客戶評論中用戶體驗信息自動提取研究
2015-06-27 08:26:03胡令傳陶曉鵬
計算機工程 2015年1期
胡令傳,陶曉鵬
(復旦大學計算機科學技術學院,上海201203)
客戶評論中用戶體驗信息自動提取研究
胡令傳,陶曉鵬
(復旦大學計算機科學技術學院,上海201203)
客戶評論在人們的日常生活中越來越重要,人們希望從客戶評論中獲取商品的用戶體驗信息。客戶評論數量的急劇增長使得用戶快速、精準地獲取有用的信息變得較為困難。為此,提出一種能夠自動提取用戶體驗信息的方法。該方法通過語義片段過濾評論中的冗余信息,提取產品特征詞及特征描述詞,將其結合組成用戶體驗信息,自動獲取信息能夠迅速、準確地從客戶評論中提取信息。實驗結果證明了該方法的有效性,并且能夠保證較高的準確率與查全率。
客戶評論;特征挖掘;情感分析;語義片段提取;用戶體驗;語義相似度
1 概述
隨著電子商務、微博的興起,人們的衣食住行與互聯網的關系越來越密切,互聯網中的信息也隨之飛速增長。電子商務中的客戶評論數量急劇增長使得用戶想要在評論中快速準確的獲取到其他用戶的體驗信息變得困難。客戶評論的特點有:數量大,在主流的電商網站上,一件商品的客戶評論已經成千上萬;內容單一,大部分的客戶評論字數較少,所包含的信息量少;語法簡單,比較口語化;表達方法簡單。
本文提出一種在評論中獲取用戶體驗信息的方法。該方法首先對評論進行分詞、詞性標注,然后進行產品特征與特征描述的提取,根據產品特征與特征描述來提取出用戶體驗信息。
2 問題分析及研究背景
2.1 問題分析
現在電商網站上出現了一些對評論進行分類、摘要的方法:(1)用戶對商品的總體體驗打分,電商網站根據分數進行分類,如一號店,這種方法的弊端是提供的信息量太少;(2)用戶添加體驗信息,其他用戶可以重復使用,如京東商城,這種方法得到的信息與具體評論內容脫節;(3)人工總結詞組,統計其數量,如百度微購,但人工總結效率低、不全面。在現有的研究方向中,與本文研究工作密切相關的主要有2個:產品特征挖掘和情感傾向分析。下面結合本文的方法對這2個方面分別進行介紹和分析。
2.2 產品特征挖掘
產品特征挖掘是指從大量的網絡客戶產品評論中獲取產品特征,這項技術是產品特征情感傾向分析的前提。文獻[1-2]使用了人工標記語料加上機器學習的方法提取汽車的產品特征,取得了不錯的效果。但人工進行參與的產品特征提取方法可移植性差。文獻[3]首先對句子進行句法分析,進行名詞短語的獲取,然后運用關聯規則進行提取到產品特征。這種方法雖然不需要人工進行干預,但準確率與效率都比較低。
人工參與和句法分析的特征提取方法都不太適用于電商網站上的客戶評論:對于前者,客戶評論數量龐大,種類繁多,采用人工進行標注特征,可行性太差;對于后者,互聯網上的評論表達自由,形式新穎,并不一定符合非常嚴謹的語法規則,導致句法分析結果不會太理想,進而準確率不會太高。本文則結合客戶評論自身的特點,采用了語義片段提取與詞頻統計結合的方法實現了自動產品特征挖掘。
2.3 情感傾向分析
情感傾向分析的目的是判斷用戶對產品的態度,包括正面、負面和中性[4]。目前情感傾向分析的技術主要分為2種:機器學習方法和語義方法。文獻[5]提出了半監督的機器學習方法進行情感傾向挖掘。這種方法雖然能夠達到非常高的準確度,但人工標記語料效率低。基于語義理解的情感分析方法[6-7]是利用詞語相似度計算詞語與褒義詞和貶義詞的距離,從而得到的詞語的情感值。在文獻[8]中,用基于語義理解的情感傾向分析方法對文本的情感傾向進行分析,取得了非常好的效果。
目前的情感傾向分析方法只是考慮了一些比較有情感色彩的詞,比如“不錯”、“好看”這樣的詞。而客戶評論特別是一些電商網站的評論中會出現很多新詞,比如“接地氣”、“正能量”這種詞,則不能很好地判斷其褒貶。更有像“荷蘭進口”這種詞,不能僅僅用褒貶來表達。因此,定義了表達范圍更廣泛的概念,稱為特征描述詞。用特征描述詞的提取來代替情感傾向分析,使得評論閱讀者能夠獲取到更加豐富的信息。
3 用戶體驗信息提取
本文提出的自動獲取用戶體驗信息方法主要有3個步驟:(1)通過產品特征挖掘獲取到產品的特征信息,即產品特征詞;(2)獲取描述產品特征的詞語,即特征描述詞;(3)合并特征詞和特征描述詞,形成用戶體驗信息。
3.1 產品特征挖掘
產品特征挖掘基于語法規則及上下文相似度計算,分3個步驟:復合名詞合并,語義片段提取,語境相似度計算。
(1)復合名詞合并。這里的復合名詞包括普通意義的復合名詞、“的”字結構等。用復合名詞作為產品特征詞能夠保證所提取信息的完整性和精確性。合并規則如下:
名詞+名詞(直至后面不是名詞)
名詞+“的”+名詞
(2)語義片段提取。客戶評論中存在字數很多,但沒有或者很少用戶體驗信息的句子,通過名詞短語和介詞短語形式的語義片段的提取有用信息提取出來。基于如下的語法規則來定義語義片段:
名詞+副詞+名詞修飾語 (東西/NN很/AD不錯/JJ)
名詞+副詞+動詞(寶寶/NN很/AD喜歡/VV)
名詞+副詞+表語形容詞 (味道/NN很/AD濃/VA)
動詞+副詞+表語形容詞 (買的/VV很/AD便宜/VA)
介詞+名詞+表語形容詞 (比/P超市/NN便宜/VA)
語義片段提取用正則表達式來實現。實驗表明,利用這些語法規則能夠提取出基本完整的語義片段集合,達到了91.9%。
(3)語境相似度計算[9]。在客戶評論中,產品特征詞的語境有許多相似之處:句中位置相似,上下文的詞相似、上下文的詞性相似。根據這些特點,本文設計了特征詞擴展算法,其中,用W1表示已知的產品特征詞;W2表示候選特征詞。W1和W2各自取前后2個詞語及其詞性分別作為它們的上下文,用PW表示上下文中的詞,PT表示對應的詞性。整個上下文如下所示:

算法中的權重值由人為設定,分值大小確定的原則為:上下文中距離特征詞越近的詞和詞性的權重越高;在距離相同的情況下,上下文中的詞比詞性的權重高。所有的候選特征詞依據得分從高至低排序,如果其得分大于預先設定的閾值,則確定為新的產品特征詞。這里的閾值是根據實驗過程中得到的結果,取其最小值所得。
特征擴展算法如下:
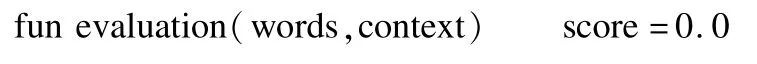

3.2 特征描述詞的提取
PMI算法[10]利用詞之間同時出現的概率判斷情感傾向,PMI算法可以用下式表示:
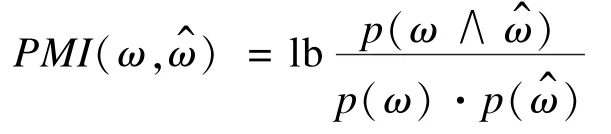
本文發現客戶評論中都有多個特征描述詞同時出現。因此借用PMI算法,利用已知的特征描述詞發現新的特征描述詞,即式(1)中ω表示已知的特征描述詞,ω^表示待確定的特征描述詞。根據PMI算法給所有的ω^打分排序之后,然后去掉其中的副詞(AD)、動詞(VV),最后根據預先設定的閾值進行篩選。這里的閾值是根據實驗結果,取每次正確結果的最小值所得。
3.3 種子詞的獲取
前面介紹的產品特征詞和特征描述詞的獲取,都需要一些初始的已知詞,分別稱為產品特征種子詞和特征描述種子詞。采用如下步驟獲取種子詞:
(1)對語義片段提取的結果進行詞頻統計。
(2)設置一個停用詞表[11],包含經常出現,但是沒有參考價值的詞語。
(3)選取出現頻率最高,且不包含停用詞的N個名詞作為產品特征種子詞,頻率最高且不包含停用詞的N個形容詞作為特征描述種子詞。N的值太小會影響拓展詞的準確度,N的值太大會影響種子詞的準確度。
3.4 特征詞和特征描述詞的合并
用戶體驗信息是特征詞與特征描述詞的結合。本文利用上下文相關性,將特征詞與特征描述詞聯系起來。依次處理每個特征詞,然后合并它們的結果。單個特征詞的處理方法如下:
(1)獲取特征詞的上下文,這里的上下文取的是特征詞的前面2個詞與后面2個詞。
(2)記錄上下文中含有的特征描述詞,并統計在所有評論中出現的次數。
(3)在含有特征描述詞的上下文中,查看是否含有否定詞,若含有否定詞,需在特征描述詞前加入否定詞,并重新統計其數量。
4 實驗結果與分析
圖1給出了本文的實驗流程,包括每個步驟的簡要實現方法。

圖1 本文方法實驗流程
4.1 實驗數據及預處理
在京東商城選取10個不同種類的商品進行對比實驗,如表1所示。在信息提取之前,對評論進行預處理:
(1)重復其他用戶的評論,即有些用戶直接復制的其他用戶的評論。
(2)存在大量重復文字的評論,如:“好好好好好!!!”。
(3)存在大量特殊字符的評論,如:“A?(?]%好”。
(4)存在大量空白的評論,如:“東西很好 很給力”。
(5)重復自身的評論,如:“東西很好 東西很好東西很好 東西很好東西很好”。
對于(1)、(5)中的評論,采取去重的方法;對于(2)、(3)中的評論,直接將評論丟棄;對于4中的評論,除去空白。

表1 京東商城選取的10個商品
4.2 修正的召回率和F-Measure值
本文的任務是從海量評論數據中提出取對客戶有用的信息,通常用準確率(precision)和召回率(recall)來評估提取的質量。并用F-Measure[12]值綜合準確率和召回率2個數值,其中常用的是F1,它的定義如下:
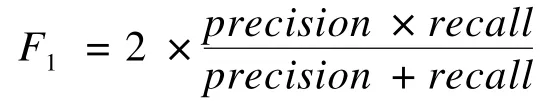
由于本文的實驗數據規模太大,無法對所有評論進行人工標注,導致無法統計所有正確信息的數量,進而無法計算召回率。因此,設計了新的召回率計算公式,稱為修正的召回率,即用2個進行比較的結果的正確部分的合并作為正確信息的全集,具體公式如表2所示。

表2 修正的查全率計算
本文把用新的召回率計算得到的F-measure值稱為修正的 F-measure值,記為Fw,傳統的 FMeasure值記為Ft。證明略,當滿足條件C1≥C2時,下式成立:
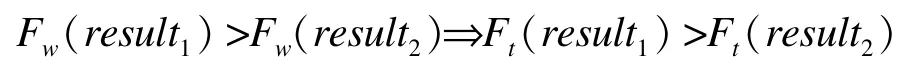
在下面實驗的比較中,把本文方法提出的結果視為提取結果1,已有方法(比如京東商城的方法)提取的結果視為提取結果2。上面的結論說明,只要本文方法提取出足夠多的正確信息,就能夠保證修正的F-measure值的比較結果與傳統的比較結果一致。
4.3 結果分析
本文對語義片段提取、種子詞獲取以及用戶體驗信息進行了實驗結果的統計與分析。
4.3.1 語義片段提取實驗
從Iphone4的評論中隨機選取100條,經過人工挑選,從中找出62個語義片段,作為實驗的“黃金標準”(Gold Stan-dard)。本文方法的提取結果如表3所示。

表3 本文方法的提取結果
表3結果表明,本文方法雖然不能保證較高的精確率,但能夠保證非常高的召回率。這樣的結果就能保證本文的語義片段提取損失盡可能少的信息量,也保證了本文最后提取出來的用戶體驗信息的全面性、完整性。
4.3.2 種子詞獲取實驗
實驗數據來自10種商品的全部評論,N的值設為5,實驗結果如表4所示。其中,每個商品的評論中產生10個種子詞,包括5個特征種子詞和5個特征描述種子詞,它們的正確性由人工評定。實驗結果表明,本文方法準確率達到98%,基本可以替代人工提供的數據。
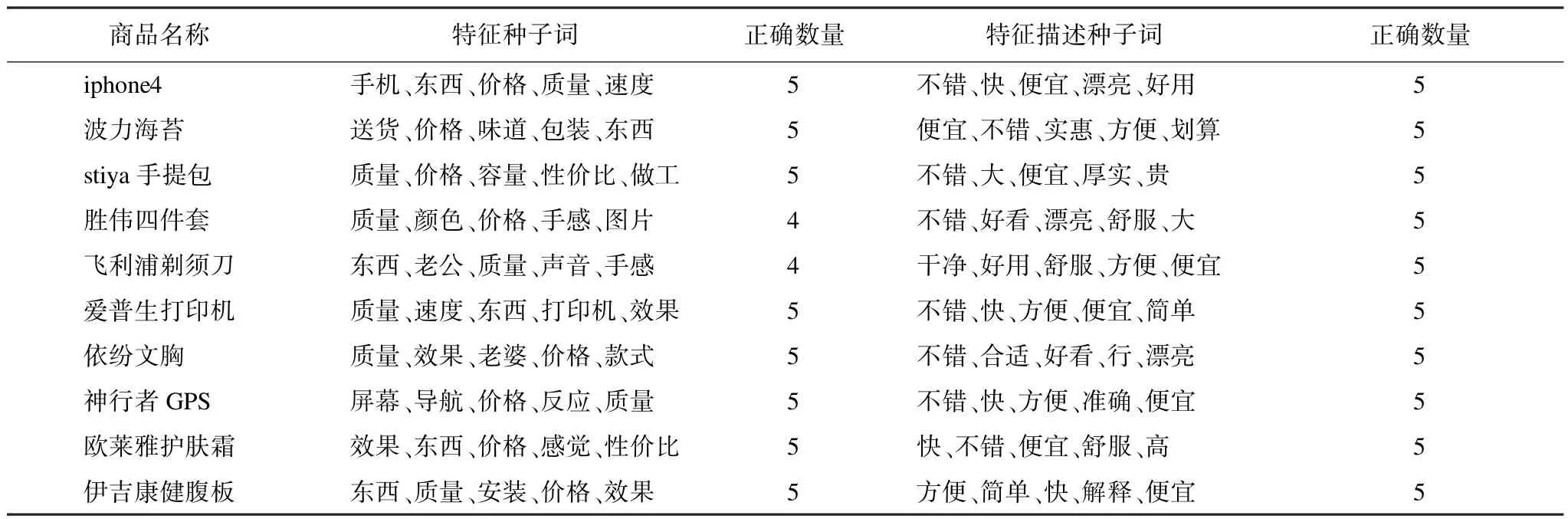
表4 種子詞提取實驗結果
4.3.3 用戶體驗信息提取實驗
本文對10種商品的評論進行用戶體驗信息提取,結果與京東商城進行比較。京東商城的結果通過爬蟲程序從評論接口獲取,每個商品都獲得一條體驗信息。本文方法和京東商城的結果都由人工判斷是否正確。實驗結果如表5、表6所示。實驗結果表明,在準確率上,本文方法與京東商城相差不大,但是在召回率上,本文方法遠遠優于京東商城。在最終F-Measure值評估上,本文方法無論是宏平均還是微平均都遠遠優于京東商城。
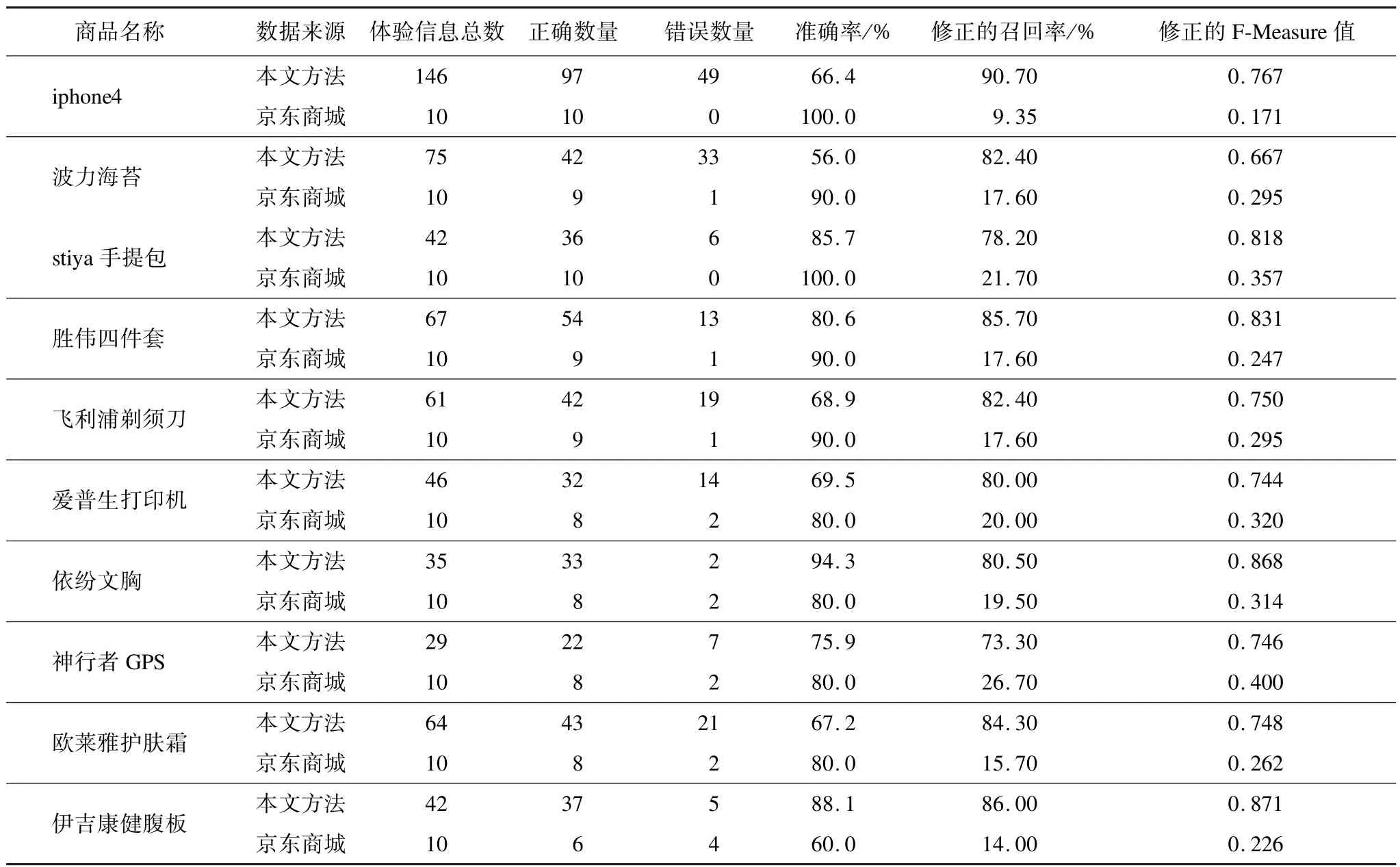
表5 用戶體驗信息提取結果對比
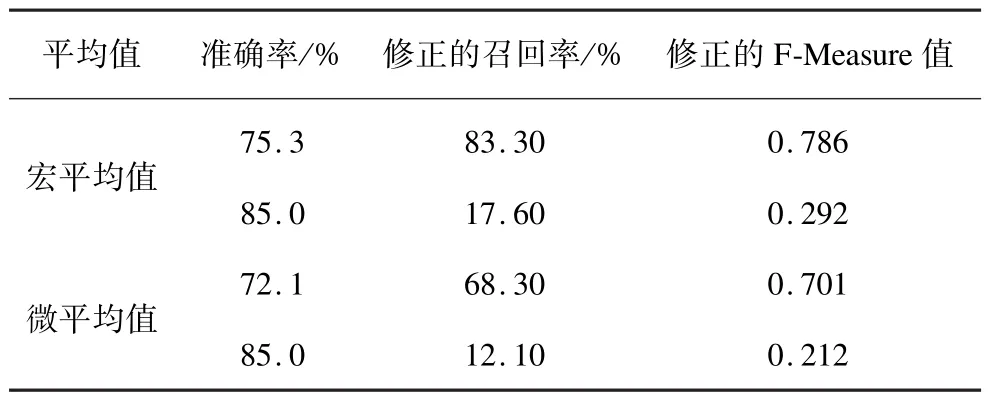
表6 宏平均值與微平均值結果對比
5 結束語
客戶評論隨著電子商務的發展起著越來越重要的角色,進而處理評論的技術要求也越來越高。現有方法依賴于人力,不能真正客觀地從評論中提取信息。本文方法能夠自動獲取產品特征與特征描述詞,并組成用戶體驗信息。實驗證明該方法能夠自動、全面、客觀地從客戶評論中獲取信息。
[1] Kobayashi N,Inui K,Matsumoto J,et al.Collecting Evaluative Expressions for Opinion Extraction[C]// Proceedings of IJCNLP’05.Berlin,Germany:Springer, 2005:596-605.
[2] Li Zhuang,Feng Jing,Zhu Xiaoyan.Movie review Mining and Summarization[C]//Proceedings of the 15th ACM International Conference on Information and Knowledge Management.[S.1.]:ACM Press,2006:43-50.
[3] Hu Mingqing,Liu Bing.Mining Opinion Features in Customerreviews[C]//Proceedings ofthe 19th National Conference on Artifical Intelligence.San Jose, USA:AAAI Press,2004:755-760.
[4] Pang Bo,Lee L.Opinion Mining and Sentiment Analysis[J].Foundations and Trends in Information Retrieval,2008,2(1/2):1-135.
[5] Pang Bo,Lee L,Vaithyanathan S.Thumbs Up? Sentiment Classification Using Machine Learning Techniques[C]//Proceedings of ACL’02.[S.1.]: Association for Computational Linguistics,2002:79-86.
[6] 徐琳宏,林鴻飛,楊志豪.基于語義理解的文本傾向性識別機制[J].中文信息學報,2007,21(1):96-100.
[7] 朱嫣嵐,閔 錦,周雅倩,等.基于hownet的詞匯語義傾向計算[J].中文信息學報,2006,(1):14-20.
[8] Nasukawa T,Yi J.Sentiment Analysis:Capturing Favorability Using Natural language processing[C]//Proceedings of the 2nd International Conference on Knowledge Capture.Sanibel Island,USA:ACM Press,2003:70-77.
[9] 劉宏哲,須 德.基于本體的語義相似度和相關度計算研究綜述[J].計算機科學,2012,39(2):8-13.
[10] Turney P D,Littman M L.Measuring Praise and Criticism:Inference of Semantic Orientation from Association[J].ACM Transactions on Information Systems,2003,21(4):315-346.
[11] 朱 杰,劉功申,陳 卓.中文文本傾向性分類技術比較研究[J].信息安全與通信保密,2010,(4):56-58.
[12] Makhoul J,Kubala F,Schwartz R,et al.Performance Measures for Information Extraction[C]//Proceedings of DARPA’99.[S.1.]:IEEE Press,1999:249-252.
編輯 索書志
Research on Information Automatic Extraction of User Experience from Customer Reviews
HU Lingchuan,TAO Xiaopeng
(School of Computer Science,Fudan University,Shanghai 201203,China)
Customer reviews are playing an increasingly important role in people’s daily lives,from which people want to obtain some information about user experience.However,with the continuous development of the Internet,it is pretty difficult for users to get the useful information in a rapid and accurate way.The common practice is to collect experience information manually or half-manually,and calculate the frequency of tem.This paper presents an automatic method to extract information about the user experience from customer reviews,it extracts product features and feature description through semantic segment filtering redundant information,and consists of user experience information,it implements information extraction rapidly and precisely.Abundant experiments show that this method is available and can guarantee very high precision and recall ratio.
customer reviews;feature mining;emotion analysis;semantic segment extraction;user experience;semantic similarity
1000-3428(2015)01-0049-05
A
TP391
10.3969/j.issn.1000-3428.2015.01.009
胡令傳(1990-),男,碩士,主研方向:自然語言處理,機器翻譯;陶曉鵬,副教授、博士。
2013-12-26
2014-02-27 E-mail:hulingchuan@hotmail.com
中文引用格式:胡令傳,陶曉鵬.客戶評論中用戶體驗信息自動提取研究[J].計算機工程,2015,41(1):49-53.
英文引用格式:Hu Lingchuan,Tao Xiaopeng.Research on Information Automatic Extraction of User Experience from Customer Reviews[J].Computer Engineering,2015,41(1):49-53.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
