關鍵詞共詞分析法:高等教育研究的新方法
2015-09-21 04:24:01郭文斌方俊明
高教探索 2015年9期
郭文斌+方俊明
摘要:關鍵詞共詞分析法是一種較新的科學計量分析方法,它主要通過對高頻關鍵詞對在同一篇文章中出現的頻次進行統計分析,生成共被引矩陣。在此基礎上,通過統計軟件,進行聚類分析、多維尺度分析、因子分析、主成分分析、社會網絡分析等高級統計處理,繪制出二維或者三維的可視化圖形,客觀系統的展示出所關注資料的直觀量化信息。在我國高等教育研究領域較少有學者對此方法進行論述,為了幫助大家更好地了解和掌握此方法,本文以2000-2012年《教育研究》文獻熱點知識圖譜作為實例,詳細展示了此方法的使用過程和注意事項。
關鍵詞:關鍵詞;共詞分析;高等教育研究;知識圖譜
一、引言
隨著研究成果的激增,數字化期刊的盛行及互聯網使用的便捷化,可以通過網上搜索引擎快捷的查詢并獲得這些成果。在應對海量數字信息的今天,傳統文獻計量和綜述方式,不僅耗費時間、效率低下、查詢資料的時間跨度短,而且難以全面搜集海量文獻信息,造成文獻研究偏于定性歸納、過于主觀。[1]激增的數據背后隱藏著許多重要的信息,缺乏挖掘數據背后隱藏的知識的手段,導致了“數據爆炸但知識貧乏”。[2]如何在浩如煙海的數字文獻中,將這些零散的信息全面、快速綜合起來,挖掘出有深度的信息為我所用,已經成為眾多研究者關注的熱點。隨著計算機技術的不斷提升,以及數理統計方法的完善,研究者使用計算機進行數據挖掘(Data Mining,DM)的能力得以大大提升。在此背景下,科學知識圖譜開始成為當前國際科學計量學領域熱門的方法之一。它是通過將科學計量學的引文分析方法與可視化技術相結合達到對信息的有效組織和利用,生成新的知識。[3]該方法首先,通過計算機和互聯網搜索引擎強大的自動查詢功能,在極短的時間里面完成對海量信息的準確查詢。其次,通過計算機對已查詢到的海量分散信息進行文獻計量統計分析,不僅可以通過量化模型將其以科學的、可視化的形式直觀的呈現出來,而且還可以發現它們之間的深層次關系和趨勢,對將要進行的同領域的研究提供科學的指導。該方法被國內外的許多科學計量學研究者應用于學科前沿的研究。但是,國內教育研究方法方面還比較落后。許多現代科學研究方法在教育科研中應用得很少,現代數學遲遲未被引進到教育科學中來。[4]對于科學計量方法在教育研究中應用的專題介紹性文獻并不多見。我們在撰寫本文前,使用關鍵詞共詞分析方法分別對國內特殊教育和自閉癥(孤獨癥)[5]相關研究成果進行了梳理和總結,積累了一定的經驗,同時,該方法對大量文獻綜合處理的高效性、準確性、客觀性和直觀性給我們留下了深刻的印象。為了幫助國內的高等教育研究者能夠對這種方法有所了解,并且能夠在今后的研究中更多的使用這種方法,提升自己教育科研的準確性和科學性,下面,我們以代表國內教育最高研究水準的教育類的核心期刊《教育研究》在2000-2012年發表的所有文獻作為研究資料,向大家展示該方法的具體使用過程和注意事項。
二、關鍵詞共詞分析方法
(一)關鍵詞共詞分析方法簡介
共詞分析(Co-word Analysis)是一種較新的文獻計量學方法,其屬于內容分析方法的一種。其主要原理是對一組詞兩兩統計它們在同一篇文獻中出現的次數,以此為基礎對這些詞進行聚類分析,從而反映出這些詞之間的親疏關系,進而分析這些詞所代表的學科或主題的結構與變化。[6]共詞分析法可分別以文獻的主題詞和關鍵詞進行共詞分析,但我們傾向于主張采用關鍵詞進行共詞分析來得出結論,主要原因有:第一,關鍵詞是論文中起關鍵作用的、最能說明問題的、代表論文內容特征的、或最有意義的詞[7];第二,關鍵詞不僅準確地反映論文的主題,而且其本身應具有獨立的檢索功能;第三,由于一篇文獻的關鍵詞或主題詞是文章核心內容的濃縮和提煉,因此,如果某一關鍵詞或主題詞在其所在的領域的文獻中反復出現,則可反映出該關鍵詞或主題詞所表征的研究主題是該領域的研究熱點[8];第四,通過對高頻關鍵詞共現關系分析,可以進一步明晰若干熱點研究領域。[9]關鍵詞共詞分析主要是通過共詞分析軟件,對符合條件的查詢到的海量信息的關鍵詞對在同一篇文章中出現的頻次進行統計分析(共詞分析),生成共被引矩陣。在此基礎上,利用統計軟件,進行聚類分析、多維尺度分析、因子分析、主成分分析、社會網絡分析等高級統計處理,繪制出二維或者三維的可視化圖形,客觀系統的展示出所關注資料的直觀量化信息。
(二)關鍵詞共詞分析方法的具體操作過程
1.準備研究工具
下載并安裝Bicomb共詞分析軟件和SPSS20作為主要研究工具。Bicomb共詞分析軟件由中國醫科大學醫學信息學系崔雷教授和沈陽市弘盛計算機技術有限公司開發。下載獲取地址為崔雷教授科學網的博客網址:https://skydrive.live.com/?cid=3adcb3b569c0a509&id=3ADCB3B569C0A509%211195。
2.準備研究資料
首先,進入網絡搜索引擎,根據自己研究目的限定文獻來源,進行文獻檢索。根據自己研究需要和目的對文獻進行取舍和保留。再次,對選取的文獻按照統一格式進行保存。第三,對保存的文獻進行標準化。最后,將保留文獻的格式轉化為Bicomb共詞分析軟件能夠識別的ANSI編碼,供后續量化統計分析使用。這里值得注意的是,如果不將文本格式編碼轉為ANSI編碼,Bicomb共詞分析軟件將無法識別有效信息。
3.進行量化統計分析
首先,使用Bicomb軟件進行關鍵詞統計并確定提取、導出高頻關鍵詞詞篇矩陣。有關Bicomb軟件進行關鍵詞統計的詳細操作過程請閱讀相關操作手冊。[10]其次,采用SPSS20對高頻關鍵詞進行聚類分析并生成Ochiai系數相同矩陣。再次,采用SPSS將高頻關鍵詞的相同矩陣轉化為相異矩陣并進行多維尺度分析。最后,對上述量化結果進行定量和定性結合的分析,得出相應的結論和建議。
概括而言,關鍵詞共詞分析法的一般過程包括:明確研究的問題、選定并標準化研究材料、高頻關鍵詞的選定、共現矩陣的提取、進行高級統計處理(相同矩陣、相異矩陣的轉化、聚類分析、多維尺度分析)。
三、關鍵詞共詞分析方法示例
為了更好的使大家掌握該方法,下面,我們以“2000-2012年《教育研究》文獻熱點知識圖譜”為例向大家進行詳細的示范說明。
(一)查找準備文獻
首先,進入中國學術文獻網絡出版總庫,進入標準檢索對話框,將發表時間欄的具體日期定義為從“2000-01-01”到“2012-12-31”,文獻出版來源限定為“《教育研究》”。根據限定好的條件進行文獻檢索,檢索到文獻2908條。其次,根據研究需要刪除研討會綜述、課題介紹、會議通知、卷首語、會議記錄、課題通過鑒定、讀后感、簡介、研討會簡介、書評、成果鑒定會、學院以及學校簡介信息、人物專訪、投稿須知、會議紀要、出版信息、目錄信息、公告等,得到有效論文2550篇。再次,對上述文獻統一按照題名、作者、關鍵詞、單位、摘要、年、期等信息以文本形式保存。最后將保存的文本信息編碼格式統一改為ANSI編碼后保存。
(二)進行量化統計
1.進行關鍵詞詞頻統計分析并提取高頻關鍵詞頻次
一個學術研究領域較長時域內的大量學術研究成果的關鍵詞集合,可以揭示研究成果的總體內容特征、研究內容之間的內在聯系、學術研究發展的脈絡與發展方向等。[11]如果在統計文獻時,關鍵詞出現的頻次越高,則表示與該關鍵詞有關的研究成果越多,研究內容的集中性就越強。一個研究領域的少量高頻次的關鍵詞,擁有該學科明顯大的信息密度與知識密度,成為信息與知識需求者檢索文獻的重點,它們被稱為核心關鍵詞。[12]詞頻分析法是利用能夠揭示或表達文獻核心內容的關鍵詞或主題詞在某一研究領域文獻中出現的頻次高低來確定該領域研究熱點和發展動向的文獻計量方法。[13]
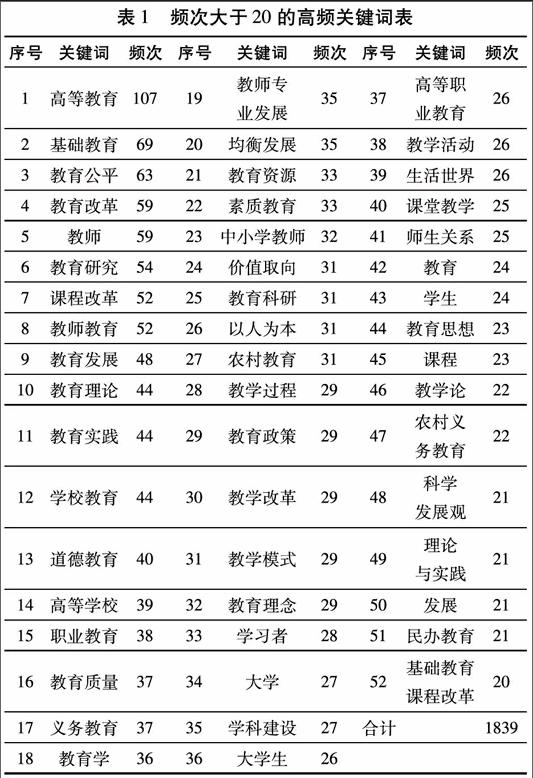
對2550篇文章中的15976個關鍵詞進行詞頻統計分析,發現關鍵詞出現的頻次范圍是1-107。為了減輕工作量,對關鍵詞頻次大于20的高頻關鍵詞進行提取,結果見表1。
從表1可以看出,頻次大于等于20的有52個關鍵詞,占關鍵詞總數的3.25%,其出現的頻次合計為1839次,詞均35.37次,占關鍵詞總頻次(15976)的11.51%。這些高頻關鍵詞表述的研究內容,是2000-2012年《教育研究》發表文章的核心內容。從高頻關鍵詞分布順序可看出,《教育研究》涉及的前10個研究熱點依次為:高等教育(107)、基礎教育(69)、教育公平(63)、教育改革(59)、教師(59)、教育研究(54)、課程改革(52)、教師教育(52)、教育發展(48)、教育理論(44)。這一統計結果,與2000-2009年八種教育學期刊文獻前10位高頻關鍵詞(高等教育、課程改革、教育研究、教育改革、素質教育、教學改革、基礎教育、課堂教學、教師、教育理論)對比,有7個高頻關鍵詞完全重合,排在第一位的高等教育和最后一位的教育理論在排序上完全吻合,其它5個僅在排列順序上發生差異。這一結果不僅驗證了本研究中統計方法的可信,而且還進一步說明相對于其它教育研究刊物,《教育研究》起著風向標的作用。
為深入挖掘這52個高頻關鍵詞的詞頻之間的關系以及它們背后隱藏的有效信息,還需要進一步采用關鍵詞共現技術來進行深入的計量學研究。
2.生成高頻關鍵詞的相同和相異矩陣
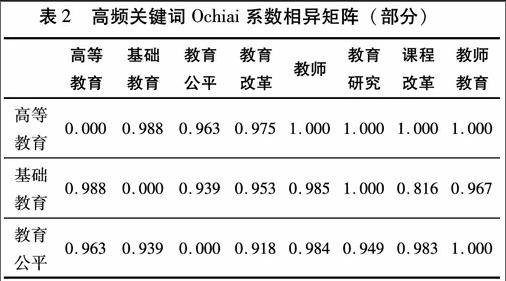
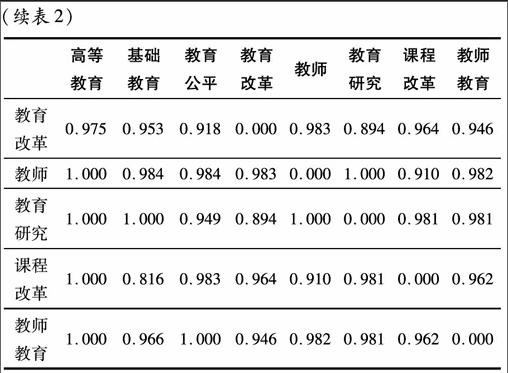
首先,生成高頻關鍵詞詞篇矩陣。對各個高頻關鍵詞是否在其它論文中成對出現(出現為1,否則為0),利用Bicomb軟件生成高頻關鍵詞詞篇矩陣。詞篇矩陣考察各高頻關鍵詞間的親疏關系,詞篇矩陣表示的是兩目標之間的相似程度的矩陣,即兩者數字越大表明兩者關系越近,越小表明兩者關系越遠。[14]其次,生成高頻關鍵詞相似系數矩陣。以關鍵詞詞篇矩陣為基礎,在SPSS20中進行相關分析,數據類型選擇“binary”二元變量,相似系數選擇“Ochiai”系數,構造出高頻關鍵詞相似系數矩陣。[15]相似矩陣中的數字表明數據間的相似性,數字的大小表明了相應的兩個關鍵詞之間的距離遠近,其數值越接近1,表明關鍵詞之間的距離越近、相似度越大;反之,數值越接近0,則表明關鍵詞之間的距離越大、相似度越小。最后,生成高頻關鍵詞相異系數矩陣。為了消除由于關鍵詞共現次數差異所帶來的影響,根據相似系數矩陣,采用相異系數矩陣=1-相似系數矩陣,產生相異系數矩陣。相異系數矩陣中數字表明數據間的相異性,其含義與相似系數矩陣意義相反,數值越接近1,表明關鍵詞之間的距離越大。相異系數矩陣結果見表2。
從表2可以看出,各關鍵詞分別與高等教育距離由遠及近的順序依次為:教師(1.000)、教育研究(1.000)、課程改革(1.000)、教師教育(1.000)、基礎教育(0.988)、教育改革(0.908)、教育公平(0.963)。這個結果說明,研究者在論及高等教育時,會更多的將其與教師、教育研究、課程改革與教師教育結合在一起討論,而較少和基礎教育、教育改革、教育公平結合起來。采用上述原理,綜合表2中的關鍵詞相異系數矩陣數據,可以初步得出的結論為:2000-2012年在《教育研究》發表的成果中,涉及到基礎教育與課程改革的資料較少,大量研究主要以高等教育為探討對象,關注高等教育中涉及的教師、教育研究、課程改革及教師教育等主要因素,對這些因素予以了更多的關注。出現這一結果的原因,一方面是《教育研究》從2004年開始增大了對“教師”這一關鍵詞的關注,開辟了專欄。另一方面的原因是,2001年“教師教育”被國務院首次提出后,引起了多方面尤其是教育界對此問題的高度重視。
3.進行高頻關鍵詞聚類分析
聚類分析是選定一些分類標準,將不同的觀察體加以分類,同一類(集群)之內觀察體彼此的相似度愈高愈好,而不同一類之間觀察體彼此的相異度愈高愈好。[16]高頻關鍵詞聚類分析是通過高級統計對已經發表文獻的高頻關鍵詞組的相似性與相異性分析,來發現它們之間的遠近關系,挖掘隱藏在它們背后的研究者關心的知識信息。關鍵詞聚類分析時,先以最有影響的關鍵詞(種子關鍵詞)生成聚類;再次,由聚類中的種子關鍵詞及相鄰的關鍵詞再組成一個新的聚類。關鍵詞越相似它們的距離越近,反之,則越遠。
將上述52個高頻關鍵詞構成的52×52的相似系數矩陣,導入SPSS20進行聚類分析。結果見圖1。
從圖1可以直觀的看出2000-2012年《教育研究》高頻關鍵詞被分為8個種類,它們的具體分布結果見表3。
從表3可以看出,2000-2012年《教育研究》8類研究具體分布為:
種類1為教學過程中的活動和改革,包括14個關鍵詞,其可以細分為6小類:小類1基礎教育教學活動及過程,包括3個關鍵詞(教學過程、教學活動、基礎教育課程);小類2教學改革與教學論,包括2個關鍵詞(教學改革、教學論);小類3教學模式與課堂教學,包括2個關鍵詞(教學模式、課堂教學);小類4學生、教師及其發展,包括3個關鍵詞(學生、發展 、教師);小類5師生關系,包括1個關鍵詞(師生關系);小類6基礎教育及素質教育的課程改革,包括3個關鍵詞(基礎教育、課程改革、素質教育)。
種類2為道德教育與生活,包括2個關鍵詞(道德教育、生活世界)。
種類3為教育與課程,包括2個關鍵詞(教育、課程)。
種類4為學校教育、義務教育及教育政策、觀念,包括16個關鍵詞,其可以細分為7小類:小類1學校教育與職業教育,包括2個關鍵詞(學校教育 、職業教育);小類2農村教育和農村義務教育,包括2個關鍵詞(農村教育、農村義務教育);小類3義務教育和均衡發展,包括2個關鍵詞(義務教育、均衡發展);小類4教育公平、質量及政策,包括3個關鍵詞(教育公平 、教育質量、教育政策);小類5教育資源,包括1個關鍵詞(教育資源);小類6教育發展與教育科研,包括2個關鍵詞(教育發展、教育科研);小類7教育理念及對學習者的關注,包括4個關鍵詞(以人為本 、科學發展觀、教育理念 、學習者)。
種類5為大學及學科建設,包括2個關鍵詞(大學 、學科建設)。
種類6為教師教育、教育理論與教育思想,包括10個關鍵詞,其可以細分為3小類:小類1教師教育及其專業發展,包括3個關鍵詞(教師教育 、教師專業發展、中小學教師);小類2教學理論、研究及實踐與改革,包括6個關鍵詞(教育理論、理論與實踐 、教育研究 、教育實踐 、教育學 、教育改革);小類3教育思想,包括1個關鍵詞(教育思想)。
種類7為高等職業教育和民辦教育,包括2個關鍵詞(高等職業教育、民辦教育)。
種類8為高等教育、高等學校與價值取向,包括4個關鍵詞,可以細分為2小類:小類1高等教育與大學生價值取向,包括3個關鍵詞(高等教育 、大學生 、價值取向);小類2高等學校,包括1個關鍵詞(高等學校)。
4.進行高頻關鍵詞的多維尺度分析
多維尺度分析(MDS)是一種可以幫助研究者找出隱藏在觀察資料內的深層結構的統計方法,其目的是在發掘一組資料背后之隱藏結構,希望用主要元素所構成的構面圖來表達出資料所隱藏的內涵,尤其是在觀察資料體很多時,利用多維尺度法更能適切地找出資料的代表方式。[16]采用多維尺度分析時,要匯報其 Stress和RSQ值,它們分別為多維尺度分析中的信度和效度估計值。其中,壓力系數(Stress)是擬合度量值,用于維度數的選擇,Stress越小,表明分析結果與觀察數據擬合越好,其值越小,說明模型的適合度越高。Kruskal(1964)給出了一種根據經驗來評價Stress優劣的尺度:若Stress≥20%,則近似程度為差(Bad);≤10%,為滿意(Fair);≤5%,則為好(Good);≤2.5%,為很好(Excellent);其理想的狀況為Stress=0,稱為完全匹配(Prefect)。[17] 模型距離解釋的百分比(RSQ),表示變異數能被其相對應的距離解釋的比例,也就是回歸分析中回歸分析變異量所占的比率,RSQ值越大,即越接近1,代表所得到的構形上各點之距離與實際輸入之距離越適合。一般認為,RSQ在0.60以上是可接受的。[18]
采用spss20對上述52個高頻關鍵詞構成的52×52的聚類分析產生的矩陣進行多維尺度分析,標準化方法選擇Z分數。結果顯示,Stress= 0.120,RSQ= 0.823,說明其擬合效果較好,可以反映出《教育研究》高頻關鍵詞間的學術聯系狀況。多維尺度分析結果見圖2。
多維尺度繪制出的坐標稱為戰略坐標,它以向心度和密度為參數繪制成二維坐標,可以概括地表現一個領域或亞領域的結構。[19]戰略坐標中,各個小圓圈代表各個高頻關鍵詞所處的位置,圖中圓圈間距離越近,表明它們之間的關系越緊密;反之,則關系越疏遠。影響力最大的關鍵詞,其所表示的圓圈距離戰略坐標的中心點越近。坐標橫軸為向心度(Centrality),表示領域間相互影響的強度;縱軸為密度(Density),表示某一領域內部聯系強度。[20]在戰略坐標劃分的四個象限中,一般而言,第一象限的主題領域內部聯系緊密并處于研究網絡的中心地位。第二象限的主題領域結構比較松散。這些領域的工作有進一步發展的空間,在整個研究網絡中具有較大的潛在重要性。第三象限的主題領域內部鏈接緊密,題目明確,并且有研究機構在對其進行正規的研究,但是在整個研究網絡中處于邊緣。第四象限的主題領域在整體工作研究中處于邊緣地位,重要性較小。[21]
結合上述理論,從圖2可以看出,首先,2000-2012年《教育研究》熱點知識圖譜分為8個區域,雖然種類1、4和6所占的區域較大,種類2、3、5、7、8所占區域較小,但從其分布位置可以看出,這些小的區域處于戰略坐標的核心附近,表明這些區域是其關注的重點。種類7和種類8所處的領域距離戰略坐標軸心位置最近,表明近幾年高等職業教育和民辦教育、高等教育、高等學校與價值取向成為了《教育研究》發文的熱點領域。其次,從各個種類所處戰略坐標的象限分布特點來看,種類4的大部分關鍵詞位于戰略坐標的第一象限,說明其不僅是《教育研究》雜志組稿的核心領域,而且其文章數量相對于其它7個種類所占領域更為多,也更成熟,該領域的研究是我國教育研究的中心領域。種類1、8主要位于第二象限,說明其主題相對松散,對其關注度還有待于進一步加強,其今后在《教育研究》文獻成果質量提升方面還具有較大的潛在價值。種類2、3、6主要位于第三象限,說明這3個種類所占的領域內部鏈接緊密,題目明確,并且有研究機構正在對其展開正規的研究,但在整個研究網絡中仍處于邊緣。種類6大部分位于戰略坐標的第四象限,說明它們所處的主題在整個研究中處于邊緣地位,重要性較小。種類7不僅橫跨四個象限,而且緊緊圍繞在戰略坐標軸心,說明它所占的領域是《教育研究》發文的重點核心領域,該領域的研究不僅與國家中長期教育改革和發展規劃綱要(2010-2012年)提出的大力發展職業教育和大力支持民辦教育的內容相一致,而且還與《教育研究》“2006中國教育研究前沿與熱點問題年度報告”中“創新高等教育發展思路”、“拓展高等教育辦學多樣化”、“職業教育的轉型與發展取向”[22]等內容相一致。此研究結果也被潘黎、王素的研究所驗證。
四、總結和展望
通過上述實例,大家可以更直觀的感受到關鍵詞共詞分析方法的使用效果,但是,在使用的具體過程中,還應該值得關注和思考下述問題。
(一)進行關鍵詞共詞分析前要確保對其進行標準化
我們主要針對《教育研究》進行計量分析,因為其風格基本一致,所以在標準化處理關鍵詞方面比較容易處理,但是,如果涉及到多個雜志間的文獻關鍵詞處理,就要特別注意對查詢到的文獻的關鍵詞進行規范和統一。比如,我們在進行自閉癥熱點研究時,要將在不同刊物中表達同樣含義的關鍵詞“自閉癥”與“孤獨癥”統一為“自閉癥”。遲景明和吳琳在研究中,將“高職院校”、“職業技術學院”和“職技高校”標準化為“高職院校”,將“高等學校”、“高等院校”、“高校”、“大學”等標準化為“高校”。對關鍵詞的標準化處理,能確保最后量化材料的準確,進而保證最后科學計量的精確、科學。但很多進行科學計量的研究忽視了此問題,導致了其研究結果的科學和準確性大打折扣。
(二)可以嘗試使用社會網絡分析法更清晰地展示關鍵詞間的強弱關系
本研究采用的多維尺度雖然可以較好的觀察到變量間的關系,但是無法表現他們之間的強弱。要更好的表達各個關鍵詞之間的強弱關系,大家以后可以嘗試進行社會網絡分析。社會網絡分析(Social Network Analysis)(簡稱SNA,有的文獻稱為“社會網”或“網絡分析”)是包括測量與調查社會系統中各部分(“點”)的特征與相互之間的關系(“連接”),將其用網絡的形式表示出來,然后分析其關系的模式與特征這一全過程的一套理論、方法和技術。[23] 采用社會網絡分析得出的三位立體網絡圖,更能直觀地反應各個體(節點)的位置及它們之間的相互關系(線段)。在原始圖線條密集,不易分析時,還可進行凝聚子群分析,使圖的直觀性增強,更容易分析理解。[24] 社會網絡分析方法介紹及其軟件的下載,國際社會網絡分析網(http://www.insna.org/cgi-bin/softdatasearch.cgi)中給出了Construct、Network Genie、ORGAN 1 Social Network Analysis、PARTNER、PermNet、Socilyzer、UCI
NET software for Social Network ?Analysis八種社會網絡分析軟件。中文社會學網(http://www.sociology2010.cass.cn/news/133424.htm)給出了包括上述軟件在內的20種軟件介紹和鏈接地址,感興趣的讀者可以自己嘗試使用。
(三)關鍵詞共詞分析法和定性方法結合使用才能更好解讀研究結果
雖然熱點知識圖譜是采用科學計量法繪制出來的,但是該方法的使用并非完全依賴定量技術,其還依賴于定性分析技術。在進行了聚類分析和多維尺度分析之后,對于各個種類及其所在區域的劃分和命名均需要雄厚的專業功底。它就像采用因子分析之后,對于各個因子的命名需要結合專業知識來命名一樣。因此,要進行科學知識圖譜的繪制,需要將定量研究與定性分析結合起來,具有一定的專業背景,才能夠對計量結果進行準確、客觀的解讀。
(四)進行關鍵詞共詞分析方法時軟件的選取也至關重要
雖然現在國內很多研究者,在社會學科、管理學科、醫學等研究領域對中文文獻的熱點知識圖譜的繪制采用了陳朝美博士研發的CiteSpace軟件,但是該軟件的優勢在于處理外文,尤其是英文文獻上,對于中文文獻的處理還存在一定的不足,而我們所介紹的Bicomb軟件在中文文獻的共詞分析方面較有優勢,因此,我們建議大家對中文材料進行科學計量研究時更多的采用此軟件。
通過本文的介紹,我們衷心希望能夠幫助高等教育研究者對關鍵詞共詞分析法有所了解,同時,也真誠的希望越來越多的高等教育研究者投入到教育研究成果的科學計量研究中來!
參考文獻:
[1]潘黎,王素.近十年來教育研究的熱點領域和前沿主題——基于八種教育學期刊2000-2009年刊載文獻關鍵詞共現知識圖譜的計量分析[J].教育研究,2011(2):47-53..
[2]王方華,陳潔,編著.數據庫營銷[M].上海:上海交通大學出版社,2006.
[3]郭文斌,方俊明,陳秋珠.基于關鍵詞共詞分析的我國自閉癥熱點研究[J].西北師大學報(社會科學版),2012,49(1):128-132.
[4]鄭日昌,崔麗霞.二十年來我國教育研究方法的回顧與反思[J].教育研究,2001(6):17-2.
[5]郭文斌,陳秋珠.特殊教育研究熱點知識圖譜[J].華東師范大學學報(教育科學版),2012,30(3):49-54.
[6]崔雷.專題文獻高頻主題詞的共詞聚類分析[J].情報理論與實踐,1996,19(4):49-51.
[7]馬妍春,黃可心.科技論文摘要、關鍵詞及參考文獻的規范化[J].情報科學,1999,17(6):625-627.
[8]楊國立,李品,劉競.科學知識圖譜——科學計量學的新領域[J].科普研究,2010,5(4):28-34.
[9]王凡.科學知識圖譜視域中的《圖書館理論與實踐》[J].圖書館理論與實踐,2011,(8):23-26.
[10]崔雷.書目共現分析系統《用戶使用說明書》[Z/OL].http://cid-3adcb3b569c0a509.skydrive.live.com/browse.aspx/BICOMB.2012-04-13.
[11]李文蘭,楊祖國.中國情報學期刊論文關鍵詞詞頻分析[J].情報科學,2005,23(1):68-70.
[12]安秀芬,黃曉鸝,張霞,等.期刊工作文獻計量學學術論文的關鍵詞分析[J].中國科技期刊研究,2002,13(6):505-506.
[13]馬費城,張勤.國內外知識管理研究熱點——基于詞頻的統計分析[J].情報學報,2006,25(2):163-170.
[14]邱均平,馬瑞敏,李曄君.關于共被引分析方法的再認識和再思考[J].情報學報,2008,27(1):69-74.
[15]遲景明,吳琳.近十年我國高等教育學學科研究熱點和趨勢——基于研究生學位論文的共詞聚類分析[J].中國高教研究,2011(9):20-24.
[16]陳正昌,程炳林,陳新豐,等著.多變量分析方法:統計軟件應用[M].北京:中國稅務出版社,2005:241-299.
[17]張文彤,主編.SPSS統計分析高級教程[M].北京:高等教育出版社,2004:40-44.
[18]靖新巧,趙守盈.多維尺度的效度和結構信度評述[J].中國考試,2008(1).
[19]Law J, Bauin S, J.Courtial P, et al.Policy and the mapping of scientific change: A co-word analysis of research into environmental acidification[J].Scientometrics,1988,14(3-4):251-264.
[20]馮璐,冷伏海.共詞分析方法理論進展[J].中國圖書館學報,2006,32(2):88-92.
[21]崔雷,鄭華川.關于從MEDLINE數據庫中進行知識抽取和挖掘的研究進展[J].情報學報,2003,22(4):425-433.
[22]教育研究編輯部.2006中國教育研究前沿與熱點問題年度報告[R].教育研究,2007(3):3-16,29.
[23]湯匯道.社會網絡分析方法述評[J].學術界,2009(3):205-208.
[24]種艷秋,張晗,冷榮新,等.利用社會網絡分析法和聚類法研究心血管疾病知識結構的比較[J].中華醫學圖書情報雜志,2007,16(6):77-90.
