帶虛警抑制的基于歸一化殘差的野值檢測方法
2015-08-17 11:14:50汝小虎柳姜文利黃知濤
電子與信息學報 2015年12期
汝小虎柳 征 姜文利 黃知濤
(國防科學技術大學電子科學與工程學院 長沙 410073)
帶虛警抑制的基于歸一化殘差的野值檢測方法
汝小虎*柳 征 姜文利 黃知濤
(國防科學技術大學電子科學與工程學院 長沙 410073)
野值檢測,或稱異常值檢測是模式識別和知識發現中一個重要的問題。以往的野值檢測方法難以有效地抑制虛警概率,針對這一問題,該文提出一種帶監督情形下基于歸一化殘差(Normalized Residual, NR)的野值檢測方法。首先利用訓練樣本計算待考查模式的NR值,其次比較NR值與野值檢測門限的相對大小,從而判斷待考查模式是否為野值。該文理論上推導了野值門限與虛警概率之間的關系表達式,以此為依據設置檢測門限,可實現在少量訓練樣本情況下仍能抑制虛警率的目的。計算機仿真和實測數據測試驗證了所提方法在野值檢測和虛警抑制方面的優越性能。
模式識別;監督;野值檢測;虛警概率;歸一化殘差
1 引言
野值定義為這樣的樣本,它偏離其他模式太遠以至于可認為它是由不同機制產生的[1]。野值檢測被廣泛應用于模式識別,知識發現和數據挖掘中,具體的問題如視頻監控,計算機入侵檢測,特定輻射源確認(Specific Emitter Verification, SEV)[2],混合標記數據集中的穩健分類[3]以及粒子圖像測速(Particle Image Velocimetry, PIV)數據中的奇異值檢測[4,5]等。
不同的應用背景一般會有不同的野值檢測技術[6-8],而以野值檢測方法的種類進行區分,可主要分為基于概率分布的[3],基于深度的[9],基于距離的[10-14],基于密度的[15]和基于聚類的[16-18]方法;以是否利用訓練樣本進行區分,可分為帶監督的和無監督的方法。針對帶監督的野值檢測問題,文獻[16]提出了基于單類支持向量機(Support Vector Machine, SVM)的野值檢測方法,該方法將樣本映射到高維核空間,利用訓練樣本建立超平面決策界,測試時把位于界外的樣本判為野值。文獻[17]引入動態學習的思想,實現了訓練樣本較少情況下超平面界的迭代擴張。文獻[18]擴展了單類SVM,對多類情形實現了穩健分類和野值檢測。但是這些方法存在一個共同的不足,即無法控制虛警概率。文獻[12-14]提出了局部化 p值估計(Localized P-value Estimation, LPE)的方法,該方法利用訓練樣本計算某種統計量G,通過比較考查模式和訓練樣本G值的相對大小得到p值的估計,如果p值大于指定的虛警率水平則將考查模式判為野值。若訓練樣本足夠并且野值滿足均勻分布假設,LPE方法可控制虛警率,同時實現一致最大勢(Uniformly Most Powerful, UMP)檢驗,但是當訓練樣本較少時該方法仍然難以抑制虛警率。文獻[4,5,10]提出了基于歸一化殘差(Normalized Residual, NR)的野值檢測方法。待考查模式的殘差定義為該模式與其近鄰模式間的距離,這一距離與近鄰模式內部距離的比值稱為模式的NR值。如果該值大于預先設定的野值門限則將待考查模式判為野值,否則認為其為正常模式。野值門限大小的設置往往依賴于經驗,雖然選擇較大的門限可以降低虛警率,但是其具體的對應關系仍然未見報道。
針對前述文獻中方法存在的不足,本文將以往基于NR的野值檢測轉化為帶監督的情形,提出一種能有效抑制虛警概率的野值檢測方法。為便于理論分析,在計算待考查模式的NR值方面,本文用隨機選擇的部分訓練樣本代替近鄰模式作為計算的依據。在野值檢測門限設置方面,本文根據重新定義的 NR,從理論上推導野值門限與虛警率之間的關系表達式,以此為依據設置門限的大小。此外,為了使檢測方法更加穩健,本文多次從訓練樣本中隨機選擇部分樣本,計算得到多個NR值,之后將這些值的平均與野值門限進行比較,由此判斷出待考查模式是否為野值。仿真實驗和實測數據測試發現,本文方法在較少訓練樣本情況下能夠更好地抑制虛警率,并且達到較高的野值檢測概率,性能優于同類方法。
本文剩余部分安排如下:第2節簡單介紹典型的LPE方法,作為同類方法,它會被用于和本文方法進行性能比較;第3節提出基于NR的野值檢測方法,包括NR的定義、野值檢測門限的理論推導以及具體的方法步驟;第4節通過仿真和實測數據測試驗證本文方法的優良性能;最后總結全文。
2 LPE方法[12-14]
文獻[12-14]將野值檢測轉化為二元假設檢驗問題,兩種假設分別為 H0:η ~f0和 H1:η ~f1,其中f1是區別于 f0的概率密度函數。帶有虛警抑制的野值檢測要求概率 P {判 為 H1|H0}≤α,其中α是指定的顯著水平。定義考查模式η的p值函數為
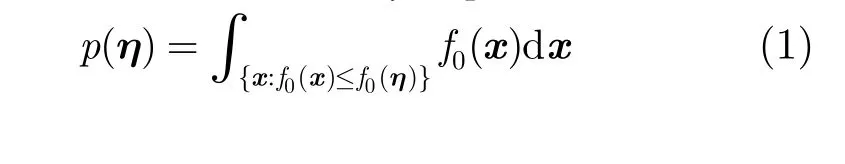
并假設 f1是均勻分布,那么該二元假設檢驗問題的UMP檢驗是
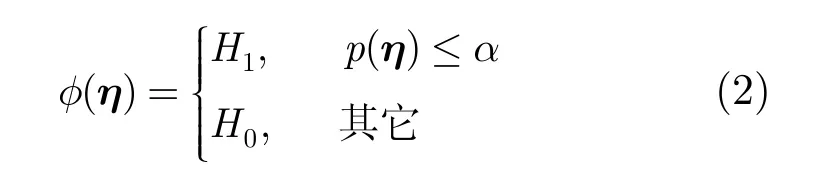
由于 f0未知,所以直接計算式(1)是不可能的。文獻[12-14]基于某種統計量G,定義
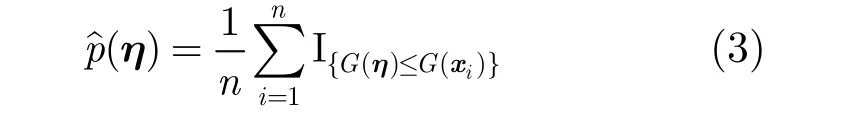
其中I是指示函數,通過 ?p(η)實現對 p(η)的近似,并證明了這種近似是漸進無偏的。
文獻[12]將統計量G定義為 G (x )= D(K)(x),即x與它周圍訓練樣本第K個最近的距離,因此被稱為 K-LPE方法。文獻[13]定義了新的統計量 G(x),其中表示向下取整,并在計算 G時采用平均的思想,提出了平均 K-LPE(averaged K-LPE,aK-LPE)方法。其基本思路是將訓練樣本隨機平分為兩部分,其中一部分的樣本 xi作為考查模式時,需從另一部分的樣本中尋找其近鄰樣本,計算得到G值。上述過程重復B次,將得到的所有G值取平均作為最后的統計量結果 G(xi)。 G(η)的計算需要首先隨機選定一半訓練樣本,從中選擇η的K個近鄰樣本,然后通過類似計算 G(xi)的過程得到。文獻[14]則實現了LPE野值檢測方法速度上的優化。
在訓練樣本足夠的情況下,式(3)中 ?p(η)對 p(η)會有較好的近似,但是近似效果會隨著訓練樣本數的減小而變差,這限制了LPE方法的應用。
3 基于歸一化殘差的方法
3.1 歸一化殘差的定義
以往對歸一化殘差(NR)的計算[4,5,10]用于解決無監督的野值檢測問題,對于帶監督的情形,本文在文獻[10]的基礎上對NR進行重新定義。從訓練樣本集 Xtr中隨機選擇K個樣本,k = 1,2,…, K ,那么待考查模式η的NR值可由式(4)計算得到。
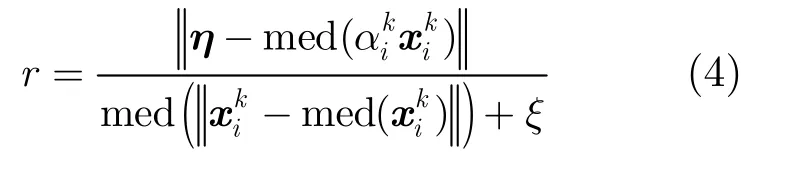
在進行野值檢測時,需要設置門限h,如果r > h則認為η為野值,否則認為 η ~f0為正常模式。以往的研究中對h的選擇帶有很大的主觀性,一般依據經驗設置為1~4。本文考慮對虛警率的控制,因此需要對門限的設置進行理論推算,將其表示為虛警率的函數。為便于分析,本文取消加權因子即設認為所有隨機選擇的訓練樣本對于判別η是否為野值具有同等的重要性。
3.2 野值門限的確定
野值門限的大小與所需的虛警率有關,所以只要分析待考查模式為正常模式的情形即可,即如果正常模式被識別為野值,則產生虛警。首先考慮高斯白噪聲的情況。設K個隨機選擇的訓練樣本為待考查模式為 η= xk=其中 x0是模式的理論值,模式噪聲滿足為噪聲方差。
根據定義,忽略容差ξ的影響,正常模式 xk的歸一化殘差其中

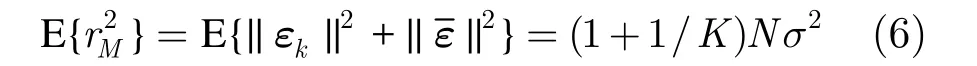
其中E{·}表示計算期望。
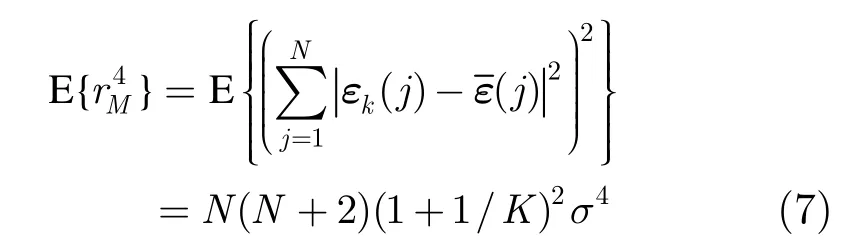
由式(6)和式(7)可得r分子平方的方差為
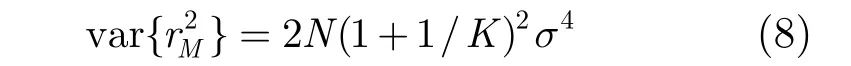
下面計算r分母平方的均值與方差。利用
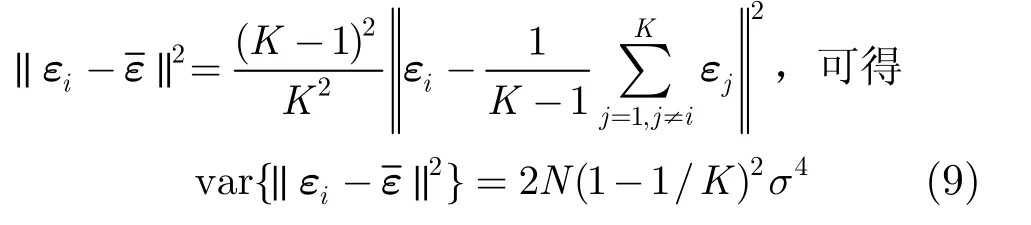
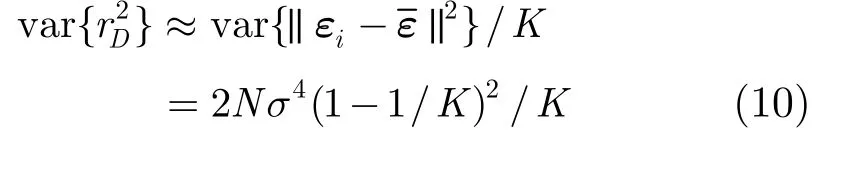
由式(8)和式(10), r2的分子與分母方差的比值為一般這是個遠大于1的數。所以r2的分母相對其分子而言較為穩定,可將視為常量,其大小為
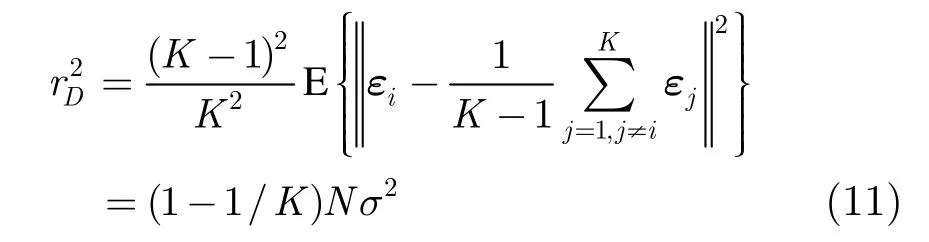
聯合式(6),式(8),式(11),可得到正常模式NR值平方的均值和方差:
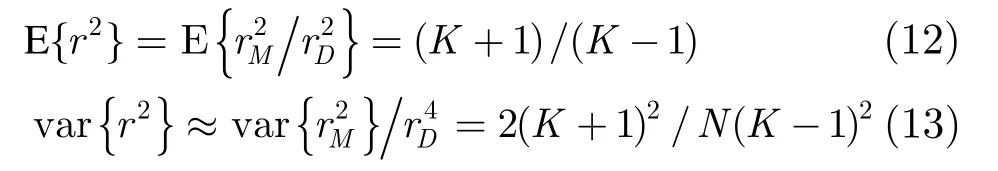
另外,容易證得 r2服從高斯分布。設野值檢測門限為 h≥ 0,利用r和h的非負性,可得本文基于NR的野值檢測方法的虛警概率為
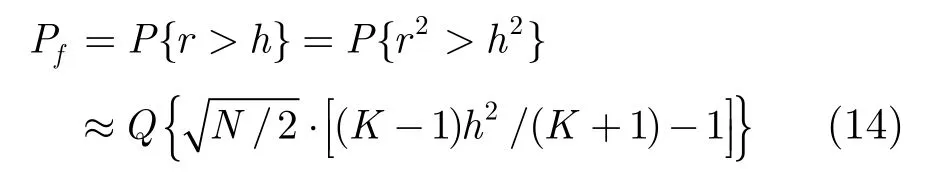
其中 Q{·}是標準高斯分布N(0,1)的右尾概率。
設所需的虛警概率為 α= Pf,根據式(14),可得到本文方法在進行野值檢測時應設置的檢測門限大小為
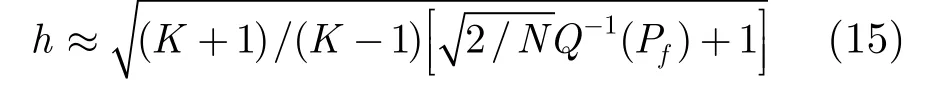
現在考慮色噪聲情形。假設噪聲的均值為零,可設 εi~N( 0, C),其中C是噪聲的協方差矩陣,滿足表示共軛轉置。假設C是已知的,或者通過
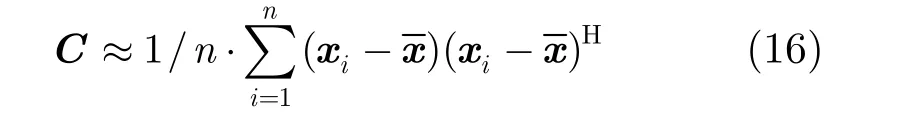
近似計算得到,其中n是訓練樣本數,x是所有訓練樣本的平均。
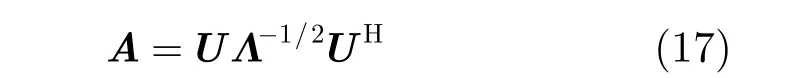
將矩陣A作用在所有訓練樣本以及待考查模式上,那么計算NR時所選訓練樣本變為 Axi=Ax0+ζi,i =1,2,…,K ,待考查模式變為 Axk= Ax0+ ζk,k >K,其中 ζi=Aεi為變換后的模式噪聲。由于
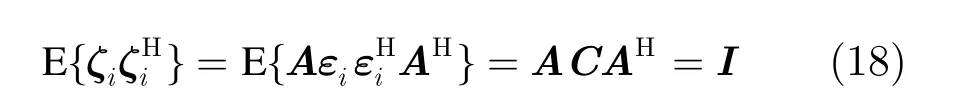
所以經矩陣A變換后模式中的色噪聲變為高斯白噪聲。經過與前文一樣的計算過程,可得到相同的分析結果,即野值門限與虛警概率的對應關系式(15)。這樣利用變換矩陣A就可解決色噪聲情形下野值檢測虛警率的控制問題。
需要說明的是,在訓練樣本數較少時,協方差矩陣C難以由訓練樣本準確估計。此時,可通過先驗信息推算C的大小。一個可行的策略是根據原始數據中噪聲的分布,以及由數據提取訓練/測試樣本時所采取的方法計算出樣本噪聲的協方差矩陣。本文4.2節進行實測數據測試時會給出這方面的例子。下文均假設C是先驗已知的。
3.3 野值檢測方法
(1)對協方差矩陣C進行特征值分解,利用式(17)計算轉換矩陣A,將其作用在訓練樣本及待考查模式上,使得樣本中的噪聲被白化。
(2)根據虛警率 Pf的大小,利用式(15)計算野值檢測門限h。
(3)對于待考查模式 ηi,在 Xtr中隨機選擇K個訓練樣本根據式(4)計算模式 ηi的NR值 ri。
4 實驗與分析
4.1 計算機仿真
考慮到本文在處理色噪聲模式時可將其白化,所以在仿真實驗中只考查白噪聲的情況。設正常模式由 x = x0+ε產生,其中 x0是幅度為1,初相為π,2.5倍周期的正弦波, ε ~N( 0, σ2I ),σ2設為 0.04,所以模式的“信噪比”約為11 dB。野值由 x= y0+ε產生,其中 y0是幅度/初相變化的正弦波或者多項式曲線。
首先驗證虛警概率與野值門限的關系式(14)的正確性。設模式維度N為50或200,訓練樣本的個數 n= 60,計算 NR 值時選擇的訓練樣本數K= 16,計算重復次數 B= 10。另產生1000個正常模式和500個野值模式作為測試樣本,蒙特卡洛仿真500次,得到的結果如圖1所示。可以看出,隨著野值檢測門限的增加,虛警概率逐漸變小。本文理論推算的 Pf-h關系式(式(14))與實驗結果吻合得很好,尤其是當模式維數較高時二者幾乎一致,說明本文野值門限理論推導結果的正確性。
其次考查參數設置對本文方法虛警抑制效果的影響。固定虛警概率 Pf= 0.05,分別改變所選訓練樣本數K和重復計算次數B,其他設置與上一實驗相同,得到的虛警概率測試結果如圖2所示。可以看出,計算NR值時選擇的重復次數B對虛警率的影響比較小,而K的值對虛警率抑制有較大影響,K值太小或太大會分別出現“過抑制”和“欠抑制”的現象。下面的實驗要將本文方法和LPE方法進行性能比較,采用統一的參數設置,為兼顧兩種方法,下文不做特殊說明時均設 B= 10, K= 16。
帶虛警抑制的已有方法中,雖然在一定的實驗條件下aK-LPE方法已被證明具有比K-LPE更優的性能[13,14],但是二者在訓練樣本數較少情況下表現如何尚需實驗檢驗。下面的實驗主要考慮將本文方法與這兩種方法進行性能對比。
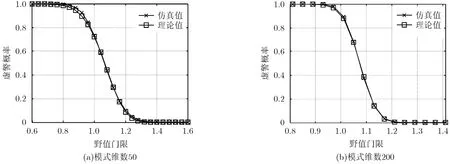
圖1 虛警概率隨野值門限的變化曲線
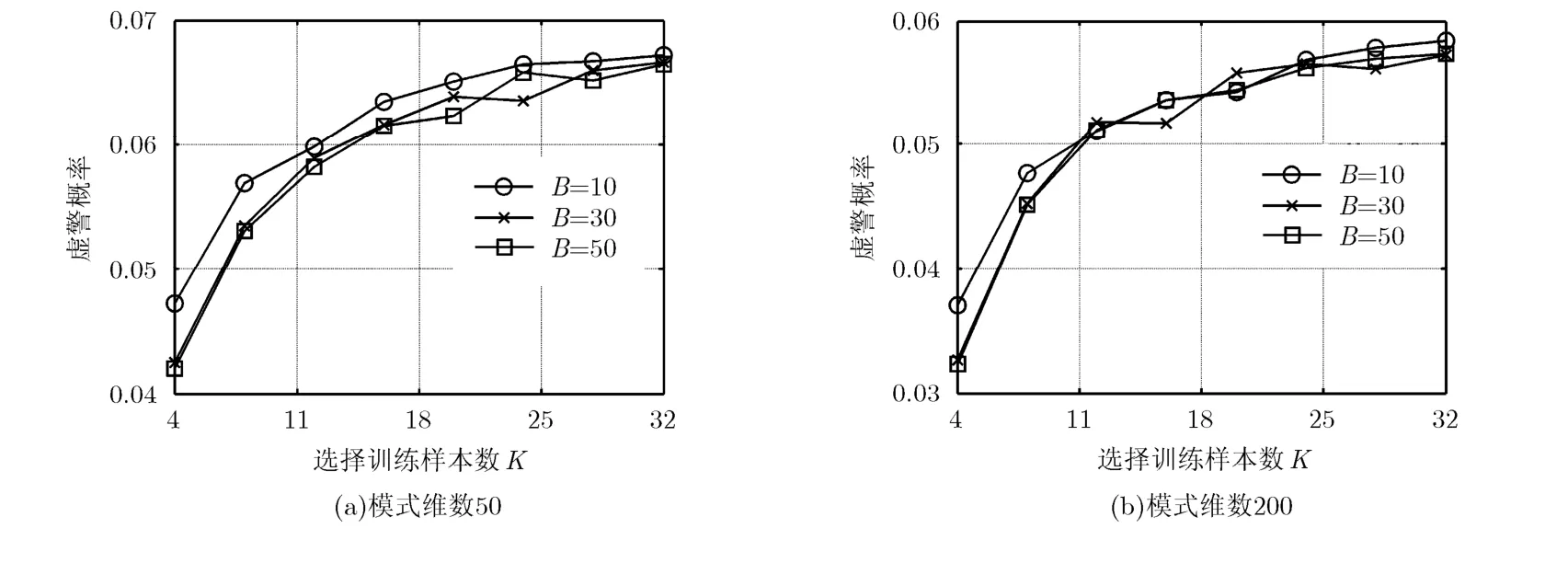
圖2 不同參數設置條件下本文方法得到的虛警概率
現在考查當訓練樣本數較少時本文方法對虛警率的抑制效果。設需要的虛警率為 Pf= 0.05,其他設置與第1個實驗一致,改變訓練樣本數n,得到的實際虛警概率如圖3所示,其中“NR”是指基于NR的野值檢測方法,圖3(b)中虛線第1個點的值為0.783,為便于各方法的對比,圖中沒有顯示該點的值。由于文獻[10]針對的是無監督情形下的野值檢測問題,這里用訓練樣本代替該文獻方法中的初始正常模式集合。該方法的野值檢測門限需要依據經驗或實驗結果人為設置,經過反復測試,為滿足虛警率為0.05的要求,將其檢測門限設為1.08。注意當訓練樣本較少時,LPE方法及本文方法可能無法取到所需數目的訓練樣本,此時可將K值選為能夠利用的訓練樣本數。
由圖3可以看出,本文方法在少量訓練樣本數情況下能夠較好地抑制虛警率,使之接近設定值。在即使只有4個訓練樣本時,本文方法仍能將虛警率抑制在2倍設定值以下,而此時LPE方法的虛警率則超過了設定值5倍以上。而對于文獻[10]中的方法,即使野值門限設置得當,也有可能產生很高的虛警。此外圖3也表明,模式維數N越大,本文方法對虛警率的抑制效果越好。這是由于N越大,3.2節推導野值門限過程中的近似越準確,此時依據式(15)設置檢測門限能更好地控制虛警率。
需要說明的是,文獻[10]提出的方法是無監督的,且沒有在野值檢測門限與虛警率之間建立直接的聯系,其檢測門限需要主觀的人為設置,無法根據虛警率大小預先選擇合適的門限值,所以無法實現真正意義上的虛警控制。鑒于它與本文方法及LPE方法本質上不屬同類,下面的實驗不再考慮該方法。
除虛警率外,野值檢測概率也是重要的性能指標,下面測試本文方法的接收機工作特性(Receiver Operating Characteristic, ROC)曲線。設訓練樣本數 n= 20,模式維數N為50或200,設置不同的虛警率,蒙特卡洛仿真200次,測試得到的ROC曲線如圖4所示,其中“NR”即指本文方法,這一表示同樣適用于后續實驗,橫軸所示的虛警率指的是實際虛警率。可以看出,在較高虛警率條件下本文方法與aK-LPE方法性能相當,說明此時本文方法也可達到 UMP檢驗的效果。但是本文所提野值檢測方法能夠滿足更低虛警率的要求,所以具有更優的綜合檢測性能。
4.2 實測數據測試
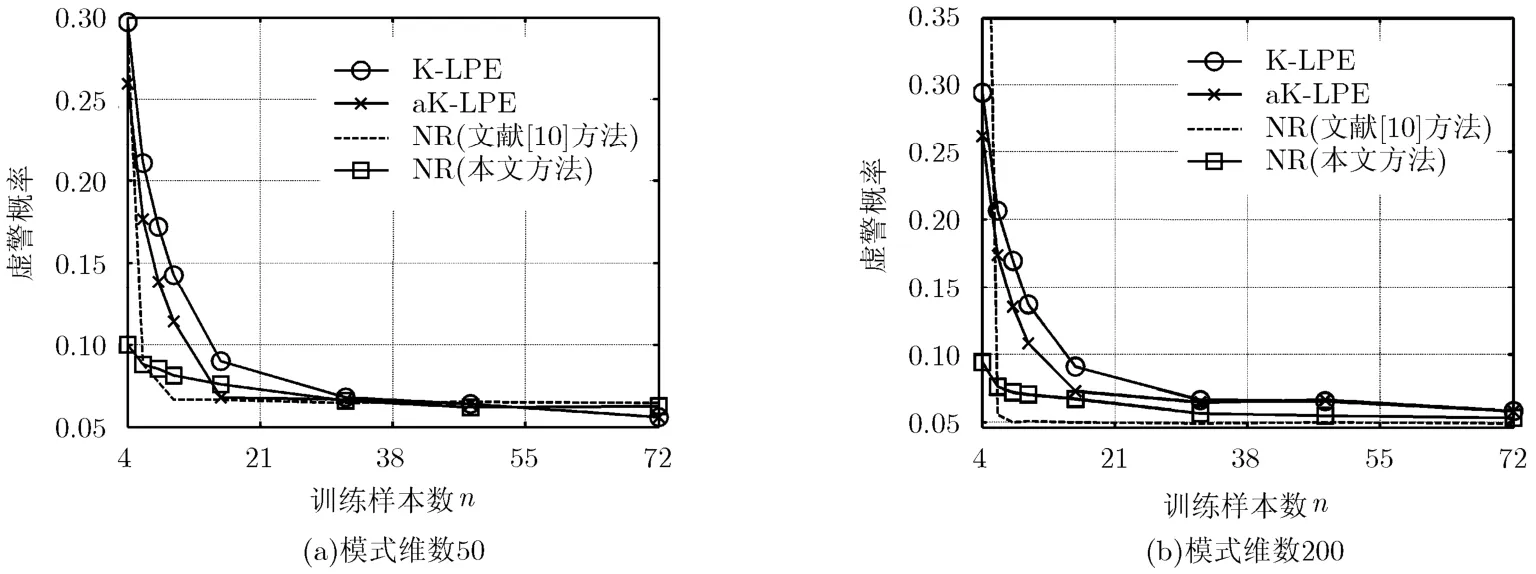
圖3 不同訓練樣本數目條件下的虛警概率測試結果
實測數據測試的場景是:由于分選錯誤或者干擾的存在,某雷達輻射源的一組信號中混入了其他源的信號,一般需要根據信號的特征參量對混入信號進行判別。提取這些信號的特征參量后,經過人工判斷,選出其中一部分特征參量,認為它們來自感興趣的輻射源,將其作為訓練樣本。由于人工挑選比較耗時,得到的訓練樣本數量并不多。現在面臨的問題是,根據已有的訓練樣本,在一定虛警概率的要求下,需對其他特征參量進行野值檢測,從而避免混入信號的影響。
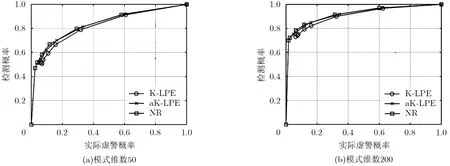
圖4 野值檢測概率隨虛警概率變化的ROC曲線
本文的測試對象是民航飛機的二次雷達(Secondary Surveillance Radar, SSR)信號,它是一種單載頻形式的窄脈沖信號。提取信號的瞬時相位[19]作為考查的特征參量,經過特征平滑,易得特征提取結果為
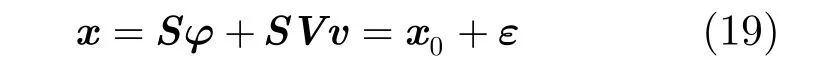
選擇一組SSR信號,它們來自同一輻射源 E0,在這組數據中混入其他兩個輻射源 E1和 E2的信號。本實驗共接收到了69個輻射源的數據,對輻射源按1到69編號,并設 E0= 1,E1= 2,E2= 4。按照式(19)進行特征提取,隨機選擇 E0的一部分特征參量作為訓練樣本,由此對其他樣本進行野值檢測。考查不同訓練樣本數時,虛警率設為考查ROC曲線時,訓練樣本數設為 n= 20。測試樣本由1000個正常模式(即屬于 E0的模式)和來自不同源共600個野值模式組成。野值檢測時需要考慮特征提取過程中引入的協方差矩陣C,按照 3.3節給出的方法流程進行處理,得到的測試結果如圖5所示。圖中數據是100次測試的平均結果。可以看出,對于實測數據,在較少訓練樣本條件下本文方法仍然能夠較好地抑制虛警率,效果優于同類方法。此外其 ROC曲線也較理想,表明其優越的野值檢測性能。
保持參數設置不變,表1給出了混入其他輻射源信號情況下,不同方法野值檢測結果 ROC曲線的線下面積(Area Under the Curve, AUC)大小,其中“維數”是指混入信號的最小樣點數。可以看出,對于所有測試集,本文提出的方法都具有最優的AUC性能。
5 結束語
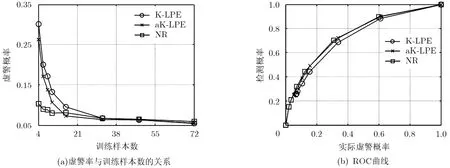
圖5 實測數據測試得到的野值檢測結果
本文考慮了帶監督情形下野值檢測的虛警抑制問題,提出了一種基于歸一化殘差的野值檢測方法。該方法利用訓練樣本重新定義了模式的歸一化殘差,據此,本文推導得到了野值檢測門限與虛警概率之間的關系表達式,為野值門限的設置和野值判別提供了理論依據。仿真實驗和實測數據測試驗證了本文理論推導的正確性,以及少量訓練樣本情況下所提方法在野值檢測和虛警抑制方面的優越性能。
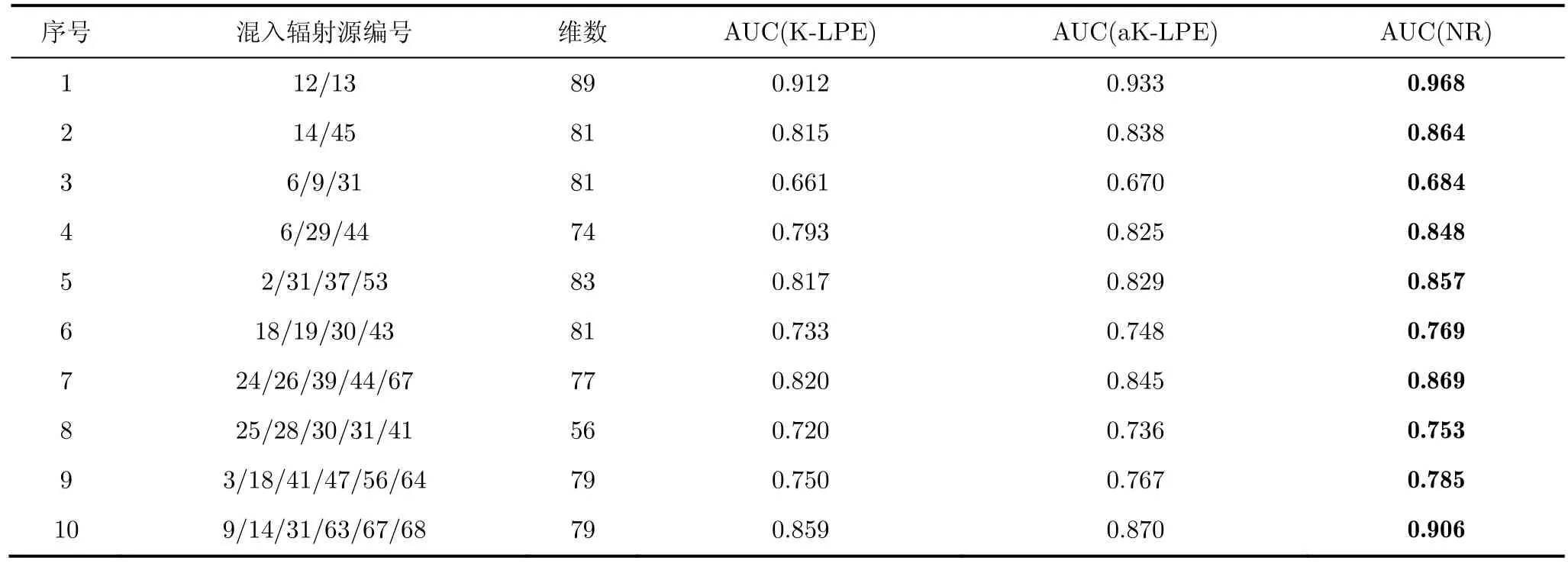
表1 對不同數據集進行野值檢測得到的AUC大小
需要指出的是,本文方法可以適應高斯白噪聲以及能推導出協方差矩陣的色噪聲情形,對于更復雜的噪聲模式,則需要對野值檢測門限進行重新推算以滿足控制虛警概率的要求。這一點可作為下一步的研究方向。
[1] Hawkins D. Identification of Outliers[M]. London: Chapman and Hall, 1980: Chapter 1-2.
[2] Liu J, Wan J, Zheng H, et al.. A method of specific emitter verification based on CSDA and SVDD[C]. Proceedings of the IEEE 2nd International Conference on Computer Science and Network Technology, Changchun, China, 2012: 562-565.
[3] Miller D J and Browning J. A mixture model and EM-based algorithm for class discovery, robust classification, and outlier rejection in mixed labeled/unlabeled data sets[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(11): 1468-1483.
[4] Westerweel J and Scarano F. Universal outlier detection for PIV data[J]. Experiments in Fluids, 2005, 39(6): 1096-1100.
[5] Duncan J, Dabiri D, Hove J, et al.. Universal outlier detection for Particle Image Velocimetry (PIV) and Particle Tracking Velocimetry (PTV) data[J]. Measurement Science and Technology, 2010, 21(5): 57002-57006.
[6] Wu S and Wang S R. Information-theoretic outlier detection for large-scale categorical data[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(3): 589-602.
[7] Li Z G, Baseman R J, Zhu Y D, et al.. A unified framework for outlier detection in trace data analysis[J]. IEEE Transactions on Semiconductor Manufacturing, 2014, 27(1): 95-103.
[8] Albanese A, Pal S K, and Petrosino A. Rough sets, kernel set,and spatiotemporal outlier detection[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1): 194-207.
[9] Ghosh A K and Chaudhuri P. On maximum depth and related classifiers[J]. Scandinavian Journal of Statistics, 2005,32(2): 327-350.
[10] Ru X H, Liu Z, and Jiang W L. Normalized residual-based outlier detection[C]. Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Guilin, China, 2014: 190-193.
[11] Nattorn B, Arthorn L, and Krung S. Outlier detection score based on ordered distance difference[C]. Proceedings of the IEEE International Computer Science and Engineering Conference (ICSEC), Nakhon Pathom, Thailand, 2013: 157-162.
[12] Zhao M and Saligrama V. Anomaly detection with score functions based on nearest neighbor graphs[J]. Advances in Neural Information Processing Systems, 2009, 22(1): 2250-2258.
[13] Qian J and Saligrama V. New statistic in p-value estimation for anomaly detection[C]. Proceedings of the IEEE Statistical Signal Processing Workshop (SSP), Ann Arbor, Michigan,USA, 2012: 393-396.
[14] Chen Y T, Qian J, and Saligrama V. A new one-class SVM for anomaly detection[C]. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, Canada, 2013: 3567-3571.
[15] Breunig M M, Kriegel H-P, Ng R T, et al.. LOF: identifyingdensity-based local outliers[C]. Proceedings of the ACM SIGMOD International Conference on Management of Data,New York, USA, 2000: 93-104.
[16] Sch?lkopf B, Platt J C, Shawe-Taylor J C, et al.. Estimating the support of a high-dimensional distribution[J]. Neural Computation, 2001, 13(7): 1443-1471.
[17] Furlani M, Tuia D, Munoz-Mari J, et al.. Discovering single classes in remote sensing images with active learning[C]. Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany,2012: 7341-7344.
[18] Jumutc V and Suykens J. Multi-class supervised novelty detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(12): 2510-2523.
[19] 葉浩歡, 柳征, 姜文利. 考慮多普勒效應的脈沖無意調制特征比較[J]. 電子與信息學報, 2012, 34(11): 2654-2659. Ye H H, Liu Z, and Jiang W L. A comparison of unintentional modulation on pulse features with the consideration of Doppler effect[J]. Journal of Electronics & Information Technology, 2012, 34(11): 2654-2659.
汝小虎: 男,1988年生,博士生,研究方向為雷達輻射源識別.
柳 征: 男,1978年生,博士,副研究員,研究方向為綜合電子戰信息戰技術、航天電子偵察信號處理.
姜文利: 男,1967年生,博士,教授,博士生導師,研究方向為綜合電子戰信息戰技術、航天電子偵察信號處理.
黃知濤: 男,1976年生,博士,教授,博士生導師,研究方向為綜合電子戰信息戰技術、衛星通信偵察與對抗.
Normalized Residual-based Outlier Detection with False-alarm Probability Controlling
Ru Xiao-hu Liu Zheng Jiang Wen-li Huang Zhi-tao
(College of Electronic Science and Engineering, National University of Defense Technology, Changsha 410073, China)
Outlier detection, also called anomaly detection, is an important issue in pattern recognition and knowledge discovery. Previous outlier detection methods can not effectively control the false-alarm probability. To solve the problem, a supervised method based on Normalized Residual (NR) is proposed. Using the training patterns, it first calculates the NR value of the query pattern, which is compared with a predefined detection threshold to determine whether the pattern is an outlier. In this paper, the relationship between the threshold and false-alarm probability is theoretically derived, based on which an appropriate threshold can be chosen. In this way,the desired false-alarm probability can be obtained even when few training patterns are available. Simulations and measured data experiments validate the superior performance of the proposed method on outlier detection and false-alarm probability controlling.
Pattern recognition; Supervised; Outlier detection; False-alarm probability; Normalized Residual (NR)
TP391.4; O235
A
1009-5896(2015)12-2898-08
10.11999/JEIT150469
2015-04-22;改回日期:2015-09-01;網絡出版:2015-11-01
*通信作者:汝小虎 ruxiaohu88@163.com
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
