一種任意維空域最小二乘算法的硬件實現(xiàn)方法
2016-01-21 02:10:03幸璐璐
通信技術(shù) 2015年6期
關(guān)鍵詞:實現(xiàn)
幸璐璐
(成都天奧信息科技有限公司,四川 成都 610000)
摘 要:在自適應(yīng)濾波算法中,空域遞推最小二乘(RLS)算法以其較快的收斂速度以及能計算出精確的最佳濾波器系數(shù)等優(yōu)勢得到了廣泛的運用。但是由于該算法較為復(fù)雜,計算量大,因此硬件實現(xiàn)時耗費資源多,難度大。提出了一種任意維空域遞推最小二乘算法的FPGA(現(xiàn)場可編程門陣列)實現(xiàn)的方法,該方法可以在硬件結(jié)構(gòu)中使用較少的乘法器和寄存器進行任意維空域遞推最小二乘運算,從而解決維數(shù)變多后資源不夠用的問題。
關(guān)鍵詞:最小二乘;現(xiàn)場可編程門陣列;實現(xiàn)
doi:10.3969/j.issn.1002-0802.2015.06.023
一種任意維空域最小二乘算法的硬件實現(xiàn)方法
幸璐璐
(成都天奧信息科技有限公司,四川 成都 610000)
摘要:在自適應(yīng)濾波算法中,空域遞推最小二乘(RLS)算法以其較快的收斂速度以及能計算出精確的最佳濾波器系數(shù)等優(yōu)勢得到了廣泛的運用。但是由于該算法較為復(fù)雜,計算量大,因此硬件實現(xiàn)時耗費資源多,難度大。提出了一種任意維空域遞推最小二乘算法的FPGA(現(xiàn)場可編程門陣列)實現(xiàn)的方法,該方法可以在硬件結(jié)構(gòu)中使用較少的乘法器和寄存器進行任意維空域遞推最小二乘運算,從而解決維數(shù)變多后資源不夠用的問題。
關(guān)鍵詞:最小二乘;現(xiàn)場可編程門陣列;實現(xiàn)
doi:10.3969/j.issn.1002-0802.2015.06.023
收稿日期:2015-01-16;修回日期:2015-04-29Received date:2015-01-16;Revised date:2015-04-29
中圖分類號:TN957
文獻標(biāo)志碼:碼:A
文章編號:號:1002-0802(2015)06-0746-04
Abstract:Among all the adaptive filtering algorithms, RLS is widely applied for its fast convergence rate and precise calculation of the filter coefficients. However, due to its complexity and large computation, the hardware implementation of RLS would bring many difficulties and consume a lot of resources. This paper proposes a method that could implement the RLS algorithm with any dimension in FPGA(Field Programmable Gate Array) and solve the problem in lacking resources due to less multipliers and registers in hardware construction.
作者簡介:
Hardware Implementation of RLS with Any Dimension
XING Lu-lu
(Chengdu Spaceon Technology Co., Ltd.,Chengdu Sichuan 610000, China)
Key words:Key words:RLS; FPGA; implementation
0引言
在空域自適應(yīng)濾波算法中,RLS(recursive least squares)算法是一種指數(shù)加權(quán)的最小二乘方法此方法使用指數(shù)加權(quán)的誤差平方和作為代價函數(shù)使此函數(shù)最小化利用遞歸的方法完成矩陣求逆運算。它具有收斂速度快,實時性好,對非平穩(wěn)信號適應(yīng)性強的優(yōu)點。
在工程運用中可以對信號的矩陣進行QR分解從而計算出方程組解,且對矩陣進行直接分解較標(biāo)準(zhǔn)RLS具有更好的數(shù)值穩(wěn)定性和更小的運算量。傳統(tǒng)的QR_RLS算法在FPGA(現(xiàn)場可編程門陣列)實現(xiàn)的時候,是通過Systolic(脈動)結(jié)構(gòu)來進行硬件實現(xiàn)的,這需要用到很多的乘法器和寄存器資源,如果算法的維數(shù)M變多會導(dǎo)致乘法器和寄存器資源不夠用。而如果選用資源夠多的硬件來實現(xiàn),又會造成硬件成本的增加。
在FPGA設(shè)計實現(xiàn)中,有時可用的邏輯資源有限,這時可能只有犧牲數(shù)據(jù)吞吐率來獲得更小的資源消耗。在資源有限的情況下,可以對某一個模塊分時進行使用,運算過程中產(chǎn)生的中間量用寄存器暫存,這種實現(xiàn)方法便是折疊。相比脈動結(jié)構(gòu),折疊算法在RLS的FPGA實現(xiàn)中的運用還不是很常見。
針對空域RLS算法的特點,本文在折疊算法思想基礎(chǔ)上提出了一種任意維空域遞推最小二乘算法的硬件實現(xiàn)的方法。該算法可以在硬件結(jié)構(gòu)中使用較少的乘法器和寄存器進行任意維空域遞推最小二乘運算,從而解決當(dāng)算法中的維數(shù)變多后資源不夠用的問題。
1QR-RLS算法

(1)
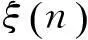
(2)
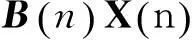
2QR-RLS算法的Systolic處理實現(xiàn)
(3)
如果式(3)中前M行每個元素看成一個計算單元,最后一行看成輸入,可進一步演化出如下的形式[4]:
(4)
相應(yīng)地可得到QR_RLS算法的Systolic結(jié)構(gòu)(脈動結(jié)構(gòu))如圖1所示。圖1中M=3,共有10個處理單元。
由此可見,傳統(tǒng)的QR_RLS算法在FPGA(現(xiàn)場可編程門陣列)實現(xiàn)的時候,是通過Systolic(脈動)結(jié)構(gòu)來進行硬件實現(xiàn)的,這需要用到很多的乘法器和寄存器資源,如果算法的維數(shù)M變多會導(dǎo)致乘法器和寄存器資源不夠用。而如果選用資源夠多的硬件來實現(xiàn),又會造成硬件成本的增加。
3改進的QR-RLS硬件實現(xiàn)算法
本文提出了一種折疊算法,可以有效地降低資源使用率,該算法的流程圖如圖2所示。
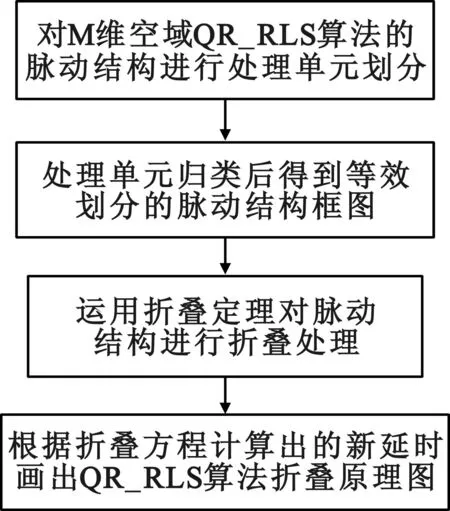
圖2 本文改進方法流程
以4維RLS(空域遞推最小二乘)算法為例,該算法的具體實現(xiàn)方法為:
a.在對QR_RLS算法進行Givens旋轉(zhuǎn)時,將M維空域遞推最小二乘算法的脈動結(jié)構(gòu)劃分為均具有輸入和輸出的邊界處理單元、內(nèi)部處理單元和乘積單元,其中M為自然數(shù)。邊界處理單元對應(yīng)于圖1中標(biāo)有z11,…,z12的圓圈,如圖3所示,共有M個。
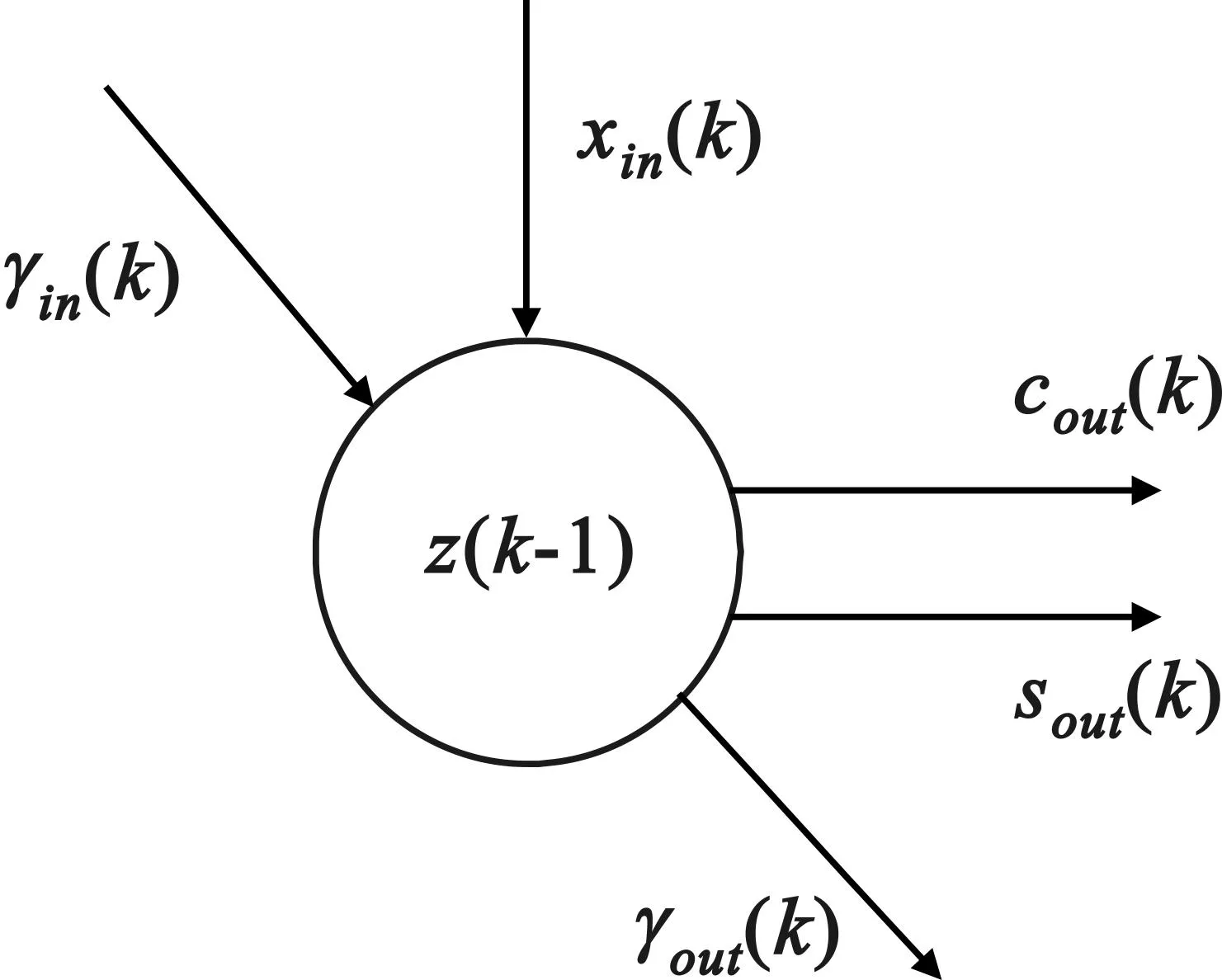
圖3 邊界處理單元示意
邊界單元的表達(dá)式為:
(5)
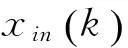
內(nèi)部處理單元對應(yīng)于圖1中的方框,它分為兩類:如圖4所示的第一內(nèi)部處理單元。
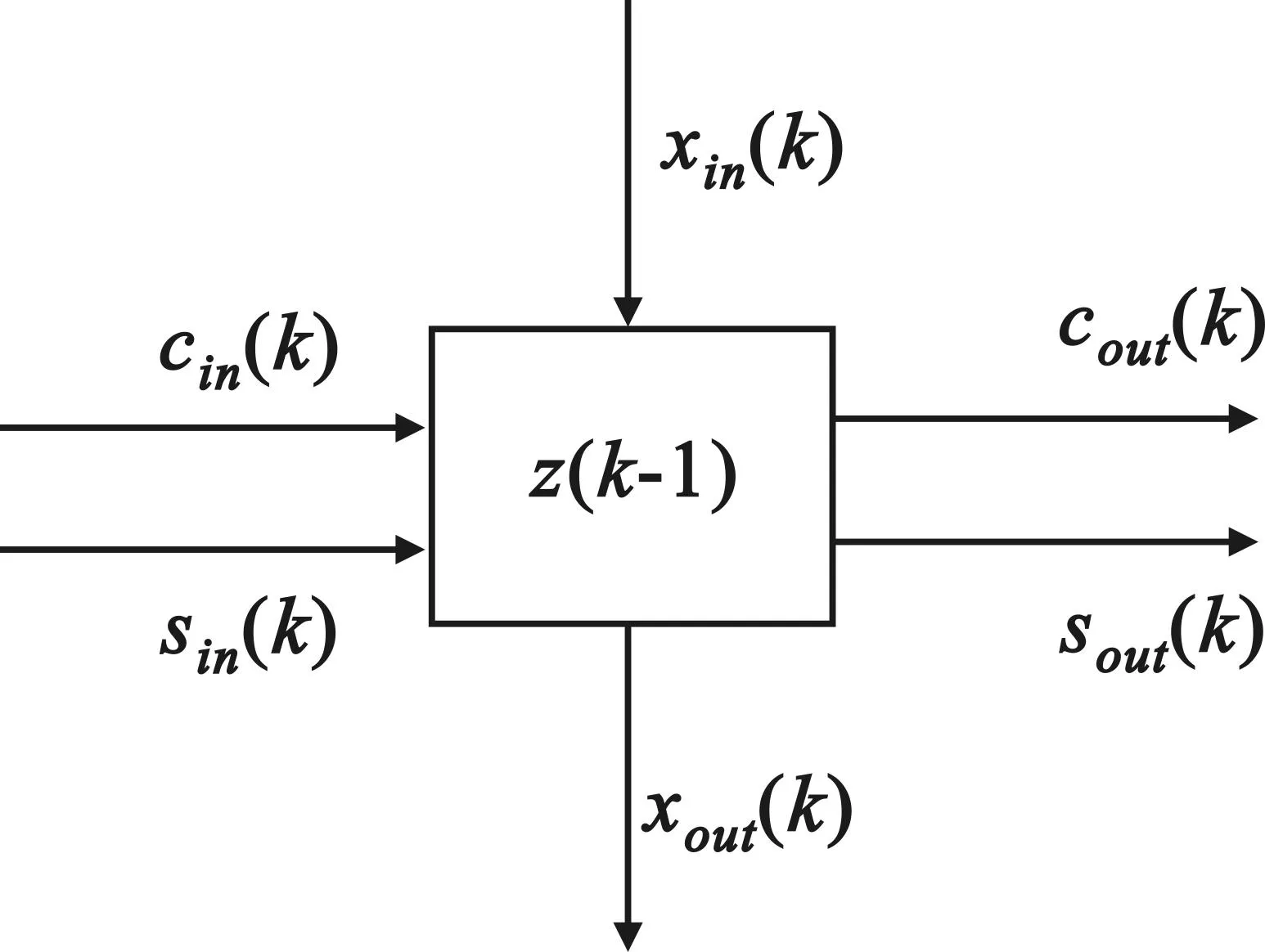
圖4 第一內(nèi)部處理單元
對應(yīng)圖1標(biāo)zji的方框,共有M(M-1)/2個:
(6)
如圖5所示的第二內(nèi)部處理單元,對應(yīng)于圖1中標(biāo)有ui的方框,共有M個。
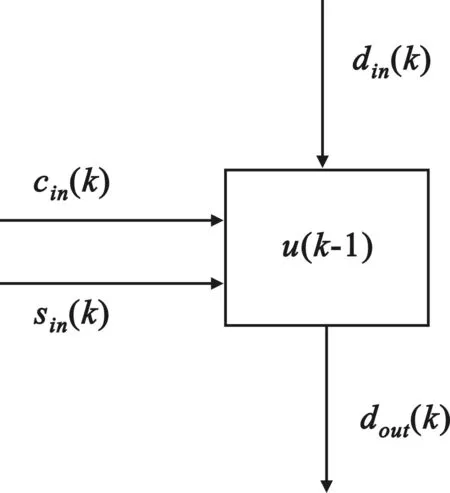
圖5 第二內(nèi)部處理單元
表達(dá)式為:
(7)
如圖6示的乘積處理單元,對應(yīng)圖2中標(biāo)有×的圓圈,該單元只有一個。
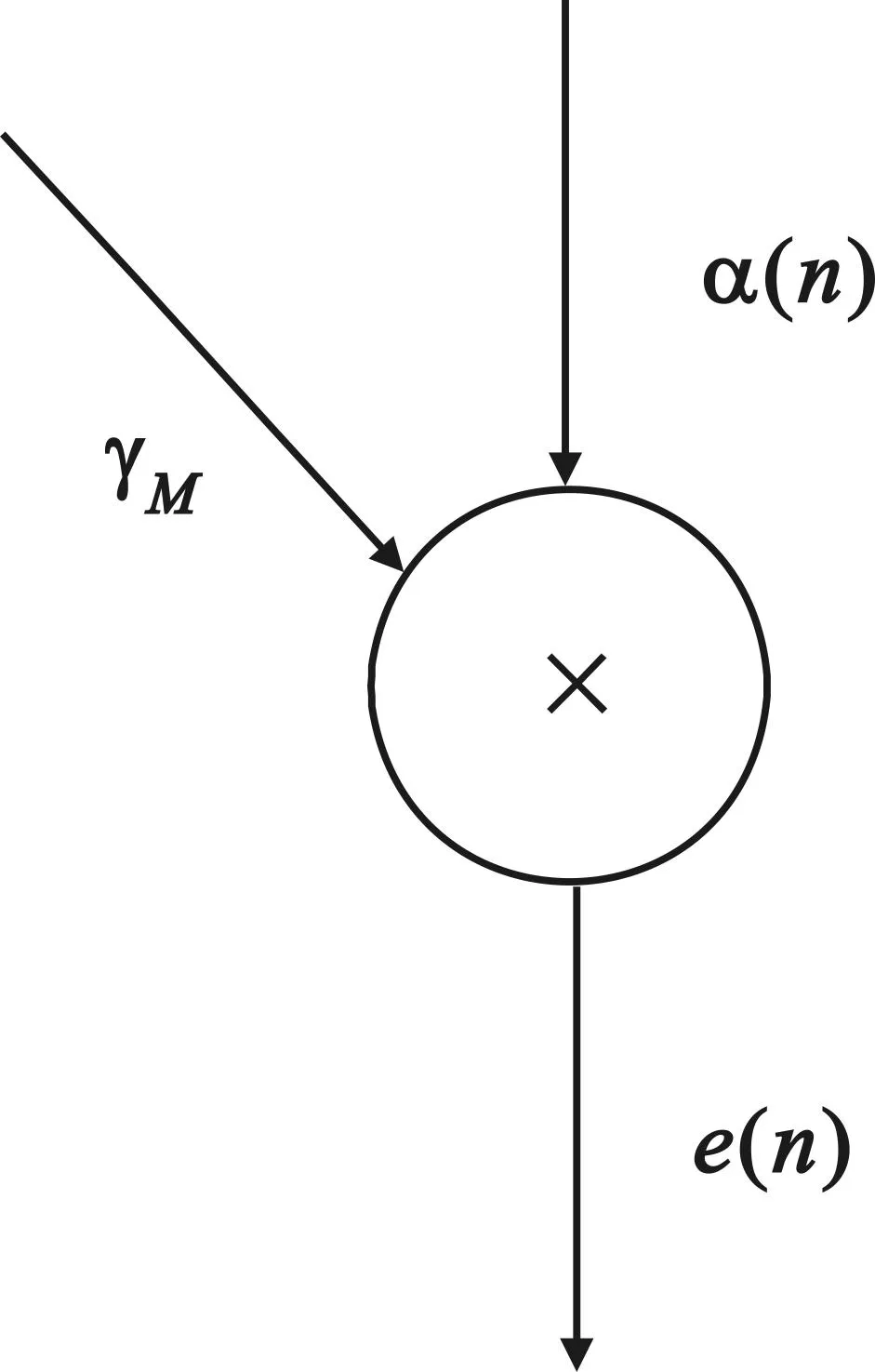
圖6 乘積處理單元示意
b.根據(jù)步驟a劃分出的三個處理單元,將M維空域遞推最小二乘算法的脈動結(jié)構(gòu)進行等效劃分,并將邊界處理單元命名為PEA(PE: processing elements,處理單元),內(nèi)部處理單元命名為PEB,乘積處理單元此處省略,因為乘積單元只影響最終的誤差信號輸出,不會影響內(nèi)部單元和邊界單元的運算。由此圖1所示的systolic結(jié)構(gòu)可以簡化成如圖7示,其中D表示延遲,在系統(tǒng)中可以認(rèn)為是一個采樣時刻。
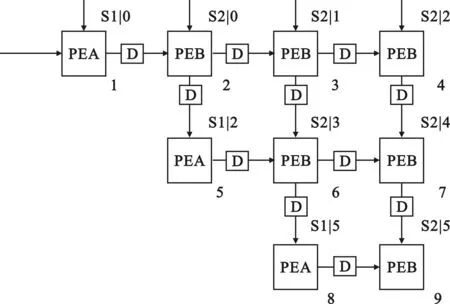
圖7等效劃分后的Systolic結(jié)構(gòu)示意
d.根據(jù)步驟c的新延時表得到Systolic結(jié)構(gòu)的折疊原理圖,如圖8所示,圖8的l表示的是迭代次數(shù)。由此得到了4維RLS算法的Systolic折疊結(jié)構(gòu),當(dāng)實際工程要求中RLS算法的維數(shù)大于4時,根據(jù)圖1畫出相應(yīng)維數(shù)的Systolic結(jié)構(gòu),然后根據(jù)步驟b得到等效后的Systolic結(jié)構(gòu)圖,重復(fù)步驟c即可得到任意維的RLS算法的Systolic折疊結(jié)構(gòu)。
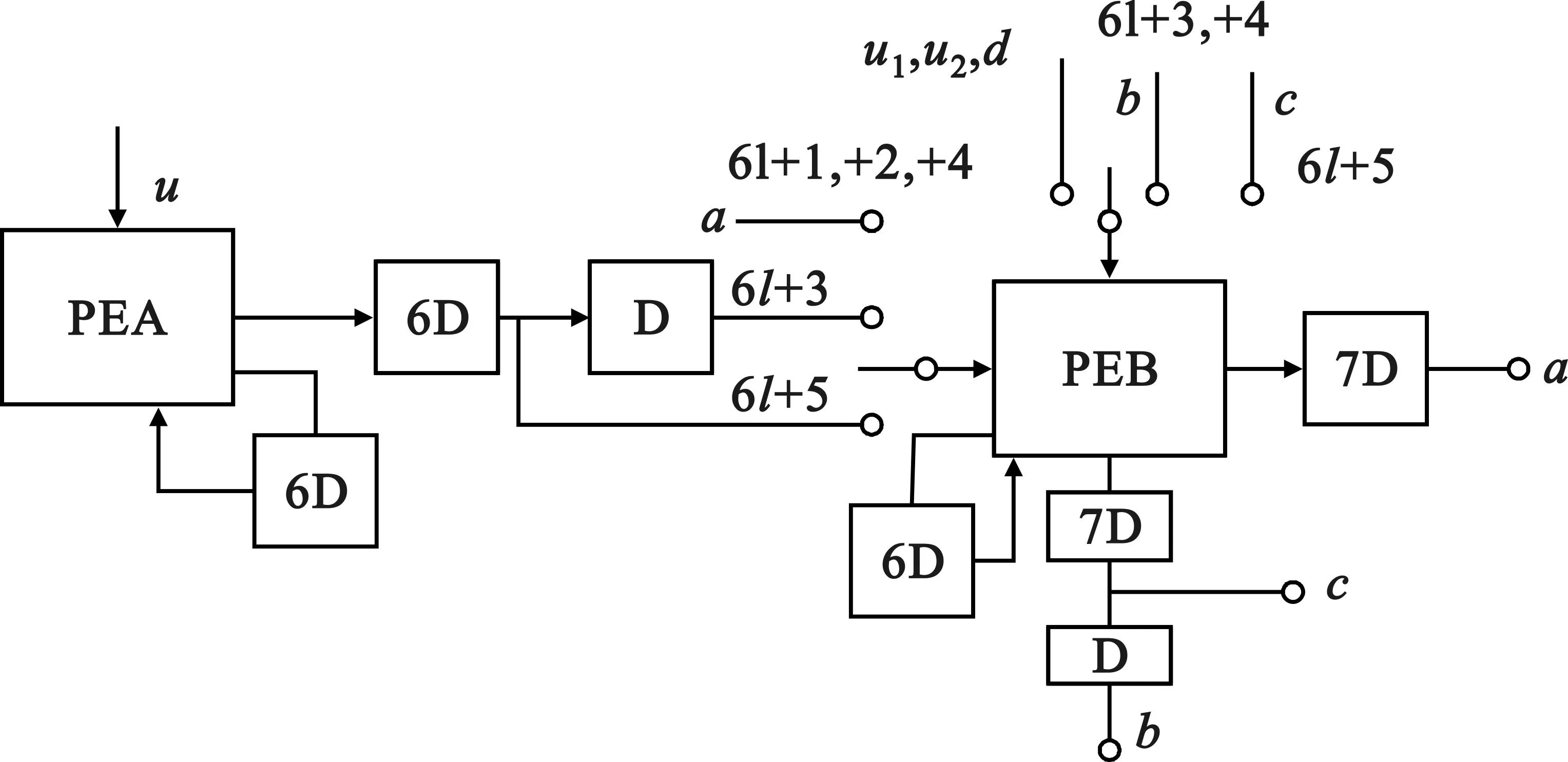
圖8 四維Systolic結(jié)構(gòu)的折疊原理
4仿真分析
用本文的折疊RLS的算法在QuartusII上分別實現(xiàn)一個4維和16維的RLS算法,觀察其仿真資源,并與4維脈動結(jié)構(gòu)的RLS算法資源消耗對比如表1所示。
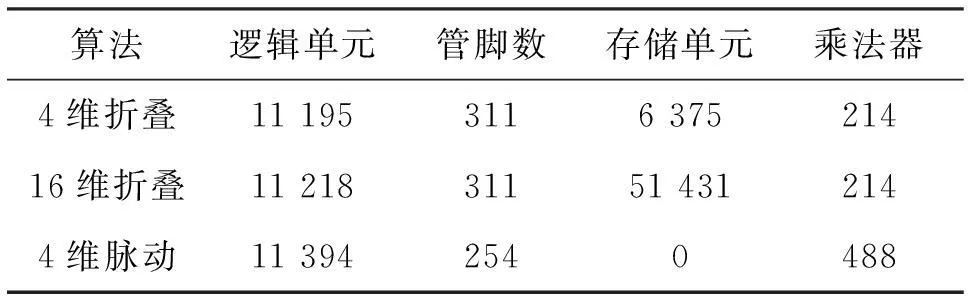
表1 仿真資源消耗對比
我們可以看出4維折疊QR_RLS與16維折疊QR_RLS所消耗的資源基本上相通,除了后者要比前者多有一些RAM資源,這是因為后者的結(jié)構(gòu)只是在前者的基礎(chǔ)上多加了一些D延時單元,其基本運算結(jié)構(gòu)是保持不變的。這一點對更高維的QR_RLS算法實現(xiàn)同樣適用。而脈動結(jié)構(gòu)不消耗存儲單元,但是會消耗更多的乘法器,當(dāng)完成四維的RLS實現(xiàn)時,所用乘法器資源已經(jīng)占了乘法器資源的91%,當(dāng)維數(shù)再增加時,硬件資源已經(jīng)不夠,故無法實現(xiàn)更高維的RLS算法。
5結(jié)語
本文分析了QR-RLS算法的原理,介紹了現(xiàn)有的基于Systolic結(jié)構(gòu)的實現(xiàn)算法。目前QR-RLS的實現(xiàn)大多采用這種結(jié)構(gòu),但是當(dāng)維數(shù)增加后,資源的耗費也會隨之增加。針對該問題,本文提出了一種通過折疊算法進行改進的方法。該方法通過折疊的思想,在原有算法的結(jié)構(gòu)上進行了改進。經(jīng)過仿真驗證,使用該算法時,當(dāng)維數(shù)增加時,消耗的硬件資源并沒有隨之增加。該算法在原有算法的基礎(chǔ)上大大減少資源的耗費情況,進而解決了當(dāng)維數(shù)增加時硬件資源不夠的問題,可以在維數(shù)較大時很好地實現(xiàn)QR-RLS算法。
參考文獻:
[1]李成, 舒勤. RLS算法自適應(yīng)信道估計的性能分析[J]. 通信技術(shù),2009,42(07):53-54.
LI Cheng,SHU Qin.Performance Analysis of RLS Algorithm Adaptive Channel Estimation[J],Communications Technology.2009,42(07):53-54.
[2]楊鐵軍, 李軍華. 基于QR分解的低復(fù)雜度RLS算法研究[J]. 機電設(shè)備, 2013(04):71-74.
YANG Tie-jun,LI Jun-hua,Low Complexity RLS Algorithm Based on QR Decomposition[J].Mechanical and Electronic Equipment, 2013, (4):71-74.
[3]杜鶴, 買培培, 蘇濤等. QR—RLS算法的浮點脈動陣結(jié)構(gòu)研究與FPGA實現(xiàn)[J]. 現(xiàn)代雷達(dá), 2011,33(05):26-29.
DU He,MAI Pei-pei,SU Tao,et al. Study on Floating-Point Systolic Array Structure and FPGA Implementation based on QR-RLS Algorithm[J].Morden Radar, 2011, 33(05):26-29.
[4]何子述,夏威.現(xiàn)代數(shù)字信號處理及其運用[M].北京:清華大學(xué)出版社,2005.
HE Zi-shu,XIA Wei.Modern Digital Signal Processing and Its Application. Beijing:Tsinghua University Press,2005.
[5]Keshab, Parhi K. VLSI數(shù)字信號處理系統(tǒng)設(shè)計與實現(xiàn)[M].北京:機械工業(yè)出版社出版, 2003.
Keshab, Parhi K. VLSI Digital Signal Processing Systems: Design and Implementation[M].China Machine Press,2003.

幸璐璐(1981—) , 女,碩士,工程師,主要研究方向為衛(wèi)星通信抗干擾理論研究與設(shè)計。
猜你喜歡
青年時代(2016年29期)2016-12-09 22:50:42
農(nóng)業(yè)與技術(shù)(2016年20期)2016-12-08 21:47:44
科學(xué)與財富(2016年26期)2016-12-01 21:03:28
中國新技術(shù)新產(chǎn)品(2016年22期)2016-11-29 04:53:54
中小企業(yè)管理與科技·上旬刊(2016年11期)2016-11-28 20:54:58
讀與寫·上旬刊(2016年10期)2016-11-25 16:11:23
科學(xué)與財富(2016年15期)2016-11-24 16:21:10
辦公室業(yè)務(wù)(2016年9期)2016-11-23 10:44:30
辦公室業(yè)務(wù)(2016年9期)2016-11-23 09:15:57
電腦知識與技術(shù)(2016年25期)2016-11-16 13:21:48
