基于FP樹的極大頻繁項集的挖掘方法
2015-09-28 01:01:54石芹芹
現代計算機 2015年36期
石芹芹
(四川大學計算機學院,成都 610065)
基于FP樹的極大頻繁項集的挖掘方法
石芹芹
(四川大學計算機學院,成都610065)
0 引言
數據挖掘是20世紀90年代興起的一項新技術,是知識發現的關鍵步驟。數據挖掘是多門學科和多門技術相結合的產物,是指從數據庫中抽取隱含的、潛在的、先前未知的、有用的信息(如知識、規則、約束和規律等)的一個非平凡過程[1]。其中挖掘關聯規則是一個非常重要的研究內容,而挖掘頻繁項集是研究關聯規則的基本和關鍵步驟。頻繁項集導致發現大型事務或關系數據集中項之間有趣的關聯或相關性,發現的這些相關聯系,可以為分類設計、交叉銷售和顧客購買習慣分析等許多商務決策過程提供幫助,故受到業界人士的青睞。然而從大型數據集中挖掘頻繁項集是具有很大的挑戰性的,因為對每一個k維的頻繁項集個頻繁1項集個頻繁2項集因此頻繁項集總共為個,項集個數太大。而極大頻繁項集隱含了頻繁項集的信息,因此近些年對極大頻繁項集的研究也越來越多。
目前,極大頻繁項集挖掘算法主要是基于Apriori 和FP-tree的改良和衍生算法。基于Apriori的有maxminer、pincer-search、Mafia、GenMax等,基于FP-tree的有Fpmax、IDMFIA、FPMFI等2。由于訪問內存中的數據比訪問外存磁盤中相同大小的數據快五六個數量級,上述這些算法至少需要兩次外存數據庫掃描,其數據結構表達形式也主要是枚舉樹、字典樹和頻繁模式樹(FP-tree)等樹形結構,結構較單一。
1 相關定義
定義1設τ={I1,I2,…,Im}是項的集合,設任務相關的數據D是數據庫事務的集合,其中每個事務T是一個非空項集(項的集合稱為項集),使得T?τ。每一個事務T都有一個標識符,成為TID。設A是一個項集,當A?T時,則稱事務T包含A。
定義2形如A?B(其中A?τ,B?τ,A≠?,B≠?,且A∩B≠?)的蘊含式叫關聯規則。
定義3在事務D中規則A?B成立,則把D中事務包含A∪B的百分比叫做支持度(有時也稱為相對支持度),記為s,即support(A?B)=P(A∪B)。
定義4在事務D中規則A?B成立,則把D中事務包含A∩B(包含A的事務也同時包含B)的百分比叫做置信度,記為c,即confidence(A?B)=P(B|A)。
定義5同時滿足最小支持度閾值(min_sup)和最小置信度閾值(min_conf)的規則成為強規則。
定義6包含項集的事務數稱為項集的出現頻度,簡稱為項集的頻度、支持度計數或計數,該支持度是絕對支持度。
定義7如果項集I的相對支持度滿足預定義的最小支持度閾值 (即I的絕對支持度滿足對應的最小支持度計數閾值),則I是頻繁項集。頻繁k項集的集合記為Lk。
定義8項集X是事務D中的頻繁項集,且不存在超項集Y使得X?Y且Y在D中也是頻繁的,則稱X是極大頻繁項集。
2 頻繁項集挖掘的兩大經典算法
Apriori算法是在1994年由Agrawal和R.Srikant提出的一種為布爾關聯規則挖掘頻繁項集原創性算法。它使用逐層搜索的迭代方法,其中k項集用于探索(k+1)項集,其算法思想是:第一遍掃描數據庫,累計每個項的計數,并收集滿足最小支持度的項,得到頻繁1項集的集合,記為L1,第二遍掃描數據庫,通過L1找出頻繁2項集的集合L2,然后每一遍掃描數據庫,都通過Lk-1找出LK,直到不能找到頻繁K項集。在通過Lk-1找出LK時,根據先驗性質進行剪枝。
頻繁模式增長(Frequent-Pattern Growth),稱為FP算法,該算法采用分治策略,發現頻繁模式而不產生候選。其算法思想是:先將代表頻繁項集的數據庫壓縮到一顆頻繁模式樹(FP-tree)中,該樹能保留項集的關聯信息。再把壓縮后的數據庫劃分成一組條件數據庫,使每一個數據庫關聯一個頻繁項或者“模式段”,并分別挖掘每個條件數據庫。該算法分兩部分,第一部分是構造FP樹,先創建樹的根節點,第二遍掃描數據庫D,對每個事務中的項按遞減支持度計數排序,為其創建一個分枝,如果當前分枝與樹的已有分枝有共同路徑,則共享路徑前綴;第二部分是挖掘FP樹,由長度為1的頻繁模式(初始后綴模式)開始,構造它的條件模式基,然后構造它的條件FP樹,并遞歸地在該樹上進行挖掘。
兩大算法中Apriori算法的候選產生-檢查方法顯著壓縮了候選項集的規模,能產生很好的性能,卻仍可能需要產生大量的候選項集,過程中需要重復地掃描整個數據庫,因此挖掘出全部的頻繁項集需要花費較昂貴的代價。FP-growth算法將發現長頻繁模式的問題轉換成在較小的條件數據庫中遞歸地搜索一些較短模式,顯著地降低了搜索開銷,但當數據庫很大時,構造基于主存的FP樹有時是不現實的。
3 基于FP樹的極大頻繁項集的挖掘方法
我們看到,頻繁模式挖掘可能產生大量的頻繁項集,特別是當最小支持度閾值設置較小或者數據集中存在長模式時尤其如此。而實際中,有的時候只需要挖掘出極大頻繁模式的集合,而不是所有頻繁模式的集合。
在一個新的頻繁項集導出之后,要對其進行超集檢查和子集檢查,檢查新發現的項集是否是某個已經發現的、極大項集的子集。這些檢查可以在構建FP樹時完成。
算法思路:(1)先掃描一遍數據庫,導出頻繁1項集的集合,并按照它們的支持度計數降序排列;(2)構建極大頻繁項集候選集列表,第二遍掃描數據庫,構造FP-tree,在對每個事務創建分支時,若當前事務的分支與已存在的事務分支完全重合,則說明該事務是已發現的極大頻繁項集的子集,不應被導出,否則存入候選集列表中。
算法:基于FP樹的挖掘極大頻繁項集的算法輸入:DB:事務數據庫;msup:最小支持度閾值輸出:極大頻繁項集的完全集M步驟構造極大頻繁項集的FP樹
①掃描事務數據庫DB一次,導出滿足msup的頻繁項集合,保存它們的支持度計數,并按支持度計數降序排列,得到頻繁項列表L,L中每項包括item-name、count;
②創建FP樹tree的根節點 “null”。每個節點有parent,child,item-name,count屬性;
③創建極大頻繁項候選列表M,初始為空;
④CreatTree(){
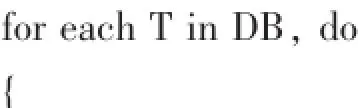
排序Ti中的項,得到Ti的頻繁項列表為[p|P];//如果Ti在M表中沒有共享前綴,按照L的次序排列,反之按M中的順序排列;p是第一個項元素,P是剩余項元素
If each p in Ti is in Mi;//如果當前事務T所有項集已在M中出現,那么此不是極大頻繁項集候選,刪除該事務集中的所有項

4 算法應用結果
假設某商店的事務數據如下表,最小支持度閾值msup=2。
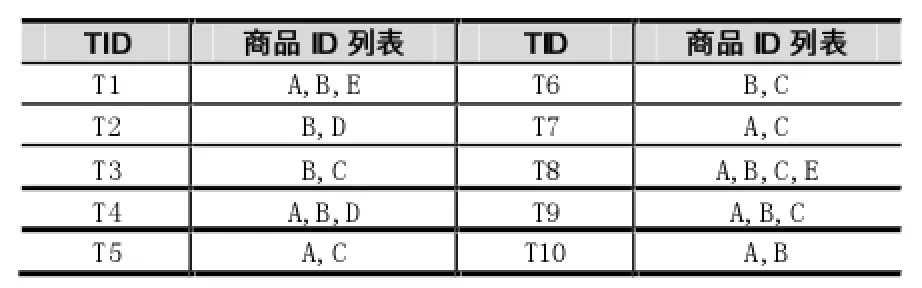
表1 某商店的事務數據
全局頻繁1項集組成的集合是L1={A,B,C,D,E},排序之后得到的L為{B:8,A:7,C:6,D:2,E:2},M={}。根據L構建的頻繁樹如圖1所示,該樹并沒有將非頻繁的項集剪枝,極大項集完全集M構建過程如表2所示。
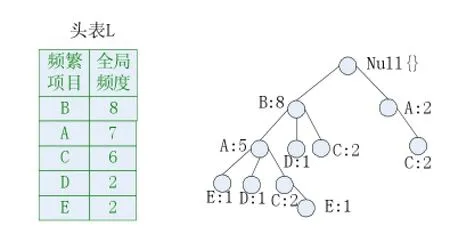
圖1 頻繁模式樹FP-tree
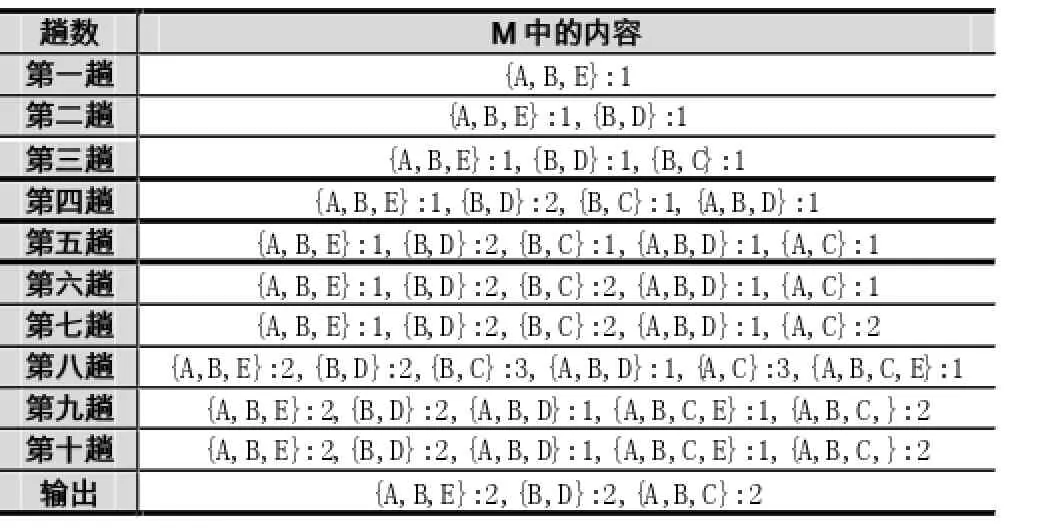
表2 極大頻繁項集候選每趟讀取事務之后的結果
5 結語
該算法基于FP樹,通過增加極大頻繁項集候選列表M,能夠準確地從事務數據庫中挖掘出所有的最大頻繁項集,在每趟讀取事務項時,如果已被候選表中的項集包含,則不需要再記錄該頻繁項集,從而節省了時間,而最后得到的候選表M就是極大頻繁項集的集合。因候選表M是存在于內存中,故計算機內存大小對該算法有一定限制,在事務數據量不大時效果較好,但在事務數據量龐大時該算法不太理想。
[1]張德干,王曉曄.規則挖掘技術[M].北京:科學出版社,2008:2.
[2]王黎明,趙輝.基于FP樹的全局最大頻繁項集挖掘算法[J].計算機研究與發展,2007:445-451.
[3]何波.基于FP-tree的快速挖掘全局最大頻繁項集算法[J].計算機集成制造系統,2011-07:1547-1552.
[4]任永功,張亮,付玉.一種基于頻繁模式樹的最大頻繁項目集挖掘算法[J].小型微型計算機系統,2010:317-321.
[5]Jiangwen Han,Micheline Kamber,Jian Pei.Data Mining Concepts and Techniques Third Edition[M].北京:機械工業出版社,2012.7.
[6]阮幼林,李慶華,楊世達.一種基于事務樹的快速頻繁項集挖掘與更新算法[J].計算機科學,2005:2-5.
[7]崔海莉,袁兆山.一種快速發現最大頻繁項集的挖掘算法[J].合肥工業大學學報(自然科學版),2006:11-16.
[8]張忠平,鄭為夷.基于事務樹的最大頻繁項集挖掘算法[J].計算機工程,2009:97-100.
[9]宋晶晶,姜保慶,關麗霞.在單向FP-tree上挖掘最大頻繁項集[J].現代計算機,2010:19-25.
Maximal Frequent Itemsets;FP-tree;Association Rules
Maximum Frequent Itemsets Mining Method Based on FP-tree SHI Qin-qin
(College of Computer Science,Sichuan University,Chengdu 610065)
1007-1423(2015)36-0007-04
10.3969/j.issn.1007-1423.2015.36.002
石芹芹(1990-),女,四川蓬溪人,碩士,碩士研究生,研究方向為圖像處理與合成、數據挖掘
2015-11-17
2015-12-10
提出一種基于FP樹的極大頻繁項集的挖掘算法,該算法在構建FP樹的過程中,通過子項集剪枝的方法,將挖掘到的極大頻繁項集存儲起來,從而節省再次挖掘FP樹的時間,較已有的算法在挖掘極大頻繁項集時簡化挖掘過程。該算法的提出,為關聯規則的精簡提供新的解決辦法。
極大頻繁項集;FP樹;關聯規則
Proposes an algorithm for mining maximum frequent itemsets based on frequent pattern tree.The algorithm is an algorithm in the process of building FP-tree by pruning children-set and storing maximum frequent itemsets,thereby saves time mining again FP-tree than existing algorithms during mining Maximum frequent itemsets.It is a new algorithm to search association rules.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
