遺傳算法及其在非線性方程組求解中的應用研究
2015-11-17 07:25:54王愛華
西華師范大學學報(自然科學版) 2015年2期
王愛華
(南充職業技術學院,四川 南充 637131)
1 引 言
電子信息技術和網絡技術飛速發展,其相關學科交叉所形成的數學模型中非線性方程組問題日益增多,其重心可歸結為各種非線性方程組的求解問題.目前,關于求解非線性方程組的相關理論和方法已較成熟,但對于求解方法的有效性研究卻不夠深入.主要原因在于計算上所具有的復雜性容易導致求解結果陷入局部最優.本文討論了如何改進遺傳算法以及如何利用改進后的遺傳算法求解非線性方程組.
2 遺傳算法及其改進
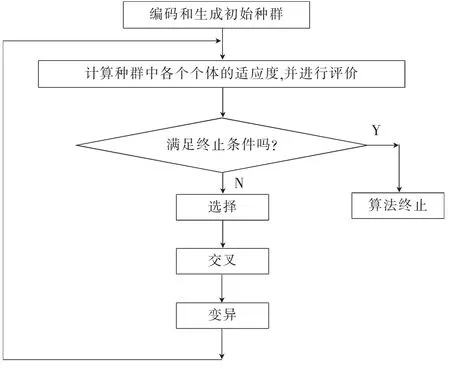
圖1 基本遺傳算法流程圖Fig.1 Flow chart of basic genetic algorithm
2.1 遺傳算法的算法流程
遺傳算法是通過模擬個體組成群體的整體狀況,進行選擇、交叉和變異等操作,以選取搜索空間中的最優解. 其算法過程及流程圖(圖1)分別如下:
a)設置種群的最大進化代數T 和遺傳操作算子,然后隨機生成初始種群p(0);
b)對種群p(t)中每個個體進行適應度評價,并計算種群的平均適應度;
c)根據優勝劣汰,選擇保留優秀個體,淘汰種群中適應度較低的個體;
d)為生成新的個體,依據選擇概率,將種群之間進行交叉運算;
e)對新個體進行交叉、變異操作,計算下一代種群p(t+1);
f)對t、T 進行比較,若t >T 或等于設置精度,則這一代為最優個體,計算終止;若t≤T,則t→t+1,從第b)步繼續計算.
2.2 遺傳算法的收斂性
評價迭代算法性能的重要指標是收斂性和收斂速度,目前基本上都是用標準遺傳算法(又稱S 遺傳算法)模型[1]來分析遺傳算法收斂性的各種結論.
設f(Sk*)=max{f(s(1,k),s(2,k),…,s(n,k))}是第k 次進化迭代時群體{s(j,k)}中的最大適應度值為此時的群體最優串(若,則令,否則(s(1),s(2),…,S(n))}是遺傳算法所求問題的全局最大適應度值,全局最優串(其中為有效基因,若在某處基因位上,群體中所有串中不存在該基因位的有效基因,則稱群體有效基因缺失[1]).則當且僅當=1 成立時,稱遺傳算法是概率性全局收斂的.其中為的概率.
現已證明,如果在進化迭代過程中,遺傳算法在保留最優串的情況下隨機地以雜交和變異搜索算子,全局優化問題可通過遺傳算法持續對空間進行搜索來完成,全局最優解將通過1 為概率找到,該結論稱為遺傳算法的極限分析定理[2].
2.3 遺傳算法的不足
遺傳算法雖然具有較好的全局搜索能力,但也存在不足:一是遺傳算法的全局收斂性理論基礎是二進制編碼,對于其他編碼方式還無有效證明;二是遺傳算法對搜索空間進行持續搜索時,可能出現多峰優化問題,獲得的最優解不一定是全局最優解,這時將重新選擇此類其他基因,導致有效基因缺失,出現早熟收斂現象.
2.4 遺傳算法的改進
2.4.1 采用浮點數編碼方式 浮點數編碼能改善由二進制編碼造成的如準確度低、計算時間長、計算量大等一系列問題.在計算機中任意某個實數可近似表示為:一個整數或定點數(即尾數)乘以某個基數(計算機中通常以2 為基數)的整數次冪[3].在計算機內,浮點數可表示為如下格式:

Ms 表示數的符號位,0、1 分別表示正、負號;M 表示數的尾數部分,采用定點小數形式表示,可用原碼(或補碼)等編碼方式.
利用浮點數編碼一方面可以擴大搜索范圍,降低算法的復雜性,提高運算效率;另一方面可以結合其他優化方式,提高求解精度.
2.4.2 確定恰當的適應度函數 適應度函數值(遺傳算法中非負)的大小決定了遺傳算法的收斂效率、找到最優解的能力以及被遺傳到下一代的概率.
在許多實際問題中,往往需要求最小費用,這時可將求最小目標根據適應度函數非負原則轉換為求最大目標的形式,變換關系式為:

式(1)中,f(m)為適應度函數,g(m)為目標函數,m 為模型參數,Cmax為一個待定的、合適的且相對較大的實數.選擇Cmax方式有:事先指定的一個較大(小)的數;進化到當代為止的最大(小)目標函數值;當代或最近幾代群體中的最大(小)目標函數值[4].
此外,因遺傳算法還存在另一些問題,比如對參數選擇敏感、進化過程中早熟收斂而后期收斂停滯等.這時又可通過另一種變換(Goldberg 線性比例變換)來解決,變換公式為:

f(x)、g(x)分別為變換前后的適應度函數值.
根據概率式轉移規則,由種群中各個體的適應度大小確定下一步搜索方向.事實上,使用(1)和(2)式計算所得出的個體適應度值,不會讓所有問題結果收斂速度一致,需要降低較高的個體適應度值克服早熟,增加較低的個體適應度值避免后期停滯[5].
2.4.3 搜索遺傳算子 遺傳算子主要有三種類型:復制算子(reproduction)、雜交算子(crossover)和變異算子(mutation)[6],因為遺傳算法是通過一系列的遺傳算子來進行的,所以搜索遺傳算子有較重要的作用,步驟如下:
第一步:選擇算子
采用的選擇概率計算方式為:

其中n 為種群大小,i 為個體排序序號,η+∈[1,2],η-=2 -η+.
遺傳算法在選擇時容易出現個別個體在種群中迅速繁殖,個體適應度彼此非常接近,搜索不能有效進行.這時可采用變換適應度函數尺度大小的方法來解決,即令:

第二步:交叉算子
遺傳算法中的交叉操作體現了信息交換的思想,即子代包含了父代的信息特征.交叉算子是一種進化計算,通過它可生成基因更加優良的個體.交叉算子的設計和實現要求在產生優良的新個體情況下又不能破壞表現優良的編碼串模式.在交叉時要注意,必須嚴格控制好交叉概率,交叉概率過大可能破壞遺傳模式,交叉概率過小則不易產生新個體.
第三步:變異算子
變異算子的作用是通過調整個體編碼中的部分基因值大小來改善遺傳算法的局部搜索能力,讓從局部出發搜索所得的個體最大程度地逼近最優解.同時,算子因基因值的新舊替換而得到變異,改變了個體編碼串的結構,保持了種群的多樣性,防止早熟[5].
3 基于改進后的遺傳算法對于非線性方程組的求解
3.1 非線性方程組的定義
非線性方程組是關于n 個變量的n 個方程,一般形式為:

3.2 非線性方程組的兩種求解方法
3.2.1 非數值算法 以往對非線性方程組的求解,所選擇的算法在計算時比較復雜.如:Newton 法、直線迭代法等.運用等價思想,將非線性方程組的求解轉為函數優化問題,如下式:

其中Φ 為方程組解的區間,并且當F(X)取最大值1 時,對應的為非線性方程組的解,其具體解法筆者在此不再作贅述.
3.2.2 爬山算法[7]爬山搜索是向值增加的方向持續移動的簡單循環過程——登高(從單獨的當前一個狀態出發,移動到與之相鄰的狀態(見圖2)).它將會在達到一個“頂峰”(相鄰狀態中沒有比它更高的值)時終止.爬山搜索是局部最優搜索,適合于最優化問題.

圖2 最優化問題Fig.2 Optimization problem
爬山搜索法趨于在得出解答前減少需訪問的節點數,因此適用于很多場合.但是,它可能存在三種弊病.一是虛假山峰的問題,此時搜索求解將涉及到大量的回溯;二是“平穩地帶”問題,此時所有可能的下一步搜索的好壞程度都一樣,那么爬山法就不如深度優先搜索法好;三是“山脊”問題,運算時在回溯中將數次越過山脊,爬山算法無效.
3.3 用改進后的遺傳算法求解非線性方程組的可行性分析
可見,遺傳算法局部搜索能力較差且存在“早熟”現象,爬山算法又難以對全局進行求解.如果綜合爬山算法和遺傳算法的優缺點,既可避免爬山算法的缺點,又可提高遺傳算法的局部搜索能力,將使求解非線性方程組問題得到有效解決.
3.4 用改進后的遺傳算法求解非線性方程組的具體步驟
根據以上分析,用改進后的遺傳算法求解非線性方程組的執行步驟可總結如下:
(1)將非線性方程組問題轉化為函數優化問題求解;
(2)確定策略變量、定求解空間、交叉、變異概率等,并設置變量上下限;
(3)確定編碼方式;
(4)計算第一代種群適應度,確定個體的優劣狀況;
(5)對種群進行尋優,結合跨世代精英選擇策略和錦標賽選擇法進行選擇操作;
(6)根據自適應交叉、自適應變異概率及自適應爬山算子進行交叉操作、非均勻變異操作作局部搜索;
(7)尋找最優個體,并進行判斷,確定非線性方程組的最優解.
4 結束語
綜上,通過采用浮點數編碼方式、確定恰當的適應度函數及搜索遺傳算子等三個方面可對遺傳算法進行改進.用改進后的遺傳算法求解非線性方程組,將改觀遺傳算法的全局收斂和爬山算法的局部收斂現象,有效降低求解非線性方程組的復雜度,提高解的準確度.
[1] 李 楠.考慮完整交易費用組合投資模型的混合遺傳算法求解[D]. 天津大學碩士論文,2005.
[2] 王學鳳.金盆水庫優化調度研究[D].西安理工大學碩士論文,2003.
[3] 劉正紅.浮點數的教學難點及對策[J].網友世界,2012(16):231 -233.
[4] 蔡松柏,沈蒲生.關于非線性方程組求解技術[J].湖南大學學報(自然科學版),2011,27(3):189 -192
[5] 任文杰.人工神經網絡在地基土液化判別及等級評價中的應用[D].河北工業大學碩士論文,2002.
[6] 黃海濱.遺傳算法中遺傳算子的分析[J].玉林師范學院學報,2001(09):25 -27.
[7] 張慶雅.楊火箭發動機法蘭連接系統模糊可靠性分析[D].西北工業大學博士論文,2003.
