基于改進HOG特征的空間非合作目標檢測
2016-02-24 07:01:04陳路黃攀峰蔡佳
航空學報 2016年2期
陳路, 黃攀峰, *, 蔡佳
1. 西北工業(yè)大學 航天飛行動力學技術重點實驗室, 西安 710072 2. 西北工業(yè)大學 航天學院智能機器人研究中心, 西安 710072
基于改進HOG特征的空間非合作目標檢測
陳路1, 2, 黃攀峰1, 2, *, 蔡佳1, 2
1. 西北工業(yè)大學 航天飛行動力學技術重點實驗室, 西安 710072 2. 西北工業(yè)大學 航天學院智能機器人研究中心, 西安 710072
傳統(tǒng)的非合作目標檢測方法大都基于一定的匹配模板,這不僅需要預先指定先驗信息,進而設計合適的檢測模板,而且同一模板只能對具有相似形狀的目標進行檢測,不易直接用于檢測形狀未知的非合作目標。為降低檢測過程中對目標形狀等先驗信息的要求,借鑒基于規(guī)范化梯度的物體區(qū)域估計方法,提出一種基于改進方向梯度直方圖特征的目標檢測方法,首先構建包含有自然圖像和目標圖像的訓練數(shù)據(jù)集;然后提取標記區(qū)域的改進方向梯度直方圖特征,以更好地保持局部特征的結構性,并根據(jù)級聯(lián)支持向量機訓練模型,從數(shù)據(jù)集中自動學習目標物體的判別特征;最后,將訓練后的模型用于檢測測試集圖像中的目標。實驗結果表明,算法在由4 953幅和100幅圖像構成的測試集中分別取得94.5% 和94.2%的檢測率,平均每幅圖像的檢測時間約為0.031 s,具有較低的時間開銷,且對目標的旋轉(zhuǎn)及光照變化具有一定的魯棒性。
非合作目標; 目標識別; 規(guī)范化梯度; 方向梯度直方圖; 局部特征
隨著航天技術的不斷發(fā)展,各國對于故障衛(wèi)星維修、近距離目標捕獲、軌道垃圾清理等新型在軌服務技術的需求日益迫切。傳統(tǒng)空間機器人的機械臂幾乎屬于全剛體系統(tǒng),加上其作用范圍受到機械臂長度和剛體靈活性的限制,因此空間機械臂主要用于合作目標的抓捕和操作,不能很好地適應未來的空間碎片清理等任務。空間繩系機器人系統(tǒng)利用柔性系繩代替多自由度剛性機械臂,在任務安全性和可靠性等方面有了顯著提高。系繩結構的應用不僅減少了平臺向目標移動過程中的能量消耗,而且避免了平臺與目標的直接接觸,從而消除了與目標直接碰撞的可能,因而在未來的空間操作中有著廣泛的應用前景。
空間繩系機器人由空間機動平臺、空間系繩和捕獲裝置3部分構成,如圖1所示。在軌捕獲過程分為3個階段:①空間平臺的繞飛階段,即空間機動平臺進行的遠程、中近距離的目標搜索和監(jiān)測過程;②空間繩系機器人捕獲目標階段,即空間機動平臺到達作用距離內(nèi)時(約200 m),操作機器人被平臺釋放,自主完成目標追蹤、識別和抓捕的過程;③空間機動平臺把目標拖入墳墓軌道的過程,即空間繩系機器人抓住目標衛(wèi)星后,空間機動平臺將目標衛(wèi)星由原軌道拖入墳墓軌道的過程[1]。
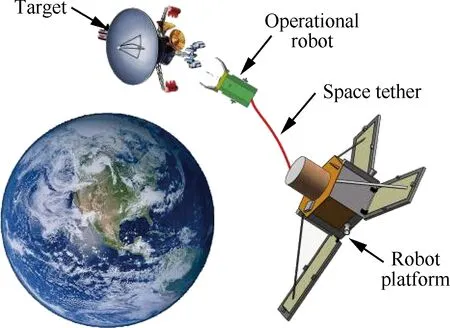
圖1 空間繩系機器人系統(tǒng)示意圖
Fig. 1 Diagram of tethered space robot system
目標特征提取是非合作目標位姿測量的基礎,在逼近非合作目標的過程中,機器人需要對目標進行識別、跟蹤并測量目標的結構、運動軌跡、空間位置和三維姿態(tài)等信息。基于視覺系統(tǒng)的空間目標檢測/識別是獲取這些信息的重要手段。
因此本文的出發(fā)點是根據(jù)目標檢測/識別算法確定目標的待抓捕區(qū)域,縮減感興趣區(qū)域的尺寸,從而為后續(xù)目標特征點等特征的提取排除背景信息的干擾。研究表明,盡管非合作目標的結構各不相同,但它們有諸多相似的部件,如用于星箭相連的分離螺栓、對接環(huán),用于連接太陽帆板與衛(wèi)星本體的太陽帆板支架等,這些非合作目標星共有的特征是機器人抓捕操作的理想部位。不失一般性,本文選取目標星本體與帆板連接處的三角形或多邊形支架作為待識別區(qū)域。
傳統(tǒng)的衛(wèi)星帆板檢測算法往往基于一定的先驗信息,并針對具有相似形狀特征的識別目標。徐文福等[2]針對三角形類衛(wèi)星帆板支架,提出基于立體視覺的目標識別算法;Wong[3]指出與空間域相比,頻率域的非合作目標識別具有更大的優(yōu)勢,更易區(qū)分不同的飛行器類別;Ramirez等[4]將遺傳算法應用于圖像中四邊形的檢測,算法對高斯噪聲污染和形變具有一定的魯棒性。文獻[5]提出一種基于彈性網(wǎng)稀疏編碼的特征袋模型,能夠較好地識別目標;文獻[6]借鑒FAST算法的空心圓環(huán)結構提出一種具有旋轉(zhuǎn)不變性的模板匹配算法,有較強的抗噪聲和抑制光照變化的能力。文獻[7]通過提出一種光照模糊相似融合不變矩,有效解決了不同位姿和光照條件的航天器目標識別問題;文獻[8]通過網(wǎng)絡參數(shù)的不斷調(diào)整,將目標的特征反映到網(wǎng)絡結構中,以實現(xiàn)對圖像目標的識別,但算法僅突出了目標特征,并未對目標的位置信息進行預測。
上述方法在所假設的目標形狀特征下,具有較好的檢測效果,但在實際中,帆板支架的結構各不相同,且帆板的旋轉(zhuǎn)角度也會隨時變化,很難找到不同條件下都能得到滿意結果的檢測模板。
本文提出一種基于改進方向梯度直方圖(Histogram of Oriented Gradient, HOG)特征的目標定位算法,首先建立含有標記信息的帆板圖像訓練集,分別提取帆板目標區(qū)域和非目標區(qū)域的特征,然后采用級聯(lián)支持向量機(Cascaded Support Vector Machine, Cascaded SVM)框架訓練特征模型,最后通過訓練模型檢測測試集圖像中的帆板支架區(qū)域。實驗結果表明,在不同視角、不同帆板旋轉(zhuǎn)角度下,文中所提算法均能夠以較低的時間開銷,高準確度定位帆板支架。
1 區(qū)域提取方法
現(xiàn)有識別算法的檢測器大都依賴于圖像的種類,即一種檢測器只能識別一類或多類相似的物體,這導致在目標檢測/識別過程中,需用不同的檢測器對同一物體進行檢測,以確定物體是否屬于特定類中的實例[9],并且采用滑窗的方式定位物體需要在不同尺度和位置下進行檢測,搜索區(qū)域較大,因此上述算法的時間復雜度較高。為降低待分類區(qū)域的數(shù)目,研究人員提出不依賴于目標種類的物體測量方法。物體度定義為圖像窗口包含有某種物體的概率,而不考慮物體的具體分類,概率越大意味著當前窗口中包含有完整物體的可能性越大。
由文獻[10-11],物體可看作圖像中具有閉合邊界的孤立元素,其與周圍背景元素的相關性較弱。傳統(tǒng)基于空間的理論認為人在觀察圖像時,注意力會從一個空間位置轉(zhuǎn)移到另一個空間位置[12],而認知學的研究表明,人類視覺更傾向于首先識別圖像中的物體,通過簡單的選擇機制初步確定潛在的物體區(qū)域,這也驗證了通過物體度確定潛在物體區(qū)域的可行性。文獻[13]提出結合圖像的形狀、顏色和紋理等特征,對物體的潛在區(qū)域進行測量,從而得到潛在區(qū)域中包含有物體的概率;文獻[14]引入級聯(lián)形式,提高了潛在區(qū)域評價的速度和精度;文獻[15]基于圖像的梯度信息,提出一種非常快速的潛在區(qū)域評價算法。
文獻[15]將標記圖像目標區(qū)域的規(guī)范化梯度(Normed Gradient, NG)作為區(qū)分物體區(qū)域和非物體區(qū)域的特征。首先選取不同尺度和方向比下的窗口{(W0,H0)},其中W0和H0分別表示窗口的尺寸,且W0,H0∈{10,20,40,80,160,320},計算其NG特征。然后采用線性模型w評價當前窗口:
(1)
式中:hl為窗口l所表示的NG特征;fl為w濾波后特征的評價值;i和(x,y)分別代表窗口l的尺寸和位置。對于尺寸i下的潛在區(qū)域,通過非極大值抑制(Non-MaximalSuppression,NMS)保留局部區(qū)域的最大響應,以達到減小搜索區(qū)域的目的。
基于以下事實:相比于由長寬方向比值較大的矩形包圍的區(qū)域,長寬比接近于1的區(qū)域中包含有物體的可能性更大,窗口區(qū)域的評價指標進一步修正為
sl=aifl+bi
(2)
式中:ai和bi分別為尺寸i下的訓練系數(shù)和偏置項;sl為窗口的最終評價值,即窗口中包含有物體的概率。
為得到圖像窗口包含物體的概率值,采用文獻[16]的級聯(lián)SVM方法訓練參數(shù):
1) 將標記區(qū)域的NG特征看作正樣本,隨機采樣非標記區(qū)域,其特征作為負樣本,利用線性SVM訓練模型w。
2) 采用線性SVM訓練參數(shù)ai、bi。對訓練集的已標記圖像,利用式(1)和式(2)生成非極大值抑制后的潛在物體區(qū)域,通過與真實標記的對比達到訓練參數(shù)的目的。
上述訓練方法具有較小的訓練時間開銷,并在PASCALVOC2007[17]數(shù)據(jù)集上取得了很好的物體定位效果,但上述算法將圖像梯度值的歐氏距離作為判別特征,如式(3)所示:
hl=min(|Gx|+|Gy|,255)
(3)
式中:Gx和Gy為窗口l對應圖像塊的梯度值。雖然梯度特征具有計算簡單、運行速度快的優(yōu)點,但卻沒有考慮圖像中廣泛存在的紋理信息,用梯度作為特征忽視了像素間及局部區(qū)域中所包含的方向信息,因此不能很好地作為目標區(qū)域的判別特征。
2 基于改進HOG特征的特征提取方法
NG特征用于VOC 2007數(shù)據(jù)集取得了較好的目標定位效果,但在實際中,尤其是對于不包含在數(shù)據(jù)集中的物體類,人工采集的圖像易受光照、噪聲等因素的影響,往往不能夠直接使用,通常要對其進行預處理,以增強圖像中的顯著特征。實驗表明,NG特征直接應用于預處理圖像其效果并不理想。
為減小衛(wèi)星載荷,衛(wèi)星帆板支架大都具有骨架型結構,支架上像素點的梯度變化方向類似,而支架與背景交界處的梯度值波動較大,其方向同支架上的梯度變化方向正交,因此在規(guī)范化梯度的基礎上,引入方向信息,不僅可以包含局部區(qū)域中的方向響應,減小因離散化梯度造成的能量丟失,而且能夠表示物體的基本形狀,從而作為一種較好地判別目標區(qū)域的特征。
2.1 方向梯度直方圖
基于如下假設:雖然無法精確地估計圖像中局部灰度值的梯度分布,但其中物體的局部外觀和形狀通常可以由對應梯度和邊緣信息很好地表征和描述,文獻[18]提出用于特征提取的方向梯度直方圖算子;文獻[19]將方向梯度直方圖算子應用于圖像/視頻行人檢測,只需行人大致保持直立狀態(tài)便可取得較好的檢測效果;文獻[20]指出HOG算子特別適合于剛體特征的表示。HOG特征是一種梯度方向的直方圖表示,與SIFT特征[21]相比,雖然HOG特征不具備尺度不變性,但其運算復雜度要低得多。首先全局歸一化圖像,減少光照等因素對物體識別的影響;然后計算圖像的梯度信息,捕獲物體的輪廓、紋理等特征,并進一步降低光照因素變化的影響;進一步,根據(jù)梯度的方向和幅值,得到各連通區(qū)域區(qū)域內(nèi)(稱為細胞)不同方向下像素分布的一維向量,為增強算子的魯棒性,對相鄰細胞組成的集合塊中的特征向量進行局部歸一化;最后,將所有集合塊的向量首尾相連,形成對當前圖像的HOG特征表示,特征提取過程如圖2所示,其中輸入圖像由數(shù)據(jù)集中圖像的標記信息獲得。

圖2 HOG特征提取流程
Fig. 2 Flowchart of extracting HOG feature
為表示輸入圖像,HOG算子需提取高維特征表示向量,其維度為
(4)
式中:w、b、c分別為檢測窗口、塊區(qū)域和細胞區(qū)域的尺寸;s為塊區(qū)域移動的步長;p為細胞內(nèi)梯度方向的數(shù)目。由于不同圖像塊之間有一定的重疊,導致特征表達向量存在一定的冗余度,定義r為生成特征表達向量中重疊部分所占比例,則有
r=
若相鄰塊之間沒有重疊部分,則定義冗余度為0。以w、b、c、s、p分別取72、16、8、8、9時為例,特征表示維度和冗余度分別為2 304和0.19,高維的特征表示給分類、檢測等問題帶來計算上的壓力,并且冗余度的存在一定程度上降低了算法的執(zhí)行效率。值得注意的是,文獻[19]中指出這種冗余特性能夠提升行人目標檢測效果,但本文試圖通過對HOG特征的改進提取具有更低維數(shù)和更適合目標和非目標區(qū)域判別的特征,因此,有必要進一步降低維數(shù)及冗余度。
2.2 改進的局部特征
HOG特征將圖像塊內(nèi)多個細胞區(qū)域的不同方向的梯度響應展開為向量,作為當前圖像塊特征的表達,不同圖像塊之間有一定的重疊,導致特征表達向量存在一定的冗余,且維數(shù)較高,這使得HOG特征應用于較大規(guī)模的數(shù)據(jù)集時不適合直接作為目標區(qū)域和非目標區(qū)域的判別特征。
本節(jié)首先以梯度方向為標準,將圖像塊內(nèi)多個細胞區(qū)域的梯度響應集中于單個細胞區(qū)域,從而獲得局部區(qū)域具有最大響應的方向,并作為當前區(qū)域的主方向;然后,對其進行極大值池化,使得子采樣后的特征具有一定的平移、旋轉(zhuǎn)不變性,進而提出一種改進的HOG特征P-HOG(Pooling-HOG)。
如圖3所示,對于輸入圖像x,首先將其放縮至72×72大小,若x的寬度和高度不相等,則改變其長寬比;然后計算每個細胞內(nèi)方向梯度的分布,如圖3(b)所示,梯度方向的分布大致刻畫了物體的形狀邊緣;為獲得更好的空間不變性,將連通區(qū)域內(nèi)的多個細胞合并,以形成更強的局部方向響應(見圖3(c));最后下采樣提取塊區(qū)域中的最大響應值,生成對應于原圖像的魯棒特征表達(見圖3(d))。此時,原圖像x由一個抽象后的8×8 的判別特征表達,特征的表示維度為64,通過下采樣操作,特征的冗余度同樣得到降低。
由于圖像的灰度值統(tǒng)計特性不同,加之容易受亮度、噪聲等外界因素的干擾,因此在對圖像進行特征提取前,通常需要對其進行預處理。文獻[18]中采用圖像元素求平方根或取對數(shù)的方法進行全局歸一化,雖然降低了光照等因素對物體識別的影響,但同時也降低了物體與背景的對比度,并且單純采用平方根法或?qū)?shù)法沒有消除圖像中存在的相關性,因此本文考慮在不影響物體主要形狀邊緣的基礎上,盡可能抑制背景區(qū)域的光照、對比度等變化,同時消除圖像元素間的相關性。

圖3 不同階段下輸入圖像的特征表示
Fig. 3 Feature representations of input image at different stages
為降低輸入圖像特征間的相關性,并在增強圖像顯著性特征的同時,有效抑制其他特征,按照如下步驟[22]對圖像進行預處理。
步驟 1RGB圖像轉(zhuǎn)為灰度圖像,并放縮至固定尺寸。
步驟 2 全局歸一化,使圖像具有均值為0、方差為1的統(tǒng)計特性:
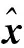
步驟3 局部歸一化,減弱非顯著性特征的影響:
式中:xi為輸入的圖像塊;mi為高斯濾波器;f(xi,mi)表示用mi對xi進行卷積濾波;yi為局部歸一化后的圖像塊。由于實際采集到的圖像不可避免地存在一定程度的噪聲,為在圖像的預處理階段減少噪聲信息的干擾,文中應用維納濾波器于局部歸一化過程,結果如圖4所示。

圖4 不同預處理方式下圖像的輸出對比
Fig. 4 Output comparison of input image with different pre-processing procedures
同只采用全局歸一化的預處理結果相比,局部歸一化后的圖像更能突出物體的特征輪廓,并可抑制背景等無關信息的干擾;應用維納濾波表現(xiàn)為對原圖像細節(jié)的模糊,尤其是當圖像中噪聲較少時,同時對圖像中邊緣等具有局部顯著性的特征加以增強。
2.3 算法流程
在基于二元規(guī)范化梯度的物體區(qū)域估計框架基礎上,引入改進的方向梯度直方圖特征描述算子,能夠保留局部區(qū)域的方向性信息,其中的池化操作為算子提供了一定的空間、旋轉(zhuǎn)不變性。此外,在提取特征之前,對圖像進行預處理操作以突出其中的顯著性元素同樣有助于提高算法的識別效果,算法流程如圖5所示。
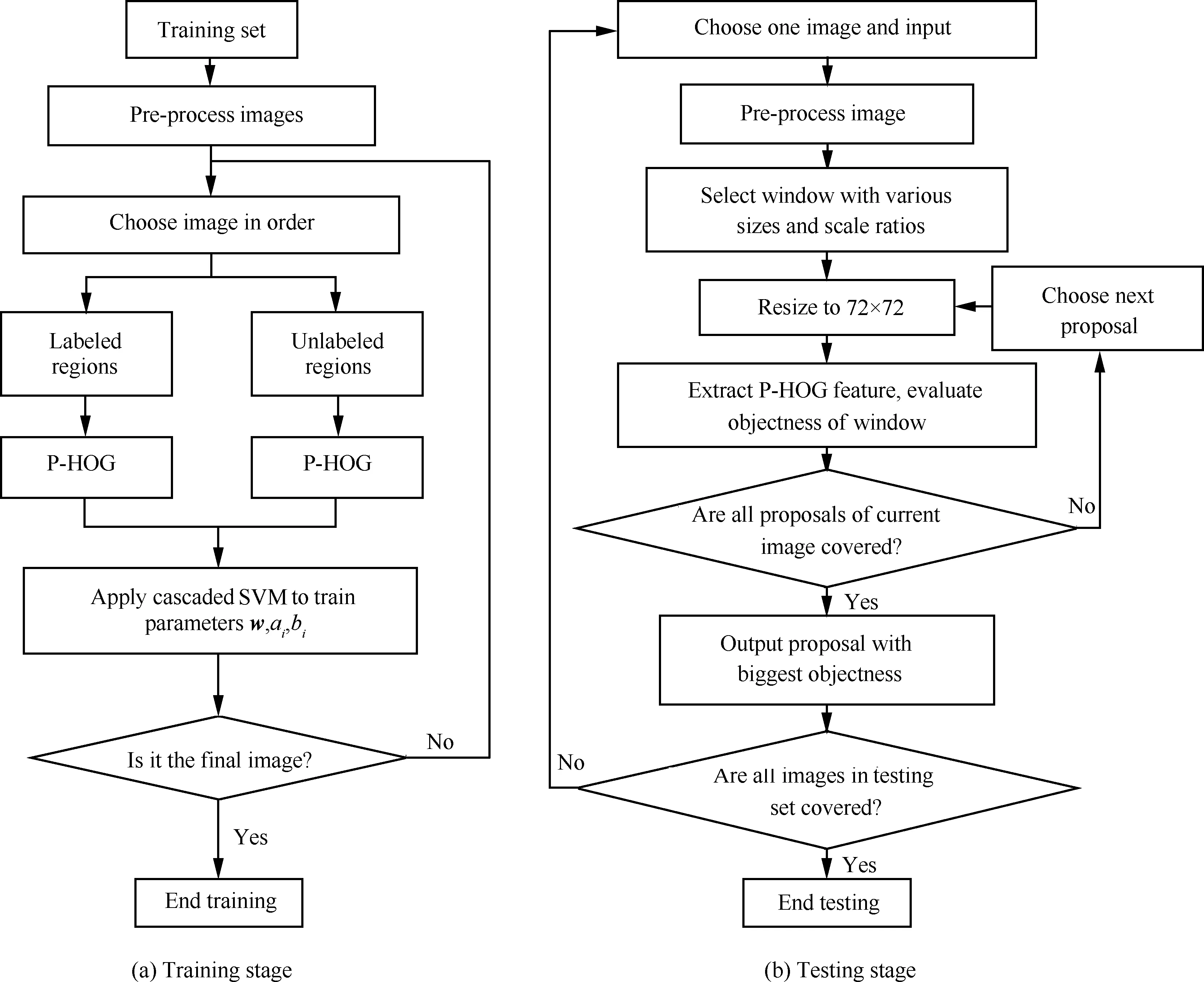
圖5 基于P-HOG的目標識別算法流程圖
Fig. 5 Flowchart of object detection algorithm based on P-HOG
3 實驗條件及結果分析
本文方法主要應用于繩系抓捕裝置接近非合作目標后的視覺測量階段,空間平臺在繞飛階段對目標的跟蹤過程并不涉及本文的討論范圍,因此圖像目標因觀測距離變化引起的差異并不大,圖像差異主要集中于目標本身,如圖6所示。
3.1 實驗條件
訓練衛(wèi)星帆板支架的識別模型依賴于大量的標記數(shù)據(jù),由于人工標記上千幅圖像的工作量較大,同時注意到Zitnick和Dollr[10]將物體定義為具有閉合邊界的孤立元素,這和帆板支架的結構形態(tài)相吻合,因此在測試集中整合其他圖像庫(如PASCALVOC2007),利用其中的自然圖像學習包括帆板支架在內(nèi)的物體基本形態(tài),利用手動采集的少量帆板支架圖像提取支架的對應特征。
為驗證算法有效性,手動采集共126幅不同形狀、角度和光照條件下的衛(wèi)星帆板圖像(見圖6(b)),并進行了人工標記。

圖6 訓練圖像集
Fig. 6 Training image set
處理單元采用CPU為IntelCorei3 3.40GHz,內(nèi)存為2G的主機,操作系統(tǒng)為WindowsXPSP3,開發(fā)工具為VS2010IDE。
3.2 結果分析
物體度被用于預先選取可能包含有物體的區(qū)域,通過增加特定目標的樣本數(shù),選取更加符合局部結構性的特征算子,將算法直接應用于目標的檢測中,其中訓練圖像集的大小為1 421,其中1 331幅自然圖像由VOC2007中隨機選取,90幅衛(wèi)星帆板圖像由手動采集得到,能夠使算法學習更多關于衛(wèi)星帆板的特征信息,有效防止欠擬合的發(fā)生。測試圖像集分成3個子測試集,測試集1由4 953幅VOC2007圖像組成,以驗證本文算法的有效性;測試集2由100幅圖像構成,包括90幅自然圖像和10幅衛(wèi)星帆板圖像;測試集3只含有10幅衛(wèi)星帆板圖像,用以驗證模型直接用于目標檢測的效果,不同測試集下的訓練結果見表1。
表1 NG特征和P-HOG特征在不同測試集下目標檢測效果的對比
Table 1 Comparison of object detection performance under different testing sets between features NG and P-HOG
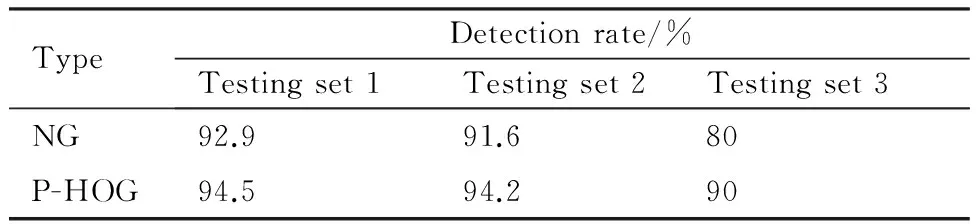
TypeDetectionrate/%Testingset1Testingset2Testingset3NG92.991.680P-HOG94.594.290
可以看出,相比于規(guī)范化梯度特征,P-HOG特征的檢測效果更好,因為預處理操作在增強圖像顯著性特征的同時,也改變了圖像中原有梯度值的分布,破壞了視覺連續(xù)性,單純采用梯度特征會產(chǎn)生更多的誤判,而P-HOG特征則能很好地保持局部區(qū)域的特性,因此其檢測效果更好。
其中,目標的檢測效果用檢測率衡量,定義為測試集中被正確檢測的圖像占測試集中圖像總數(shù)的比例,檢測率越大表示算法的檢測效果越好。如果算法對目標的預測區(qū)域與已標記的實際區(qū)域之間的交集部分超過其并集的50%,圖像可以被認為是正確檢測的。圖7(a)所示的衛(wèi)星帆板支架得到正確檢測,而圖7(b)中由于預測窗口與實際區(qū)域未相交(NG)或重疊區(qū)域比例過低(P-HOG),故判定為檢測錯誤。

圖7 NG特征和P-HOG特征對衛(wèi)星帆板支架的正確及錯誤檢測結果
Fig. 7 Correct and incorrect detection results by features NG and P-HOG of satellite panels stents
進一步,表2給出了不同特征下每幅圖像的平均訓練和測試時間對比,由于規(guī)范化梯度的判別特征計算簡單,因此其時間開銷很低。而P-HOG特征雖然能夠有效地保持局部信息,但不可避免地提高了計算復雜度,其平均訓練時間為0.046 s(為NG特征的2.421倍),預測時間為0.031 s(為NG特征的2.385倍)。雖然算法運行時間低于NG特征,但相對于基于模板匹配的檢測算法仍然具有優(yōu)勢。
表2 NG特征和P-HOG特征下每幅圖像的平均訓練、預測時間開銷對比
Table 2 Comparison of average training and testing time per image between features NG and P-HOG
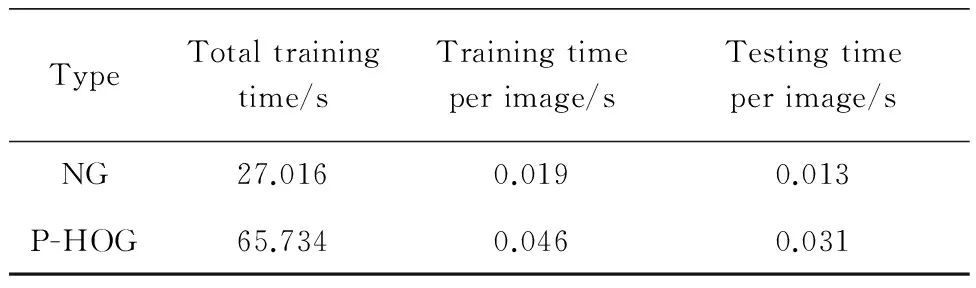
TypeTotaltrainingtime/sTrainingtimeperimage/sTestingtimeperimage/sNG27.0160.0190.013P-HOG65.7340.0460.031
圖8給出了規(guī)范化梯度特征和P-HOG特征對衛(wèi)星帆板支架的檢測結果對比,不難看出兩種方法都能夠正確檢測大部分的圖像,但后者由于利用了更多的結構性信息,因此其預測窗口更接近于實際的標記區(qū)域。
特別地,圖8反映了本文算法能夠適應一定視角差異下的目標檢測任務。算法將帆板支架看作具有閉合邊界的元素,這一性質(zhì)是不隨著視角的改變而變化的,因此算法可以適應目標視角的變化。此外,構建的訓練集中已經(jīng)包含目標在不同視角下的圖像,進一步保證了訓練后的模型能夠?qū)W習到不同角度下目標的判別特征。
圖9給出了算法在不同光照條件下對目標的檢測結果,結果表明算法在不同光照條件下均能正確檢測目標,對光照影響有一定的魯棒性。
值得注意的是,雖然檢測算法能夠適應不同的光照環(huán)境,但實際的在軌服務,尤其是交會對接任務一般都在太陽入射角恒定的情況下開展。因此檢測過程中因光照引起的圖像差異并不大。



圖8 NG特征和P-HOG特征對衛(wèi)星帆板支架的檢測結果對比
Fig. 8 Detection results comparison of bracket images by features NG and P-HOG of satellite panels stents
圖9 本文算法在不同光照條件下的檢測結果
Fig. 9 Detection performances of the proposed method under different luminance
從局部來看,除灰度值較大外,圖像中的光亮部分與其余部分并無實質(zhì)的不同,局部歸一化后僅有部分亮光邊緣得以保留,大部分的光亮部分作為非顯著性特征被抑制。而保留的邊緣一般非閉合,且形態(tài)特征與目標支架差異較大,因此并不會對目標的檢測造成過多干擾。
4 結 論
1) 利用局部歸一化方法在突出圖像局部顯著性特征上的優(yōu)勢,結合維納濾波,對數(shù)據(jù)集圖像進行預處理,減弱了圖像中光照、噪聲等外界因素對檢測過程的影響,并進一步增強物體的邊緣。
2) 利用級聯(lián)SVM能夠從數(shù)據(jù)集中學習目標判別特征和HOG特征適用于剛性物體檢測的特點,提出一種改進的HOG特征算子,可以有效地保持圖像的局部信息,從而保證目標檢測的精度。
3) 通過對標準圖像集的檢測實驗,驗證了算法對物體檢測精度的提升;通過對包含衛(wèi)星帆板支架的圖像應用模型,驗證了算法能夠適應目標形狀和尺度的變化,并對光照條件和旋轉(zhuǎn)具有一定的魯棒性。相比于NG特征,算法的檢測結果更接近于實際標記;同基于模板的檢測方法比,算法的時間效率更高。
4) 進一步,本文算法假定測試圖像中一定含有目標物體,因此模型只考慮目標的檢測定位問題,但實際的場景更為復雜,測試圖像中可能并不包含所檢測的目標物體,此時對圖像進行目標檢測是沒有意義的。因此未來工作考慮引入圖像物體的分類過程,通過分類模型首先判斷圖像中是否包含待檢測的目標類型,以提高模型的自適應性。
[1] HUANG P F, CAI J, MENG Z J, et al. Novel method of monocular real-time feature point tracking for tethered space robots[J]. Journal of Aerospace Engineering, 2014, 27(6): 04014039.
[2] 徐文福, 梁斌, 李成, 等. 空間機器人捕獲非合作目標的測量與規(guī)劃方法[J]. 機器人, 2010, 32(1): 61-69. XU W F, LIANG B, LI C, et al. Measurement and planning approach of space robot for capturing non-cooperative target[J]. Robot, 2010, 32(1): 61-69 (in Chinese).
[3] WONG S K. Non-cooperative target recognition in the frequency domain[J]. IEE Proceedings-Radar, Sonar and Navigation, 2004, 151(2): 77-84.
[4] RAMIREZ V A, GUTIERREZ S A M, YANEZ R E S. Quadrilateral detection using genetic algorithms[J]. Computacióny Sistemas, 2011, 15(2): 181-193 .
[5] 史駿, 姜志國, 馮昊, 等. 基于彈性網(wǎng)稀疏編碼的空間目標識別[J]. 航空學報, 2013, 34(5): 1129-1139. SHI J, JIANG Z G, FENG H, et al. Elastic net sparse coding-based space object recognition[J]. Acta Aeronautica et Astronautica Sinica, 2013, 34(5): 1129-1139 (in Chinese).
[6] CAI J, HUANG P F, WANG D K. Novel dynamic template matching of visual servoing for tethered space robot[C]//2014 4th IEEE International Conference on Information Science and Technology (ICIST). Piscataway, NJ: IEEE Press, 2014: 389-392.
[7] 徐貴力, 徐靜, 王彪, 等. 基于光照模糊相似融合不變矩的航天器目標識別[J]. 航空學報, 2014, 35(3): 857-867. XU G L, XU J, WANG B, et al. CIBA moment invariants and their use in spacecraft recognition algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2014, 35(3): 857-867 (in Chinese).
[8] 李予蜀, 余農(nóng), 吳常泳, 等. 紅外航空圖像自動目標識別的形態(tài)濾波神經(jīng)網(wǎng)絡算法[J]. 航空學報, 2002, 23(4): 368-372. LI Y S, YU N, WU C Y, et al. Morphological neural networks with applications to automatic target recognition in aeronautics infrared image[J]. Acta Aeronautica et Astronautica Sinica, 2002, 23(4): 368-372 (in Chinese).
[9] 黃凱奇, 任偉強, 譚鐵牛. 圖像物體分類與檢測算法綜述[J]. 計算機學報, 2014, 36(6): 1225-1240. HUANG K Q, REN W Q, TAN T N. A review on image classification and detection[J]. Chines Journal of Computers, 2014, 36(6): 1225-1240 (in Chinese).
[10] ZITNICK C L, DOLLR P. Edgebox: Locating object proposals from edges[C]//Computer vision-ECCV 2014. Zurich: Springer International Publishing, 2014: 391-405.
[11] HEITZ G, KOLLER D. Learning spatial context: Using stuff to find things[C]//Computer vision-ECCV 2008. Marseille: Springer, 2008: 30-43.
[12] YANULEVSKAYA V, UIJLINGS J, GEUSEBROEK J M. Salient object detection: From pixels to segments[J]. Image and Vision Computing, 2013, 31(1): 31-42.
[13] ALEXE B, DESELAERS T, FERRARI V. Measuring the objectness of image windows[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2189-2202.
[14] RAHTU E, KANNALA J, BLASCHKO M. Learning a category independent object detection cascade[C]//2011 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE Press, 2011: 1052-1059.
[15] CHENG M M, ZHANG Z M, LIN W Y, et al. BING: Binarized normed gradients for objectness estimation at 300fps[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE Press, 2014.
[16] ZHANG Z, WARRELL J, TORR P H S. Proposal generation for object detection using cascaded ranking SVMs[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE Press, 2011: 1497-1504.
[17] EVERINGHAM M, GOOL L V, WILLIAMS C K I, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[18] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2005, 1: 886-893.
[19] DALAL N. Finding people in images and videos[D]. Grenoble: Institut National Polytechnique de Grenoble-INPG, 2006: 33-50.
[20] UIJLINGS J, VAN DE SANDE K E A, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171.
[21] LOWE D G. Object recognition from local scale-invariant features[C]//Proceedings of the Seventh IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 1999, 2: 1150-1157.
[22] JARRETT K, KAVUKCUOGLU K, RANZATO M, et al. What is the best multi-stage architecture for object recognition?[C]//2009 IEEE 12th International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2009: 2146-2153.
陳路 男, 博士研究生。主要研究方向: 目標檢測與識別, 計算機視覺, 機器學習。
Tel: 029-88460366-803
E-mail: chenlu11@mail.nwpu.edu.cn
黃攀峰 男, 博士, 教授, 博士生導師。主要研究方向: 空間機器人學, 空間遙操作, 導航、制導與控制。
Tel: 029-88460366-801
E-mail: pfhuang@nwpu.edu.cn
蔡佳 男, 博士研究生。主要研究方向: 非合作目標檢測, 跟蹤與相對位姿測量, 視覺導航。
Tel: 029-88460366-803
E-mail: caijia@mail.nwpu.edu.cn
Received: 2015-01-04; Revised: 2015-02-07; Accepted: 2015-03-11; Published online: 2015-03-18 14:16
URL: www.cnki.net/kcms/detail/11.1929.V.20150318.1416.002.html
Foundation items: National Natural Science Foundation of China (11272256, 61005062)
*Corresponding author. Tel.: 029-88460366-801 E-mail: pfhuang@nwpu.edu.cn
Space non-cooperative target detection based on improved features of histogram of oriented gradient
CHEN Lu1, 2, HUANG Panfeng1, 2, *, CAI Jia1, 2
1.NationalKeyLaboratoryofAerospaceFlightDynamics,NorthwesternPolytechnicalUniversity,Xi′an710072,China2.ResearchCenterforIntelligentRobotics,NorthwesternPolytechnicalUniversity,Xi′an710072,China
Traditional non-cooperative target detection methods are mostly based on different matching templates which are well-designed with additional prior information. Moreover, one single template can be merely used to detect objects with similar shapes and structures, causing low applicability in detecting non-cooperative targets whose prior information are usually unknown. In order to solve those problems and inspired by the object estimation technique based on normed gradient, an object detection algorithm using improved features of histogram of oriented gradient is proposed. A training data set composed of natural images and target images is first built manually. Secondly, we extract the modified HOG information in the labeled regions to preserve detailed structures of the local features. Then, the cascaded support vector machine is used to train the model autonomously, which does not require prior information. Finally, we design several tests using the trained model to detect targets from the testing images. Numerous experiments demonstrate that the detection rates of the proposed method are 94.5% and 94.2% respectively when applied to testing sets with 4 953 and 100 images. The time consumption of extracting one image is about 0.031 s while it is robust to object rotation and illumination under certain condition.
non-cooperative target; object detection; normed gradient; histogram of oriented gradient; local feature
2015-01-04; 退修日期: 2015-02-07; 錄用日期: 2015-03-11; < class="emphasis_bold">網(wǎng)絡出版時間:
時間: 2015-03-18 14:16
www.cnki.net/kcms/detail/11.1929.V.20150318.1416.002.html
國家自然科學基金 (11272256, 61005062)
.Tel.: 029-88460366-801 E-mail: pfhuang@nwpu.edu.cn
陳路, 黃攀峰, 蔡佳. 基于改進HOG特征的空間非合作目標檢測[J]. 航空學報, 2016, 37(2): 717-726. CHEN L, HUANG P F, CAI J. Space non-cooperative target detection based on improved features of histogram of oriented gradient[J]. Acta Aeronautica et Astronautica Sinica, 2016, 37(2): 717-726.
http://hkxb.buaa.edu.cn hkxb@buaa.edu.cn
10.7527/S1000-6893.2015.0072
V412.4+1; TP301.6
: A
: 1000-6893(2016)02-0717-10
*
猜你喜歡
保健醫(yī)苑(2022年5期)2022-06-10 07:46:12
小哥白尼(趣味科學)(2021年8期)2021-11-20 06:08:04
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
模具制造(2019年3期)2019-06-06 02:10:54
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
航天器工程(2014年5期)2014-03-11 16:35:55
