融合直推式學習和語義理解的詞語傾向性識別
2016-02-23 06:31:42趙君喆焦翠珍戴文華
計算機技術與發(fā)展 2016年1期
聞 彬,饒 彬,趙君喆,焦翠珍,戴文華
(湖北科技學院 計算機科學與技術學院,湖北 咸寧 437100)
融合直推式學習和語義理解的詞語傾向性識別
聞 彬,饒 彬,趙君喆,焦翠珍,戴文華
(湖北科技學院 計算機科學與技術學院,湖北 咸寧 437100)
目前詞語情感傾向性識別研究主要分為機器學習和語義理解,機器學習不能很好地識別通用領域詞語,語義理解又存在準確率和召回率不夠高的問題,因此文中提出了一種融合直推式學習和語義理解的詞語傾向性識別方法。首先對HowNet知識庫體系進行改進,在已有的四種義原的基礎上,提出第五義原—情感義原;然后將第五義原手工融入到HowNet知識庫中,再在此基礎上提出詞語情感相似度計算方法計算詞語的情感值;最后將該方法融合直推式學習以判定詞語情感傾向性。通過實驗結(jié)果表明,與支持向量機和原語義理解方法相比,該方法在識別情感詞上取得了較好的效果。
詞語傾向性識別;機器學習;語義理解;意見挖掘;情感義原;HowNet
1 概 述
由于越來越多用戶樂于在互聯(lián)網(wǎng)上分享自己的觀點和意見,使得互聯(lián)網(wǎng)中這類信息迅速膨脹,僅靠傳統(tǒng)的人工方法難以有效及時地獲取網(wǎng)上的海量信息,更難以提供準確的分析和處理,因此,迫切需要相關的自然語言處理技術來處理這些相關的評價信息。意見挖掘技術在此背景下應運而生,并引起了廣泛的關注。
意見挖掘的目的是發(fā)現(xiàn)文本中作者所持有的主觀態(tài)度,為產(chǎn)品推薦、輿情監(jiān)控和觀點抽取等提供支持。現(xiàn)有的意見挖掘技術主要分為基于語義理解的和基于機器學習的。其中基于機器學習的方法典型的有:樸素貝葉斯(Na?ve Bayes,NB)、支持向量機(Support Vector Machine,SVM)、最大信息熵(Maximum Entropy,ME)等。
機器學習方法在處理特定領域語料時有著較高的準確率,但是分類器設計復雜,訓練語料標注工作繁瑣,同時,當涉及到通用語料時,機器學習往往不能得到較好的效果。而基于語義理解的方法則可以解決這類問題。語義理解的方法從情感詞出發(fā),構建文本的情感模型,從而判斷出文本的情感傾向性,因此,如何識別情感詞是語義理解方法的核心。
目前國內(nèi)外研究詞語傾向性的方法主要分為兩種—基于統(tǒng)計學的方法和基于語義理解的方法。基于統(tǒng)計學的方法主要是利用機器學習來獲取詞語的情感傾向性。
在英文方面,Hatzivassiloglou和McKeown[1]使用監(jiān)督學習的方法對詞語進行情感語義傾向性判別;Turney等[2]利用點互信息(PMI-IR)方法搜索引擎的“NEAR”操作來計算待定詞與具有強烈傾向性的種子詞集合的關聯(lián)程度;Yu等[3]挑選出若干極性較強的形容詞(情感詞)構建一個種子詞集合,通過計算新詞和種子詞的共現(xiàn)概率來判斷新詞的語義傾向性。在文本情感分類方面,Pang等[4]利用人工標注語料,分別使用樸素貝葉斯、最大熵和支持向量機三種分類模型對影視文本進行分類,Sinno Jialin Pan[5]、Xavier Glorot[6]和Blitzer[7]等眾多學者利用領域適應算法分析文本的情感傾向性;Wan[8]利用已有的英文情感語料庫完成中文文本的情感分類。基于語義理解的方法主要有基于現(xiàn)存的本體知識庫,例如中文的HowNet和英文的Wordnet。在英文處理方面,Jaap等[9]利用WordNet的同義詞關系確定形容詞的褒貶;Baccianella等[10]基于WordNet構建了認可度最高的SentiWordNet;Maks和Vossen[11]基于詞典模型進行情感分析和意見挖掘;在中文處理方面,具有代表性的是朱嫣嵐等[12]采用基于HowNet的語義相似度和語義相關場兩種方法計算詞語的傾向性。同時國內(nèi)很多學者[13-14]研究建立情感詞典來處理觀點挖掘等問題,但是到目前為止還沒有一部權威的情感詞典可供借鑒。
因此文中首先在HowNet知識庫定義的四個義原的基礎上,人工添加HowNet第五義原—情感義原[15],然后利用改進的HowNet知識庫計算詞語之間的情感相似度,再融合直推式學習判定情感詞極性。
2 融合直推式學習和語義理解的詞語傾向性識別
2.1 基于HowNet的情感詞判別方法
HowNet語義相似度的方法反映詞語語義的相似程度,也即兩個詞語在不同上下文環(huán)境中在詞語替換的情況下不改變文本句法語義結(jié)構的程度。因此,利用詞語的語義相似度概念計算詞語的情感值。
HowNet中若詞語有多種表達含義,則詞語有多個義項,每個義項又由多個義原組成。那么詞語的語義相似度計算實際上是義原的相似度計算[16]。
對于兩個詞語Word1和Word2,假設詞語Word1有n個義項Y1,Y2,…,Yn,詞語Word2有l(wèi)個義項Z1,Z2,…,Zl,則詞語的相似度計算如式(1)所示:
(1)
將詞語相似度的計算轉(zhuǎn)換成概念之間的相似度計算。
2.2 HowNet義原相似度計算
在HowNet中用義原表示詞語概念,所以概念相似度計算就是義原相似度計算。
由于所有義原構成了一個樹狀義原層次體系,因此可以使用公式(2)計算兩個義原p1,p2之間的語義距離。
(2)
其中,d是p1和p2在樹狀義原層次體系中的路徑距離;α是一個可調(diào)節(jié)的參數(shù)。
2.3 概念情感相似度計算
在HowNet知識庫中概念分成四個義原:“第一基本義原”、“其他基本義原”、“關系義原”和“符號義原”。但是HowNet中的這四種義原的相似度計算沒有考慮詞語的情感語義。詞語概念S1,S2之間的相似度計算如式(3)所示。
(3)
文中在計算情感相似度時引入了情感義原作為詞語概念的第五義原,并人工挑選HowNet中的情感詞加入第五義原:“desired/良”、“undesired/莠”。

(4)

(5)
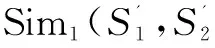
2.4 基于概念情感相似度的詞語情感語義值
計算出詞語概念情感相似度之后,結(jié)合訓練集對測試集中的詞語計算情感值。計算方法如式(6)。
(6)
其中,Sentiment(word)表示測試集中詞語word的情感值;Sim(word,Set_Pi)表示詞語word與褒義訓練集Set_Pi的相似性;Sim(word,Set_Nj)表示詞語word與貶義訓練集Set_Nj的相似性。
2.5 直推式學習
通過上面的基于HowNet的情感詞計算方法,可以得到每個詞語的情感值。文獻[15]中實驗證明,該方法可以取得較好的實驗效果,因此在此方法的基礎上進行進一步研究,將直推式方法融入其中。將每次判定出來的情感詞加入到訓練集中,如果判定該詞語為褒義情感詞,則加入到褒義測試集中;如果判定為貶義情感詞,則加入到貶義訓練集中;若屬于中性詞,則放回待測測試集中。然后用新的訓練集和測試集重復該工作,直到所有詞的極性不再改變?yōu)橹梗@而易見,該過程必然是收斂的,直推式算法詳細過程如下所示。
Step1:建立訓練集和測試集;
Step2:對測試詞集利用文中提出的方法計算詞語情感值,并判定詞語的情感傾向性;
Step3:若待判定詞語判定為正面情感詞,則從測試集中移動到正面訓練集中;若為負面情感詞,則從測試集移動到負面訓練集中;若為中性詞,則將該詞放回測試集中等待下一次判定;
Step4:重復Step2-3直到測試集和訓練集中的詞語不再改變。
3 實驗結(jié)果及分析
首先構造出初始訓練集和測試集。為了達到更好的實驗效果,盡量選擇極性較強的中文詞語作為訓練集,具體訓練集組成如表1所示,其中褒義貶義各包含20個情感詞。

表1 訓練集
為了能夠達到較好的通用性,文中從新浪、網(wǎng)易、百度三大平臺下載新聞語料12 854篇,然后利用中科院分詞工具ICTCLAS對文本進行分詞處理;再根據(jù)停用詞表刪除停用詞;由于詞語中只有名詞、形容詞和動詞才存在情感,因此抽取出所有的名詞、形容詞和動詞,最后進行人工調(diào)整得到測試集詞語共6 961個,其中褒義情感詞1 989,貶義情感詞2 056,中性詞2 916。
對于知網(wǎng)知識庫中的詞語,人工標注“desired/良”和“undesired/莠”,標注數(shù)據(jù)如表2所示。
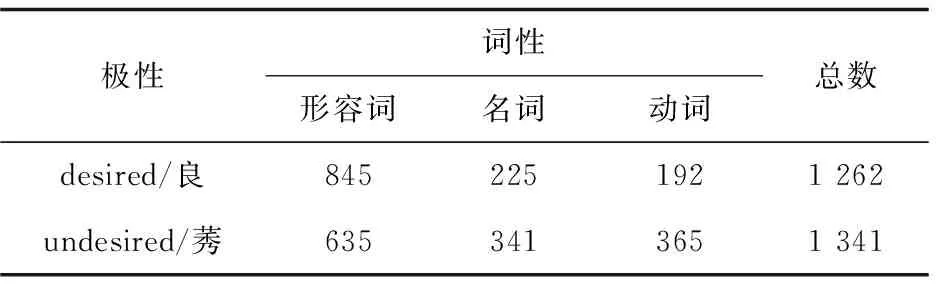
表2 良莠標注情況
對于2.3中的參數(shù),文獻[15]中對θ1,θ2設置進行了實驗,并根據(jù)實驗結(jié)果發(fā)現(xiàn)當設置為0.7和0.3時可以達到最好的實驗效果。在HowNet中對參數(shù)β1,β2,β3,β4分別設置為:0.5,0.3,0.15,0.05。對2.4中的計算詞語情感值的閾值,文獻[15]也進行了講解,并將其設置如式(7)所示。

(7)
實驗利用三種方法進行驗證:支持向量機(SupportVectorMachine,SVM)、原語義理解方法(SemanticComprehension,SC)以及融合直推式學習和語義理解(TransductiveLearning&SemanticComprehension,TL&SC)。利用準確率(Precision)、召回率(Recall)和F(F-measure)值作為判定準則。其中SVM方法中將褒義詞、貶義詞和中性詞平均分成三部分,然后以其中一部分作為訓練集,另外兩部分作為測試集,依次替換三部分角色。基于篇幅限制,表3列出的SVM結(jié)果是循環(huán)三次后所取得的平均值。SC和TL&SC方法的實驗結(jié)果見表4和表5。

表3 SVM實驗結(jié)果
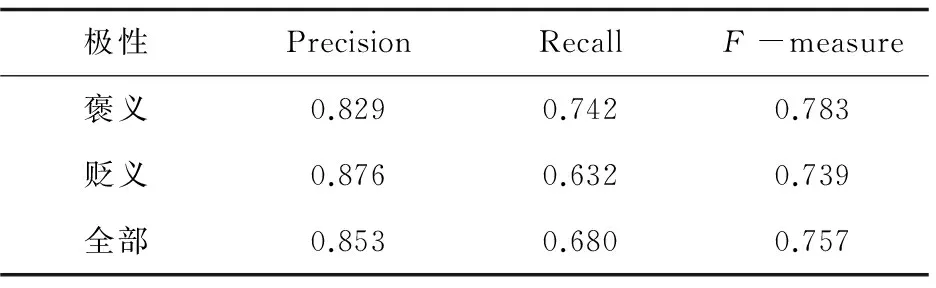
表4 SC實驗結(jié)果

表5 TL&SC實驗結(jié)果
三個實驗數(shù)據(jù)對比如圖1所示。
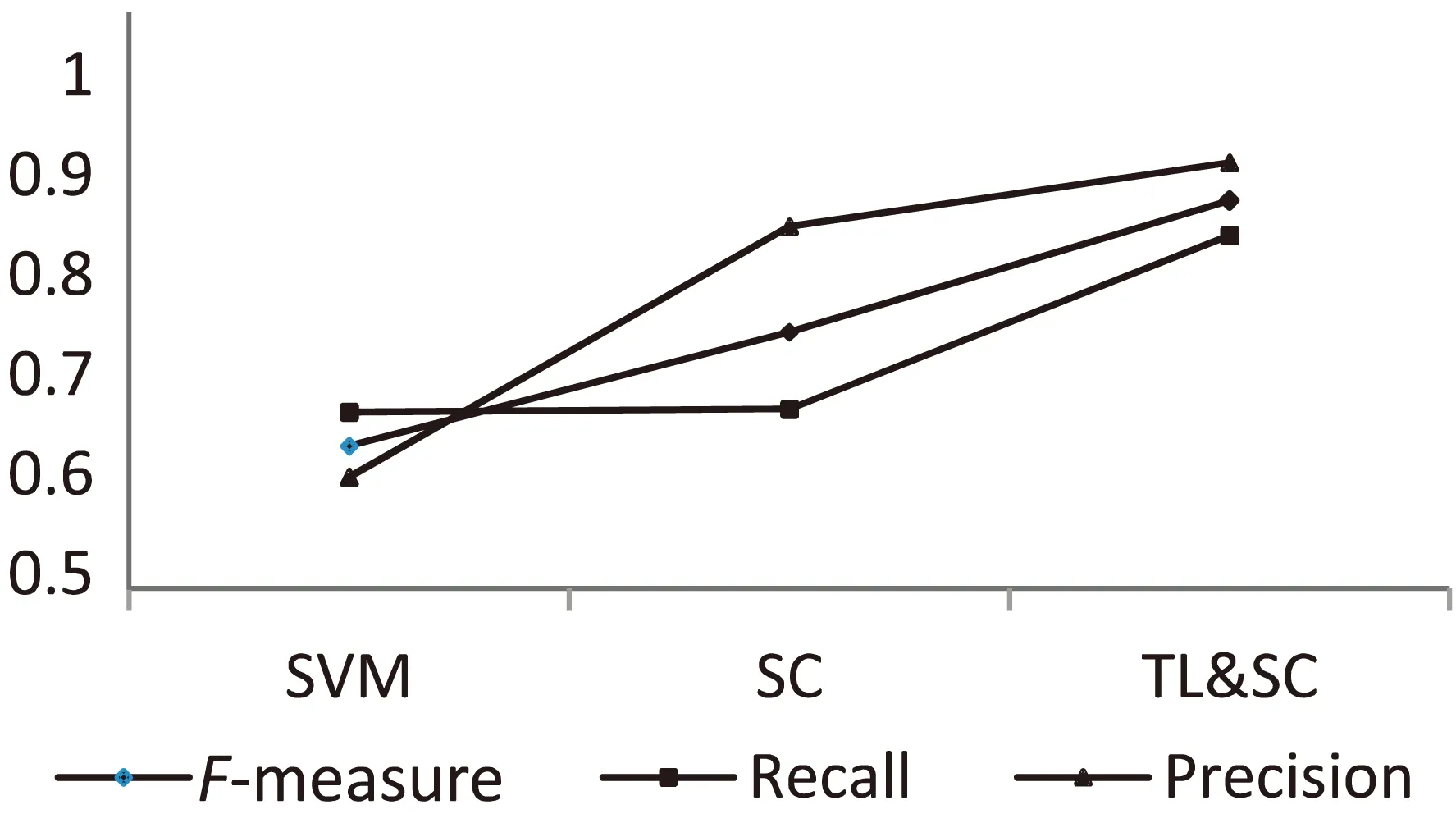
圖1 三種方法結(jié)果比較
從圖中可以很容易看出,在處理通用文本時,SVM方法得分都不是很高;當使用文中提出的SC方法時,準確率有明顯提升,但是不足的是召回率不能達到較高效果;最后使用TL&SC時,可以看到,不管是準確率、召回率還是F值,相對于其他兩種方法,都達到了較為理想的效果。
4 結(jié)束語
文中所提方法利用了HowNet知識庫計算詞語的情感相似度,然后根據(jù)計算得到的詞語情感值結(jié)合閾值來判斷詞語的情感傾向性,再將該方法融入直推式學習中。文中針對支持向量機、原語義理解方法和融合語義理解和直推式學習三種方法分別進行了實驗,結(jié)果表明,針對通用領域獲取的詞語,第三種方法不論在準確率、召回率還是在F值上都有明顯的性能提升。
當然,文中方法也存在不足之處:由于針對單個詞語判定情感傾向性,這樣勢必忽略了特定語義環(huán)境下詞語的情感傾向性,如何獲取這些情感詞是未來的研究方向之一;同時文中利用ICTCLAS進行分詞、詞性標注處理,這樣會忽略掉許多網(wǎng)絡(非常態(tài))用語,而這些網(wǎng)絡用語卻表達了極強的極性,如果能結(jié)合網(wǎng)絡環(huán)境判定出這些詞語也是未來的重要研究方向。
[1]HatzivassiloglouV,McKeownKR.Predictingthesemanticorientationofadjectives[C]//Proceedingsofthe35thannualmeetingofassociationforcomputationallinguisticsandthe8thconferenceoftheEuropeanchapteroftheACL.[s.l.]:[s.n.],1997:174-181.
[2]PeterT,MichaelL.Measuringpraiseandcriticism:inferenceofsemanticorientationfromassociation[J].ACMTransactionsonInformationSystems,2003,21(4):315-346.
[3]YuHong,HatzivassiloglouV.Towardsansweringopinionqu-estions:separatingfactsfromopinionsandidentifyingthepo-
larityofopinionsentences[C]//ProcofEMNLP-03.Sapporo,Japan:[s.n.],2003:129-136.
[4]PangBo,LeeL,VaithyanathanS.Thumbsup?Sentimentclassificationusingmachinelearningtechniques[C]//Proceedingsofthe2002conferenceonempiricalmethodsinnaturallanguageprocessing.Philadelphia:AssociationforComputationLinguistics,2002:79-86.
[5]PanSJ,NiXiaochuan,SunJiantao,etal.Cross-domainsentimentclassificationviaspectralfeaturealignment[C]//Proceedingsofthe19thinternationalconferenceonWorldWideWeb.[s.l.]:[s.n.],2010:751-760.
[6]GlorotX,BordesA,BengioY.Domainadaptationforlarge-scalesentimentclassification:adeeplearningapproach[C]//Procof28thinternationalconferenceonmachinelearning.Bellevue,WA,USA:[s.n.],2011.
[7]BlitzerJ,DredzeM,PereiraF.Biographies,bollywood,boomboxesandblenders:domainadaptationforsentimentclassification[C]//ProcofACL.[s.l.]:[s.n.],2007:187-205.
[8]WanXiaojun.Co-trainingforcross-lingualsentimentclassification[C]//Proceedingsofthe47thannualmeetingoftheACLandthe4thIJCNLPoftheAFNLP.[s.l.]:[s.n.],2009:235-243.
[9]KampsJ,MarxM,MokkenRJ,etal.UsingWordNettomeasuresemanticorientationofadjectives[C]//Proceedingsofthe4thinternationalconferenceonlanguageresourcesandevaluation.Lisbon,Portugal:[s.n.],2004:1115-1118.
[10]BaccianellaS,EsuliA,SebastianiF.SentiWordNet3.0:anenhancedlexicalresourceforsentimentanalysisandopinionmining[C]//Proceedingsofthe7thconferenceoninternationallanguageresourcesandevaluation.Valletta,Malta:[s.n.],2010:2200-2204.
[11]MaksI,VossenP.Alexiconmodelfordeepsentimentanalysisandopinionminingapplications[J].DecisionSupportSystems,2012,53(4):680-688.
[12] 朱嫣嵐,閔 錦,周雅倩,等.基于HowNet的詞匯語義傾向計算[J].中文信息學報,2006,20(1):14-20.
[13] 徐琳宏,林鴻飛,楊志豪.基于語義理解的文本傾向性識別機制[J].中文信息學報,2007,21(1):96-100.
[14]WenBin,DaiWenhua,ZhaoJunzhe.Sentencesentimentalclassificationbasedonsemanticcomprehension[C]//Procoffifthinternationalsymposiumoncomputationalintelligenceanddesign.[s.l.]:[s.n.],2012:458-461.
[15] 聞 彬,何婷婷,羅 樂,等.基于語義理解的文本情感分類方法研究[J].計算機科學,2010,37(6):261-264.
[16] 劉 群,李素建.基于《知網(wǎng)》的詞匯語義相似度的計算[C]//第三屆漢語詞匯語義學研討會.臺北:出版者不詳,2002.
Identifying of Word Sentiment Orientation of Transductive Learning and Semantic Comprehension
WEN Bin,RAO Bin,ZHAO Jun-zhe,JIAO Cui-zhen,DAI Wen-hua
(College of Computer Science and Technology,Hubei University of Science and Technology,Xianning 437100,China)
At present,the research on word sentiment orientation identification is mainly divided into machine learning and semantic comprehension,but machine learning cannot handle general field words effectively,semantic comprehension also cannot get high scores at precision and recall,therefore,a new fusion method between transductive learning and semantic comprehension for judging word polarity was put forward in this paper.Firstly the HowNet knowledge base system is improved,on the basis of four primitive,the fifth primitive—sentimental primitive was proposed,which was integrated into HowNet manually,on the basis of this,then a new word sentimental similarity calculation method was proposed to compute word’s sentimental value.At last,combine this way with transductive learning for identifying word’s sentimental orientation.The performance of experiment shows that compared with SVM or traditional semantic comprehension,it can get better results.
word sentiment orientation;machine learning;semantic comprehension;opinion mining;sentimental primitive;HowNet
2015-04-20
2015-07-22
時間:2016-01-04
國家自然科學基金面上項目(61373108);湖北省教育廳科研項目(Q20112809,B20082803);湖北省教育廳人文社會科學研究項目(13g389)
聞 彬(1982-),男,講師,碩士,研究方向為自然語言處理、機器學習。
http://www.cnki.net/kcms/detail/61.1450.TP.20160104.1453.016.html
TP391.1
A
1673-629X(2016)01-0074-04
10.3969/j.issn.1673-629X.2016.01.015
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
開放教育研究(2020年2期)2020-03-31 01:54:14
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
