基于內(nèi)容的語音檢索方法探究
2015-07-23 03:07:18李峰泉蘇培華
電子測試 2015年2期
李峰泉,蘇培華
(西安外事學(xué)院工學(xué)院,陜西西安,710077)
1 語音識別的意義
近年來,人工神經(jīng)網(wǎng)絡(luò)的研究有了飛速發(fā)展,語音信號處理的各項課題是促進(jìn)其發(fā)展的重要動力之一,同時,它的很多研究成果也體現(xiàn)在有關(guān)語音的各項應(yīng)用之中。目前,世界上涌現(xiàn)了其它一些新研究課題,諸如模糊理論、混沌理論和小波(Wavelet)信號處理等,也都能夠在語音信號處理的研究中找到用武之地。
語音信號數(shù)字處理涉及一系列前沿科研課題,是目前發(fā)展最迅速的信息科學(xué)研究諸領(lǐng)域中的一個。正如其他數(shù)字處理研究課題,語音處理的研究涉及三方面互相密切配合的任務(wù)和課題,這就是,應(yīng)用、算法(包括基礎(chǔ)理論和軟件)和硬件系統(tǒng),三者缺一不可。
語音識別的起步較晚,大規(guī)模的研究開始于70年代初期,近年來已取得了長足的進(jìn)展。它可以用于人機(jī)直接對話、語音打字機(jī)以及兩種語言之間的直接通信等一系列重要場合。語音合成是人機(jī)對話的另一個重要環(huán)節(jié),讓機(jī)器將文本語言轉(zhuǎn)換成具有人聲特點、抑揚(yáng)頓錯、自然流利的口頭語言絕非易事,這一研究課題也正日益受到重視。其它一些重要的應(yīng)用領(lǐng)域還包括語音增強(qiáng)和說話人識別及確認(rèn)等。
2 語音識別模型的建立
語音識別模型起始于用戶創(chuàng)建的語音信號,以完成一個給定任務(wù)。遵循任務(wù)的語法、語義、語用,將輸入信號分解成一系列單詞。根據(jù)初步處理結(jié)果,使用動態(tài)知識表述的高級處理來修正語法、語義、語用,使其成為有意義的詞句。用這種方法將不合理的推理或結(jié)論刪去,以減小被誤解的概率。高級處理框的回饋限制了用戶的有效語音的搜索范圍,從而減少了識別模型的復(fù)雜度。識別系統(tǒng)以語音形式響應(yīng)用戶,從而使系統(tǒng)可以即時響應(yīng)用戶。
語音識別系統(tǒng)的基本任務(wù)是準(zhǔn)確地識別、理解講話的內(nèi)容,是對語音共性的識別。
以所要識別的單位來分,有孤立詞識別、音素識別、音節(jié)識別、單句識別、連續(xù)語言識別和理解。語音理解是在語音識別的基礎(chǔ)上,用語言學(xué)知識來推斷語音的含義。語音理解系統(tǒng)是更高一級的語音識別系統(tǒng)。這類語音識別的發(fā)展情況是先從最原始的單音節(jié)識別,到限定數(shù)量的單詞識別,再到對內(nèi)容進(jìn)行某種程度限制的會話識別。其模型示意圖如圖1所示。
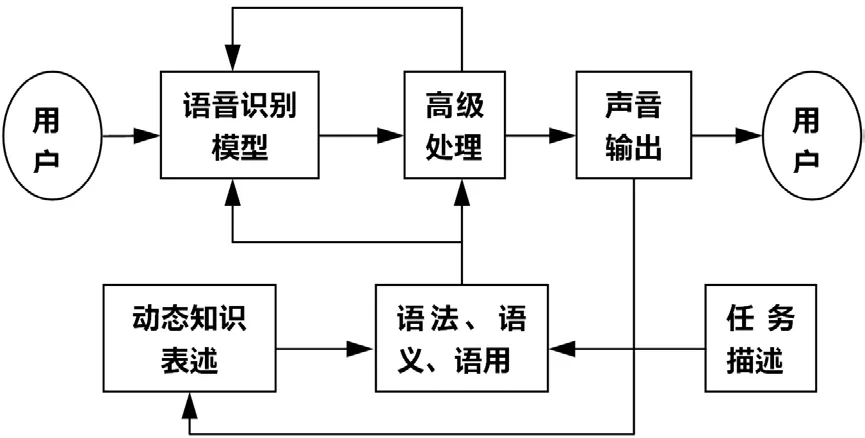
圖1 通用語音識別系統(tǒng)模型
3 語音識別系統(tǒng)現(xiàn)狀
通用DSP芯片的出現(xiàn)及其性能價格比的迅速提高為各種使用化語音信號處理系統(tǒng)的實現(xiàn)鋪平了道路。美國TI公司在80年代中期研制出的第一代DSP芯片TMS32010和TMS32020完成一次乘/累加運(yùn)算(16位、定點)需要200ns,第二代DSP芯片TMS320C25完成一次乘/累加(32位、浮點)運(yùn)算只需要50ns,且片內(nèi)的ROM和RAM和片外可擴(kuò)充的RAM容量都大大增加。此外,美國AT&T公司研制出的DSP-16C和DSP-32C,美國AD公司研制出的ADSP21010和ADSP21020等芯片系列與上述TI公司的第二代和第三代DSP芯片大致處在相似的水平上。第三代DSP芯片及更高一代的DSP芯片的出現(xiàn)將使語音信號數(shù)字處理技術(shù)的發(fā)展和實用化登上一更高的新臺階。
一些采用計算機(jī)語音識別技術(shù)研制成的系統(tǒng)已投入使用。如航空查詢和購票服務(wù)系統(tǒng),用于顧客和航空公司的計算機(jī)之間關(guān)于機(jī)票查詢及記帳購票的服務(wù)。再如日本新干線火車預(yù)約座位系統(tǒng),它叫作VoiceQ-A系統(tǒng)(語音問答系統(tǒng))。它在問訊時進(jìn)行會話識別,而在回答時進(jìn)行語音合成輸出。又如瑞典的語音識別系統(tǒng),它已被瑞典Ericsson公司用來裝備內(nèi)部快呼通訊網(wǎng),使用這種系統(tǒng)打電話時,人們不必再撥號或按數(shù)字鍵,只需說出受話人的姓名便可以接通了。這個系統(tǒng)比日本東芝公司的語音撥號電話機(jī)更為先進(jìn)。后者僅能識別數(shù)字,而前者能識別相當(dāng)數(shù)量的詞或詞組。采用語音識別的產(chǎn)品還有聲控打字機(jī)、聲控攝影機(jī)、聲控卡拉OK機(jī)等。
在我國,語音技術(shù)的研究起步較晚,投入的研究單位和人員也比較少。語音技術(shù)的產(chǎn)品較少,技術(shù)性能也比較差,功能比較簡單,應(yīng)用領(lǐng)域也比較少。
4 語音識別策略
4.1 語音信號處理方法
在進(jìn)行語音識別之前,必須先了解語音的生理學(xué)過程、語音基礎(chǔ)知識及有關(guān)的聲學(xué)基礎(chǔ)知識有助于作出正確的語音分析,有助于提高語音的識別率。
4.2 策略概要
根據(jù)上面的描述,本文采用如下算法分析了特征表征聲音的效果,并提出了有效的索引算法,可以滿足查詢的需要。具體原理如圖2所示。
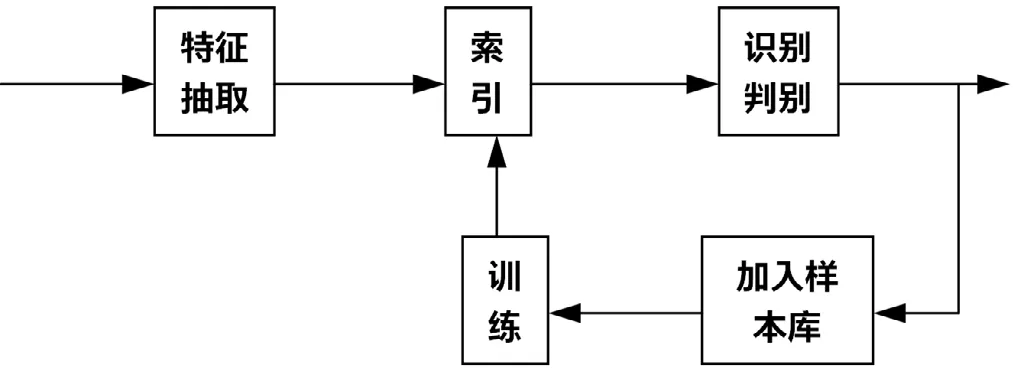
圖2 非特定人語音識別系統(tǒng)原理圖
4.3 語音分析(語音特征抽取)
語音信號的特征抽取的成功與否直接影響語音識別的效果。目前這項工作多由計算機(jī)完成。計算機(jī)語音分析(語音特征抽取)是計算機(jī)語音處理的一個重要內(nèi)容,也是計算機(jī)語音合成及語音識別的基礎(chǔ)。計算機(jī)合成的語音音質(zhì)的好壞、計算機(jī)語言識別率的高低,都取決于計算機(jī)分析工作質(zhì)量的好壞。語音分析有時域分析、頻譜分析和語譜分析三種方法。這三種方法分別由一種圖形來表示。時域分析用時域波形圖,頻譜分析用頻譜圖,語譜分析用語譜圖。常用的語音分析方法有由于頻譜分析方法獲得的特征相對比較穩(wěn)定,分析數(shù)據(jù)又不需要特殊的儀器,是語音分析方法中較好的選擇。
4.4 索引
傳統(tǒng)的數(shù)據(jù)庫索引技術(shù)是基于關(guān)鍵字字段的算術(shù)運(yùn)算:大小比較和包含關(guān)系運(yùn)算。索引的構(gòu)造主要是利用傳遞性將記錄排序,然后劃分為不同的區(qū)間,區(qū)間再劃分為子區(qū)間,層層下去構(gòu)造出一棵索引樹。然而,多媒體的特征都是多維的,記錄間是一種相似關(guān)系,這種關(guān)系運(yùn)算只具有自反性、對稱性,卻沒有傳遞性。這主要是由于多維引起的。因此,傳統(tǒng)的構(gòu)造索引樹的方法不再適用。
聲音索引主要解決查找的正確性問題。單詞內(nèi)容的最后判定是根據(jù)所獲得的相似結(jié)果集得到的。索引的算法要能保證查找的結(jié)果是有效和有用的。索引的查找速度也是索引性能的一個重要指標(biāo)。對于數(shù)據(jù)庫而言,索引的最終目的就是加快查找的速度。和已有的算法相比選用基于SOM和統(tǒng)計檢驗的算法是一種方便的選擇。
4.5 特征匹配及識別
幾乎在所有的聲音識別中,作為識別判定的基礎(chǔ),都采用了輸入聲音和標(biāo)準(zhǔn)圖案的短時頻譜間的距離或相似度。在聲音識別中,為了使兩個矢量x,y的距離尺度d(x,y)有效,希望其具有如下性質(zhì):

根據(jù)數(shù)學(xué)定義,d(x,y)表示距離,則 d(x,y)必須滿足三角不等式。但在聲音識別中,這一項要求并非是必須的。
即使同一個人發(fā)同一個單詞,其發(fā)音長度也會發(fā)生變化,而且按非線形伸縮。為此在識別單詞的階段,對應(yīng)標(biāo)準(zhǔn)和輸入聲音的相同音素之間,都需要對時間軸進(jìn)行按非線形伸縮的時間歸一化(DTW:dynamic time warping)處理,具體方法可采用動態(tài)程序設(shè)計法(DP:dynamic programming)。最先在聲音的時間歸一化問題上使用DP法的是蘇聯(lián)的Slutsker、Vintsyuk、Velichko和Zagoruyko等人,日本的迫江、千葉等人幾乎在同一時期發(fā)表了類似的論文。其后,這種方法對聲音識別產(chǎn)生了很大影響,成為重要技術(shù)之一。
5 系統(tǒng)測試
運(yùn)用基于SOM和統(tǒng)計檢驗的索引算法的非特定人語音識別系統(tǒng)AudioHouse已經(jīng)初步實現(xiàn)。該系統(tǒng)集合了聲音采樣、特征抽取、索引處理、語音識別及一些處理輔助工具等模塊。
聲音采樣模塊是方便說話人錄制指定采樣單詞語音的工具。特征抽取模塊集合了LPC、倒譜、Gabor濾波等特征抽取方法。用戶可根據(jù)需要選擇相應(yīng)特征。索引處理是系統(tǒng)的核心算法所在。它提供了基于SOM和統(tǒng)計檢驗的索引算法,以及加權(quán)二重索引算法。語音識別模塊是計算索引算法查詢出的相似聲音文件的加權(quán)相似度,對查詢樣本作出最終判斷。
通過測試可以發(fā)現(xiàn),倒譜系數(shù)可以較好的描述發(fā)音單詞的特征;Gabor濾波法可以較好的刻畫說話人的韻律特征;LPC系數(shù)對單詞和說話人的識別效果均為中上,而且其特征抽取速度最快。單個數(shù)字所含信息量較少,彼此發(fā)音差距也比較大,所以比較容易識別。單詞的變化比較多,混淆的概率比較大。實驗證明,當(dāng)被識別的單詞有所減少的時候,單詞的識別率會有所提高。進(jìn)一步研究漢語的語音特征會有助于提高單詞的識別率。
猜你喜歡
小學(xué)科學(xué)(學(xué)生版)(2021年7期)2021-07-28 06:44:42
科技傳播(2019年22期)2020-01-14 03:06:34
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
消費(fèi)導(dǎo)刊(2017年20期)2018-01-03 06:26:40
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
衡陽師范學(xué)院學(xué)報(2015年3期)2015-02-10 06:02:23
河南科技(2014年23期)2014-02-27 14:19:15
