面向XBRL的DC-Apriori挖掘算法研究
2015-09-27 02:35:30曾志勇閆亞麗
現代計算機 2015年26期
曾志勇,閆亞麗
(1.云南財經大學信息管理中心,昆明 650221;2.云南財經大學信息學院,昆明 650221)
面向XBRL的DC-Apriori挖掘算法研究
曾志勇1,閆亞麗2
(1.云南財經大學信息管理中心,昆明650221;2.云南財經大學信息學院,昆明650221)
0 引言
XBRL是一種網絡報告語言,全稱為eXtensible Business Reporting Language,它融合了計算機技術與企業財務會計準則,該語言是在XML語言基礎上擴展而來。XBRL有自己的技術規范和分類標準來定義文檔的語法格式,數據之間的關系,運算方法等,并根據技術規范和分類標準生成實例文檔將數據展示出來,形成可閱讀的文件形式,供用戶分析使用。它可以降低用戶的使用成本,提高數據的使用率,提高客戶的服務準確率,也可以跨平臺使用,不受任何應用程序的限制。XBRL提供了靜態數據轉變為動態數據的途徑,不僅使數據搜集更加流暢,而且讓信息搜尋人員的搜索、分析更加快速準確,在財政,金融等社會領域和企業內部有著廣泛的應用。
由于XBRL獨特的網絡語言報告形式,XBRL語言特定的表示方法,并且它的使用不受任何應用程序的限制,并且有統一的標準格式,這些特點方便了數據挖掘技術的應用,提高了數據挖掘的共享度以及精確度,完成了數據在計算機程序之間的集成,極大地方便了用戶的使用,進一步提高了數據挖掘的效率。而關聯規則是數據挖掘技術中的一個比較重要的分類,它在一個比較大的數據庫中發掘不同項目之間的一些相關關系,也就是說把那些頻繁出現的項集從數據庫中發掘出來。自從在上個世紀90年代,Agrawal和他的同事在處理市場上購物籃的問題時提出了關聯規則算法Apriori后,世界上有非常多的科研人員就該算法提出了改進,但在XBRL數據格式上的研究還不多。
本文首先在XBRL數據集上實現Apriori算法,并通過實驗來驗證其不足,然后再實現DC-Apriori算法,并對這兩種算法在頻繁項集的生成效果上通過實驗進行驗證。
1 傳統Apriori算法
Apriori算法的主要思想是:給定一個交易數據集合,根據指定的最小支持度和最小可信度,挖掘數據之間的關聯規則。一般來說,Apriori算法的挖掘過程分為兩個內容:
(1)挖掘出事務數據庫中所有的頻繁項集,也就是說,在事務數據庫中,所有支持度大于最小支持度的項集都要能夠挖掘出來。
(2)在生成頻繁集的基礎上,生成所有的關聯規則。也就是說,利用第一步生成的頻繁集,挖掘出可信度大于等于用戶指定的最小可信度的規則,找出不同項之間的關聯規則。
作為一種挖掘布爾關聯規則頻繁項集的算法,Apriori算法使用逐層搜索的迭代方法,通過K-頻繁項集來搜索(k+l)-頻繁項集。Apriori算法首先找出頻繁1-項集的集合,用于產生頻繁2-項集集合,然后再使用頻繁集合來產生頻繁集合,如此下去,一直到不能夠再找到頻繁k-項集為止。
對于XBRL數據的關聯規則挖掘,由于其半結構化的特點,所以難以直接使用傳統的高級語言實現,而XQuery以其簡單支持多種表達式和構造函數等特點,得到了很多人的應用,因此本文將其作為XBRL數據挖掘算法的實現工具。
2 DC-Apriori算法
由于需要掃描整個數據庫,支持度大于最小支持度的候選頻繁k項集才可以入選頻繁項集k,所以Apriori算法的計算時間很大一部分都是用在計算頻繁項集的支持度上。在頻繁項集中的每一個項都需要計算支持度,而且每次都需要讀取數據庫。因此通過降低對整個數據庫的掃描次數以及掃描數據庫時對每個數據項所做的比較次數就可以獲得一個運行效率比較高的算法。
鑒于此,可以在算法中通過加入刪除計數(Delete Counter)的方式來減少掃描數據庫的次數以及掃描數據庫時對每個數據項所做的比較次數,我們稱該種算法為DC-Apriori。在該算法中,對每一個候選項集,只需對數據庫進行一次掃描就可以了。然后通過刪除那些不能生成頻繁項集的項的方式來去除數據的冗余,從而提高運行效率。
在改進的刪除計數DC-Apriori算法中,尋找頻繁項集的思想是:通過第一次數據庫掃描,統計出所有只包含一個元素項集出現的概率,然后找出概率大于等于最小支持度的項集,由兩部分項集組成頻繁項集 。從第二次數據庫掃描開始,對頻繁項集的項進行循環計算,直至最高維數項集生成為止。
在循環計算頻繁項集的過程中,第k步時,在上一層生成的頻繁K-1項集基礎上生成候選K項集。在頻繁K-1項集的生成過程中,要對所有該候選集中的項進行統計,得到每一個項所出現的次數。對于其他項,如果它的計數小于K-1則表明包含項的項集已經對生成的頻繁項集不再有任何作用,刪除該項,從而減少了由該項參與生成的項集組合。然后再對新生成的K維頻繁項集進行檢測,查看所有的K-1維頻繁項是否都已經在K-1維頻繁項集中。如果有頻繁項沒有被包含,就要刪除該頻繁項,從而得到一個只包含K維頻繁項集的候選頻繁項集。
得到k維候選頻繁項集后,掃描事務數據庫D的每一個事務,如果該事務中包含有候選頻繁項集中的項,則保留該項事務,否則刪除該事務。在每生成一次高緯度的頻繁項集時,都會刪除一些事務和頻繁項集,從而減少下一維度的事務掃描I/O的開銷,直至生成最高維度的項集,則數據庫中的事務記錄量降至最少,由此可以提高算法的計算效率。
帶有刪除計數的DC-Apriori算法的偽代碼可以描述如下:
輸入:事務數據庫D;最小支持度$minsupport。
輸出:D中的頻繁項集L。


3 實驗結果
實驗的硬軟件環境如下所示:①硬件配置:酷睿i5 2.5G雙核CPU,4G內存。②操作系統:Win2000。③數據庫:X-Hive6.0/DB。④編譯環境:JDK 1.6.7。
為了測試對XBRL實例文檔的數據挖掘的支持以及驗證改進后的Apriori算法通過XQuery實現后的數據挖掘效率,我們采用了互聯網上上市公司披露XBRL實例文檔組成的數據庫做為數據集,分別進行了以下兩組實驗:
(1)針對包含有不同事務數量的數據庫,在最小支持度、最小信任度一樣的情況下,測試兩種算法的運行時間。

表1 不同事務數的運行時間

圖1 有不同事務數目數據集的挖掘效率
通過圖1可知,兩種算法的運行時間上,針對同數量的事務數據庫,在數據量大于15000條時,DC-Apriori算法的運行時間要比Apriori算法減少了一半左右。由此可知,DC-Apriori算法針對大規模的數據庫處理時有著較好的優勢。
(2)針對包含有不同最小支持度,在同一數據庫的條件下,測試兩種算法的運行時間。
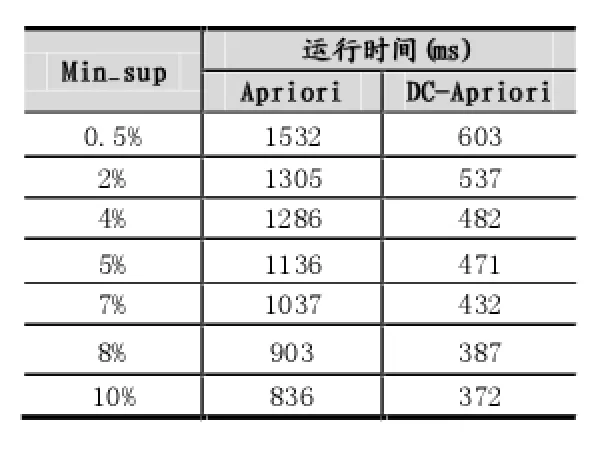
表2 不同支持度的算法運行時間
通過圖2可知,總體上來講,針對不同的支持度,Apriori算法的運行時間都要比DC-Apriori算法要長,而且DC-Apriori在不同的支持度下的運行效率比較穩定,沒有隨著支持度不同而在運行時間上出現大幅度的變化。Apriori算法在支持度比較低的情況下,運行時間比較長,隨著支持度的增加,運行時間會出現一些比較大的變化,算法不太穩定。
4 結語
從上節的實驗數據結果來看,通過XQuery實現DC-Apriori算法對XBRL文檔進行關聯規則數據挖掘是可行的。針對時間方面的對比來看,改進后的算法運行時間有了明顯提高,該算法在對XBRL文檔挖掘中運行時間有了明顯的改善。
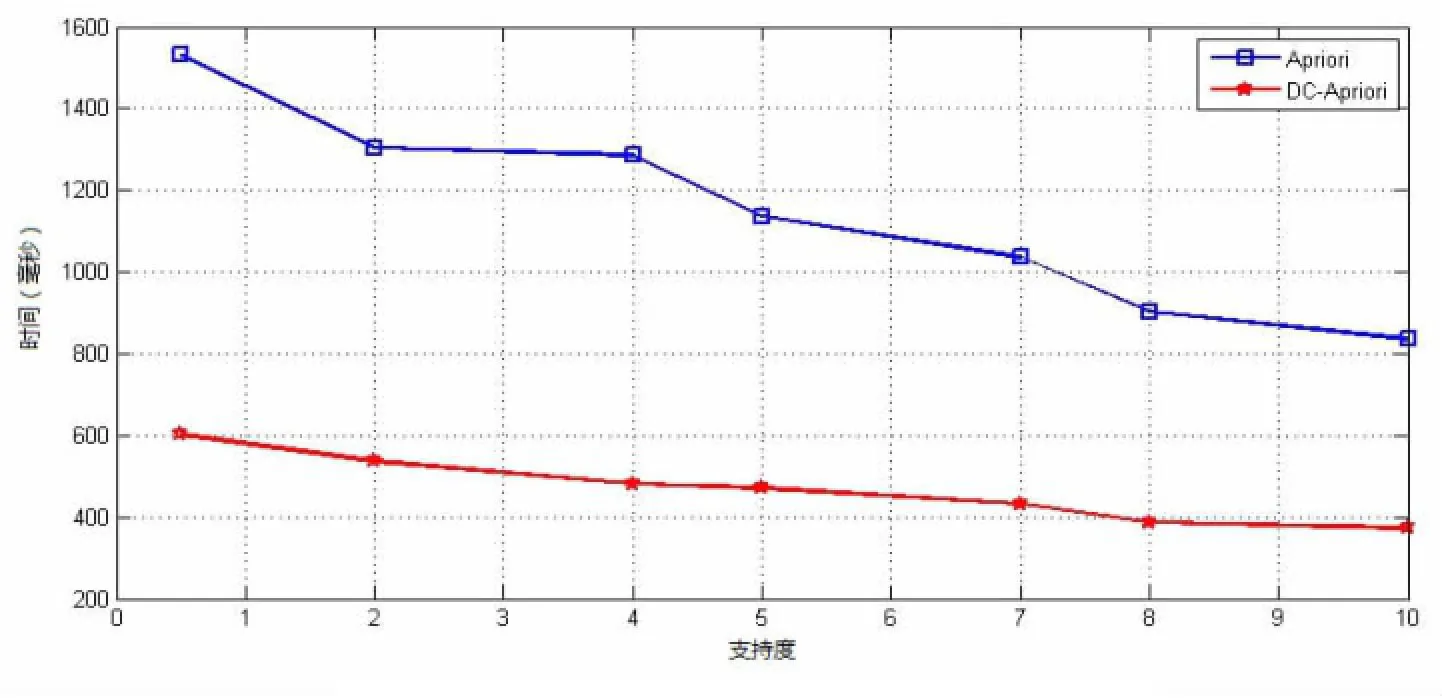
圖2 相同事務數目不同支持度的挖掘效率
[1]Amnon Meisels,Michael Orlov and Tal Maor.Discovery Associations in XML Data[C].Proceedings of the Third International Conference on Web Information Systems Engineering(Workshops),Singapore,2002.
[2]許淵.面向xbrl的數據挖掘[J].中國管理信息化(綜合版),2005(10):45-46.
[3]姚靠華,洪昀.XBRL層次結構與財務信息數據挖掘[J].會計之友,2009,1:60-62.
[4]亓文娟,晏杰.數據挖掘中關聯規則Apriori算法.計算機系統應用[J],2013,04:121-124.
XBRL;Association Rules;DC-Apriori Algorithm
Research on DC-Apriori Algorithm Facing XBRL
ZENG Zhi-yong1,YAN Ya-li2
(1.The Information Management Center,Yunnan University of Finance and Economics,Kunming 650221;2.The Information Department,Yunnan University of Finance and Economics,Kunming 650221)
1007-1423(2015)26-0027-04
10.3969/j.issn.1007-1423.2015.26.007
2015-07-28
2015-08-15
XBRL作為一種基于XML的可擴展性商業報告語言,目前已廣泛應用于財務系統中。因企業財務數據越來越多,利用數據挖掘方法挖掘出我們需要的信息顯得極為重要。實現一種面向XBRL的DC-Apriori挖掘算法,實驗表明:在X-Hive數據庫中采用DC-Apriori算法進行XBRL關聯規則挖的方法是行之有效的,并且挖掘效率高于傳統Apriori算法的效率。
XBRL;關聯規則;DC-Apriori算法
教育部人文社會科學研究青年基金(No.10YJCZH004)、云南財經大學校科研基金重點項目(No.YC10A003)
曾志勇,男(漢族),貴州貞豐人,教授,博士,研究方向為數據挖掘
閆亞麗,女(漢族),山東菏澤人,碩士,研究方向為數據挖掘
XBRL is a kind of extensible business reporting language which based on XML,it has been widely used in the financial system.More and more enterprise financial data bring us to use the method of data mining to dig out the important information we need.Puts forward a DCApriori algorithm facing XBRL,the experiment shows that using DC-Apriori algorithm in X-Hive to excavate XBRL data is feasible and effective,and the efficiency of DC-Apriori algorithm is higher than Apriori algorithm.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
