基于聚類的高效(K,L)-匿名隱私保護
2015-06-27 08:26:03柴瑞敏馮慧慧
計算機工程 2015年1期
關鍵詞:信息
柴瑞敏,馮慧慧
(遼寧工程技術大學電子與信息工程學院,遼寧葫蘆島125105)
基于聚類的高效(K,L)-匿名隱私保護
柴瑞敏,馮慧慧
(遼寧工程技術大學電子與信息工程學院,遼寧葫蘆島125105)
為防止發布數據中敏感信息泄露,提出一種基于聚類的匿名保護算法。分析易被忽略的準標識符對敏感屬性的影響,利用改進的K-means聚類算法對數據進行敏感屬性聚類,使類內數據更相似。考慮等價類內敏感屬性的多樣性,對待發布表使用(K,L)-匿名算法進行聚類。實驗結果表明,與傳統K-匿名算法相比,該算法在實現隱私保護的同時,數據信息損失較少,執行時間較短。
(K,L)-匿名;敏感屬性;隱私保護;信息損失;聚類;K-means算法
1 概述
隨著計算機網絡和數據庫等相關技術的快速發展,醫療、銀行賬戶、電子郵件等各種系統廣泛的滲透于生活應用中,應用系統數據庫中的個體數據,被過度地用于數據挖掘和數據發布,這就導致個人的隱私信息極易被暴露,用戶的隱私安全得不到保障,工作生活受到影響,嚴重的甚至危及生命。因此,個人的隱私保護成為丞待解決的問題,許多隱私保護方法也被提出。常用方法是在數據發布前,先對數據預處理,把能夠顯示身份特征的屬性(如姓名、身份證號等)去掉,該方法雖然有一定功效,但隱私信息泄露仍然存在。文獻[1]研究表明,把美國的選民登記表和去掉身份特征標識的醫療信息表利用郵編、性別、年齡等屬性進行鏈接,至少87%的美國公民的個人信息都可以被檢測出來,造成隱私嚴重泄露。針對數據匿名發布中的隱私泄露問題,本文提出一種基于聚類的匿名保護算法,考慮背景知識攻擊和一致性攻擊的影響,減少數據匿名后的信息損失。
2 相關工作
為實驗數據隱私保護,1998年,K-匿名(K-anonymity)技術被Samarati和L.Sweeney在PODS上率先提出,引起很大關注。K-匿名技術表現為,將每個個體的敏感屬性隱藏在規模為K的群體中,方法簡單實用,被廣泛應用及研究。2002年L.Sweeney又在此基礎上提出了K-匿名保護模型[2],將理論高度進一步提升。同時,他又在文獻[3]中繼續提出針對這一技術的泛化和隱匿方法,此方法在實際應用中,確實對隱私信息起到很大保護作用。2004年Meyerson和Williams指出,即便對表中一些元素隱匿,要保證匿名結果為最佳的K-匿名問題也已經被證明是NP完全問題。
防止隱私泄露常用方法為添加噪聲、數據交換和數據隱匿[4],通過對要發布的數據表添加未知元素、把數據隱藏在更寬泛的取值空間內等方法,實現數據的隱私保護目的。從理論上來說,這些方法能起到一定作用,使隱私泄露信息減少,但通常也會發生發布數據失真等現象,使數據發布沒有意義。
現有的K-匿名算法大多通過泛化和隱匿技術來實現k-匿名化,易忽略信息泄露問題。文獻[5]對K-匿名后的數據進行分析研究,考慮背景知識的影響來分析信息泄露問題,而不同用戶對背景知識的掌握常常是參差不齊的,且由此要進行的數據泛化也會產生影響,結果可能會與期望結果大相徑庭。因此,為防止基于背景知識的攻擊,本文使用基于聚類的高效(K,L)-匿名算法,考慮準標識符屬性對敏感屬性的影響,先將敏感屬性聚類,然后利用K-匿名算法,分析每組數據的敏感屬性不同值的個數L與K值之間的關系,有效保護匿名后的秘密屬性,防止其隱私信息泄漏。
聚類是依據對象自身的相似性,將一個對象的集合分割成一系列有意義的子集的過程。聚類完成后特征為:每個簇內高度的同質性,每對簇間高度的異質性。典型聚類問題如K-means和K-Center[6]。
3 基本概念
定義1(標識符屬性) 在發布的數據中,能直接鏈接標識一條特定的記錄(個體),稱之為標識符屬性,如姓名、身份證號、銀行卡號。
定義2(準標識符QI) 數據表的屬性中,除標識符屬性外,能夠與外部屬性相連接的屬性集合,稱為準標識符[7]。
定義3(K-匿名)T(A1,A2,…,An)是一個表, QI是表T的準標識符,當且僅當在QI對應的每個等價類中,出現的屬性個數最少為K(K≥2)時,就說表T滿足K-匿名。
定義4(等價類) K-匿名化后,在準標識符屬性中對應的每組至少k個相同的元組的集合,稱為一個等價類。
定義5((K,L)-匿名) 給定一個表T,如果表T滿足K-匿名的要求,并且在準標識符QI上的值相同的一組等價類中,敏感屬性不同值至少有L個,則說表T滿足(K,L)-匿名,其中,K≥2,1<L≤K,L,K均取整數。
定義6(參考矩陣) 準標識符對敏感屬性影響概率的參考矩陣為J,是m×n型矩陣,其中,m是敏感屬性個數;n為準標識符個數;qi(1≤i≤n)是準標識符屬性;pi(1≤i≤m)是敏感屬性。

其中,Jij為第i個準標識符對第j個敏感屬性的影響概率。DISab為任一準標識符對第a個敏感屬性和對第b個敏感屬性的影響距離:
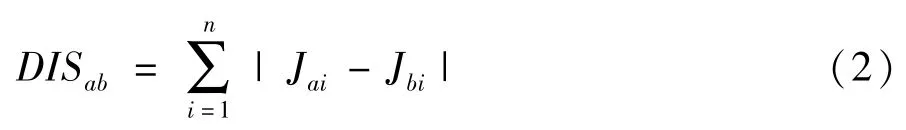
下面從實例說明(K,L)-匿名。表1是某原始數據表,顯示的是個人信息及疾病表。表2是滿足表1的2-匿名化表,表3為某人口信息表。表1中對數據先進行預處理,標識符屬性如姓名、身份證號等已刪除,屬性集合(年齡,國家,郵編,性別)是準標識符,疾病為敏感屬性。由表2可知該表滿足K匿名,且滿足L多樣性(K=2,L=2)。遇到表3鏈接攻擊時,能有效防止信息泄露。如表3中的第2條信息,名字為tiffany的個人信息與表2鏈接,不能得出它到底得了什么病,個人隱私得到了有效保護,實現了K-匿名。但是,它忽略了背景知識攻擊,比如名字為tom的個人信息與表2鏈接,雖然不能判斷出他得的是什么病,但是通過個人知識了解到,日本人患心臟病的概率及其低微,那么幾乎可以肯定地推斷出他得的是癌癥,而這種病是tom不想為人知的,他的個人隱私因此就被泄露了。而且,與表1相比,表2雖然很好地保護了隱私信息,但是有信息損失。本文的主要研究重點就是要在滿足(K,L)-匿名[8]的同時,使要發布的表信息損失降到最少。
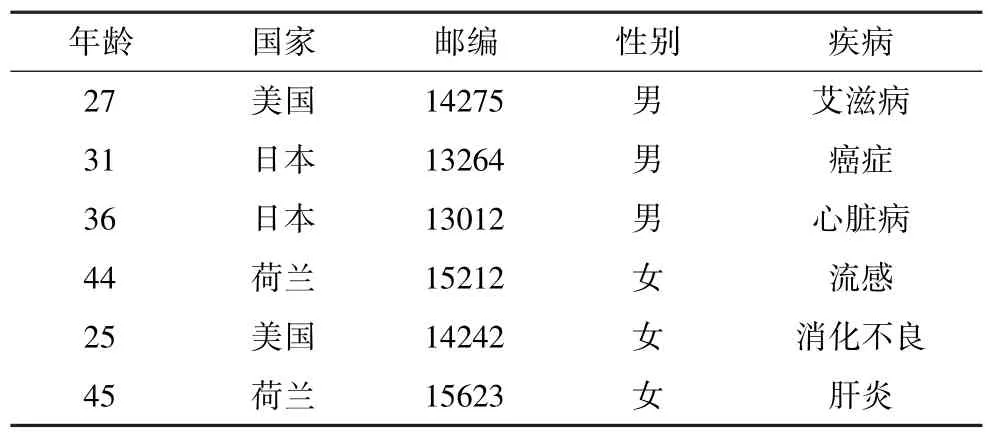
表1 原始數據表

表2 2-匿名數據表

表3 人口信息表
4 (K,L)-匿名聚類算法
K-匿名在遇到鏈接攻擊時,能夠有效防御,防止隱私信息泄露,但是在遇到同質攻擊和背景知識攻擊時,卻無能為力。為了更好保護敏感信息,增加對數據的L-diversity[9]處理,即(K,L)-匿名聚類算法。
對于輸入的數據集,為使發布的數據有意義且使信息損失盡量降低,可分為2個步驟進行:
(1)進行數據集背景知識參考矩陣的計算,各個準標識符對各個敏感屬性的影響的強弱均可明顯的反應出來。據此對敏感屬性進行聚類,本文采用改進的K-means算法,使類內數據更相似,類間數據更不同。聚類結果較傳統K-means算法,數據精度更高,能為以下數據匿名化作更好的鋪墊。
(2)將數據集中的每條記錄初始化為等價類,依據第一步的聚類結果將等價類進行聚類,然后,計算最小化信息損失,對等價類進行合并,K-匿名化要滿足生成的等價類大小在K與2K之間。同時判斷生成的等價類是否滿足L-diversity匿名化原則,使算法最終滿足(K,L)-匿名化。
4.1 敏感屬性聚類
對敏感屬性值進行聚類。令M為敏感屬性值的個數,L為L-diversity(多樣性)中的參數,則聚類個數為G=M/L。在此過程中要求簇內元素具有極大的同質性,每對簇間元素具有極大的異質性。依據此特點,可以提出改進的K-means算法來完成,因為相比傳統的K-means算法,改進的K-means算法更高效省時[10]。
傳統的K-means算法步驟為:對于給定的聚類簇數,首先對集群初始化,隨機選擇初始聚類中心,通過分配每個數據到最近的質心,生成新的分區集群。重復以上計算,直到質心不再變化。傳統 K-means算法雖然能快速處理數據,且快速簡單,但它存在著局限性:K值需要事先指定,對噪聲和孤立點敏感等,其中最突出的是對初始聚類中心的隨機選擇,易使聚類結果不穩定,造成結果陷入局部最優解,甚至得到相差甚遠的聚類結果。
K-means聚類算法的目的是使簇內最大程度的相似,每對簇間數據最大程度地不同。聚類結果的好壞與初始聚類中心的選擇關系重大。為使聚類效果更好,應選擇盡可能離得遠的對象作為初始聚類中心,以避免在應用K-means聚類算法時由于初始聚類中心選擇的過于鄰近,造成選取的初始聚類中心在同一個簇中,或小簇被包涵在大簇中等聚類結果不好的情況。
改進的K-means聚類算法具體步驟是:首先計算n個數據對象間的兩兩距離,找到距離最大的2個點,并分別以它們為質心,然后計算離此2個質心最近距離的數據對象,劃分到該簇中,直到達到閾值。再通過計算剩余數據對象與前2個質心間的最大距離,找第3個質心,以此類推,直到每個簇的質心不再變化。改進的K-means聚類算法不需要預先指定K值,不受隨機分配初始質心的影響,通過選取距離最遠的數據點為質心,不會產生傳統K-means聚類算法中初始質心在同一個簇的情況,將數據集劃分的更合理,能更好實現聚類效果,即簇內最大程度的相似,每對簇間數據最大程度地不同。
上述步驟對于下一步進行的匿名化會有較大影響,因此,本文提出改進的K-means算法對敏感屬性聚類,算法描述如下:
輸入背景知識參考矩陣,敏感屬性值M,L
輸出敏感屬性聚類結果
(1)先從數據集中選擇2組數據,形成2個簇。根據式(2)計算數據中每一對之間的距離,選擇出最遠的2組數據(如d1和d2),這2個數據將被視為初始集群中心。計算確定離d1最近的數據點并且將該數據點添加到d1集群,且從數據集中刪除該數據,直到該集群內數量達到閾值。d2同理,由此,形成2個簇;
(2)更新2個新形成簇的質心;
(3)第3個簇的選擇是,同樣由式(2)計算數據集中與前2個簇距離最遠的數據,以此數據為中心,生成第3個簇;
(4)直到形成G個簇;
(5)計算集群算術平均值獲得集群的質心;
(6)Until質心不再變化。
4.2 (K,L)-匿名聚類算法
為實現K-匿名,就需要對數據進行變換,由此就不可避免地會產生信息損失。對數值型屬性和分類型屬性,分別按不同的方式進行信息損失計算。設表T中的準標識符為QI(N1,N2,…,Nn,M1,M2,…,Mm),其中,Ni(1≤i≤n)為第i個數值型屬性,Mj(1≤j≤m)為第j個分類屬性。K-匿名化時,其中一個元組t=(xN1,xN2,…,xNn,xC1,xC2,…,xCm)被變換成t′=([yN1,zN1],[yN2,zN2],…,[yNn,zNn],DC1,DC2,…,DCm),則其信息損失定義如下[11],令R=(r1,r2,…,rk)為一個聚類。
定義7(元組信息損失) 元組信息損失定義為:
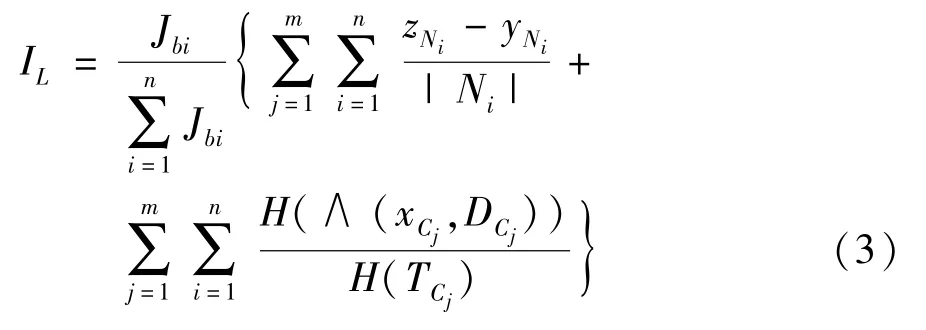
(K,L)-匿名算法描述如下:
輸入包含N條記錄的表T,參數K,L。
輸出(K,L)-匿名化的表T′。
(1)將數據集中每條記錄初始為等價類;
(2)從步驟(1)中G個簇中,每個簇選一條記錄,作為G個等價類的質心;
(3)Repeat;
(4)根據式(3)計算算法1聚類結果中同一簇所有記錄轉變到對應等價類中的信息損失;
(5)將信息損失最小的記錄分配到對應的等價類;
(6)每個等價類內記錄個數到K,則停止向該等價類內分配,直到只有最后一個等價類內記錄數不是K;
(7)更新G個等價類的質心;
(8)在以上生成的等價類中,查找敏感屬性個數小于L的等價類;
(9)計算第G個記錄中所有記錄轉換到該等價類的最小信息損失;
(10)直到前邊G-i個等價類滿足L多樣性;
(11)最后一個等價類中記錄數若不足K,按最小信息損失分配到對應等價類中;
(12)再次更新等價類的質心;
(13)Until質心不再變化。
5 實驗結果與分析
5.1 實驗環境
本文實驗的驗證采取UCI機器學習數據庫中的Adult數據集。該數據集應用廣泛,在隱私保護研究中有權威性,其內容包括了部分美國人口普查數據,數據量很大。采用文獻[12]中的數據預處理方法,將含有缺失值的不完整數據及有身份特征標識的姓名、身份證號碼等信息刪除,得到的實驗數據集包含45 222條數據記錄。將屬性{age,work class, education,martial status,race,gender,native country}作為準標識符屬性,其中,age和education為數值型屬性,occupation為敏感屬性,其余5個屬性為分類型屬性。
5.2 數據質量
將本文算法與傳統K-匿名算法在信息損失方面進行比較,結果如圖1所示,可以看出,在K值遞增的情況下,本文算法信息損失較小,而且隨著K值的增大,該優勢更明顯,數據質量更高。

圖1 信息損失度量
5.3 運行時間
將本文算法與傳統K-匿名算法在運行時間方面進行比較,結果如圖2所示,可以看出,在K值遞增的情況下,本文算法在運行時間上具有優勢。對任意K值,本文算法的運行時間都比傳統K-匿名算法短,且優勢明顯,體現了本文算法的高效性。
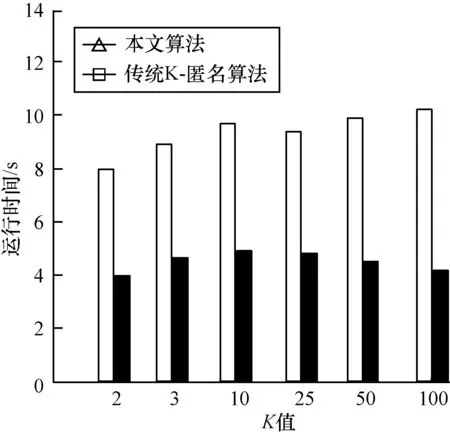
圖2 運行時間
6 結束語
本文利用改進K-Means算法將待發布數據聚合成K個簇,簇內最大程度相似,每對簇間數據最大程度不同,使準標識符對敏感屬性相似的數據聚合在一起。根據聚合結果對整個數據集進行聚類,且使每個等價類滿足L-多樣性,以此實現(K,L)-匿名。實驗從數據質量和運行時間2個方面進行比較,可以看出,當K值增大時,本文算法能獲得高質量的結果,實現數據發布中敏感屬性的保護。下一步將研究在面對海量數據時如何實現數據的高效保護。
[1] LeFevre K,DeWitt D J,Ramakrishnan R.Mondrian Multi Dimensional K-anonymity[EB/OL].[2014-02-10].http//www.cs.wisc.edu/-lefevre/Research.htm.
[2] Sweeney L.K-anonymity:A Modelfor Protecting Privacy[J].International Journal of Uncertainty, Fuzziness and Knowledge-based Systems,2002,10(5): 557-570.
[3] Sweeney L.Achieving k-anonymity Privacy Protection Using Generalization and Suppression[J].International Journal of Uncertainty,Fuzziness,and Knowledge-based Systems,2002,10(5):571-588.
[4] 吳溥峰,張玉清.數據庫安全綜述[J].計算機工程, 2006,32(12):85-88.
[5] Machanavajjhala A,Gehrke J,KiferD.l-diversity: Privacy Beyond K-anonymity[EB/OL].[2014-02-10]. http://www.cs.cornel.ledu/_mvnak.
[6] 邱保志,許 敏.無參數聚類邊界檢測算法的研究[J].計算機工程,2011,37(15):23-26.
[7] 萬 濤,劉國華.K-匿名數據中的數據依賴問題研究[J].計算機工程,2012,38(20):38-40.
[8] 羅紅薇,劉國華.保護隱私的(L,K)-匿名[J].計算機應用研究,2008,25(2):526-528.
[9] 韓建民,于 娟虞慧群,等.面向數值型敏感屬性的分級l-多樣性模型[J].計算機研究與發展,2011, 48(1):147-158.
[10] 徐義峰,陳春明 徐云青.一種改進的K-均值聚類算法[J].計算機應用與軟件,2008,25(3):275-277.
[11] 傅鶴崗,曾 凱.多維敏感k-匿名隱私保護模型[J].計算機工程,2012,38(3):145-147.
[12] Lefevre K,Dewittd J,Ramakrishnan R.Incognito: Efficient Full-domain k-anonymity[C]//Proceedings of 2005ACM SIGMOD InternationalConferenceon Management of Data.New York,USA:ACM Press, 2005:49-60.
編輯 金胡考
Efficient(K,L)-anonymous Privacy Protection Based on Clustering
CHAI Ruimin,FENG Huihui
(School of Electronic and Information Engineering,Liaoning Technical University,Huludao 125105,China)
In order to prevent sensitive information leakage in the release data,this paper puts forward a kind of anonymous protection algorithm based on clustering.It takes the overlooked influnces of identifier to sensitive attributes into account,clusters the sensitive attribute of data,and makes the modified k-means clustering algorithm apply to this step,to make the data more similar in class.It uses(K,L)-anonymous method for tables which being published, considering of sensitive attribute in the equivalence class,and puts forward the effective methods for privacy protection. Experimental results show that the proposed model has good effect of privacy protection,compared with the traditional K-anonymous methods,it can achieve privacy protection,at the same time,reduce the loss of data information,make the data have a higher accuracy,and the executive time is shorter.
(K,L)-anonymous;sensitive attribute;privacy protection;information loss;clustering;K-means algorithm
1000-3428(2015)01-0139-04
A
TP309
10.3969/j.issn.1000-3428.2015.01.026
柴瑞敏(1969-),女,副教授、碩士,主研方向:信息安全,數據庫技術,數據挖掘;馮慧慧,碩士研究生。
2014-03-10
2014-05-09 E-mail:656248970@qq.com
中文引用格式:柴瑞敏,馮慧慧.基于聚類的高效(K,L)-匿名隱私保護[J].計算機工程,2015,41(1):139-142.
英文引用格式:Chai Ruimin,Feng Huihui.Efficient(K,L)-anonymous Privacy Protection Based on Clustering[J]. Computer Engineering,2015,41(1):139-142.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
