大數據在電信行業的應用研究
2015-12-21 02:41:22丁亦志李邵平牛瑛霞DingYizhiLiShaopingNiuYingxia
互聯網天地 2015年6期
丁亦志,李邵平,牛瑛霞/Ding Yizhi,Li Shaoping,Niu Yingxia
(中國移動通信集團設計院有限公司 北京100080)
1 引言
大數據(Big Data)技術或稱巨量資料,是指所涉及的資料量規模巨大到無法通過目前主流軟件工具,在合理時間內達到擷取、管理、處理,并整理成為幫助企業經營決策更積極目的的資訊。自2012年以來,大數據一詞越來越多地被提及,人們用它來描述和定義信息爆炸時代產生的海量數據,并命名與之相關的技術發展與創新。數據已經滲透到當今每一個行業和業務職能領域,成為重要的生產因素。
作為云計算、物聯網后IT 行業又一顛覆性的技術革命,大數據隨著近年來互聯網和信息行業的發展而引起人們的廣泛關注,本文旨在對電信行業中的大數據應用進行研究探討。
2 大數據發展趨勢及應用場景
2.1 大數據發展趨勢
通過對互聯網行業大數據的研究,歸納出以下4 項發展趨勢。
(1)去小型機化
“傳統數據庫+小型機+高端陣列”的模式在性價比上很難再延續,SMP的擴展能力接近上限。
(2)計算與數據處理一體機化
軟硬件垂直整合帶來高性能優勢和高集成度。
(3)內存和多核計算的崛起
磁盤已經落伍,內存才是王道;1 TB RAM PC已可行,新的壓縮算法允許在內存里完整儲存大量數據;16 核擴充至64 核,為CPU 提供足夠的指令和數據是高效處理數據的關鍵。
(4)MPP/列存儲,Hadoop 低成本海量分布式架構強勢
通用x86 服務器+Linux+高速網絡+SSD 存儲、MPP+列存儲集群的Scale Out 和OLAP 高性能、Hadoop 生態圈的蓬勃發展。
2.2 大數據應用場景
洛杉磯警察局和加利福尼亞大學合作利用大數據預測犯罪的發生,Google 流感趨勢(Google Flu Trends)利用搜索關鍵詞預測禽流感的散布,統計學家內特·西爾弗(Nate Silver)利用大數據預測2012年美國選舉結果。類似的應用在互聯網行業不勝枚舉,對運營商來說,大數據又有哪些方面的價值?本文總結出以下6 種典型的應用場景,見表1 所列。
3 大數據的平臺架構
3.1 運營商大數據價值體系
本文提出移動互聯網時代運營商的大數據價值體系,包括客戶研究、精準營銷、智能管道、全業務融合和新業務模式等,如圖1所示。
客戶研究包括用戶內容偏好、用戶行為偏好、用戶位置軌跡、用戶交往圈、用戶分群。精準營銷包括內容偏好營銷、事件營銷、位置營銷、業務交叉推薦、渠道協同營銷、體驗式營銷。智能管道包括管道可視化、差分服務、公平使用、策略計費、信息與內容過濾、競爭/替代業務監控分析。全業務融合包括統一客戶信息提升管理水平、統一產品信息提升優化程度、統一服務信息改善客戶體驗、統一資源信息保障協同調度。新商業模式包括后向收費模式支撐、合作產品引入分析、新流量產品引入分析、行業分析報告發布、數據服務開放共享。

表1 運營商典型應用場景
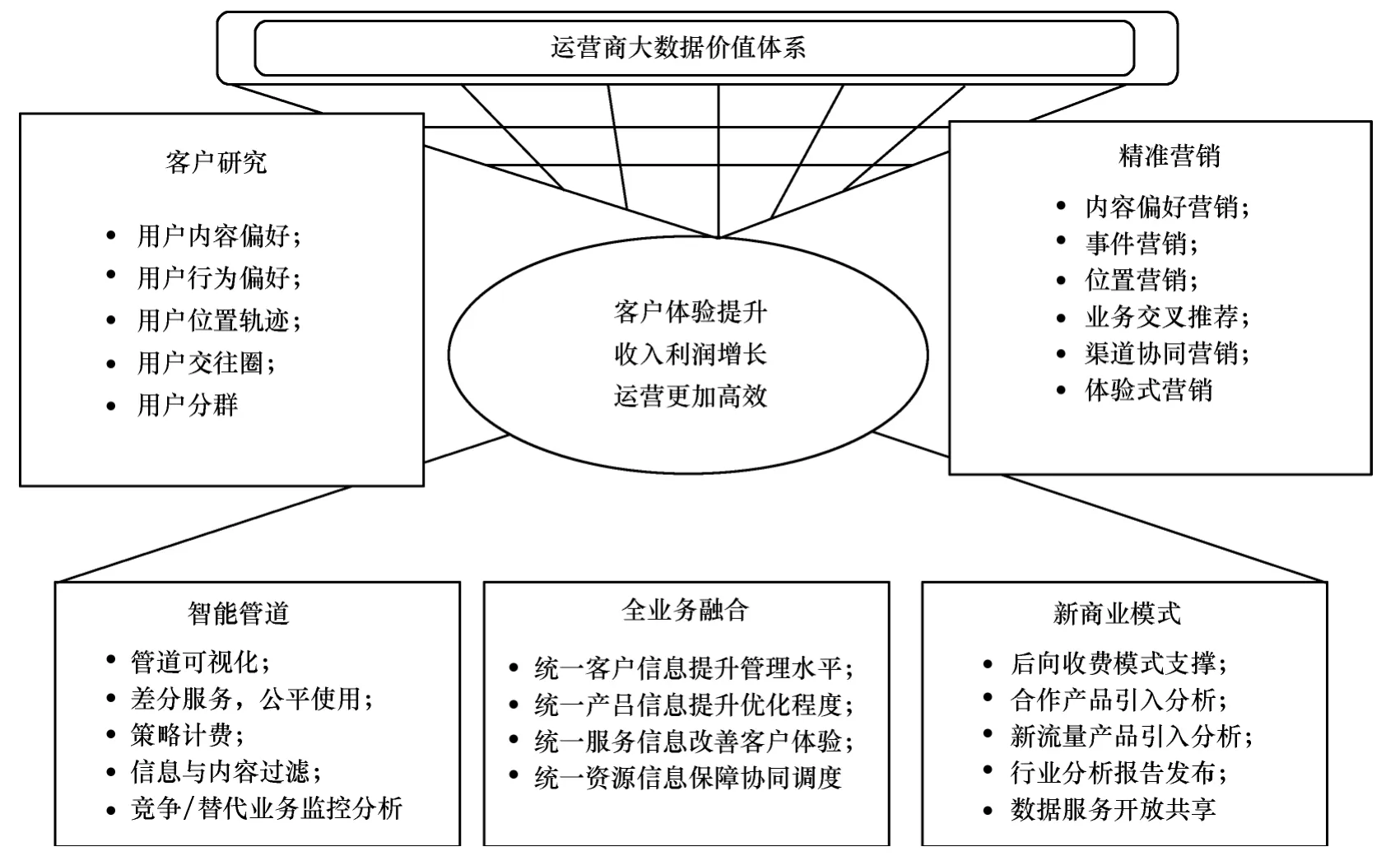
圖1 運營商大數據價值體系
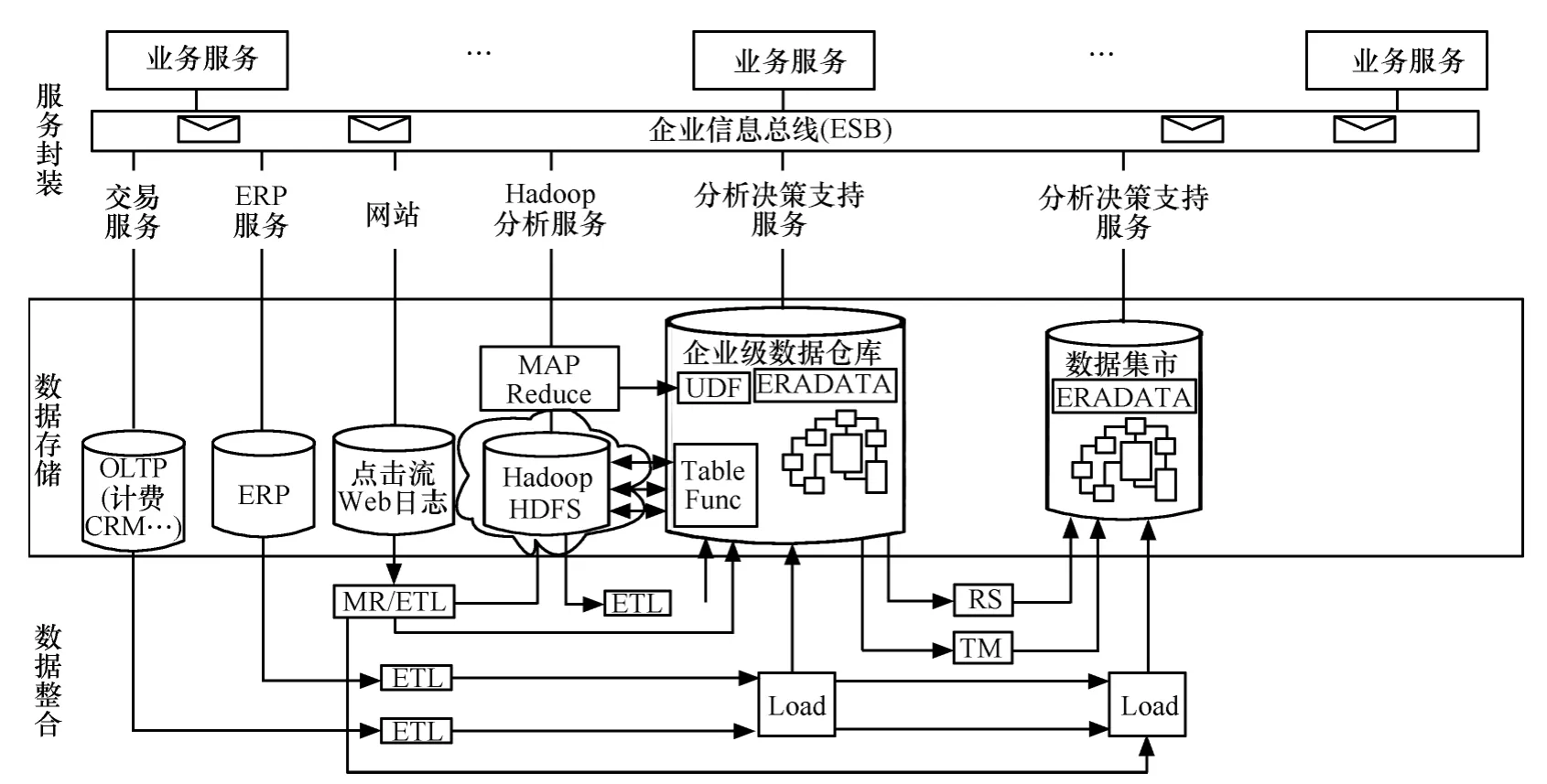
圖2 割裂式混搭架構
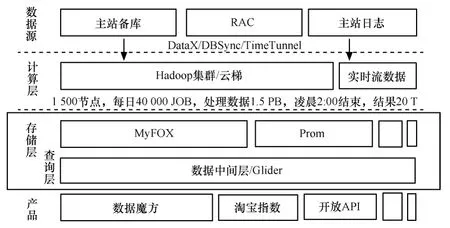
圖3 混搭架構+深度定制化部件架構
3.2 大數據平臺架構
大數據平臺架構主要包括割裂式混搭架構、混搭架構+深度定制化部件、Hadoop 深度定制架構和自主研發新架構4 類架構。
(1)割裂式混搭架構
割裂式混搭架構模式是Hadoop+MPP RDB/SMP RDB,以Hadoop 處理非結構化為輔,RDB 處理結構化為主。主要應用于eBay、KDDI、中國移動省級經分等,架構如圖2所示。
(2)混搭架構+深度定制化部件
混搭架構+定制化部件是Hadoop+MPP RDB+NoSQL/MyFox/Prom/glider/OceanBase、Hadoop 海量結構化/非結構化存儲、ETL 和離線計算基礎;MPP DB面向高速訪問存儲和部分實時計算; 專用場景部件,例如基于NoSQL的Prom/OceanBase,解決特定業務場景問題(全屬性查詢)和復雜的實時計算。阿里巴巴和淘寶是此架構最好的代表,如圖3所示。
(3)Hadoop 深度定制架構
Hadoop 深度定制架構即Hadoop Enhanced,圍繞Hadoop 生態圈進行深度定制和優化。騰訊和百度是此架構的代表,如圖4所示。
(4)自主研發新架構
自主研發架構包括Caffeine、Pregel、Dremel、Power Drill、Storm、Qubole、RCFile 等,擁有核心知識產權和創新技術驅動業務革新。Google、Twitter、Facebook 都是基于自主研發的新架構,如圖5 和圖6所示。
(5)運營商平臺架構的演進
在大數據中,運營商在3~5年內仍然是以結構化數據處理為主。但今后的趨勢是往混合結構方向演進。當前建設方案應采取Hadoop+MPP RDB 集群的混搭模式,為使上層應用平滑過渡,需要在混搭的架構上建設透明訪問層,以屏蔽數據源的異構、多實例特性。Hadoop平臺承擔了原始海量數據的抽取、轉換、加載和輕度匯總等計算任務。同時新建MPP RDB 集群的深度分析庫,支撐查詢模型復雜、多變的自助分析應用。具體架構演進示意如圖7所示。
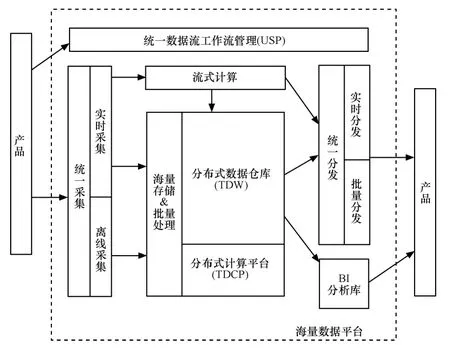
圖4 Hadoop 深度定制架構
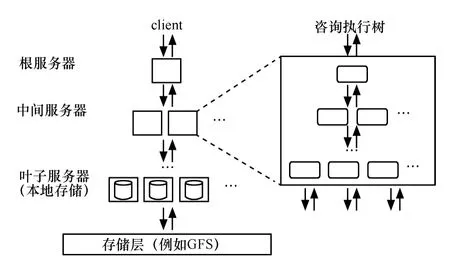
圖5 自主研發新架構示意
①專用數據倉庫(如TD)+MPP RDB 集群混搭模式,支撐傳統的固定查詢,如報表類應用等。
②用Hadoop平臺支撐流量清單查詢,這需要對Hadoop 進行深度定制、改造。否則需要將清單數據加載到MPP RDB 集群的數據倉庫中支撐查詢。
③MPP RDB 集群支撐自助分析類應用,此類查詢模型復雜、多變,且要求實時展現。
4 關鍵技術
大數據涉及的關鍵技術主要包括流數據處理、費關系型數據庫技術、MPP DB 和文件型分布式存儲。
4.1 流數據處理
為應對海量數據實時處理的需求,業界引入了流處理的機制。在數據流動的過程中分析和計算,分析只對一定時間段內(Δt)的數據進行處理,事件/數據觸發分析,分析過程始終在線,流處理又分為狹義流處理和廣義流處理兩大類。
狹義流處理為ESP(Event Stream Process,事件流處理)和CEP(Complex Event Process,復雜事件處理)。
廣義流處理不但提供結構化數據的離散事件流處理能力,同時提供非結構數據的連續流處理,如Video、Image、Text。對非結構化數據一般主要提供分布式計算機制。
4.2 非關系型數據庫技術
相比于RDBMS,NoSQL 數據存儲不需要固定的表結構,通常也不存在連接操作,在解決大規模數據的可擴展性上有獨到的解決方案,因此,在大數據存取上具備RDBMS 無法比擬的性能優勢,非常適合超大規模和高并發的SNS 型Web2.0 網站;但在一致性方面,則不如RDBMS,不適用于企業的關鍵應用。
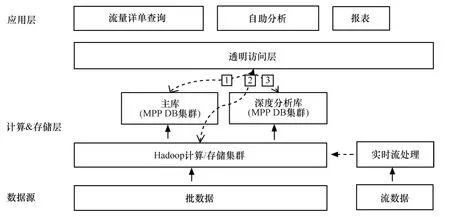
圖7 由混搭架構向深度定制架構演進
NoSQL 一般與具體應用強綁定,主要由開源項目推動,Facebook、Digg、Twitter、Amazon 等都是NoSQL的推動者,其中,Facebook的Cassandra、Google的Big Table、Amazon的Dynamo 等都是非常成功的NoSQL商業實現。
目前,NoSQL家族中應用較為廣泛的有HBase(Hadoop的衍生項目,類似Google的Big Table)、Cassandra(由Facebook 開發,用于存儲特別大的數據,是網絡社交云計算方面理想的數據庫)、MongoDB(功能最豐富、最像關系型數據庫的非關系型數據庫,可存儲比較復雜的數據類型)。
4.3 MPP DB
MPP DB 是指大規模并行處理(Massive Parallel Processing)數據庫,有兩種基本形式:Share Disk 和Share Nothing。
Share Disk:性能比較高,由于需要在節點間共享鎖和緩存,可擴展性受到一定限制。適合高并發的OLTP 應用和數據量較小的OLAP 應用。
Share Nothing:每個節點的存儲、計算、內存完全獨立,數據分區存放,可擴展性好。適合大數據量的OALP 引用,但計算設備不容易做到熱備,可用性級別略低。
兩種基本形態都比較適合大數據的處理。考慮到擴展性,主存儲和ETL 數據加工應首選Share Nothing。數據分析要求靈活,擴容壓力不大,自定義數據處理的應用建議采用Share Disk,局域網絡帶寬在不斷提升,Share Disk 前景同樣很好,與Share Nothing 適用不同的場景。
4.4 大數據的存儲—文件型分布式存儲
對比MPP DB,文件型分布式存儲的優點主要有以下幾個方面:
①基本實現了RAID 所具備的數據高可用性要求;
②比RAID 自愈能力更強;
③沒有數據庫冗余開銷。
對比MPP DB,文件型分布式存儲的缺點主要有以下幾個方面:
①基于指定的Key 散列分布,對數據運用限制很大;
②Key Value 方式連續讀寫效率不高;
③沒有事務、關聯、數據版本控制等數據庫特性。
5 相關應用與實踐
針對大數據,運營商進行了相關嘗試,下面以BSS 云化ETL、融合通信、某省日志詳單系統為案例進行簡單的介紹。
5.1 BSS 云化ETL
移動數據業務和流量的爆發式增長,帶來了網絡建設和維護費用的成倍增加。數據業務中大量的非價值業務占據了60%以上的流量總帶寬。低價值業務造成收入與業務量失去關聯性,原有技術方式不能支撐數據業務盈利,使高價值業務的服務質量難以保證,最終導致終端用戶的體驗和滿意度下降。
流量經營分析對云化ETL 和數據挖掘的要求:對各個數據源的日志進行轉換裝載,將海量數據存儲在分布式存儲中,基于這部分數據能夠進行匯總等計算。對于ETL的訴求,要求能夠基于海量數據做E-T-L 操作,同時能夠做相應的關聯匯總統計等功能。
5.2 融合通信SmartCare
SmartCare 為用戶提供Network Insight解決方案,包括業務質量、用戶體驗、網絡性能等。網絡及業務信令實時流入,一方面被存儲下來作為詳單存儲和查詢;另一方面被匯總計算得到統計結果,用于OLAP 分析和報表查詢。Infosea HDFS 和HBase 被用于詳單存儲,MR 被用于匯總計算。
其中,HBase 單點入庫1.3 萬條/s(4.5 MB/s),MR 服務器單點入庫1.2 萬條/s,單點存儲空間為9.6 T(2 T×8 塊),xDR 單據產生速率為28.1 萬條/s,每條362 Byte。
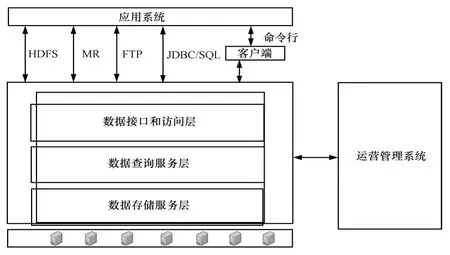
圖8 日志詳單系統模型
5.3 某省日志詳單系統
日志詳單類數據云存儲系統基于x86 PC 服務器集群,通過軟件系統實現高性能和海量存儲,具體如圖8所示。
設計目標如下。
①高可靠性,通過數據和服務冗余、分布式鎖系統來解決PC 硬件故障率較高的問題。
②高可伸縮性,系統可以容易地增加或者減少容量和性能。
業務描述如下。
①基于HDFS的數據存儲服務:為數據庫系統提供海量結構化數據的存儲服務,通常使用具備冗余存儲、自動負載均衡能力的云計算分布式文件系統。
②基于MR 和Hive的數據查詢服務: 完成用戶查詢的分解、轉換、執行、結果收集和優化工作,由于數據可能被分配在很多存儲服務節點上,數據查詢服務必須具備分布式查詢執行和結果收集能力,同時考慮到硬件的不可靠性,數據查詢服務需要具備很高的容錯能力。
③數據接口和訪問層:連接應用程序和數據查詢服務。主要對應用提供兩類接口:數據存取接口,如針對非結構化數據的HDFS 接口; 數據查詢分析接口,MR 接口、標準JDBC/SQL 接口等。
6 結束語
隨著互聯網業務的高速發展,大數據的廣泛應用是業務發展的趨勢。運營商需要加強對大數據的管理,對網絡和業務系統進行全方位覆蓋,深刻理解業務,精確洞察數據,充分發揮數據價值。后續,大數據技術與流量經營相結合,對大數據應用價值探索,構建大數據流量增值體系將是研究的重點。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
