基于FPGA的高效機載視頻采集及預處理方法
2015-12-19 00:55:20姜宏旭李輝勇劉亭杉段洣毅張萍
北京航空航天大學學報 2015年1期
關鍵詞:方法
姜宏旭,李輝勇,劉亭杉,段洣毅,張萍
(北京航空航天大學 計算機學院,北京100191)
近年來,無人機在軍用和民用領域均獲得了廣泛應用,其承擔的首要任務是通過機載視頻編碼系統實時獲取和處理視頻信息并及時傳送到地面控制中心[1].隨著光電載荷技術的發展,在視頻分辨率不斷提高的同時,視頻模式也呈多樣化發展,除可見光視頻外,還有紅外、數碼相片等[2].為了適應機載應用的發展,需要高性能多模式視頻編碼系統的支持,然而機載應用的特殊性要求系統在追求高性能的同時,還要考慮系統的可靠性和低功耗[3].
基于現場可編程門陣列(FPGA)的機載視頻采集及預處理系統的主要功能單元包括多模式視頻采集、顏色空間轉換和視頻數據交互傳輸.多模式視頻采集單元是基于Camera Link接口實現機載多模式視頻數據的實時采集.文獻[4]面向嵌入式系統,選用FPGA基于FIFO(First Input First Output)機制解決了Camera Link相機和DM642之間無法直接連接的問題.文獻[5]為了完成高清實時視頻通信,采用FPGA實現了Camera Link接口的視頻采集,可以滿足高清視頻數據的實時采集.然而這些設計都側重于Camera Link接口功能的實現,忽略了在視頻采集過程中數據錯誤的控制.目前的研究缺乏對視頻采集過程中出現的數據錯誤進行有效控制,在一定程度上難以保證視頻數據的可靠性,尤其是針對機載應用,及時可靠地獲取清晰的視頻信息顯得尤為重要.
顏色空間轉換預處理單元的主要功能是將視頻的顏色空間從RGB轉換到YCbCr.機載視頻采用Camera Link接口輸入,其視頻是RGB格式,然而大多數視頻編碼標準使用YCbCr顏色空間[6-7].因此FPGA除了實時采集視頻圖像數據外,還要擔負顏色空間轉換任務.然而顏色空間轉換中有多個浮點乘運算,這在FPGA上實現時,往往需要設計專門的浮點乘法器進行處理,從而占用大量的邏輯資源和布線資源,增加系統功耗.為了提高系統效能,通常的方法是采用查找表(LUT)方式實現乘法運算,文獻[8-9]均對LUT進行了優化處理以提高計算效率.因為LUT需要占用的計算資源較少,所以在實際應用中十分有效.然而,直接使用LUT實現的不足之處在于隨著變量數值位寬的增大,LUT占用的存儲空間將不斷增大.為了解決這個問題,文獻[10-12]分別針對LUT的存儲空間優化進行了一定研究.雖然在一定程度上節約了存儲空間,但是效果不是十分明顯.文獻[13-15]中針對截斷式乘法器的研究為本文的處理提供了一種新的思路.對于嵌入式應用程序而言,截斷乘法不需要緩存乘法運算結果的完整長度,這有效減少了乘法運算占用的存儲空間并降低了功耗.所以,為了進一步降低視頻預處理中浮點乘法引入的動態功耗,本文綜合LUT和截斷處理技術,設計了一種高低位分離的截斷式LUT乘法器,實現了高效低功耗的RGB到YCbCr顏色空間轉換.
視頻數據交互傳輸單元的主要任務是實現視頻數據和壓縮碼流在FPGA與DSP之間的高效傳輸.在FPGA與DSP之間存在大量視頻數據的頻繁傳輸,這會占用DSP的部分處理資源,影響編碼器性能.針對這個問題,本文采用SRIO接口,設計了一種以FPGA為控制核心的數據交互機制,盡量減輕DSP的負擔,使DSP專注于視頻編碼運算,降低處理延時.
1 可靠的多模式視頻采集方法
在機載多模式視頻編碼系統設計中,視頻輸入接口需要支持多種模式的視頻圖像數據,然而在具體實現中發現,不同模式視頻切換過程中,容易出現視頻數據錯位現象.其原因是在模式切換的瞬間,視頻數據的發送方和接收方出現了信號不同步的問題.為了有效降低數據錯誤的影響,本節設計了一種具有自動檢錯機制的視頻數據采集方法,實現錯誤的自動檢測和及時恢復.
1.1 自動檢錯控制器設計
視頻圖像采集主要是根據輸入的幀有效信號與行有效信號來確定開始采集的時機,即在幀有效信號與行有效信號均有效(即為1)時,采集視頻圖像的有效數據.為了防止視頻模式切換時錯誤視頻數據積累,設計了一種自動檢錯控制器.首先做如下符號定義:
1)視頻模式為 Model[n],其中 n=1,2,…,7;
2)分辨率為 Wn×Hn,其中 n=1,2,…,7;
3)每行采集到的數據為Wcapture;
4)行有效信號為Lsignal.
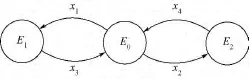
圖1 自動檢錯控制狀態機模型Fig.1 State machine model of automatic error control
自動檢錯控制器初始狀態為E0,事件x1(或x2)發生時進入狀態E1(或E2),并做出相應的控制動態r1(或r2).當r1(或r2)執行結束后,控制器自動回到狀態E0.E1和E2為瞬間狀態,它們隨著控制動作的結束而自動結束.從上述錯誤恢復機制可知,在視頻模式切換時,如果出現數據錯誤,自動檢錯控制會將錯誤控制在一幀數據內,甚至是一行數據內,可有效避免錯誤積累.
1.2 多模式視頻魯棒采集方法
在FPGA平臺上實現視頻采集時的狀態機一般包括4個狀態:IDLE,SAV,CAP和EAV狀態,為了解決不同模式視頻切換過程中出現的數據采集錯誤,保證視頻數據的可靠性,本文在上述4種采集狀態中加入自動檢錯機制,并將本文設計的自動檢錯控制器ERR加入到狀態機.這樣在視頻采集過程可以動態實時地檢測視頻采集的正確性,一旦出現錯誤,可以及時恢復處理,如圖2所示是可靠的視頻采集方法狀態機模型.
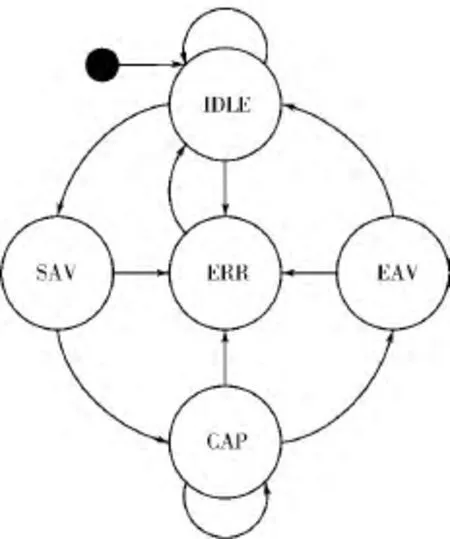
圖2 可靠的視頻采集方法狀態機模型Fig.2 State machine model of robust video capture method
IDLE狀態標示當前處于空閑狀態,當視頻SAV碼到來時,進入SAV狀態.SAV狀態是視頻采集起始狀態,CAP狀態是視頻采集階段,若檢測到視頻結束碼則進入EAV狀態,否則繼續采集視頻.EAV狀態是視頻采集結束狀態,下一步進入IDLE狀態.可靠的視頻采集具體過程如下:
1)在IDLE狀態時,檢測到同步信號到來,檢查后續標志碼校驗位出錯則進入ERR.
2)SAV狀態檢查標志碼不是起始碼,進入ERR.
3)CAP狀態設置采集數據量計數,檢測采集到的視頻數據是否與當前模式視頻數據一致,若有錯誤,則進入ERR,否則繼續采集.
4)EAV狀態檢查標志碼不為結束碼,則進入ERR,否則在EAV狀態完成時,行計數增加,當頂場數據和一幀數據采集結束時,核對行計數值是否符合當前模式的視頻格式,若不符合則進入ERR.
5)ERR狀態即進行自動檢錯控制,當出現標志碼錯誤時,表明視頻同步信號出錯,對采集當前視頻幀數據進行清空處理;當出現視頻數據量不足或超量時,進行相應的補齊和截斷操作.在系統恢復后,由ERR進入IDLE狀態,等待采集新一幀視頻數據.
綜上所述,可靠的視頻采集方法是在原有視頻采集過程基礎上,有效利用視頻同步信號,實時檢測所采集的視頻數據是否符合當前需要處理的視頻模式,一旦出現錯誤,系統能夠及時采取措施恢復正常工作,控制錯誤擴散,避免了錯誤數據積累.
2 高效低功耗色彩空間轉換
根據 ITU-R BT.601 標準,R,G,B 3 個分量分別用8 b 表示,取值范圍為[0,255],并且 R,G,B與 Y,Cb,Cr的關系為

根據式(1),本文對常系數乘法的定義如下:

式中,A為常系數,采用W b的二進制數表示;X為R,G和B中任一個分量的值,采用8 b的無符號二進制數表示;F為乘積,如果乘法運算的結果為完整長度,則F是(8+W)b的二進制.顯然,當直接使用LUT完成乘法運算時,存儲乘積的數據表占用(8+W)·28b,這對于嵌入式系統來說是不能接受的.在RGB到YCbCr轉換時,Y,Cb和Cr的位寬與R,G和B的位寬一致,均采用8 b的二進制無符號數表示.為了減少存儲開銷,引入截斷處理的方法對LUT進行優化設計,提出了一種高低位分離的截斷式LUT乘法器.
2.1 高低位分離的截斷式LUT乘法器設計
由于式(2)中的X位寬為8 b,如果直接建立乘積的查找表,采用8 b輸入,需要28=256個存儲空間,這在一定程度上增加了FPGA的資源消耗.由于大部分FPGA的構造均采用4輸入LUT或6輸入LUT,結合這個特點,本設計采用高低位分離的LUT,將X分為高4b和低4b,分別建立部分乘積的查找表:LUT0和LUT1.這樣設計會增加一次加法運算,但存儲空間變為2×24=32,極大地節約了存儲空間.此外,充分使用FPGA內部的4輸入LUT,避免了資源浪費.因此,式(2)被分解為
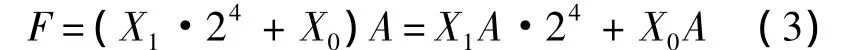
式中X0和X1為4b的二進制數.根據X0和X1的取值不同得到的部分積不同,將部分積的值建立查找表,在進行乘法運算時,根據乘數的值進行查表獲取相應的部分積,再將部分積進行加法運算即可得到乘法的最終乘積.為了進一步節省存儲空間,對LUT中存儲的部分積進行截斷處理.將部分積中幾乎不影響最終乘積的尾數丟棄,具體丟棄策略需要在計算精度和存儲空間之間進行權衡.表1所示為截斷的部分積查找表.

表1 截斷式部分積的LUT(T-LUTn,n=0或1)Table1 LUT based on truncated partial product(T-LUTn,n=0 or 1)
設Fn(n=0或1)分別為查找表T-LUT0和T-LUT1的輸出值,即
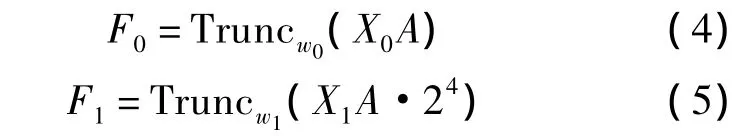
如圖3所示為基于高低位分離的截斷式查找表乘法器結構示意圖,其乘法器輸出乘積FTrunc可表示為
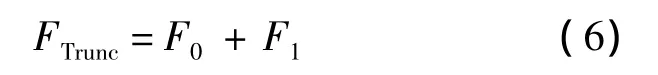
由于對乘法的部分積進行了截斷處理,所以計算結果會存在一定的誤差,其誤差率Erate可表示為式中,F為不使用截斷處理的精確乘積;FTrunc為使用截斷處理的乘積.

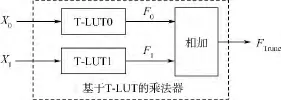
圖3 基于高低位分離的截斷式LUT乘法器結構Fig.3 Truncated LUT multiplier structure based on the separation of high and low bits
由式(7)可知,誤差率是存儲空間和截斷處理的權衡值,截斷處理中丟棄的位數越多,誤差率越高.分析截斷處理的過程,由于最終乘法結果需要一個8 b輸出,在計算過程中所產生的部分積的尾部字節最終都會被丟棄.因此為了節省存儲空間,在建立LUT時就將作用不大的尾部字節丟棄,這樣對最終乘積的影響不大,又能節省LUT的存儲空間.如圖4所示為W b×8 b部分積相加計算過程示意圖.對應上述兩個分離部分積,對最終乘積結果影響較大的是MSP(Most Significant Part)部分,在運算時必須保留.對于 LSP(Least Significant Part)部分,其主要能量集中在LSPmajor部分,因此為了補償由于截斷處理帶來的誤差積累,根據四舍五入的思想,可對LUT中存儲的每一個部分積增加兩位作為差錯補償.根據最終乘積結果,如果LSPmajor<10(二進制),則直接丟棄;如果LSPmajor≥10,則對MSP部分進行加1.因此,進行截斷處理時,根據n的不同,LUT0和LUT1中存儲的部分積位寬分別為w0=6和w1=10.

圖4 Wb×8 b部分積陣列Fig.4 Wb ×8 b partial product array
2.2 高效的RGB到YCbCr空間轉換
為了便于在FPGA平臺上實現RGB到YCbCr轉換,首先對運算中的浮點系數進行定點化處理,然后再采用基于高低位分離的截斷式LUT乘法器完成乘法運算.浮點數進行定點化是通過將浮點數擴大一定的倍數(左移若干位)取整數部分,計算完成后再將結果縮小相應的倍數(右移相應的位)得到最終計算結果.因此確定位移位數要權衡變換后的精度損失和計算量.圖5所示是通過統計的方式將系數乘以相應的擴大倍數完成定點化以后,再右移相應的位數,將結果與原系數計算結果比較獲得的精度損失的柱狀圖,x坐標表示式(1)中的各個常系數,y坐標表示定點化后損失的精度值.

圖5 系數的精度損失比較Fig.5 Comparison of coefficient precision losses
由圖5可知位移14 b時可達到較高精度,與位移15 b相比,精度損失差距很小.考慮到計算復雜度的因素,盡量減少運算的位數,位移位數不宜過多,本文采用位移14 b的方法進行定點化擴展.經過定點化處理后的式(1)可以表示為

由式(8)可知,RGB到YCbCr顏色空間轉換過程中的每個乘法運算都是位寬為8 b的變量與位寬為14 b的常系數相乘獲得中間結果.為了減少精度損失,參照截斷處理策略,在計算時保留兩位進行誤差補償,可將式(8)轉為

以Y為例進行說明,Y可以表示為

式中,A為14 b的常系數;R,G和B的位寬均為8 b;C為常數16.
根據式(3)進行高低位分離,并按表1建立相應的乘法部分積查找表.為了節省存儲空間,對查找表中的部分積進行截斷處理.這樣將乘法操作轉換成查表和加法操作,得到乘積FLUT1,FLUT2和FLUT3,位寬為10 b.在計算FLUT時,需要進行右移2位操作,為了進一步降低誤差,在進行移位操作時,根據四舍五入原則判斷要丟棄2位FLUT[1][0]的值,如果 FLUT[1][0]<10,則對結果影響不大,可以直接移位丟棄;如果 FLUT[1][0]≥10,則 Y的值為
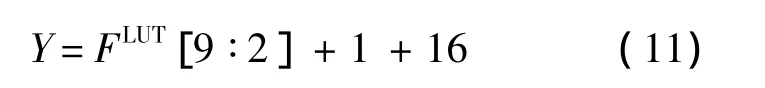
計算Cb和Cr的值時用與計算Y的處理方法相同,這樣不但能實現四舍五入操作,并且避免移位操作,加速計算過程.圖6所示為基于高低位分離的截斷式LUT(T-LUT)浮點乘法結構示意圖.圖7所示為基于T-LUT浮點乘法器的RGB到YCbCr轉換結構示意圖.
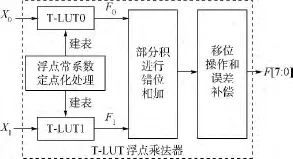
圖6 基于高低位分離的截斷式LUT浮點乘法器結構Fig.6 Truncated LUT float multiplier structure based on the separation of high and low bits
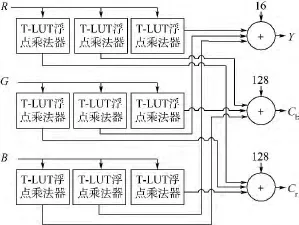
圖7 基于T-LUT浮點乘法器的RGB到YCbCr轉換結構Fig.7 RGB to YCbCrconversion structure based on T-LUT float multiplier
采用查找表方式可以將乘法運算轉換成只有查表和加法運算的操作.在處理過程中,查表操作的速度相對于加法運算會快很多,因此整個處理過程的速度限制在加法運算上.針對運算過程中含有的多次加法運算,本文采用加法流水的方式提高加法運算速度,從而進一步提高顏色空間轉換效率.
3 基于SRIO的高效數據傳輸機制
在FPGA+DSP架構的視頻處理系統中,通常利用FPGA擴展視頻接口并完成視頻預處理任務,利用高性能的通用DSP作為主要運算器件完成復雜的視頻處理功能.FPGA與DSP間的高速視頻數據的互連傳輸是系統正常工作的基本前提.SRIO(Serial Rapid I/O)總線作為一種高可靠、高效能和具有良好擴展性的開放總線標準,已經成為高性能嵌入式系統中高速互連的主要傳輸方式之一.本文采用SRIO作為數據傳輸的高速鏈路,SRIO協議中規定了多種事務類型,它們可以分為兩種數據傳輸方式:直接IO/DMA(direct IO/Direct Memory Access)傳輸方式和消息傳遞.直接IO/DMA傳輸方式速度較快,支持本地器件通過SRIO協議讀寫對端器件的存儲器,但是本地器件需要知道對端存儲結構,同時需要考慮存儲器讀寫同步;消息傳遞不需要知道對端器件存儲結構,只需知道對端ID和郵箱號就可以完成數據傳輸.
為實現SRIO高速傳輸,降低DSP的SRIO傳輸負擔,本設計使用FPGA通過直接I/O傳輸方式完成SRIO總線上所有視頻數據的收發工作,采用消息傳遞方式完成FPGA與DSP同步.如圖8所示為以FPGA為控制核心的數據交互機制示意圖.FPGA為SRIO傳輸控制核心,這樣設計的優勢是DSP基本不需要參與SRIO傳輸控制工作,SRIO視頻數據傳輸過程對DSP基本透明,DSP可以專注于視頻處理計算.

圖8 以FPGA為控制核心的數據交互機制Fig.8 Data exchange mechanism based on FPGA control
當原始視頻數據由FPGA傳入DSP時,FPGA通過SWRITE事務發送所有數據,SWRITE事務通過SRIO總線能夠實現對DSP的DDR3存儲器直接寫操作,寫操作過程對DSP核完全透明.考慮到存儲讀寫同步,要求此過程中DSP禁止訪問該視頻數據緩沖區.在DDR3中視頻數據寫滿一幀后,通過DOORBELL事務通知DSP,解除該存儲區域訪問鎖;當視頻碼流由DSP傳入FPGA時,FPGA通過NREAD事務請求讀取處理后的視頻碼流數據,DSP的SRIO硬件接口直接讀取DDR3對應存儲位置,組織NREAD響應事務包,發送處理后視頻數據到FPGA,此過程對DSP核完全透明.為實現存儲讀寫同步,DSP在完成一幀視頻數據壓縮處理后,向FPGA發送一個控制包通知FPGA回收該幀的壓縮碼流.控制包的格式如圖9所示,包括包序號、數據存儲地址和數據長度.其中包序號用1 b表示,相鄰的兩個包序號采用0或1表示,以示區別,數據存儲地址根據SRIO協議規范采用34b表示;數據長度根據一幀數據壓縮后的碼流量采用32 b表示.

圖9 控制包格式Fig.9 Format of control packet
綜上所述,以FPGA為控制核心的SRIO傳輸過程,一方面可以減少DSP在SRIO傳輸過程中的時間開銷,使DSP可以專注于視頻處理過程,降低編碼延時;另一方面,簡化本系統支持的SRIO事務種類,只使用3種SRIO事務完成視頻數據傳輸過程,節約FPGA邏輯資源,有助于提高SRIO傳輸速度.
4 實驗與分析
如圖10所示為FPGA+DSP架構的機載視頻采集及預處理結構示意圖,其主要功能單元包括視頻采集、顏色空間轉換和視頻數據交互傳輸.FPGA作為協同處理器承擔著關鍵的紐帶作用,其中的一個主要任務是快速地從機載記錄儀獲取多模式原始視頻圖像數據,實時完成色彩空間轉換后傳入DSP進行壓縮處理.
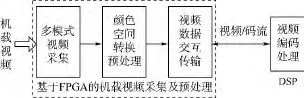
圖10 機載視頻采集及預處理結構Fig.10 Structure of airborne video capture and preprocessing
為了評估本文方法的有效性,FPGA平臺選用 Xilinx公司的 XC5VSX50T-1ff665,采用 SRIO接口與DSP建立數據傳輸通路.使用Verlog硬件描述語言在FPGA平臺上實現本文設計的方法,首先驗證視頻采集和預處理的正確性和性能,然后針對預處理后的數據完成高速傳輸測試.
4.1 視頻采集及預處理測試
為測試設計中視頻采集方法的可靠性,分別使用和不使用自動錯誤檢錯機制的方法進行測試,在視頻模式不斷切換過程中,觀察采集的視頻圖像正確性.經實驗測試,使用自動錯誤檢錯機制的方法可以正確采集視頻數據,而不使用自動檢錯機制時,采集的視頻容易出現錯誤積累,引起視頻錯位.如圖11所示為實驗比較圖(分辨率為720像素×576像素).

圖11 視頻采集的實驗比較圖Fig.11 Comparison of video capture experiment
實驗表明,本文提出的可靠的視頻采集方法利用視頻同步信號自動檢查視頻數據量是否正確,能夠在視頻數據丟失或中斷后及時恢復,將錯位數據控制在一幀甚至一行視頻內,避免產生錯誤累計,提高了視頻源的可靠性.
為測試顏色空間轉換的有效性,分別實現了本文方法、直接法、文獻[16]的方法和文獻[17]的方法.當用直接法實現時,在計算前應將浮點數定點化,并且在計算過程中不使用DSP48進行運算;對于文獻[16]和文獻[17]的方法,編譯環境的配置和程序實現分別參考對應的文獻.對于本文提出的方法,為了節省FPGA上的運算資源,也不使用DSP48.表2比較了在相同條件下4種方法的資源消耗和性能測試結果.
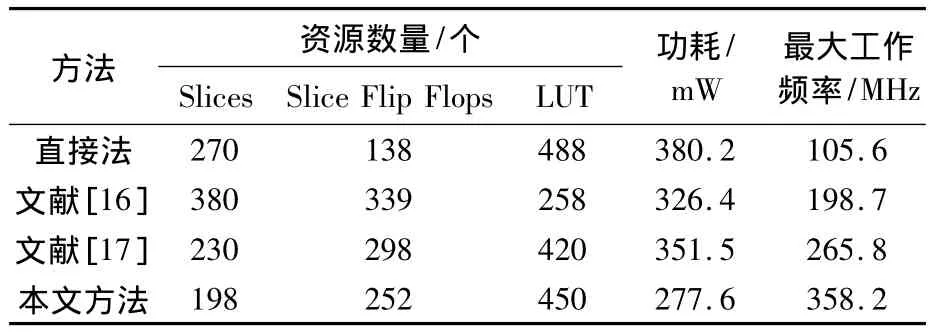
表2 資源消耗及性能比較結果Table2 Resource consumption and performance comparison results
由表2可知,與直接法相比,本文方法最大工作頻率為358.2 MHz,是直接法的3.5倍,證明該方法能顯著提高轉換速度.之所以本文方法使用了較多的Slice Flip Flops,是因為流水線技術占用FPGA上較多的寄存器.文獻[16]和文獻[17]的方法節省了LUT,但是使用了更多的 Slices和Slice Flip Flops.FPGA中具有較多的LUT資源,本文提出的方法使用了略多的LUT資源,獲得了更高的頻率.并且本文方法采用基于截斷處理建立的LUT,減少了存儲空間和計算位寬,因此降低了電路的動態功耗.實驗證明本文方法的功耗比其他幾種方法減少了15% ~27%.圖12所示為實驗性能比較圖.

圖12 性能比較Fig.12 Performance comparison
因為在截斷處理的過程中,丟棄的是對結果影響最小的尾數,并且采用誤差補償機制減小了誤差,因此本文提出的方法幾乎不影響計算結果的精度.圖13顯示了平均誤差補償的結果.
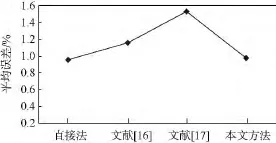
圖13 平均誤差比較Fig.13 Comparison of mean error
4.2 高效的數據傳輸測試
根據目前機載視頻處理系統的需求,通過FPGA采集和預處理后需要傳入DSP的原始視頻最大數據率小于500 Mb/s,因此設置FPGA與DSP之間SRIO通路為1.25 Gb/s工作模式.
測試FPGA通過SRIO的SWRITE(流寫)事務向DSP傳輸數據,并存儲到DDR3.SWRITE事務包頭信息極短,有效數據打包率高于NWRITE(普通寫)等其他事務.SRIO協議規定每個事務包最大有效數據載荷為256 B,因此使用攜帶256 B數據的SWRITE事務可以實現最高速率的SRIO傳輸過程.在1.25 Gb/s模式下,由于8b/10b編解碼SRIO數據傳輸率為1 Gb/s,SWRITE事務打包率為95%,此時SRIO理論最高有效數據傳輸速率為950Mb/s.經過實驗測試,使用本文方法其數據發送速率可達880 Mb/s,達到理論值傳輸速率93%,完全可以滿足系統需要的最大數據傳輸率.
測試FPGA通過SRIO讀取DDR3速率和正確性,在1 s內FPGA向DSP連續發送NREAD請求事務,在FPGA端接收NREAD響應事務,檢查收到數據正確性并記錄收到數據包數量,測試結果為812 Mb/s,達到理論值傳輸速率90%,數據正確無誤.
以XC5VSX50T-1ff665型FPGA為目標器件,本文方法能夠完成FPGA與DSP的SRIO自動收發;SRIO例程沒有實際應用價值,只提供了利用ChipScope工具手動發送SRIO事務功能.如表3所示測試統計本文實現SRIO方法和SRIO例程邏輯資源使用情況.
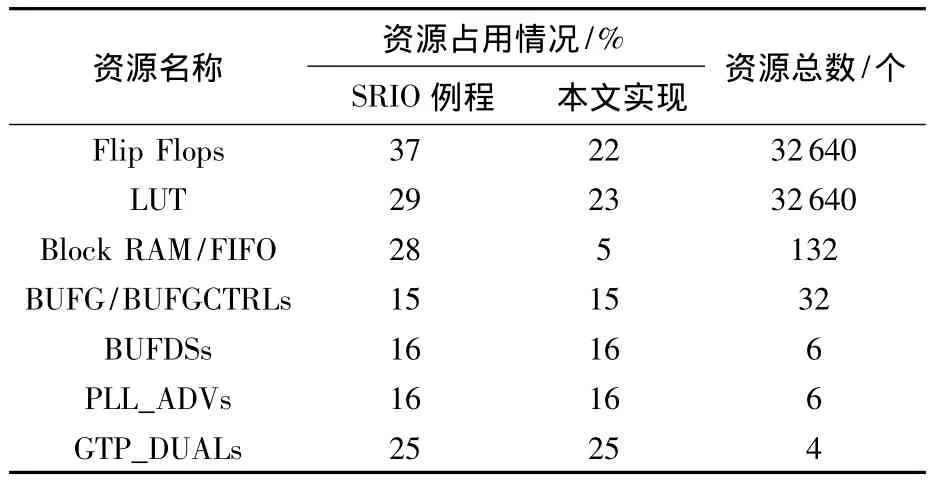
表3 SRIO資源占用情況統計Table3 SRIO resource occupancy statistics
對比資源使用情況可知:
1)本文方法占用較少Flip Flops和LUT資源.Flip Flops反映芯片寄存器資源,LUT是FPGA實現邏輯運算的查找表.本文簡化SRIO事務實現,保留了常用的 SWRITE,NREAD及 DOORBELL事務,刪除不常用的SRIO原子事務操作,同時簡化了SRIO地址計算過程和存儲數據過程;SRIO例程支持所有事務類型,存儲過程和地址計算過程復雜,同時ChipScope核也占用較多資源.
2)本方法占用較少Block RAM/FIFO資源.根據視頻傳輸特點,本文采用以行為單位的收發緩存隊列,大小僅為6個視頻行,大大降低FPGA上需要的緩存數據量;同時采用收發緩存隊列結構實現數據緩存,相比SRIO例程中使用的雙端口RAM控制簡單、實現方便,可靠性更高.
3)其他資源占用一致.BUF主要用于SRIO高頻輸入時鐘和數據緩存;PLL_ADVs用于SRIO高頻時鐘網絡減少抖動;GTP_DUALs是FPGA集成的高速收發器,實現SRIO硬件接口.
綜上所述,本文結合視頻傳輸特點,在占用較少邏輯資源情況下,設計實現了FPGA與DSP間SRIO的高速互連,數據傳輸速率達到理論值90%以上.
5 結論
本文針對機載視頻采集及預處理系統中的關鍵功能單元從可靠性、高效性角度進行了研究,主要包括:
1)設計了一種可靠的多模式機載視頻采集方法,通過增加自動檢錯機制,有效避免了采集錯誤的積累.
2)針對顏色空間轉換中浮點運算占用資源多,功耗大的問題,設計了一種基于高低位分離的截斷式LUT乘法器,并實現了一種高效低功耗的顏色空間轉換方法,提高了系統性能.
3)采用SRIO數據傳輸協議在FPGA與高性能DSP之間設計了一種由FPGA為控制中心的高效數據交互策略,可以減少DSP在數據傳輸過程中的資源開銷,使其更加專注于視頻處理,提高系統性能.
此外,本文設計的方法已經成功應用于機載視頻壓縮系統中,取得了良好的效果.
References)
[1] Blair J B,Rabine D,Wakeet S.et al.High-altitude laser altimetry from the global hawk UAV for regional mapping of surface topography[C]//AGU Fall Meeting Abstracts.San Francisco:AGU,2012:885.
[2] Adams S M,Levitan M L,Friedland C J.High resolution imagery collection utilizing unmanned aerial vehicles(UAVs)for postdisasterstudies[J].Bridges,2014(10):1143879634-1143879667.
[3] Saffar S,Abdullah A.Vibration amplitude and induced temperature limitation of high power air-borne ultrasonic transducers[J].Ultrasonics,2014:54(1):168-176.
[4] Wang D Y,Tao X H,Hu R.The design of the interface for camera link and DM642[C]//Control and Decision Conference.New York:IEEE,2010:2914-2916.
[5] 賈建祿,王建立,郭爽,等.基于Camera Link的高速圖像采集處理器[J].液晶與顯示,2010,25(6):914-918.Jia J L,Wang J L Guo S,et al.High speed image grabber and processor based on Camera Link[J].Chinese Journal of Liquid Crystals and Displays,2010,25(6):914-918(in Chinese).
[6] Singh S K,Kumar S.Novel adaptive color space transform and application to image compression[J].Signal Processing:Image Communication,2011,26(10):662-672.
[7] Li S A,Chen C Y,Chen C H.Design of a shift-and-add based hardware accelerator for color space conversion[J].Journal of Real-Time Image Processing,2013,9:1-14.
[8] Liu Z G,Du S Y,Yang Y,et al.A fast algorithm for color space conversion and rounding error analysis based on fixed-point digital signal processors[J].Computers & Electrical Engineering,2014,40(4):1405-1414.
[9] Meher B K,Meher P K.A new look-up table approach for highspeed finite field multiplication[C]//2011 International Symposium on Electronic System Design.New York:IEEE,2011:51-55.
[10] Meher P K.LUT optimization for memory-based computation[J].IEEE Transactions on Circuits and Systems II:Express Briefs,2010,57(4):285-289.
[11] Meher P K.New approach to look-up-table design and memorybased realization of FIR digital filte[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2010,57(3):592-603.
[12] Meher P K.New look-up-table optimizations for memory-based multiplication[C]//Proceedings of the 12th International Symposium on Integrated Circuits.New York:IEEE,2009:663-666.
[13] Kuang S R,Wu K Y,Yu K K.Energy-efficient multiple-precision floating-point multiplier for embedded applications[J].Journal of Signal Processing Systems,2013,72(1):43-55.
[14] Eswari S.Design of low error and power fixed width multiplier by using compensation function[J].International Journal of Engineering Research and Technology,2013,7(2):755-760.
[15] Balamurugan S,Srirangaswamy B,Marimuthu R,et al.FPGA design and implementation of truncated multipliers using bypassing technique[C]//Proceedings of the International Conference on Advances in Computing,Communications and Informatics.Berlin:ACM,2012:1111-1117.
[16] Xue J,Cao X.Color space conversion based on FPGA[C]//IEEE International Conference on Computer Science and Automation Engineering.New York:IEEE,2012:422-425.
[17] Yang Y,Peng Y H,Liu Z G.A fast algorithm for YCbCr to RGB conversion[J].IEEE Transactions on Consumer Electronics,2007,53(4):1490-1493.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
