f),若A=C∪D,C∩D=?,C為條件屬性集,D為決策屬性集,這樣的信息系統稱為決策表,決策表是一類特殊而重要的信息系統。

定義4:R為一族等價關系P∈R,若ind(R)=ind(R-{P}),則稱P為R中不必要的,否則稱P為R中必要的。如果每一個P∈R都是必要的,則稱P為獨立的,否則稱P為依賴的。
定義5:對于一個決策表S=(U,C∪D,V,f),B?C,若B是獨立的,且ind(B)=ind(C),則稱B是C的一個約簡,記為red(C)。
定義6:核屬性定義為core(P)=∩red(P),其中red(P)表示P的所有約簡。
核的概念的用處:(1)可以作為所有約簡的基礎;(2)在知識約簡中是不能消去的知識特征集合。

定義8:在信息系統S=(U,A,V,f)中,C∈A,?a∈A-C關于屬性集C的重要性定義為:
sgfc(a)=H(C∪{a})-H(C)
由定義可知,屬性a∈A-C關于屬性集C的重要性由C中添加a后所引起的信息熵的變化大小決定,此值越大,a關于C越重要。
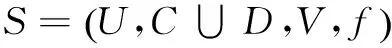
因此,分辨矩陣中元素cij是能夠區別對象xi和xj的所有屬性的集合;但若xi和xj屬于同一決策類時,則分辨矩陣中元素cij的取值為空集?。顯然,分辨矩陣是一個依主對角線對稱的n階方陣,在進行分辨矩陣運算時,只需考慮其上三角(或下三角)部分[5]。
對于規則的質量,有三個衡量標準,分別是置信度、覆蓋度和支持度[6]:
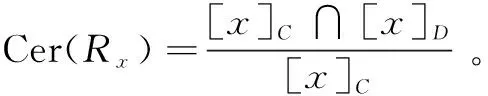
確定性程度Cer(Rx)反映了決策規則的可信性,或者說置信度,是衡量規則r中條件類分配到決策類的精度。

覆蓋度Cov(Rx)用來評估決策規則的質量,反映了決策規則條件類對決策類的覆蓋程度。
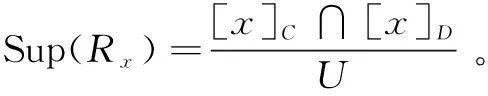
支持度Sup(Rx)用來衡量決策規則的強度,反映了論域中支持此決策規則的對象占全體對象的比例。支持度越大,說明支持該決策規則的對象越多,規則的強度就越大,規則的泛化能力和魯棒性就越好。
2 屬性約簡方法
現有的主流屬性約簡方法有基于正域的屬性約簡方法、基于屬性依賴度的屬性約簡方法、基于信息熵的屬性約簡方法和基于差別矩陣的屬性約簡方法等[7-10]。基于信息熵的屬性約簡方法利用信息熵來度量屬性重要度,算法運行效率和準確性都相對較高。因此,文中采用基于信息熵的屬性約簡方法,算法描述如下[11]:
輸入:信息系統S=(U,A,V,f);
輸出:信息系統的核與最小約簡。
步驟1:計算H(A)。
步驟2:求Core(A)。
(1)Core(A)=?;
(2)對每個a∈A,計算sgf(a);
(3)對每個a∈A,IFsgf(a)>0THENCore(A):=Core(A)∪{a};
(4)輸出Core(A)。
步驟3:求最小約簡。
(1)令C=Core(A),執行以下過程;
(2)若H(C)=H(A),則C為A的一個約簡,轉(3),否則轉(2);

(4)輸出約簡C。
3 規則提取方法
規則提取即為屬性值約簡,是在保持決策能力不變的前提下,在屬性約簡的基礎上,進一步刪除冗余的屬性值以提高生成規則的泛化能力。屬性值約簡有很多種算法,常見的有一般值約簡算法、基于分辨矩陣的值約簡算法、基于LEM2的規則提取算法等[12-13]。由于基于分辨矩陣的規則提取方法簡單易操作,但效率較低,所以為了提高效率,文中采用一種改進的基于分辨矩陣的屬性值約簡算法,描述如下[14]:
輸出:該決策表的一個決策規則集R。
步驟1:構造M(S)。
步驟2:計算第i行核屬性C0。
(1)C0=0;
(2)num(j)為M(S)第i行第j個元素所含的屬性個數,對M(S)每一行IFnum(j):=1THENC0:=C0∪cij。
步驟3:修改M(S)。
(1)B←C0;
(2)IFCij∩B≠?
THENM(S)=M(S)-{Cij}
其中i為定值,即將分辨矩陣的第i行中所有與B相交不空的屬性集賦空;
(3)IFM(S)第i行為空,THEN執行步驟4,ELSE轉(4);
(4)計算每個c屬于C-B的重要性,擴充B,計算c∈C-B在M(S)的第i行中出現的次數,將出現次數最多的屬性加入B轉(2)。
步驟4:得出規則。
(1)對于第i行IFc∩B:=?THENDes([x]B)→Des([x]D);
(2)用上述算法對每一行對象進行處理,最終得到決策規則集R。
4 實驗分析
4.1 數據收集
為了得到大量相關數據來研究影響高校學生學習成績的關鍵因素,設計了一份影響高校學生學習成績的調查問卷。問卷內容涵蓋了學生基本信息、學習態度、學習方法三大方面。其中,基本信息包括學生的個人信息和家庭信息,學習態度包括學習目的與學習動力,學習方法包括學習的時間地點與方式手段。問卷共包括21個問項,前20個構成條件屬性,后一個為決策屬性。為了便于數據處理與提取,所有問項皆為單選,每個答案獨立不重疊。具體的調查問卷見表1。

表1 調查問卷
為了使調研對象的分布較均勻,調研結果更加可靠,調研對象為在校的大一到大四的學生,調研地點有宿舍、圖書館、自習室、考研教室、食堂、校園街道。總共收了300份問卷,剔除其中不符合要求以及明顯隨意填寫無參考價值的21份問卷,剩余279份為真實有用數據。
4.2 數據處理
使用第2節中基于信息熵的屬性約簡算法對收集的279份數據進行屬性約簡,約簡結果為14個屬性:性別*,父母的平均文化程度*,每周上網的時間,上課時一般坐在第幾排,母親職業,圖書館借書頻率,愛好,鍛煉身體的時間,購買學習輔導書,學習上遇到問題時的解決方式,作業是否獨立完成,翹課的頻率,努力學習的原因。其中,打*的2個為核屬性。
在上述屬性約簡的基礎上利用第3節中改進的基于分辨矩陣的屬性值約簡算法對約簡后的決策表進行處理,得出了33條有效規則,鑒于篇幅有限,在此就不列出了。其中,覆蓋度0.5以上,支持度0.3,置信度0.9以上的規則共16條,如表2所示。

表2 規則集
其中,Ci=j中的Ci代表表1中的第i個問題也是第i個條件屬性,Ci的值j代表表1中第i個問題的第j個選項也是條件屬性的值,D為決策屬性,D的值為表1中第二十一個問題的選項也是決策屬性值。
為了驗證得出規則的質量,從279份數據中分別隨機抽出30%、60%、90%的數據作為測試用數據,以驗證上述16條規則的分類精度,也就是規則的可靠程度。為了保證結果的準確性,對每種比例的測試數據都抽取了100次,如30%的測試數據,抽取100次,計算每次抽取組的分類精度,取100次分類精度的平均值作為最終結果。不同比例測試數據的分類精度如表3所示。
從表3中可以看出,通過運用基于信息熵的屬性約簡算法以及改進的基于分辨矩陣的屬性值約簡算法后,得出的16條規則的分類精度均在0.7以上,由此可見從數據集中得出的16條規則是較為可靠的。
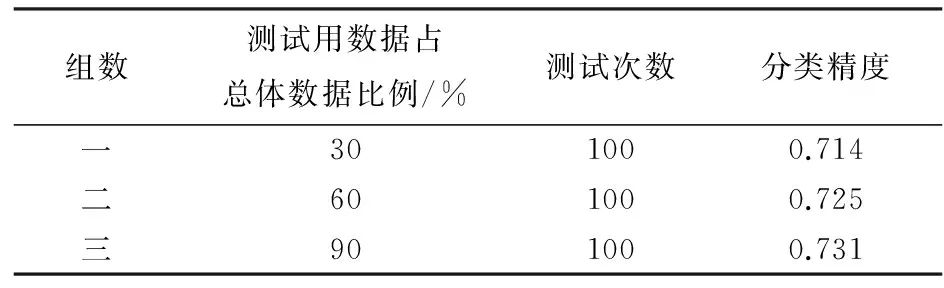
表3 16條規則的分類精度
為了進一步驗證文中方法的正確性,從279份數據里隨機抽取50%、60%、70%、80%、90%的數據作為訓練數據,剩余數據作為測試數據,進行交叉測試,每組交叉測試進行100次。計算結果如表4所示。

表4 交叉測試結果
從表4的測試結果中不難得出,當訓練數據量和測試數據量各占總數據量的50%時,分類精度依然可以達到0.6以上,說明文中采用的算法較為恰當,得到的規則的準確度和泛化能力也比較好,從而驗證了文中方法的有效性,證明了文中結論的精確性。而且當訓練數據增多時,分類精度也逐漸提高。這是因為訓練數據越多,所提取規則的質量也越好,這個結果也符合人的直觀認識。
從上述實驗分析結果可以看出,影響高校學生成績的因素可以分為兩個方面:一是主觀態度,包括:上自習時間、上網時間、鍛煉身體的時間、上課時坐在第幾排、圖書館借書頻率、作業是否獨立完成以及翹課頻率等;二是客觀環境,包括:性別、父母文化程度、母親職業等。再由得出的規則綜合來看,一是態度積極向上的學生成績多優于態度一般的學生,像自習時間、圖書館借書頻率、作業獨立完成情況、鍛煉身體的時間等與學校成績呈正相關,而上網時間、翹課頻率與學生成績呈負相關;二是女生成績普遍好于男生,因為女生比較細心,在學習考試當中更容易取得優良的成績;三是父母文化程度越高孩子成績越好,因為文化程度高的父母可以為子女提供更好的學習指引,更擅長培養子女良好的學習習慣。從提取的規則中發現有趣的是母親的職業對孩子成績的影響要大于父親職業的影響,也許是受中國相夫教子的傳統影響,母親在子女成長的過程中陪伴的更多,母親的很多行為習慣比父親對子女造成的影響更大,所以母親在孩子的學習生活中扮演著非常重要的角色。
以上研究成果可以幫助高校教師和學生了解在眾多的影響因素中有哪些是影響學生學習成績的最關鍵因素,以及這些關鍵因素和成績之間的依賴關系,從而幫助教師改進教學方法,并幫助學生改進學習方法,以更好地提高成績。
5 結束語
為了幫助高校教師及學生準確分析影響學習成績的關鍵因素,以有效提高學生成績,文中設計了影響高校學生學習成績因素的調查問卷,構成決策表,然后利用粗糙集理論的屬性約簡和規則提取算法,從決策表中提取影響高校學生學習成績的關鍵因素以及這些關鍵因素和成績之間的依賴關系,導出規則集,通過實驗驗證了規則集的有效性。研究成果可以幫助高校教師改進教學方法,幫助高校學生改進學習方法。
[1]PawlakZ,Grzymala-BusseJW,SlowinskiR,etal.Roughsets[J].CommunicationsoftheACM,1995,38(11):88-95.
[2]PawlakZ,SkowronA.Roughsets:someextensions[J].InformationSciences,2007,177(1):28-40.
[3] 張文修,吳偉志,梁吉業,等.粗糙集理論與方法[M].北京:科學出版社,2001.
[4] 呂林霞,趙錫英,唐占紅.一種基于信息熵的信息系統屬性約簡算法[J].自動化與儀器儀表,2013(5):197-199.
[5]PawlakZ.Roughsetapproachtoknowledge-baseddecisionsupport[J].EuropeanJournalofOperationalResearch,1997,99(1):48-57.
[6]PawlakZ.Roughsets,decisionalgorithmsandBayes'theorem[J].EuropeanJournalofOperationalResearch,2002,136(1):181-189.
[7] 陳 娟,王國胤,胡 軍.優勢關系下不協調信息系統的正域約簡[J].計算機科學,2008,35(3):216-218.
[8] 路松峰,劉 芳,胡 波.一種基于屬性依賴的屬性約簡算法[J].華中科技大學學報:自然科學版,2008,36(2):39-41.
[9]FaustinoAgreiraCI,MachadoFerreiraCM,MacielBarbosaFP.Roughsettheory:dataminingtechniqueappliedtotheelectricalpowersystem[M].Netherlands:Springer,2013.
[10] 楊 萍,李濟生,黃永宣.一種基于二進制區分矩陣的屬性約簡算法[J].信息與控制,2009,38(1):70-74.
[11] 吳尚智,茍平章.粗糙集和信息熵的屬性約簡算法及其應用[J].計算機工程,2011,37(7):56-58.
[12] 徐 怡,李龍澍,李學俊.改進的LEM2規則提取算法[J].系統工程理論與實踐,2010,30(10):1841-1849.
[13]Grzymala-BusseJW.AnewversionoftheruleinductionsystemLERS[J].FundamentalInformation,1997,31(1):27-39.
[14] 饒 泓,夏葉娟,李姆竹.基于分辨矩陣和屬性重要度的規則提取算法[J].計算機工程與應用,2009,44(23):163-165.
Research on Factors Affecting College Achievement Based on Rough Set
CAI Xing-yu1,XU Yi1,2,CHENG Zhi-wei1
(1.Department of Computer Science and Technology,Anhui University,Hefei 230601,China; 2.Key Lab of Intelligent Computing and Signal Processing of Ministry of Education,Anhui University, Hefei 230039,China)
Achievement is an important indicator of teaching quality and student learning.Because of many factors that affect student’s achievement,teachers and students cannot clearly recognize the key factors affecting the results.Therefore,on the one hand,teachers cannot make an improvement to teaching methods to improve the quality of teaching.On the other hand,students are unable to make targeted improvements to the learning methods to improve study performance.To help college students and teachers for analysis of key factors influencing academic performance accurately,a questionnaire about factors affecting college student achievement is designed.Those data are collected from the school’s freshman to senior,then using heuristic attribute reduction algorithm based on information entropy in rough set theory to identify the key factors affecting the performance of college students,and next applying improved property values reduction algorithm based on resolution matrix in rough set theory to mine key factors affecting student achievement and college students dependencies between the results derived the rule set.Finally through the experiment,the validity of the rule set is verified.Research can help university teachers and students to understand the key factors that affect performance,thereby improving the way teachers teaching and students learning.
college student;factors affecting achievement;rough set;rule extraction;attribute reduction
2016-01-21
2016-04-26
時間:2016-10-24
國家自然科學基金資助項目(61402005);安徽省自然科學基金項目(1308085QF114);安徽省高等學校省級自然科學基金項目(KJ2013A015,KJ2011Z020);安徽大學大學生科研訓練計劃項目(KYXL2014064);安徽大學計算智能與信號處理教育部重點實驗室開放課題項目
蔡興雨(1994-),男,研究方向為機器學習、數據挖掘;徐 怡,副教授,博士,研究方向為智能信息處理和粗糙集理論。
http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1114.048.html
TP39
A
1673-629X(2016)11-0200-05
10.3969/j.issn.1673-629X.2016.11.043
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
幸福(2018年33期)2018-12-05 05:22:42
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
中國科技信息(2016年14期)2016-07-31 21:16:32
