結(jié)合分解技術(shù)的多目標(biāo)引力搜索算法
2015-06-15 17:21:12畢曉君刁鵬飛王艷嬌
哈爾濱工業(yè)大學(xué)學(xué)報(bào) 2015年11期
關(guān)鍵詞:優(yōu)化
畢曉君,刁鵬飛,王艷嬌,肖 婧
(1.哈爾濱工程大學(xué)信息與通信工程學(xué)院,150001哈爾濱;2.東北電力大學(xué)信息工程學(xué)院,132012吉林吉林;3.遼寧省交通高等專科學(xué)校信息工程系,110122沈陽)
結(jié)合分解技術(shù)的多目標(biāo)引力搜索算法
畢曉君1,刁鵬飛1,王艷嬌2,肖 婧3
(1.哈爾濱工程大學(xué)信息與通信工程學(xué)院,150001哈爾濱;2.東北電力大學(xué)信息工程學(xué)院,132012吉林吉林;3.遼寧省交通高等專科學(xué)校信息工程系,110122沈陽)
針對(duì)基于分解的多目標(biāo)遺傳算法在解決多目標(biāo)問題時(shí)無法有效解決前沿面非均勻、不連續(xù)的問題,提出一種基于分解技術(shù)的多子群串行搜索的多目標(biāo)引力搜索算法(MOGSA/D).為充分利用算法優(yōu)化分解出的目標(biāo)函數(shù)所得到的進(jìn)化信息、提高收斂速度,采取多種群串行的搜索方式;針對(duì)理想前沿面為非超平面的情況,提出一種預(yù)測理想前沿面形狀的方法,并針對(duì)預(yù)測結(jié)果選擇適合的權(quán)重系數(shù)生成方式;為提高解集的整體質(zhì)量,提出一種基于目標(biāo)權(quán)值的策略刪減種群.通過標(biāo)準(zhǔn)測試函數(shù)的實(shí)驗(yàn)驗(yàn)證,所提算法與其他多目標(biāo)進(jìn)化算法相比在解集的收斂性以及分布性上均有較大提高,驗(yàn)證了算法的有效性.
引力搜索算法;多目標(biāo)優(yōu)化;分解;多種群策略
多目標(biāo)優(yōu)化問題MOP(multi-objective optimization problem)需要同時(shí)優(yōu)化2個(gè)或2個(gè)以上的目標(biāo)函數(shù),且各個(gè)優(yōu)化目標(biāo)之間通常是相互沖突的,因此不存在能使所有目標(biāo)都達(dá)到最優(yōu)的解.
多目標(biāo)進(jìn)化算法MOEA(multi-objective evolutionary algorithm)是目前廣泛采用的一種解決MOP的方法,主要可以分為3類:1)基于Pareto占優(yōu)關(guān)系的MOEA算法,如ε-占優(yōu)機(jī)制[1]、E-占優(yōu)機(jī)制[2];2)基于評(píng)估指標(biāo)的MOEA算法,如HypE[3]等算法;3)基于分解技術(shù)的MOEA算法,如MOEA/D算法[4].其中基于分解的MOEA算法因其計(jì)算簡單、復(fù)雜度小和收斂性好受到廣泛關(guān)注,但當(dāng)理想前沿面為不連續(xù)、非均勻等形狀時(shí),所得到的優(yōu)化結(jié)果的收斂精度及穩(wěn)定性還有待進(jìn)一步提高.
引力搜索算法GSA(gravitational search algorithm)是2010年提出的群智能優(yōu)化算法,具有設(shè)置參數(shù)少、全局搜索能力強(qiáng)、計(jì)算簡單、收斂速度快等優(yōu)點(diǎn)[5].本文將GSA與分解技術(shù)相結(jié)合,提出一種基于分解技術(shù)的多目標(biāo)引力優(yōu)化算法.主要?jiǎng)?chuàng)新點(diǎn):1)采用分解技術(shù),將多目標(biāo)問題分解成單目標(biāo)問題,然后采用多子群串行搜索的策略對(duì)各子問題展開優(yōu)化,提高進(jìn)化搜索的效率;2)提出一種理想前沿面的預(yù)測策略,并根據(jù)預(yù)測結(jié)果選取適合的權(quán)重系數(shù)計(jì)算方式,一定程度上保證了解集分布的均勻性;3)針對(duì)解在各目標(biāo)所得結(jié)果的線性加權(quán)和,提出一種種群刪減策略,提高了解集相對(duì)于理想前沿面的逼近性及分布的均勻性.
1 引力搜索算法及基于分解的多目標(biāo)算法
1.1 引力搜索算法
可以把種群中的個(gè)體想象成是一組在空間中運(yùn)動(dòng)的粒子,它們?cè)谌f有引力的作用下,相互運(yùn)動(dòng),其質(zhì)量的大小是評(píng)價(jià)解優(yōu)劣的標(biāo)準(zhǔn),質(zhì)量較大粒子的位置對(duì)應(yīng)較優(yōu)解.粒子通過相互作用、相互運(yùn)動(dòng)實(shí)現(xiàn)進(jìn)化信息的共享,從而向最優(yōu)區(qū)域展開搜索.
設(shè)空間中含有N個(gè)粒子,則第i個(gè)粒子的位置表示為


式中:Maj(t)和Mpi(t)分別為粒子j和粒子i的質(zhì)量;ε是一個(gè)極小的常量;G(t)表示在t時(shí)刻的萬有引力常數(shù),具體定義為

式中:T為設(shè)置的最大迭代次數(shù),G0為初始時(shí)刻的引力常數(shù),Rij(t)為粒子i與粒子j之間的歐氏距離.則在t時(shí)刻,粒子i在k維上受到的其他粒子的合力為

式中:rankj為變化區(qū)間在[0,1]之間的隨機(jī)數(shù);為粒子j對(duì)粒子i在第k維空間上的作用力.依據(jù)牛頓第二定律,定義t時(shí)刻粒子i在k維上的加速度為

在進(jìn)化過程中,粒子的速度和位置的更新方式為

粒子的質(zhì)量與適應(yīng)度值有關(guān),質(zhì)量越大的粒子越接近最優(yōu),并且它對(duì)其他粒子的作用力相應(yīng)會(huì)更大,但移動(dòng)速度較慢.粒子質(zhì)量的計(jì)算方式為

式中:fi(t)為粒子i的適應(yīng)度值;w(t)為質(zhì)量最小粒子的適應(yīng)度值;b(t)為質(zhì)量最大粒子的適應(yīng)度值.
圖1給出了GSA算法的操作流程圖.

圖1 GSA算法流程圖
1.2 基于分解的多目標(biāo)算法
基于分解的多目標(biāo)優(yōu)化算法結(jié)合了多目標(biāo)局部搜索和多個(gè)單目標(biāo)Pareto抽樣的優(yōu)點(diǎn),而切比雪夫法又是其中解決效果最好的方法.在切比雪夫分解模型下,對(duì)于一個(gè)給定的權(quán)重向量,對(duì)應(yīng)的單目標(biāo)子問題可描述為

式中:權(quán)重向量λ=(λ1,…,λm)滿足λk≥0且為參考點(diǎn),是由解集在各個(gè)目標(biāo)函數(shù)上取得的最優(yōu)值構(gòu)成的虛擬點(diǎn),對(duì)于最小化問題有z?i=min{fi(x)|x∈Ω},1,2,…,m.在滿足條件的情況下,對(duì)于任意一個(gè)給定的權(quán)重向量,存在一個(gè)使式(1)達(dá)到最小的最優(yōu)解,該最優(yōu)解就是原多目標(biāo)優(yōu)化問題的一個(gè)Pareto最優(yōu)解.所以,可以通過設(shè)定N個(gè)不同的權(quán)重向量獲得N個(gè)最優(yōu)解來構(gòu)成Pareto最優(yōu)解集.
2 基于分解的多目標(biāo)引力搜索算法
提出一種基于分解技術(shù)的多目標(biāo)引力搜索算法(MOGSA/D).首先選取幾組具有偏好性的權(quán)重系數(shù)展開優(yōu)化搜索,并以此判別理想前沿面的形狀.然后基于預(yù)測結(jié)果選取適合的權(quán)重系數(shù)計(jì)算方式.種群在對(duì)分解后的優(yōu)化問題展開搜索時(shí),相鄰子問題的解具有相似性,因此為充分利用這種近似性,提高求解能力尤其是非均勻不連續(xù)問題的優(yōu)化效率,采用多子群串行搜索的策略.最后為提高解集的收斂精度并兼顧粒子分布的均勻性,提出一種基于目標(biāo)權(quán)值的策略對(duì)種群進(jìn)行刪減.
2.1 權(quán)重的自適應(yīng)選取
MOEA/D通過構(gòu)造多組權(quán)重系數(shù)將一個(gè)MOP分解為一組單目標(biāo)優(yōu)化問題,并通過子問題之間的合作來同時(shí)優(yōu)化這組子問題,從而獲得對(duì)理想最優(yōu)解集的一個(gè)逼近.但該方法存在2個(gè)問題:
1)傳統(tǒng)MOEA/D算法采用的權(quán)重系數(shù)生成方法是基于理想面是超平面的情況.針對(duì)理想面非均勻的情況,單一的權(quán)重系數(shù)生成方式會(huì)影響解集分布的均勻性,如圖2所示.

圖2 分布非均勻前沿面
2)當(dāng)前沿面不連續(xù)時(shí),若算法對(duì)處在斷開區(qū)域的子目標(biāo)問題進(jìn)行優(yōu)化求解,則由于進(jìn)化壓力容易得到相同的解,勢(shì)必會(huì)浪費(fèi)計(jì)算資源,降低算法的整體優(yōu)化性能,如圖3所示.

圖3 分布不連續(xù)前沿面
為解決上述問題,文獻(xiàn)[6]提出權(quán)重向量根據(jù)其自身的最優(yōu)解進(jìn)行自適應(yīng)調(diào)整,文獻(xiàn)[7]提出一種加強(qiáng)的權(quán)重向量調(diào)整方法.但這些方法所適用的前提條件是理想前沿面是超平面的情況,當(dāng)前沿面為非超平面或不連續(xù)時(shí),上述方法均不能保證所得解集分布的均勻性,且會(huì)浪費(fèi)計(jì)算資源.因此,權(quán)重系數(shù)的生成必須針對(duì)不同的前沿面形狀自適應(yīng)產(chǎn)生.
基于以上分析,首先對(duì)理想前沿面的形狀進(jìn)行預(yù)測.通過選擇具有明顯偏好性的權(quán)值系數(shù)可以得到理想前沿面的邊界點(diǎn),若理想前沿面為超平面,則對(duì)2個(gè)目標(biāo)問題有判別方式為

理論證明:當(dāng)理想前沿面是超平面時(shí),則對(duì)2個(gè)目標(biāo)問題是一條直線,在極端情況下,當(dāng)權(quán)重向量的取值為(1,0)時(shí),所得的最優(yōu)解在2個(gè)目標(biāo)函數(shù)上的解是這條前沿面上的一個(gè)端點(diǎn);同理,當(dāng)權(quán)重向量取值為(0,1)時(shí)為前沿面的另一個(gè)端點(diǎn);對(duì)一個(gè)等腰直角三角形,角分線也是中位線,即取權(quán)重向量為(0.5,0.5)時(shí),所得的解應(yīng)位于前沿面的中點(diǎn)位置上.
對(duì)3個(gè)目標(biāo)問題,可判斷點(diǎn)和面的位置關(guān)系,即通過求解4組權(quán)重系數(shù)構(gòu)成的子問題的最優(yōu)值,判斷理想前沿面的形狀.設(shè)4組偏好權(quán)重系數(shù)構(gòu)成的

根據(jù)得到的平面方程,通過比較點(diǎn)和面的位置關(guān)系得到前沿面的預(yù)測結(jié)果,具體描述如下:
若

若

若

當(dāng)預(yù)測到前沿面形狀后,針對(duì)不同的預(yù)測結(jié)果,為有效解決非均勻不連續(xù)前沿面問題,必須保證權(quán)重系數(shù)構(gòu)成的向量與前沿面的焦點(diǎn)均勻分布在前沿面上.提出一種權(quán)重系數(shù)的生成方式為

1)當(dāng)前沿面為超平面時(shí),則p取值為1,即λ構(gòu)成的面也為超平面;
2)當(dāng)前沿面為凸平面時(shí),則p取值為2,即λ構(gòu)成的面也為凸平面;
3)當(dāng)前沿面為凹平面時(shí),則p取值為0.5,即λ構(gòu)成的面也為凹平面.
2.2 多子群串行搜索
對(duì)于非連續(xù)理想前沿面,由于進(jìn)化壓力的驅(qū)使,必然會(huì)導(dǎo)致幾組相似權(quán)重系數(shù)所構(gòu)建出的子問題具有相同的解.為解決前沿面不連續(xù)所帶來的資源浪費(fèi)問題,結(jié)合GSA的收斂速度快、求解精度高、進(jìn)化步長可控等特性,采取多子群串行搜索的策略對(duì)構(gòu)造出的子問題進(jìn)行優(yōu)化.相鄰權(quán)重系數(shù)所對(duì)應(yīng)的解也具有相似性,根據(jù)這種相似性,可以為下一個(gè)種群粒子的初始化設(shè)定一個(gè)較小的范圍,相比于在整個(gè)空間隨機(jī)初始化種群縮小了搜索區(qū)域,提高了種群搜索最優(yōu)解的速度.因此,當(dāng)一個(gè)子種群完成對(duì)其優(yōu)化問題的求解時(shí),參考此前最優(yōu)解初始化種群,粒子生成方式為
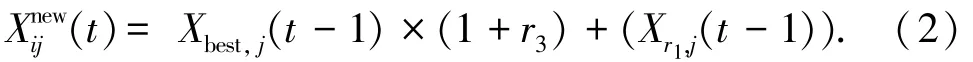
2.3 刪減策略
為了利于決策者的選擇,提高解集中解的代表性,需要對(duì)優(yōu)化得到的最優(yōu)解集進(jìn)行篩選,以提高其分布的均勻性及收斂程度.以最小化問題為例,能夠使各目標(biāo)值都取較小的點(diǎn),將更容易支配其他的解也即更靠近理想前沿面,但對(duì)互不支配的2個(gè)解則較難判斷其優(yōu)劣.對(duì)此,通過比較2個(gè)相似非支配解在各目標(biāo)上整體的逼近程度加以刪減.對(duì)非支配解尤其是較為相似的2個(gè)解,可通過計(jì)算其歸一化后的各目標(biāo)值的加權(quán)和進(jìn)行篩減,具體描述如下:
將解集中各粒子按照歐式距離進(jìn)行排序,對(duì)于相對(duì)距離小于閾值u的2個(gè)粒子,先分別將各目標(biāo)值歸一化,然后計(jì)算其各目標(biāo)上的加權(quán)和,即

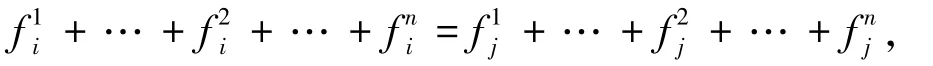
則說明此時(shí)2個(gè)解相同,任意刪除一個(gè).若

則第j個(gè)解優(yōu)于第i個(gè)解,刪除第i個(gè)解.
基于目標(biāo)加權(quán)和的判定方式,可以較好地對(duì)相似非支配解進(jìn)行刪減,使最終得到的解集更佳逼近前沿面.對(duì)于擁擠區(qū)域的刪減,在一定程度上保證了分布的均勻性,同時(shí),降低了決策者的選擇壓力.
2.4 算法實(shí)現(xiàn)流程
步驟1算法初始化,設(shè)定問題維數(shù)D,種群規(guī)模N1和N2以及2個(gè)種群各自的最大迭代次數(shù),問題的函數(shù)評(píng)價(jià)次數(shù),以及κ、u、G0、a、H.
步驟2對(duì)多目標(biāo)問題的個(gè)數(shù),選擇相應(yīng)的幾組偏好權(quán)值系數(shù)(若目標(biāo)個(gè)數(shù)為2,則選擇3組帶有偏好性的權(quán)值系數(shù),若目標(biāo)個(gè)數(shù)為3,則選擇4組帶有偏好性的權(quán)值系數(shù))構(gòu)成目標(biāo)函數(shù).
步驟3計(jì)算每個(gè)個(gè)體的適應(yīng)度值,并求出其相應(yīng)的慣性質(zhì)量.
步驟4根據(jù)個(gè)體的慣性質(zhì)量,求得每個(gè)個(gè)體所受的合力,進(jìn)而求得其加速度.
步驟5判斷是否滿足終止條件,若不滿足轉(zhuǎn)到步驟3.
步驟6當(dāng)完成對(duì)各組偏好權(quán)重系數(shù)構(gòu)成的單目標(biāo)函數(shù)的求解后,采用式2.1節(jié)描述的方法判斷前沿面的形狀.若前沿面形狀是凹的,則p=0.5;若前沿面形狀為凸的,則p=2;否則p=1,具體的權(quán)重系數(shù)生成方式如2.1節(jié)所示.
步驟7根據(jù)得到的一系列權(quán)重系數(shù),按步驟3、步驟4進(jìn)行優(yōu)化搜索.
步驟8當(dāng)滿足終止條件時(shí),重新初始化新的子種群,初始化方式采用式(2)所示方式進(jìn)行.
步驟9當(dāng)達(dá)到最終的函數(shù)評(píng)價(jià)次數(shù)后,采用刪減策略對(duì)解集進(jìn)行刪減,即將解集中各粒子按照歐式距離進(jìn)行排序,對(duì)于相對(duì)距離小于閾值u的2個(gè)粒子,先分別將各目標(biāo)值歸一化,然后計(jì)算并比較粒子各目標(biāo)上的加權(quán)和,保留較優(yōu)粒子.
步驟10輸出最終的解集.
3 仿真實(shí)驗(yàn)與結(jié)果分析
所有實(shí)驗(yàn)在硬件配置為Intel?CoreTM2 Duo CPU P7570 2.26 GHz、2 G內(nèi)存、2.27 GHZ主頻的計(jì)算機(jī)上進(jìn)行,開發(fā)環(huán)境為Matlab2 010.b.
3.1 測試問題
實(shí)驗(yàn)選用二目標(biāo)ZDT和三目標(biāo)DTLZ兩個(gè)系列的多目標(biāo)測試函數(shù)[8],具體包括ZDT1、ZDT2、ZDT3、ZDT4、ZDT6、DTLZ1和DTLZ2等7個(gè)函數(shù).這些測試函數(shù)具有理想前沿面形狀為凹形、凸形、不連續(xù)以及多模等特點(diǎn),可驗(yàn)證所提算法的有效性.
采用世代距離指標(biāo)(generational distance metric,GD)和空間度量指標(biāo)(spacing metric,SP)[9-10]兩種評(píng)價(jià)標(biāo)準(zhǔn)測試所提算法的性能.GD和SP的定義為

式中:N表示通過算法求得的解集中解的個(gè)數(shù);di為求得的解集中第i個(gè)解到理想最優(yōu)解集的最小歐幾里得距離;ˉd為算法求得所有解di的平均值.
GD的值越小,表明算法求得的解集與問題的理想最優(yōu)解集越接近,算法收斂性越好.SP的值越小,表明算法求得的解集中的解分布的越均勻,算法的均勻性越好.
3.2 參數(shù)設(shè)置
實(shí)驗(yàn)結(jié)果與目前解決多目標(biāo)問題效果較好的NSGAII[11],MOEA/D-AWA[7],Adaptive-MOEA/D[12]和HMOEA[9]進(jìn)行了比較,相關(guān)參數(shù)如表1所示.
選取的二目標(biāo)偏好權(quán)重向量個(gè)數(shù)為3,即分別偏好2個(gè)目標(biāo)的向量,以及任意選取的向量分別為(0.99,0.01)、(0.01,0.99)、(0.5,0.5);選取的三目標(biāo)偏好權(quán)重系數(shù)個(gè)數(shù)為4,即分別偏好3個(gè)目標(biāo)的權(quán)重向量以及任意選取的一組向量,分別為(0.90,0.05,0.05)、(0.05,0.90,0.05)、(0.05,0.05,0.90)、(0.33,0.33,0.34).
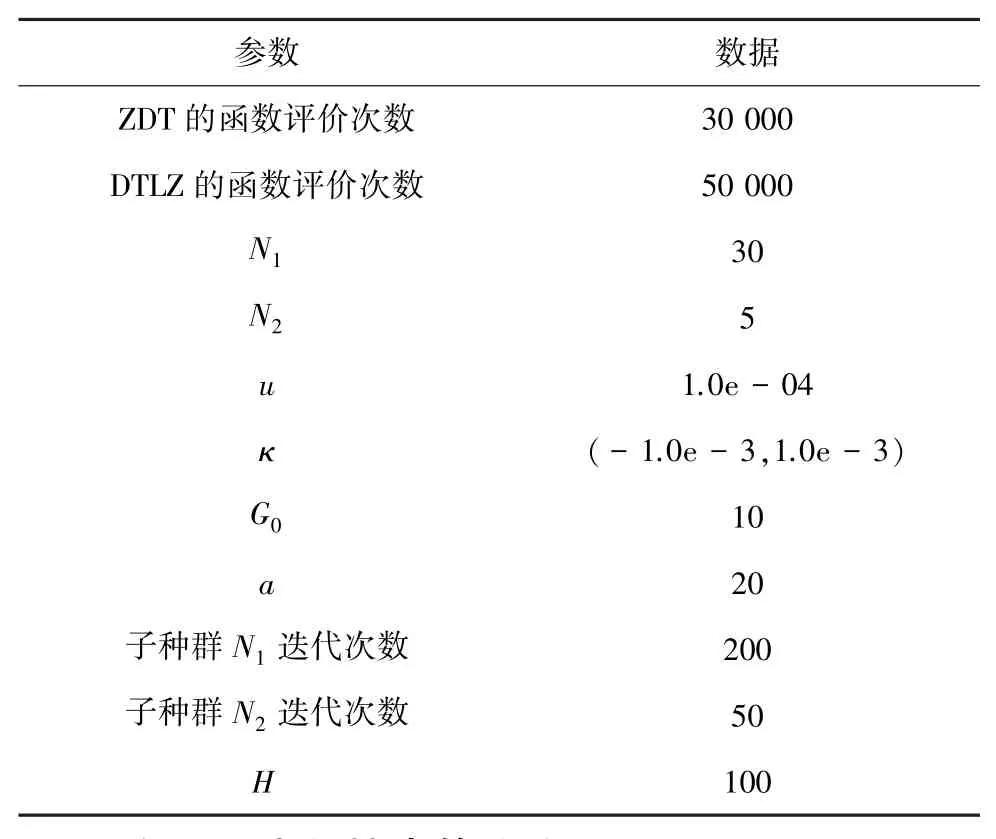
表1 參數(shù)設(shè)置
3.3 多子群串行搜索策略驗(yàn)證
為驗(yàn)證多子群串行搜索策略在解決多目標(biāo)問題時(shí)的有效性,通過觀察算法對(duì)測試問題搜索的漸變過程進(jìn)行實(shí)驗(yàn),驗(yàn)證多子群策略的有效性.函數(shù)ZDT3具有前沿面不連續(xù)的特點(diǎn),因此選取該函數(shù)作為實(shí)驗(yàn)函數(shù).實(shí)驗(yàn)結(jié)果如圖4所示.

圖4 隨迭代得到解集的漸進(jìn)變化趨勢(shì)
從圖4可以看出,隨著函數(shù)評(píng)價(jià)次數(shù)的不斷增加,所得到的解集逐漸遍布了整個(gè)理想前沿面,取得了較好的逼近效果,說明多子群串行搜索的有效性.圖中出現(xiàn)離散點(diǎn),這是因?yàn)閷?duì)子問題的搜索會(huì)產(chǎn)生一些非支配解,這些解對(duì)于當(dāng)前子問題不是最優(yōu)解但對(duì)于其他子問題來說則是最優(yōu)解,體現(xiàn)了多種群串行搜索策略在優(yōu)化多目標(biāo)問題時(shí),不會(huì)漏掉得到的較優(yōu)解,具有較好的全局搜索性能.
3.4 刪減策略有效性驗(yàn)證
為驗(yàn)證刪減策略在解決多目標(biāo)問題中的有效性,選取測試函數(shù)ZDT1進(jìn)行驗(yàn)證,實(shí)驗(yàn)結(jié)果如圖5所示,指標(biāo)SP和GD的對(duì)比如表2所示.

圖5 刪減前后算法所得前沿面對(duì)比

表2 解集在刪減前后的GD值和SP值
從圖5可以看出,在算法未對(duì)解集進(jìn)行刪減時(shí),所得到的前沿面存在較多被支配解,當(dāng)對(duì)其進(jìn)行刪減后,得到的解集則是由一群非支配解構(gòu)成.由表2可以看出,采取刪減策略對(duì)解集進(jìn)行刪減后,指標(biāo)GD和SP均得到較大的提升,即得到的解集無論是收斂性還是均勻性均得到了提高,驗(yàn)證了刪減策略的有效性.
3.5 求解性能對(duì)比
主要考察MOGSA/D算法與對(duì)比算法在標(biāo)準(zhǔn)測試函數(shù)上的性能比較,測試結(jié)果如表3及表4所示.其中表3給出各算法在優(yōu)化各問題時(shí)所得GD指標(biāo)的均值及方差,表4給出各算法在優(yōu)化各測試問題時(shí)所得SP指標(biāo)的均值及方差.
從表3中可以看出,對(duì)于ZDT1、ZDT2、ZDT3和ZDT4等4個(gè)測試函數(shù),MOGSA/D算法在指標(biāo)GD以及指標(biāo)SP上都取得了優(yōu)于其他對(duì)比算法的性能,也即收斂性以及分布性都是最好的;對(duì)函數(shù)ZDT6以及函數(shù)DTLZ2,MOGSA/D算法的GD是最小的,也即收斂性是最好的,分布性指標(biāo)也僅次于MOEA/D-AWA;對(duì)函數(shù)DTLZ1,MOGSA/D算法在收斂性指標(biāo)上沒有得到較好的效果,但分布性仍優(yōu)于其他對(duì)比算法.綜合來看,在求解ZDT和DTLZ問題上,本文所提算法無論在收斂性、魯棒性還是分布性上均優(yōu)于其他同類算法.

表3 各算法的GD值(第一行)及其標(biāo)準(zhǔn)差(第二行)

表4 各算法的SP值(第一行)及其標(biāo)準(zhǔn)差(第二行)
4 結(jié) 語
基于分解的多目標(biāo)引力搜索算法MOGSA/D,通過對(duì)理想前沿面的估計(jì),自適應(yīng)選取與之匹配的權(quán)重系數(shù)生成方式;采用多子群串行搜索各子目標(biāo)問題方法,為充分利用子問題的相似性,提出一種擾動(dòng)生成新種群的策略;根據(jù)所得解集中粒子間的擁擠度,提出一種基于各目標(biāo)加權(quán)和的方式刪減較劣解,以保證解集更均勻地逼近理想前沿面.通過對(duì)測試函數(shù)集ZDT和DTLZ上的實(shí)驗(yàn)證明,MOGSA/D算法與現(xiàn)有的MOEAs相比,具有更好地收斂性及和分布的均勻性.
[1]HERNáNDEZ-DíAZA,SANTANA-QUINTERO L,COELLO COELLO C,et al.Pareto-adaptive∈-dominance[J]. Evolutionary Computation,2007,15(4):493-517.
[2]郭思涵,龔小勝.正交設(shè)計(jì)的E占優(yōu)策略求解高維多目標(biāo)優(yōu)化問題研究[J].計(jì)算機(jī)科學(xué),2012,39(2):276-279,310.
[3]BADER J,ZITZLERE.HypE:an algorithm for fasthypervolumebased many-objective optimization[J].Evolutionary Computation,2011,19(1):45-76.
[4]LIHui,ZHANGQingfu.Multiobjective optimization problems with complicated pareto sets,MOEA/D and NSGA-II[J]. IEEE Transactions on Evolutionary Computation,2009,13(2):284-302.
[5]RASHEDI E,SARYAZDI S.GSA:a gravitational search algorithm[J].Information Sciences,2009,179(13):2232-2248.
[6]WANG R,PURSHOUSE R C,F(xiàn)LEMING P J.Preferenceinspired co-evolutionary algorithm using weights for manyobjective optimization[C]//Proceeding of the fifteenth Annual Conference Companion on Genetic and Evolutionary Computation Conference Companion.New York:ACM,2013:101-102.
[7]QIYutao,MA Xiaoliang,LIUFang,et al.MOEA/D with adaptive weightadjustment[J].Evolutionary Computation,2014,22(2):231-264
[8]TAN Yanyan,JIAO Yongchang,LIHong,etal.MOEA/D+ uniform design:a new version of MOEA/D for optimization problems with many objectives[J].Computers&Operations Research,2013,40(6):1648-1660.
[9]TANG L,WANG X.A hybrid multiobjective evolutionary algorithm for multiobjective optimization problems[J]. IEEE Trans on Evolutionary Computation,2013,17(1):20-45.
[10]SIMON D.Biogeography-based optimization[J].IEEE Transactions on Evolutionary Computation,I2008,12(6):702-713.
[11]DEB K,PRATAP A,AGARWAL S,et al.A Fast and elitistmultiobjective genetic algorithm:NSGA-II[J].IEEE Transactions on Evolutionary Computation,2002,6(2),182-197.
[12]SUCIU M,PALLEZ D,CREMENE M,et al.Adaptive MOEA/D for QoS-based web service composition[M]. Berlin:Springer,2013.
(編輯王小唯)
M ulti-objective gravitational search algorithm based on decom position
BIXiaojun1,DIAO Pengfei1,WANG Yanjiao2,XIAO Jing3
(1.College of Information and Communication Engineering,Harbin Engineering University,150001 Harbin,China;2.College of Information Engineering,Northeast Dianli University,132001 Jilin,Jilin,China;
3.Dept.of Information Engineering,Liaoning Provincial College of Communications,110122 Shenyang,China)
When the ideal frontier is discontinuous or inhomogeneous,the multi-objective evolutionary algorithm can’t solvemulti-objective problems effectively by decomposition.In order to improve this situation,a novelmultiobjective gravitational search algorithm based on decomposition(MOGSA/D)is proposed.In MOGSA/D,the multi-population serial strategy is good for the population study evolutionary information.According to shape prediction of ideal frontier,a suitable generation method of weight coefficient is selected.A pruning strategy is adopted to prune the solution set.Experimental results show that MOGSA has a good performance to solve multiobjective problems in comparison with othermulti-objective optimization algorithms.
gravitational search algorithm(GSA);multi-objective optimization;decomposition;multi-population strategy
TP18
:A
:0367-6234(2015)11-0069-07
10.11918/j.issn.0367-6234.2015.11.012
2014-11-30.
國家自然科學(xué)基金(61175126);中央高校基本科研業(yè)務(wù)費(fèi)專項(xiàng)資金(HEUCFZ1209);高等學(xué)校博士學(xué)科點(diǎn)專項(xiàng)科研基金(20112304110009).
畢曉君(1964—),女,教授,博士生導(dǎo)師.
畢曉君,398317196@qq.com.
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59
消費(fèi)導(dǎo)刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
