一種虛擬機負載均衡調度算法
2015-08-09 02:29:46張瑩李華
河南科技 2015年12期
張 瑩 李 華
(國家知識產權局專利局專利審查協作河南中心,河南 鄭州 450000)
虛擬化技術是企業創建綠色數據中心的核心技術之一,多處理器技術的快速發展使計算能力有了突破性的提高,同時也使虛擬化技術成為研究熱點。虛擬化技術通過在底層物理環境與虛擬機之間建立虛擬機監視層,從而屏蔽了復雜的底層物理環境,使物理機硬件資源不僅能夠同時被多個虛擬機共享,處于運行狀態的虛擬機還可以在兩臺不同的物理機之間進行無間斷的遷移[1]。因此,為了合并服務器資源和應用,虛擬化技術逐漸成為大型企業構建安全穩定的企業架構的最佳解決方案。
目前,在商業發展和開源技術研究中有多種虛擬化架構,其中包括劍橋大學的XEN。在Xen中,多個虛擬機同時運行在相互隔離的虛擬環境中,共享底層物理硬件,包括處理器資源,且各個虛擬機能夠以接近物理計算系統的性能運作[2]。Xen中常用的三種CPU調度算法包括:BVT(借用虛擬時間算法)、SEDF(最早截止時間優先算法)和基于信任值算法(Credit),三種算法各有不同的性能瓶頸,因此,如何實現高效調度成為虛擬化技術中面臨的更大挑戰。
專利CN102053858A中提出了一種虛擬機調度算法,通過監測虛擬機的CPU 調度以及狀態標識信息,解決了鎖搶占問題,從而在多處理器架構中實現更精確的可調度狀態監測,提高底層物理CPU 資源的利用率[3]。華中科技大學的金海提出了一種Xen虛擬化環境中動態感知音頻應用的CPU 調度算法,通過設置合適的時間片大小以及增加實時優先級等策略,提高了Xen 中音頻應用的播放性能[4]。
本文提出了一種SMP(對稱多處理器)系統中的動態負載均衡調度算法—動態最早截止時間優先算法(DLB_DEF)來提高物理CPU 利用率,從而減少空閑CPU。為了實現該算法,我們設計了一種共享等待隊列,考慮到多處理器環境中cache和內存的同步關系,使虛擬CPU在執行完任務之前都在同一個物理CPU上執行。仿真實驗表明,改進后的DLB_DEF 算法能夠優化系統性能,并完全消除空閑物理CPU。
2 SEDF算法以及SMP架構
2.1 SEDF算法
在虛擬化計算環境中,多個虛擬機通過分時調度策略共享物理處理器資源,每個虛擬機就是一個域,每個域對應一個或多個虛擬CPU(VCPU)[5]。因此,如何公平高效地將物理CPU 資源分配給多個虛擬機,并使CPU 有效利用率達到合理范圍就是一個問題。
SEDF 算法是一種基于最早截止時間策略的實時算法,每個VCPU都會根據自身處理情況設置一個參數:最早截止期限(deadline),SEDF根據該時間參數決定VCPU的調度順序[6],而且VCPU 的優先級根據deadline 的改變而變化。SEDF 算法將調度具有最早截止時間的VCPU,從而保證虛擬機任務能及時完成。
每個域都設置一個三元組(s, p, x),時間片s 和周期時間p共同表示該域請求的CPU份額和時間,flag是一個boolean 類型的值,表示該域是否能夠占用額外的CPU 份額,三個參數時間粒度的設置對調度的公平性影響很大。VCPU 結構體的屬性如圖1 所示,每個PCPU 包含2個雙鏈表隊列,如圖2所示。

圖1 VCPU結構體

圖2 PCPU的雙鏈表隊列
runnableq 隊列中的VCPU 都是處于running 或runnable狀態,根據deadline參數排序,隊首的VCPU處于running 狀態,而其他VCPU 都處于runnable 狀態,必須在deadline規定時間內執行調度;waitq隊列中的VCPU處于runnable狀態,還未開始計時。
總之,SEDF 算法可以通過參數動態配置VCPU 的優先級,因此在負載較大的實時系統中具有較高性能,當系統負載較小時其CPU 使用率可以達到100%,然而,隨著負載逐漸增大,一些任務就會發生時間錯誤,錯過截止期來不及處理而夭折。另外,SEDF 算法不支持SMP 架構,從而不能實現對多CPU間全局負載均衡的控制。
2.2 SMP架構
在SMP架構中,多個處理器共享內存,但每個處理器都對應一個私有cache,大多數調度算法都遵循就近原則執行調度,也就是說首選本地CPU來執行相應的任務,從而提高cache 命中率。當一個私有cache 被修改后,就要考慮內存和cache之間的一致性問題,即不僅要確保修改后cache和相應內存之間的一致性,而且要確保內存和其他cache 之間的一致性。在執行過程中,VCPU 可能會處于掛起狀態,比如時間片到或被其他事件阻塞,此時VCPU 雖然停止執行,但是其對應的私有cache 中還保存著運行時環境[7],當處于掛起狀態的VCPU 被再次喚醒時,使其在上次執行過的物理CPU上繼續執行,從而減少數據一致性產生,即就近調度原則。
為了提高CPU資源的利用率,就要重視cache和內存一致性帶來的性能消耗問題。即VCPU 在PCPU 之間的頻繁調度會產生嚴重的cache抖動,進而使數據一致性問題產生額外的性能損耗,嚴重降低CPU執行速度[8]。
3 DLB_DEF算法的設計
通過上節中對SEDF 算法的分析可知:SEDF 在實時性環境中具有較好性能,但不支持SMP 架構,如果一個CPU空閑,它只能等待新的VCPU任務到來,而此時其他CPU 的任務量可能已經超載,此時SMP 架構中的多處理器系統的物理性能遠低于具有相同處理器個數的系統。基于此研究結論,本文提出一種基于SMP 架構的虛擬機負載均衡調度算法——DLB_DEF算法。
在DLB_DEF 算法中,共享隊列shareWaitq 中的VCPU 按照deadline 參數進行排序,且都處于runnable 狀態,如圖3所示為shareWaitq結構體屬性:

圖3 shareWaitq結構體
每個PCPU 具有不同的等待時間權值,即為對應runnableq 隊列中存放的VCPU 的運行時間總和。當PCPU 空閑時就從共享等待隊列中調取VCPU 任務,同時,考慮到cache 就近原則,將該VCPU 任務上次執行過的PCPU 記作pre_pcpu,改進后CPU 和VCPU 的結構體屬性分別如圖4和圖5所示:
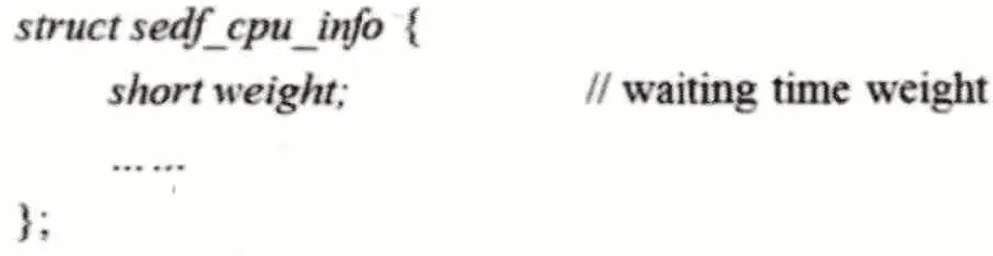
圖4 改進后的PCPU結構體

圖5 改進后的VCPU結構體
假設物理機有M個可運行的PCPU,如式(1)所示;式(2)為runnableq隊列中的所有VCPU;式(3)為所有PCPU的weight集合;式(4)為weight集合中的最小時間權值。
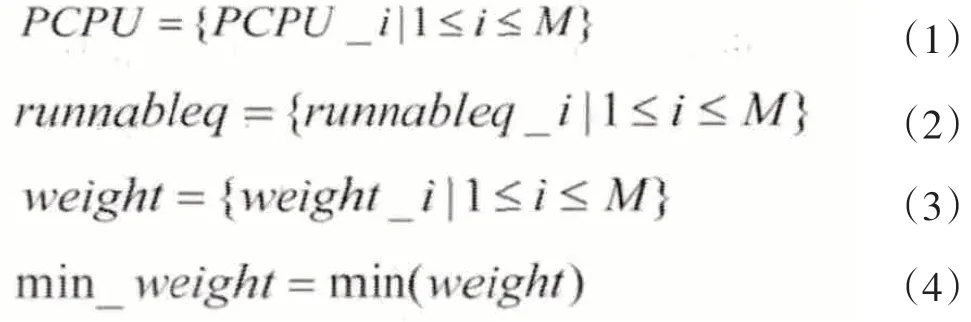
改進后的動態負載均衡算法DLB_DEF與SEDF算法相同,PCPU都是優先調用具有最早截止期限的VCPU,通過增加并實時更新共享等待隊列shareWaitq,從而實現動態負載均衡。DLB_DEF算法如圖6所示:

圖6 DLB_DEF算法
4 仿真實驗與結果
4.1 仿真平臺及環境配置
Schedsim 是一種CPU 調度模擬器,提供了良好的接口,能夠實現先來先服務算法、短作業優先算法等多種常見的調度算法[9]。基于Schedsim,本文設計并實現了SEDF 算法和改進后的DLB_EDF 算法,并模擬了兩種算法在不同數量處理器上的調度情況,最后對兩種算法調度的系統性能進行了分析和比較。
將SEDF 和DLB_EDF 中的一個VCPU 任務記作一個進程,由5個參數表示:進程ID 號、優先級、就緒時間、執行時間和最早截止期限。為了滿足仿真實驗的需要,假設PCPU個數最大為6,配置5個進程池,分別包含10、20、40、60、80個進程,仿真實驗步驟如下:
步驟1:創建的進程池至少符合以下要求:①2個就緒時間相同而最早截止期限不同的進程,②2個就緒時間和最早截止期限都相同的進程,③2個執行時間不同而就緒時間和最早截止期限相同的進程,④2個分別具有不同的就緒時間、執行時間和最早截止期限的進程,⑤就緒時間與執行時間之和大于最早截止期限的2個進程,⑥將所有進程的最早截止期限設置為與優先級成反比。
步驟2:進程池中的所有進程入隊。
步驟3:配置PCPU個數,選擇調度算法和調度模式。
步驟4:運行模擬器。
以下實驗結果是以包含40個VCPU的進程池作為參考,對每個進程池分別做10 組測試,并取10 組數據的平均值。
4.2 仿真結果分析
當兩個算法的進程都完成時,如圖7、圖8、圖9 分別為系統吞吐量、平均周轉時間和平均應答時間的比較結果。
通過圖7-9我們可以看到,當PCPU個數為1時,由于需要考慮cache 就近原則,因此DLB_DEF 的系統吞吐量和任務完成率比SEDF算法略小,但是平均周轉時間以及平均響應時間比SEDF略大;當PCPU個數增多,即在支持SMP 架構的多處理系統中,具有負載均衡策略的DLB_DEF 算法的各個性能指標都略超過SEDF,系統吞吐量和任務完成率逐漸增大,平均周轉時間以及平均響應時間卻逐漸減小。特別地,當DLB_DEF 和SEDF 的系統吞吐量具有最大差值時,PCPU個數等于4,即在PCPU為4時DLB_DEF算法具有最優性能。當PCPU個數繼續增大為6 時,SEDF 算法由于空閑PCPU 的出現而導致多種系統指標性能降低,而此時,在DLB_DEF算法中,雖然PCPU個數增多,但由于共享等待隊列的互斥性,PCPU調用任務時等待互斥鎖的解鎖時間逐漸增大,同時,共享等待隊列的更新也要占用更多時間,因此,DLB_DEF 算法的系統吞吐量、任務完成率、平均周轉時間以及平均響應時間也逐漸達到平穩狀態。
當PCPU個數逐漸增多時,即具有更多處理器來執行系統任務時,SEDF 和改進后的DLB_DEF 算法的任務完成數和任務完成率都逐漸增大,但是兩者的完成率都達不到100%,即有些VCPU 由于錯過截止時間而錯過執行的機會,但是DLB_DEF 在總體上完成量比SEDF多。
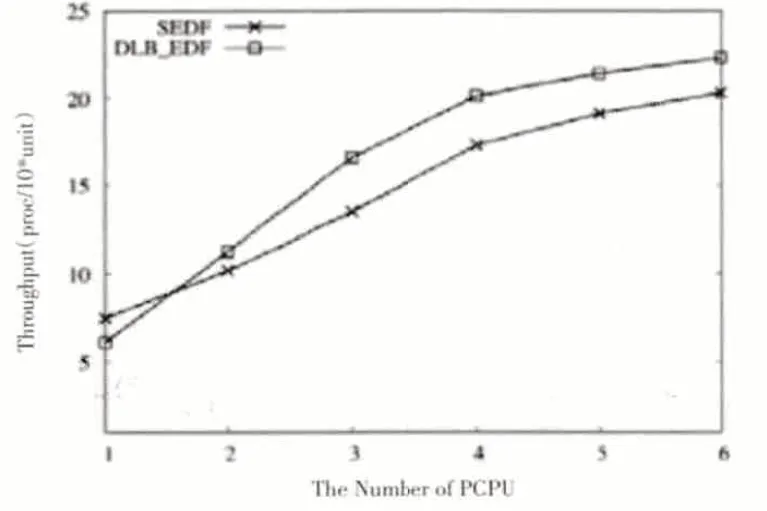
圖7 系統吞吐量對比
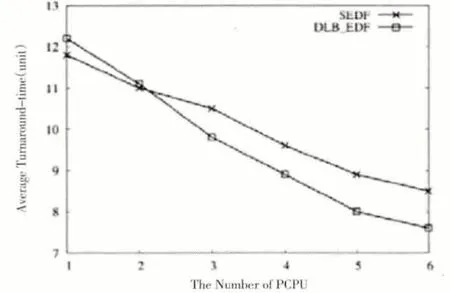
圖8 平均周轉時間對比
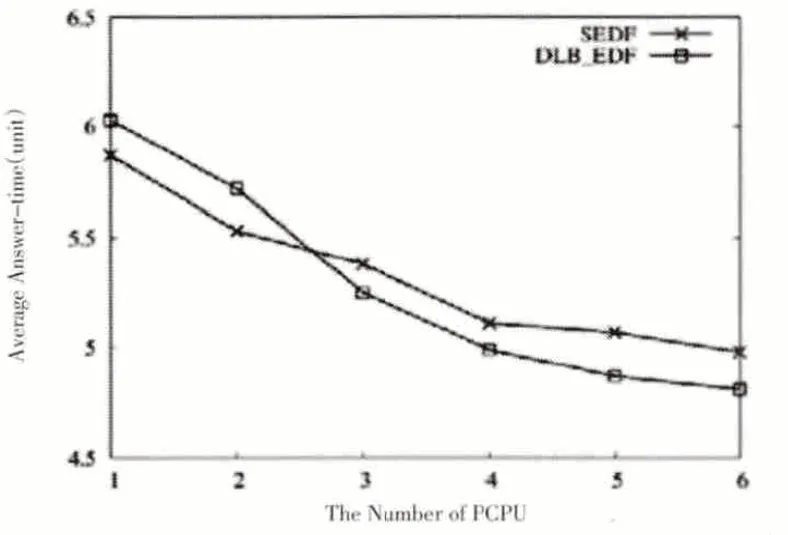
圖9 平均應答時間對比
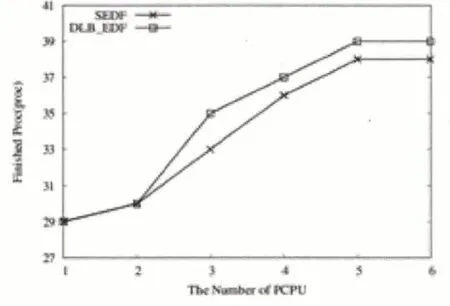
圖10 完成進程數對比
5 總結
本文主要對SEDF算法進行分析,針對其不支持SMP架構的不足,提出一種動態負載均衡算法DLB_DEF。該算法設計了一個共享等待隊列存儲VCPU 任務,并根據cache就近原則和PCPU的等待時間權值,VCPU可選擇最優PCPU 執行其任務。DLB_DEF 算法不僅可以降低cache 抖動帶來的性能損耗,還可以通過獲取PCPU 的最小等待權值來增大PCPU使用率。最后,在Schedsim仿真環境中模擬SEDF和DLB_DEF,仿真結果表明,DLB_DEF在系統吞吐量、平均周轉時間和應答時間、進程完成率等性能指標上都略優于SEDF 算法。目前僅在模擬環境中執行DLB_DEF 算法,下一步任務要將DLB_DEF 嵌入到XEN源代碼中并運行在真實虛擬環境中。
[1]懷進鵬,李沁,胡春明. 基于虛擬機的虛擬計算環境的研究與發展[J]. 軟件學報,2007,18(8):1016-1026.
[2] Paul Barham,Ian Pratt,Keir Fraser,et al,“Xen and the art of virtualization,”In SOSP’03:Proc of the nineteenth ACM symposium on Operating systems principles,New York,ACM,2003,15:164-177.
[3]金海,吳松,石宣化,等. 一種虛擬CPU 調度方法[P].中國專利,102053858,2011-05-11.
[4] Huacai Chen,Hai Jin,Kan Hu,et al.“Adaptive audio-aware scheduling in Xen virtual environment,”In AICCSA’10: Proc of the ACS/IEEE International Conference on Computer Systems and Applications. USA, IEEE Computer Society Washington,2010:1-8.
[5]Hyunsik Choi,Saeyoung Han,Sungyong Park and Eunji Yang,“A CPU Provision Scheme Considering Virtual Machine Scheduling Delays in Xen Virtualized Environment,”TENCON’09:2009 IEEE Region 10 Conference.2009:1-6.
[6]Xinjie Zhang,Dongsheng Yin,“Real-time Improvement of VCPU Scheduling Algorithm on Xen,”In CSSS’11: Computer Science and Service System.2011:1506-1509.
[7]常建忠,劉曉建.虛擬機協同調度問題研究. 計算機工程與應用,2011,47(6):38-41.
[8] Min Lee, A.S.Krishnakumar, P.Krishnan et al.“Supporting Soft Real-Time Tasks in the Xen Hypervisor,”In VEE '10: Proceedings of the 6th ACM SIGPLAN/SIGOPS international conference on Virtual execution environments[J].New York,ACM,2010,45:97-108.
[9]姚文斌,鄭興杰.一種改進的SEDF 算法[J].小型微型計算機系統.2010,31(3):446-450.
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中國外匯(2019年20期)2019-11-25 09:54:58
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
家庭影院技術(2017年9期)2017-09-26 03:41:45
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
中學生(2015年2期)2015-03-01 03:43:33
民主與科學(2014年3期)2014-02-28 11:23:03
