基于多核計算機集群系統的網格分區策略
2015-06-26 15:48:32王振亞葉友達
空氣動力學學報 2015年1期
王振亞,葉友達
基于多核計算機集群系統的網格分區策略
王振亞,葉友達
(國家計算流體力學實驗室,北京100191)
網格分區技術是提高并行計算效率的重要手段。基于圖的分區技術(如Metis等)已經可以完全做到負載平衡,但是隨著計算機集群系統的發展,節點間的通訊成為并行計算中的重要時間消耗部分。為此,提出一種適用于非結構網格的新分區策略(MC Partition method),減少了節點間的通訊規模,結果表明,這種分區方法可以較大的提高并行計算效率。
非結構網格;多核;集群;并行;通信
0 引言
計算流體力學(CFD)在航空航天以及很多工業過程中都得到了非常廣泛的應用。由于求解問題的復雜程度越來越高,需要的計算網格數量急劇增加,如果說10年以前的網格數量主要在百萬量級的話,現在使用上千萬量級的網格求解已經很常見的,對于一些復雜外形,網格規模甚至達到上億量級,并行計算已成為必需的手段。對基于非結構網格的解算器而言,由于非結構網格不具有結構網格數據隱含的順序性,用什么原則進行網格分區,怎樣才能夠提高非結構網格解算器的并行計算效率,一直是其中的一個重要問題。
在網格規模增加的同時,計算機技術也在飛速進步,雖然單核運算速度比十年前快了一個量級,但是計算機技術中最令人矚目的屬于大規模并行計算機的飛速發展。從2012年11月13日的第40屆TOP500排名[1]中可以發現,排名第一的Titan系統的Linpack性能達到17.59Pflops,排在第十位的Fermi系統也達到1.72Pflops;而進入TOP100的系統性能也從一年前(38屆)的115.9Tflops提升到243.9Tflops。工業標準化的集群系統(Cluster)已經牢牢占據了本屆TOP 500HPC排行榜的壟斷地位,從2001年6月只有32套,發展到2012年411套系統,82.2%的比重,十年間增長了近13倍。越來越強的計算能力對算法提出了更高的要求。由于采用GPU等加速技術,單個節點的計算速度可以得到大幅提高,但是現在大家發現當前大規模并行計算機遇到的瓶頸主要是數據交換的速度,包括網絡速度,甚至I/O速度等[2]。新的集群系統每個節點都是由多核CPU組成,計算中的數據交換與通信就存在計算機節點內部的總線速度——節點之間的網絡速度——I/O速度之間的平衡,從而需要計算軟件用更多的注意力來解決這些新的問題。
本文將主要通過分區方法的改進來提高并行計算效率。第一部分將通過分析提出問題,并提出解決問題的方法;第二部分將在通過數值計算來驗證新方法;第三部分將是本文的小結。
1 算法介紹
一直以來,負載平衡和減少通信量都是并行計算中必須考慮的兩個問題。并行計算的計算時間一般可以如下表示:
并行計算時間=繼承的串行計算時間+
并行的額外時間開銷(1)
負載平衡就是要求分配到每個計算單元的計算規模基本一致,它和并行繼承的串行計算時間有關,計算中不希望出現由于負載不平衡造成快的計算單元等待慢的計算單元的情況;通信量的減少就可以相應減少計算中不同計算單元間數據通信產生的時間。
對于非結構網格而言,隨著很多基于圖(graph)的分區軟件(如Metis[3]等)的應用,負載平衡在基于非結構網格的計算流體力學軟件中已經可以很方便做到[4]。對于同樣的網格(約16 000 000單元)和同樣的網格分區(用pmetis分成112個區域),完全負載平衡,我們在兩個不同的集群系統中做了測試(表1)。從結果可以發現,兩個計算機系統的速度相差7倍,如果再仔細分析,可以發現其中由于每個計算單元的運算速度提高使得相應的計算速度提高了4倍,然而由于數據傳輸速度的提升使得計算時通信速度提高了24倍。

表1 不同集群系統比較Table 1Comparation of different clusters
為了進一步研究數據通信在計算中的影響,我們在把一個網格(約39 000 000單元)分成不同數量的任務并行計算,計算結果見表2。可以發現,隨著參與計算的計算單元數量超過128,并行計算效率逐漸下降。由于在網格分區時已做到負載平衡,并行計算效率降低主要原因是因為隨著參與計算的計算單元數量增加,分配到每個計算單元的網格數量隨之減少,相應造成了通信數據在總的計算數據中所占的比例增加,通信造成的時間開銷在總計算時間中的比重不再是不可忽略的小量。

表2 并行計算效率比較Table 2Comparation of the parallel computing efficiency
從而可以發現,在達到負載平衡以后,通信速度已經成為當前的并行計算流體力學軟件一個主要瓶頸,這個問題和連接計算集群每個節點的網絡的物理特性有關,包括網絡拓撲結構、網絡帶寬等,同時和通信數據的構成也有很大關系。當前計算機集群的每個節點的CPU一般都是由多核組成,節點內的多核之間的數據通信是基于總線,不同節點之間的數據通信是基于網絡,而對于當前的計算機技術而言,計算機內部總線的速度比網絡速度要快得多。顯然可以發現,如果在分區時僅僅考慮負載平衡的話,則分區形成的每個子區基本上相互獨立,那么會在并行計算中造成普遍以網絡速度來衡量數據通信速度的情況,表3采用和表1同樣的網格,用Metis分成48個分區,可以做到完全負載平衡,考察其在一個由6節點共48核(6×8)的集群上運行的結果,在每個節點中取一個核為代表,研究其通信數據的分布情況。
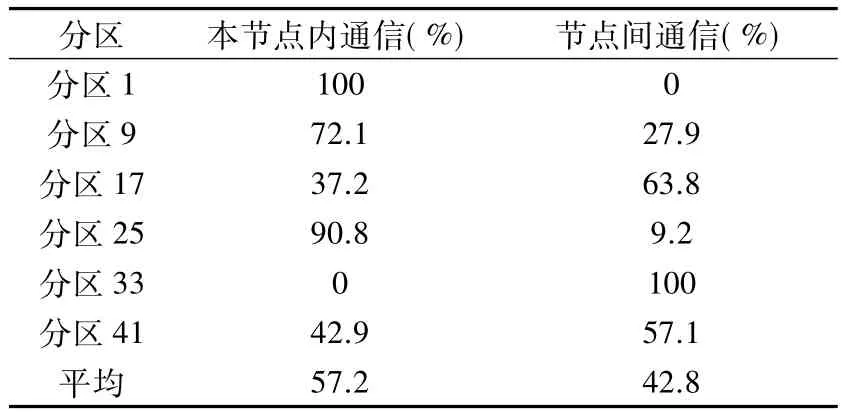
表3 只考慮負載平衡的分區通信數據分析(Metis)Table 3Analysis of communication data considering of load balancing
從表3中可以發現,根據這種分區原則得到的網格分區,節點之間的通信量在每個計算單元的全部通信量中所占比例非常大,有的計算單元甚至都在和本節點外的計算單元通信,而節點之間的通信是按照網絡速度來計算的,這樣的數據分布必然會大大降低通信速度。通過這樣的分析,為了進一步提高數據通信速度,我們需要——調整計算單元內的通信數據分布,增加節點內通信數據的比例。
如果計算機集群系統由N個節點組成,每個節點內有M個核(記為N×M),根據這個原則,我們提出多核集群分區策略(MultiCore Partition,簡稱MC),可以如下描述:
MC Partition策略(如圖1)
1)按照負載平衡的原則把網格分為N個區,對應N個節點;
2)For i=1 to N
按照負載平衡的原則把每一個子區分為M個區,生成的子區分別對應于第i個節點的M個核;
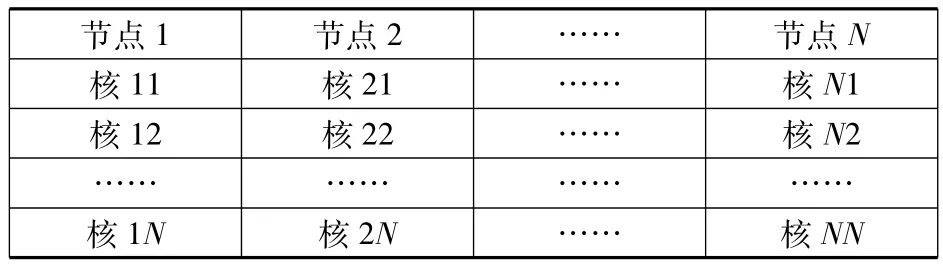
圖1基于多核的分區方法(MC Partition)Fig.1Partition method by MC
采用表3對應的網格,我們在考慮計算機集群系統(6×8)上每個節點的多核性質后,按照MC方法進行分區,分區結果見表4。由于節點之間以及核之間的分區算法考察了負載平衡,所以也達到了完全負載平衡。從表4可以發現,基于這種分區策略的分區結果,使得每個計算單元的節點內通信數據所占比例大大增加,平均值提高了35%。這種分區策略實際上造成的結果是使得計算數據不僅僅在計算機內存中存放在一起,同時它們在幾何上也是相鄰的。根據基本常識判斷,這樣應該會帶來通信時間的減少,從而提高計算速度和并行效率。
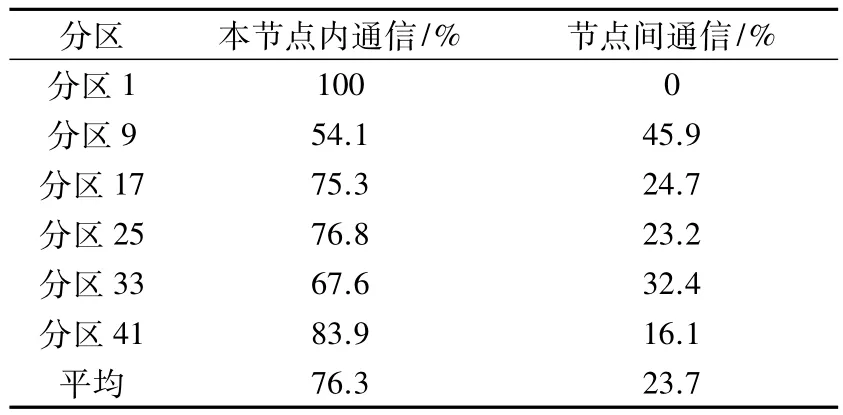
表4 多核分區方法(MC Partition)的通信數據分析Table 4Analysis of communication data by MC partition
2 數值結果
表5為表3和表4對應的兩種不同分區方法在同一個6×8集群系統的測試計算結果,從中可以看到采用MC Partition方法的分區使得通信速度提高了32%,總的計算速度提高了10%。
并行加速比一般如下表示[5]:

表5 不同分區方法比較(6×8)Table 5Comparation of different partition methods(6×8)

為了更好地測試計算方法,我們用一個更大規模的網格(約33 600 000單元的非結構網格)來計算,分成112個分區,測試在同一個7×16集群系統進行。測試結果在表6給出。可以看出,雖然此計算機系統的網絡性能已經比較好,但是在采用MC Partition方法之后,通信速度仍然提高了32%,計算速度提高了近10%。

表6 不同分區方法比較(7×16)Table 6Comparation of different partition methods(7×16)
串行計算的CPU時間是不變的,并行計算時間按照(1)式計算,由于并行計算中負載平衡的實現,每個計算單元所繼承的串行計算量也是基本固定的,如果共有K個參與計算的單元,則每個計算單元所繼承的串行計算量可以近似為1/K;如果通信效率提高30%,那么就可以提高并行加速比,尤其在數據通信時間在計算中所占比例很大的時候,將會得到更明顯的表現。
從表5和表6可以發現,由于兩種分區算法都能夠很好的保證負載平衡,所以并行計算中的串行計算部分的時間開銷都基本保持不變。為了提高并行計算中的串行計算部分的速度,當前的并行計算機集群系統已經大量采用了如GPU等加速計算技術,但是數據傳輸部分的通信時間開銷也是并行計算中需要重點注意的部分。對比表6和表2,可以發現對于總的網格量而言,112個分區基本上還在并行計算的線性加速區內,由于計算條件限制,沒有采用更多的計算單元,我們可以預計在分區增加、計算單元增加的情況下,這種分區方法仍然是可以有效提高通信速度的。
3 結論
本文提出了一種適合現代多核計算機集群系統的分區方法(MC Partition),分區時不僅可以達到每個計算單元之間的負載平衡,而且由于考慮了計算機集群系統每個節點內多核的特點,讓計算機內更高速的數據傳輸部件傳輸盡可能多的數據,大大減少了并行計算中依靠節點間的網絡傳輸的數據量,較大的提高了數據傳輸速度,提高了計算速度和并行效率。
當然,對于CFD而言,并行計算的數據傳輸不可能做到速度為零,但是我們通過考慮計算機系統的特點,確實可以提高并行計算的效率。
致謝:感謝國家計算流體力學實驗室的周越同志大力提供計算資源。
[1]http://www.top500.org/
[2]Hu Q F,Numerical simnulation and high-performance computer[C]//Beijing:seminar on key technology in high performance numerical simulation of military engineering,2010.(in Chinese)胡慶豐.數值模擬和高性能計算機[C]//北京:軍工高性能數值模擬中重大基礎關鍵技術研討會會議論文集.2010年1月.
[3]Karypis G,Kumar V.Multilevel k-way partitioning scheme for irregular graphs[J].Journal of Parallel and Distributed Computing,1998,48:96-129.
[4]Wang Z Y,Lu S,Ye Y D,Grid partition of unstructured grid[C]//14thComputational Fluid Dynamics Conference,2004(in Chinese)王振亞,盧笙,葉友達.非結構網格分區技術研究[C]//第十二屆全國計算流體力學會議論文集,2004.
[5]Michael J Quinn.Parallel programming in C with MPI and OpenMP[M].Beijing:Tsinghua University Press.
A new grid partition strategy for muliti-core cluster system
Wang Zhenya,Ye Youda
(National Laboratory of Computational Fluid Dynamics,Beijing100191,China)
Grid partition method is important to the efficiency of parallel computing.By now,partition method on graph,as Metis,can do load balancing very well.While as the cluster systems improve,communication between node of cluster becomes important.A new partition strategy for unstructured grid according to the new multi-core computer cluster system is proposed.As it is realized and proven to reduce the communication between the nodes,it can improve the parallel computing efficiency about 10%.
unstructured grids;multi-core cluster;parallel;communication
V211.3
Adoi:10.7638/kqdlxxb-2013.0013
0258-1825(2015)01-0087-04
2013-01-24;
2013-05-06
王振亞(1974-),男,湖南醴陵人,博士,助理研究員,主要從事非結構網格生成以及基于非結構網格的數值計算軟件研制工作.E-mail:niels_wang@163.com
王振亞,葉友達.基于多核計算機集群系統的網格分區策略[J].空氣動力學學報,2015,33(1):87-90.
10.7638/kqdlxxb-2013.0013.Wang Z Y,Ye Y D.A new grid partition strategy for muliti-core cluster system[J].Acta Aerodynamica Sinica,2015,33(1):87-90.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年14期)2020-09-11 07:57:42
科技傳播(2019年22期)2020-01-14 03:06:34
消費導刊(2017年20期)2018-01-03 06:26:40
家庭影院技術(2017年9期)2017-09-26 03:41:45
時代英語·高二(2015年1期)2015-03-16 00:08:11
衡陽師范學院學報(2015年3期)2015-02-10 06:02:23
