基于深度學習的人臉姿態分類方法
2016-02-27 06:31:58鄧宗平趙啟軍
計算機技術與發展 2016年7期
鄧宗平,趙啟軍,陳 虎
(四川大學 計算機學院 視覺合成圖形圖像技術國防重點學科實驗室,四川 成都 610065)
基于深度學習的人臉姿態分類方法
鄧宗平,趙啟軍,陳 虎
(四川大學 計算機學院 視覺合成圖形圖像技術國防重點學科實驗室,四川 成都 610065)
人臉姿態通常表達著有用的信息,準確地把握人臉的姿態,往往在人臉對齊、人類行為分析以及司機疲勞駕駛監控等方面有著重要的作用。文中方法與以往姿態估計方法不一樣,是一種基于卷積神經網絡,應用深度學習做人臉姿態分類的方法。首先,第一次網絡對姿態在yaw方向上進行5分類,同時在roll方向具有魯棒性。之后,將第一次輸出正臉的結果進入第二次網絡,對姿態在pitch方向進行3分類。所有的輸出結果對光照都具有魯棒性。文中采用級聯的方法在公開庫上做測試,準確率高達95%以上。在實際監控視頻中,姿態估計不僅有較高的準確率,而且有驚人的速度。由于本身實驗的設計獨特性,只做了自身實驗對比。結果充分展示了用合理的神經網絡與網絡級聯的方法在姿態估計上面的發展潛力。
姿態分類;級聯;深度學習;卷積神經網絡
0 引 言
人臉姿態估計是模式識別與計算機視覺領域重要的研究課題。人臉姿態估計在人臉對齊、人臉識別方面有著重要的影響。比如,在已知不同的姿態前提下可以有更精確的算法來進行對齊或匹對工作。此外,人臉姿態自身也具有重要的實際應用價值,比如疲勞駕駛監控[1]、消費者購物行為分析等。
研究人員提出了很多姿態估計的方法,比如:基于模型的方法[2]、基于人臉外觀的方法[3]、基于3維人臉的方法[4]。同時在文獻[5]中,還提出了一種基于橢圓模板和眼睛嘴巴位置的人臉姿態估計方法。常用算法包括支持向量機、基于特征空間的方法[6],以及使用神經網絡[7]的姿態估計,等等。
文中運用深度學習的方法對人臉姿態進行大角度分類。首先用第一級網絡進行5種姿態分類(左+,左,正,右,右+),在第一級分類為正臉的前提下進行第二層網絡,再區分3種姿態(俯,正,仰),然后進行相關參數對比實驗。實驗結果表明,用深度學習的方法進行姿態分類是可行的,而且可以得到令人滿意的效果。實驗的關鍵在于合理的卷積神經網絡設計,有效的數據處理與級聯方式,以及在訓練網絡過程中選擇合適的參數。
1 深度學習與卷積神經網絡
深度學習的概念源自人工神經網絡,其是包含多隱藏層的多層感知器(MLP)。它通過對輸入數據的低層特征學習來形成更加抽象的高層特征表示,從而學習到數據的分布規律[8]。文獻[9]揭示了深度學習的發展潛力。此后,文獻[10-12]也展示了深度學習在圖片分類、人臉識別、行人檢測、信號處理等領域所取得的成果。深度學習之所以稱之為“深度”是相較于傳統的機器學習方法而言的,比如支持向量機(SVM)[13]、提升方法(boosting)、最大熵方法等。
深度學習網絡的非線性操作的層數比較多,屬于非監督的學習。深度學習常用的算法包括:自動編碼器、稀疏自動編碼器、受限玻爾茲曼機、卷積神經網絡、深度信念網絡[14]等。實驗選用卷積神經網絡。
卷積神經網絡是人工神經網絡的一種,是計算機視覺與模式識別、語音分析等領域研究的熱點。卷積神經網絡是由多層的神經網絡構成,每一層又可以有多個二維平面,每一個平面有多個獨立的神經元。典型的卷積神經網絡如圖1所示。
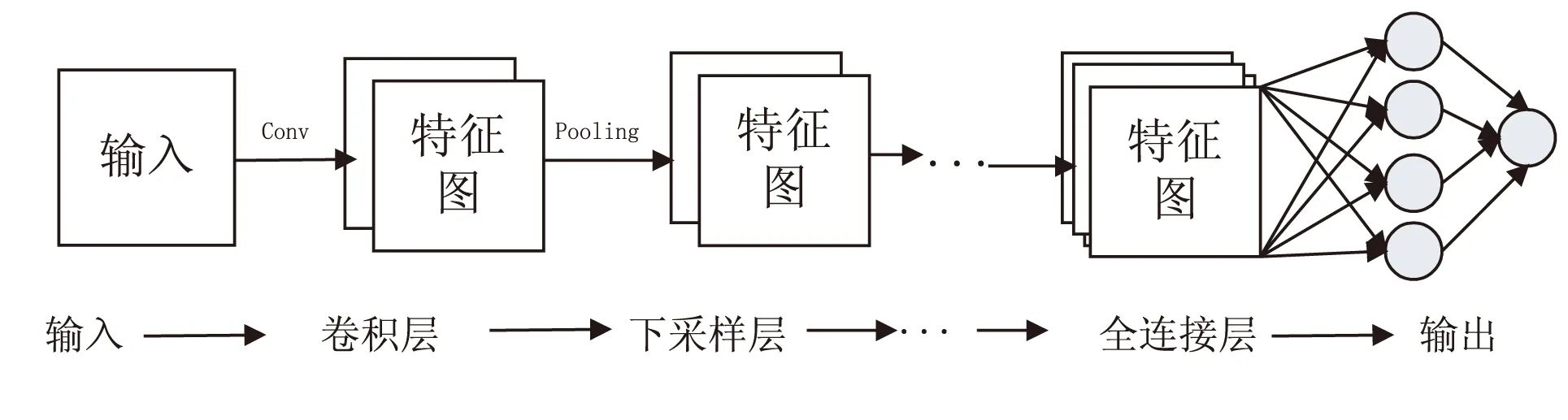
圖1 卷積神經網絡
文中實驗也按照這樣的“卷積-pooling-卷積-pooling”設計模式進行網絡設置,并且采用兩層級聯的方法進行相應的姿態分類。
2 實驗評估參數
測試實驗評估包括兩個方面:一方面是訓練模型實時輸出性能指標,包括損失函數(loss)、訓練中測試準確率(accuracy);另一方面是模型測試性能指標,包括分類準確率、姿態分類時間。
2.1 訓練實時輸出性能指標分析
假設網絡最后的全連接層輸出5維數據是θi(i=0,1,…,4),則輸出概率函數可表示為:
(1)
損失函數定義如下:
loss=-log(σi(θ))
(2)
其中,σi(θ)表示屬于第i類的概率大小,即預測出來的屬于每一類的概率大小。由于σi(θ)在[0,1]之間,則對應的loss值就應該取值在(0,+∞)。因此,loss值越小,表明學習到的特征越好。
網絡最后接accuracy層輸出,其為評判分類準確度,accuracy越接近1,說明訓練分類效果越好。
對比實驗主要是調節三個參數,它們分別是學習率(base_lr)、學習步長(stepsize)、最大迭代次數(max_iter)。學習率是指神經網絡學習數據特征的能力,學習步長是每學習一定次數之后相應改變學習率的次數大小,最大迭代次數是學習總的次數。
2.2 測試結果性能指標
對訓練好的模型進行性能評估,包含了兩個重要指標:一是測試已知類型的姿態圖片獲取的準確率;二是進行姿態分類估計所需要耗費的時間(ms)。
3 實驗與測試
3.1 數據集
訓練數據分別來源于FERET,Multi-pie,Cas-peal和point-04公開數據庫。四個數據庫的共同特點在于,它們的數據是按照不同角度進行的分類,因此便于對數據集進行加標簽分類。實驗第一個網絡把姿態角分為5類,第二個網絡姿態分為3類。
3.2 數據處理方式
由于原始數據的數量有限性,實驗需要對原始數據進行擴充。實驗之前,對相應的原始數據按1:5的比例劃分測試集與訓練集,然后對訓練數據進行擴充。數據處理方法如下:
(1)人臉檢測;
(2)獲取人臉框之后,用旋轉、平移、縮放的方式對訓練數據進行擴充;
(3)同時為了讓姿態分類模型適應不同的環境條件,實驗對部分圖片進行加光照、加噪聲的處理。
在各種處理方式下,最終數據分布均勻,訓練圖片全部歸一化為32*32大小的灰度圖,如圖2所示。

圖2 實驗灰度圖(旋轉角(上),俯仰角(下))
3.3 網絡設置
實驗網絡使用3層卷積層,3層下采樣,網絡層之間加適當的變換層,最后的網絡進行兩次全連接。第一次網絡輸出一組5維向量,第二次網絡在第一次預測結果為正臉的情況下進行再分類,精細姿態角是俯仰還是平視角度,最后的輸出都是3維向量。最終經過兩層網絡,實驗得到的結果是7分類問題。級聯方式如圖3所示。
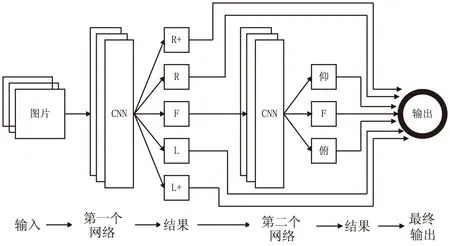
圖3 級聯示意圖
3.4 對比訓練方法與評估
表1是實驗對部分參數的嘗試并且修改部分參數
后獲取的結果。進行了多組實驗,結果表明,當初始base_lr設置過大(大于0.01),網絡很快出現飽和狀態,反之,學習能力很弱,獲取的有效信息很少。同時,對學習步長和學習迭代次數的設置也會直接影響學習的效果。因此,設計了5組實驗進行對比,對比結果如表1所示,兩層網絡的訓練方法是一致的。
3.5 測試方法與結果
根據上面的實驗比較,把實驗4訓練出的模型作為測試模型,測試方法是根據已知角度的圖片進行定量分析,測試集不僅包括訓練的各種角度,而且包含了光照、旋轉的變化。所有的測試圖片預處理方法與訓練數據一致。同時,實驗對人臉由輸入網絡到輸出結果的所需時間進行計算,準確地記錄姿態估計所需要的時間。實驗取得了較高的準確率,在測試速度上也同樣令人滿意。測試結果與測試環境如表2所示。

表1 參數對比實驗及結果
注:Mean-loss表示平均誤差,參數越小越好;Max-accuracy表示訓練中最大準確率;Last-accuracy表示最終收斂的準確率。
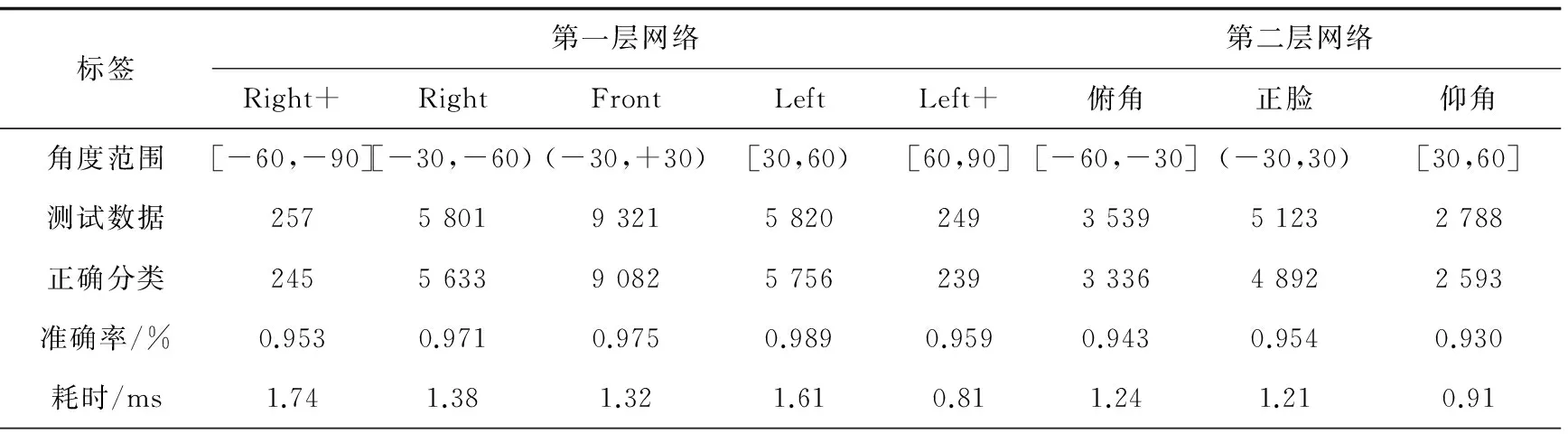
表2 網絡實驗結果與時間統計
注:測試電腦配置,4核cpu處理器:intel i5-4690 3.50 GHz,顯卡:NVIDIA GeForce GTX750。
3.6 實驗總結
由實驗結果可知,使用深度學習方法進行姿態估計,不管在數據庫還是在實際應用場景都是可行的。
4 結束語
文中應用深度學習在人臉姿態問題上進行了嘗試,結果表明,深度學習是一種高效、高準確度的新方法。但是,實驗還存在不足之處,有待進一步研究。總的說來,深度學習下進行人臉姿態估計,是一個可行且高效的方法。為了突破已有成果與應用的限制,更大的數據、更深的網絡將會是一個契機,在大數據的支持下,把更多更好的人臉姿態估計應用到實際生活中,比如:場景監控、司機駕駛監控,甚至是物體形態分析,都將成為可能,相信在深度學習的浪潮中人臉姿態估計會有更好的發展。
[1] Ghaffari A,Rezvan M,Khodayari A,et al.A robust head pose tracking and estimating approach for driver assistant system[C]//Proc of IEEE international conference on vehicular electronics and safety.[s.l.]:IEEE,2011:180-186.
[2] Yang R,Zhang Z.Model-based head pose tracking with stereovision[C]//Proceedings of fifth IEEE international conference on automatic face and gesture recognition.[s.l.]:IEEE,2002:255-260.
[3]NgJ,GongS.Compositesupportvectormachinesfordetectionoffacesacrossviewsandposeestimation[J].Image&VisionComputing,2002,20(5):359-368.
[4]BaggioDL,EmamiS,EscrivaDM,etal.MasteringOpenCVwithpracticalcomputervisionprojects[M].Birminghan:PacktPublishingLtd,2012:208-254.
[5] 施 華.頭部姿態估計與跟蹤系統的研究與實現[D].上海:華東師范大學,2015.
[6]DarrellT,MoghaddamB,PentlandAP.Activefacetrackingandposeestimationinaninteractiveroom[C]//Procof2013IEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEEComputerSociety,1996:67-67.
[7]HoggT,ReesD,TalhamiH.Three-dimensionalposefromtwo-dimensionalimages:anovelapproachusingsynergeticnetworks[C]//ProceedingsofIEEEinternationalconferenceonneuralnetworks.[s.l.]:IEEE,1995:1140-1144.
[8] 余 凱,賈 磊,陳雨強,等.深度學習的昨天、今天和明天[J].計算機研究與發展,2013,50(9):1799-1804.
[9]KrizhevskyA,SutskeverI,HintonGE.Imagenetclassificationwithdeepconvolutionalneuralnetworks[M]//Advancesinneuralinformationprocessingsystems.[s.l.]:[s.n.],2012:1097-1105.
[10]LuoP.Hierarchicalfaceparsingviadeeplearning[C]//ProcofIEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2012:2480-2487.
[11]SunY,WangX,TangX.Deepconvolutionalnetworkcascadeforfacialpointdetection[C]//ProceedingsofIEEEcomputersocietyconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2013:3476-3483.
[12]ZhuZ,LuoP,WangX,etal.Deeplearningidentity-preservingfacespace[C]//Proceedingsof2013IEEEinternationalconferenceoncomputervision.[s.l.]:IEEEComputerSociety,2013:113-120.
[13] 王 輝.主成分分析及支持向量機在人臉識別中的應用[J].計算機技術與發展,2006,16(8):24-26.
[14]HuangGB.Learninghierarchicalrepresentationsforfaceverificationwithconvolutionaldeepbeliefnetworks[C]//ProcofIEEEconferenceoncomputervisionandpatternrecognition.[s.l.]:IEEE,2012:2518-2525.
Face Pose Classification Method Based on Deep Learning
DEND Zong-ping,ZHAO Qi-jun,CHEN Hu
(National Key Laboratory of Fundamental Science on Synthetic Vision,School of Computer Science,Sichuan University,Chengdu 610065,China)
Face pose usually contains useful information,so detecting it accurately plays an important role in face alignment,human behavior analysis and drivers’ fatigue driving monitoring.A novel method is proposed in this paper which applies deep learning to human face pose classification based on convolutional neural networks.It can be divided into two steps mainly.First,layer one classifies pose into 5 categories at direction yaw,and it’s of robustness at direction roll.Then layer two takes the result of step one as input to classify pose into 3 categories at direction pitch.All outputs are robust to illumination.The cascade connection is used to test on public benchmark,and the result shows that its accuracy is 95%.In real surveillance video,it has both high accuracy and fast estimating speed.Due to the particularity of experiment,it only contrasts the result to itself.Experimental results show that well-designed cascade connection of neural network can estimate pose well.
pose classification;cascade;deep learning;convolutional neural network
2015-11-12
2016-03-09
時間:2016-06-22
國家自然科學基金資助項目(61202160,61202161);科技部重大儀器專項(2013YQ49087904)
鄧宗平(1990-),男,碩士研究生,研究方向為模式識別、計算機視覺;趙啟軍,副教授,碩士生導師,研究方向為深度學習、模式識別、機器學習、計算機視覺等;陳 虎,講師,碩士生導師,研究方向為模式識別、圖像處理等。
http://www.cnki.net/kcms/detail/61.1450.TP.20160622.0845.060.html
TP301
A
1673-629X(2016)07-0011-03
10.3969/j.issn.1673-629X.2016.07.003
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
