決策技術應用分析與驗證
2015-12-24 10:32:36王億,徐偉
北方經貿 2015年8期
王 億,徐 偉
(黑龍江職業學院,哈爾濱 150080)
一、模糊決策樹技術應用分析
決策樹是通過一系列規則對數據進行分類的過程。它提供一種在什么條件下會得到什么值的類似規則的方法。構造決策樹的過程為:首先尋找初始分裂。決定哪個屬性域作為目前最好的分類指標。一般的做法是窮盡所有的屬性域,對每個屬性域分裂的好壞做出量化,計算出最好的一個分裂。建決策樹,就是根據記錄字段的不同取值建立樹的分支,以及在每個分支子集中重復建立下層結點和分支。
由于現實世界中某些事物的屬性是很相近的,如果按照清晰的標準把它們分到不同的類別,可能會造成信息的丟失。例如:當“車載重量”低于100時,認為是“輕”,而高于100低于200時,則認為是“中”,那么當重量是臨界值的時候,用模糊的方法更適合。模糊綜合評判的過程包括:綜合考慮各種屬性,建立被評判對象的因素集;建立評判集,即評價的等級和評語;建立單因素評判,即對實際對象的因素集中的屬性運用評判集進行評價;根據實際情況,賦予不同因素以不同的權重;根據權重和單因素評判結果得出綜合評判的結果。
清晰算法是一種典型的決策樹歸納算法,這種算法在假定示例的屬性值和分類值是確定的前提下,使用信息熵作為啟發式建立一棵清晰的決策樹。針對現實世界中存在的不確定性,人們提出了另一種決策樹歸納算法,即模糊決策樹算法,它是清晰決策樹算法的一種推廣。這兩種算法在實際應用中各有自己的優劣之處,針對一個具體問題的知識獲取過程,選取哪一種算法目前還沒有一個較明確的依據。
(一)生成決策樹的優缺點
清晰決策樹(CDT)知識表示可理解性差,沒有考慮現實中分類的不確定性,生成樹概括能力差,對空間的劃分過于細致,不易推廣。產生的知識具有一定的偏差,易受噪音影響,易產生過于適合現象。模糊決策樹(FDT)知識表示可理解性強,充分考慮現實中分類的不確定性,生成樹的概括能力強,對空間劃分適中,易于推廣。產生的知識表達較為準確,抗噪音能力強,避免產生過于適合現象。
(二)適用范圍
CDT適用于符號值屬性和分類較清晰、噪音小的中小型數據庫。FDT適用于各種情況的數據庫,特別是對屬性和類模糊性強,有噪音的數據庫。對模糊決策樹算法的評價決策樹對比神經元網絡的優點在于可以生成一些規則。當進行一些決策時,還需要相應的理由的時候,使用神經元網絡就不行了。
總之,在決策樹的算法當中,模糊決策樹更符合現實世界,具有更廣泛的應用空間。
二、模型準確性評估
(一)解釋評估標準
在完成一個挖掘算法之后,常常會獲得成百上千的模式或規則。顯然這些規則中會有一小部分是有實際應用價值的。那么如何對數據挖掘所獲得的挖掘結果進行有效地評估,以便最終能夠獲得有價值的模式(規則)知識,這就給數據挖掘提出了許多需要解決的問題。
1.使一個模式有價值的因素是什么?評估一個模式(知識)是否有意義通常依據以下四條標準:一是易于用戶理解;二是對新數據或測試數據能夠確定有效程度;三是具有潛在價值;四是新奇的。一個有價值的模式就是知識。
2.一個數據挖掘算法能否產生所有有價值的模式(知識)?這是指數據挖掘算法的完全性。期望數據挖算法能夠產生所有可能模式是不現實的。實際上一個模式搜索方法可以利用有趣性評價標準來幫助縮小模式的搜索范圍。因此通常只需要保證挖掘算法的完全性就可以了。
3.一個數據挖掘算法能否只產生有價值的模式?解釋評估所挖掘模式的趣味性標準對于有效挖掘出具有應用價值的模式知識是十分重要的。這些標準可以直接幫助指導挖掘算法,獲取有實際應用價值的模式知識,以及摒棄無意義的模式。更為重要的是這些模式評估標準將積極指導整個知識發現過程,通過及時清除無前途的搜索路徑,提高挖掘的有效性。判斷分類的好壞一般可從如下指標進行考慮:預測準確率、速度、創建速度、使用速度、處理噪聲和丟失值、伸縮性、對磁盤駐留數據的處理能力、可解釋性、對模型的可理解性、規則好壞的評價、決策樹的大小和分類規則的簡明性。
(二)二分法交叉驗證評估的實現方法
其中預測準確度是用得最多的一種比較尺度,特別是對于預測分類任務而言,目前公認的方法是分層交叉驗證的損失函數方法。交叉驗證是一種模型評估方法。分類是有監督學習,通過學習可以對未知的數據進行預測。在訓練過程開始之前,將一部分數據予以保留,在訓練之后,利用這部分數據對學習的結果進行驗證,這種模型評估方法為交叉驗證。兩分法是交叉驗證最易用的方法,數據集被分為兩個獨立的子集,稱為訓練集及測試集,有時也稱為正集與反集,二分法交叉驗證工作原理如圖1所示。
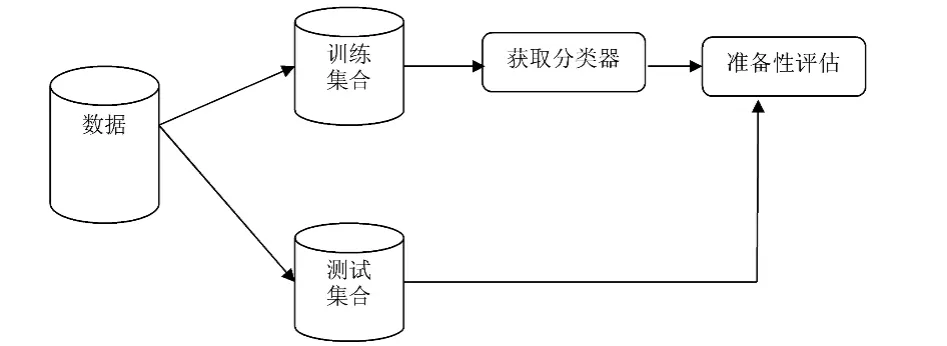
圖1 二分法交叉驗證工作原理
通過二分法交叉驗證,生成驗證過后的有意義的決策樹數據表,以備知識表示的相對正確性。
以上各步的目的就是利用生成的規則來預測測試集中的未知數據是屬于哪一分類,并通過測試結果與實際情況相吻合的準確率來判斷該決策樹是否有效,如果準確率達到或超過預先確定的閾值,則認為所建立的決策樹模型是有效的,能夠應用于實際工作,否則該模型的分類效果不好,需要重新選定訓練集生成新的決策樹,并繼續利用準確率來判斷該決策樹模型的優劣,直到準確率達到預定的閾值為止。本模型準確性評估如圖2所示。

圖2 模型準確性評估的示意圖
在研究的過程中,經過調研及專業分析,確定的準確率閾值為84%,經過對模型測試,其準確率達到了89%,超過預定的準確率閾值,能夠滿足用戶需求。
三、解決問題的方法
1.確定挖掘對象、目標。清晰地定義出挖掘對象,明確目標是數據挖掘的重要一步。明確目標就是定義分析的目的,要弄清所分析的現象并不總是容易的。一般情況下,各個系統的目標是明確的,但是潛在的問題很難轉化為分析需要的具體目標。對問題和目標的明確描述是正確建立分析的先決條件,此時確定的目標決定后面的方法如何組織,因此挖掘的對象和目標一定要明確。
2.數據的收集。根據確定的數據分析對象抽象出在數據分析中所需要的特征信息,然后選擇合適的信息收集方法,將收集的信息存入到數據庫中。
3.數據預處理。對收集的數據進行清理。因為在數據庫中的數據一般是不完整的、含噪聲的、不一致的,因此在這個階段中需要對數據庫中的數據進行清理,對數據進行檢查,保證數據的完整性和數據的一致性,除去噪聲,填補丟失的域,刪除無效數據等,將完整、正確、一致的數據信息存入到數據庫中。
4.數據轉換。將選取的數據轉換成一個分析模型,建立一個真正適合挖掘算法的分析模型,不同的挖掘算法可能采用不同的分析數據模型。
5.分類挖掘知識和信息。目的是根據系統要實現的功能和任務來確定挖掘的分類模型。選擇合適的數據挖掘技術及算法,并使用適當的程序設計語言來實現該算法,在凈化和轉換過的數據集上進行挖掘,得到有用的分析信息。
6.知識的表示——生成分類規則。將數據挖掘得到的分析信息進行解釋和評價,生成分類規則呈現出來。
7.知識的應用。將分析得到的規則應用到日常管理中,管理人員可以利用所得到的知識改進管理方法,調整管理策略,提高管理水平。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
