基于案例推理的財務報告舞弊識別研究
2015-06-09 19:37:13李清任朝陽
財經理論與實踐 2015年3期
李清++任朝陽

摘要:上市公司財務報告舞弊對資本市場建設和投資者利益保護掣肘已久。以2003~2012年我國滬深A股財務報告舞弊公司及其配對公司為樣本,依據“舞弊鉆石”理論和現有文獻提取舞弊識別指標,基于案例推理思想構建財務報告舞弊識別模型。研究發現,較之于非舞弊公司,舞弊公司通常面臨更大的盈利壓力和償債壓力,成長能力更弱,事務所變更現象更為普遍,被出具非標準審計意見的概率更高。基于仿蘭氏距離的案例推理模型對測試集樣本的識別總正確率為66.7%。
關鍵詞: 財務報告舞弊;案例推理;熵值法;K近鄰法
中圖分類號:F239.1文獻標識碼:A文章編號:1003-7217(2015)03-0084-06
一、引言
財務報告是上市公司與資本市場溝通的橋梁。因此,確保財務報告信息的真實、準確意義重大。財務報告舞弊是指公司在對外財務報告活動中,由于故意或輕率的行為,無論是虛假或漏列,結果導致重大誤導性財務報告,且對投資者的投資決策產生實質性影響的行為。由于信息不對稱及有限理性,投資者對上市公司的舞弊操作往往難以分辨,常蒙受巨額財產損失。因此,識別舞弊性財務報告,辨別上市公司信息真偽,有助于保護投資者利益,為建設投融資并重的規范的資本市場提供支持。
舞弊與反舞弊的博弈歷時已久,有關財務報告舞弊識別的研究也未曾間斷。Ngai等(2011)[1]對美國1997~2008年在金融欺詐領域的49種期刊上已發表文獻進行統計發現,普遍應用的方法包括Logistic回歸、人工神經網絡、貝葉斯網絡、決策樹等。Beasley(1996)[2]通過構建Logistic回歸模型,探討了董事會結構特征與財務報告舞弊之間的關系,研究發現舞弊公司的外部董事比例顯著低于非舞弊公司,而審計委員會設置與否與財務報告舞弊之間不存在顯著相關關系。Lee等(1999)[3]以美國證券交易委員會“會計與審計處罰公告”和“華爾街日報索引”所載1978~1991年間舞弊公司為樣本,建立Logistic回歸模型,著重討論了指標“盈余與經營現金流量差”的舞弊識別能力,結果發現財務報告舞弊公司的盈余與經營現金流量差異顯著高于非舞弊公司。此外,人工神經網絡[4,5]和基于多標準決策技術[6]在公司財務報告舞弊識別方面的應用也不乏研究成果。特別地,Curet等(1996)[7]討論了案例推理在輔助審計師識別管理舞弊中的應用,探索了案例推理模型的開發、完善和評估技術。Hwang等(2004)[8]以137家韓國制造業公司為樣本,以涵蓋6個控制因素的56個風險指標為基礎,采用層次分析法為指標賦權,以歐氏距離法度量案例相似程度,檢驗了案例推理模型在企業內部控制風險評估方面的應用效果。結果表明,案例推理的風險評估模型效果顯著優于人工審計,也好于多元判別分析。
國內關于財務報告舞弊識別的研究則主要采用統計方法和人工神經網絡方法。陳國欣等(2007)[9]選取29個指標,以126家舞弊公司和126家非舞弊公司為樣本建立了Logistic回歸模型,結果顯示盈利能力弱、管理者持股比例高、獨立董事人數少、被出具非標準審計意見的上市公司舞弊可能性更高。韋琳等(2011)[10]、洪葒等(2012)[11]分別以舞弊三角形理論和GONE理論為指導,構建了Logistic回歸模型。梁杰等(2006)[12] 使用5個財務比率和3個會計項目指標建立了基于模糊邏輯和神經網絡的財務報告舞弊識別的混合模型。劉君等(2006)[13]以36家舞弊公司和16家非舞弊公司為樣本,基于均值差異顯著的9個指標,構建了徑向基概率神經網絡財務報告舞弊識別模型。
財經理論與實踐(雙月刊)2015年第3期2015年第3期(總第195期)李清,任朝陽:基于案例推理的財務報告舞弊識別研究
財務報告舞弊是一類復雜的經濟現象[14],目前仍是會計研究領域的“灰箱”,而案例推理方法適用于規則不完善、不明確、不一致的領域[15],它在財務報告舞弊識別領域是否也有較高的正確率,國內尚未有這方面的研究。本文試圖構建財務報告舞弊識別的案例推理模型,以期達到較高識別正確率,輔助投資者鑒別上市公司財務報告信息真偽,提高投資決策的效率和效益。
二、基于案例推理的財務報告舞弊識別原理(一) 案例表示
每個樣本公司都視為一個案例,并用其特征屬性表示,以便于檢索和計算距離。
1. 原始案例篩選。
由于相關指標數據在2003年以后才較為完整,故樣本區間選擇為2003~2012年。CSMAR數據庫中共有16種違規類型,選取“虛構利潤、虛列資產、虛假記載(誤導性陳述)、披露不實、重大遺漏、推遲披露”6種違規類型作為研究樣本。刪除金融業和主營業務模糊的綜合類上市公司,最終得到滬深A股181家舞弊公司。以年初總資產規模相近、同行業、同年度為標準,選取181家非舞弊公司作為控制組樣本。
考慮到先建立模型后使用模型的時間順序,將全部樣本按照年份日期劃分為兩個樣本集:2003~2010年共計260個案例歸為訓練集,占71.8%,舞弊和非舞弊公司各130家;2011~2012年共計102個案例歸為測試集,占28.2%,舞弊和非舞弊公司各51家。
2. 特征屬性提取。“舞弊鉆石”理論為舞弊識別指標的提取提供了理論指導,該理論最早由Wolfe等[16]于2004年提出。通過對舞弊三角形理論的深入考察,結合對大量舞弊案的主要策劃者能力特征的分析,Wolfe等將舞弊動因進一步拓展為壓力、機會、合理化、能力四因素。追根溯源,舞弊三角形理論源自1950年美國著名犯罪學家Cressey對250個罪犯的訪談研究。經過為期5個月的訪談,Cressey發現,舞弊的產生是由壓力、機會、合理化三因素共同作用的結果 [17]。Wolfe等(2004)觀察發現,即使舞弊者感知到壓力且存在“較好”的舞弊機會,也有似乎“合理”的借口,但如果舞弊者估計自身能力不足以隱蔽地實施舞弊而不被懲罰,舞弊行為仍然不會發生[15]。舞弊者往往在組織內位居要職,熟悉組織的內部控制缺陷,認為自己能輕易避開懲罰,自負而且心理承壓能力較強。具備這些能力特征的策劃者被視為催動舞弊發生的第四個因素。
(1) 壓力因素。舞弊壓力有多種來源,而財務收支失衡、異常開支需求以及由意外損失導致的入不敷出等財務壓力是主要來源之一。企業財務壓力可以通過營運能力、盈利能力、償債能力、成長能力等反映出來。衡量營運能力的常用指標有應收賬款周轉率、存貨周轉率、總資產周轉率等;衡量盈利能力的常用指標有總資產凈利率、銷售凈利率、財務費用率、盈余經營現金流量差等;衡量償債能力的指標有流動比率、速動比率、現金比率、資本負債率等;衡量成長能力的指標有總資產增長率等[3,10,13]。考慮我國資本市場特殊的制度背景,例如對增發配股公司凈資產收益率的要求、對連續多年的虧損公司進行限制交易特殊處理(ST、*ST)乃至退市的規定,加之核準制下公開發行股票的門檻較高,“殼資源”尤為稀缺,上市公司具有強烈的業績達標舞弊傾向,鑒于此,使用是否具有配股動機、保盈動機衡量來自業績達標的舞弊壓力[11]。
(2) 機會因素。完善的公司治理機制是抵御和防范財務報告舞弊的重要屏障,公司治理不完善則往往給舞弊提供機會[5]。Beasley(1996)[2]研究發現,舞弊公司的董事會通常較少外部獨立董事。Dechow等(1996)[18]發現舞弊公司大多缺乏內部審計委員會,董事長與總經理二職合一現象較為普遍。此外,股權結構是公司治理的重要組成部分,被視為公司治理的產權基礎。我國上市公司國有股“一股獨大”現象突出,國資控股的公司由于所有者監督缺位,其經營者更有機會通過舞弊實現控制企業以獲取私人利益[19]。另一方面,注冊會計師審計是遏止組織舞弊的最后一道防線, 為了掩蓋舞弊行為,舞弊公司在舞弊實施年度傾向于變更審計師事務所[20],變更審計師可能導致不了解情況的新任審計師難以發現和阻止舞弊。綜上,本文選擇二職合一、獨董比例、是否設立審計委員會、國有股比例、事務所變更衡量機會因素。
(3) 合理化因素。合理化是為舞弊行為尋找借口的心理過程,舞弊者的行為與其自身道德可接受程度相關。如果一個人認為舞弊已經超出自身道德底線,則其通常不會實施。然而,由于行為者的心理活動是內在而復雜的,難以直接測量,已有研究大多借用與個人道德相關的代理變量進行間接衡量。Rae等[21]認為,舞弊等非誠信行為的發生常常由于當事人不夠正直。韋琳等(2011)[10]分析認為,存在舞弊行為的公司常常由于對審計工作的不配合,被出具非標準審計意見的可能性較大。舞弊公司的非誠信行為還往往給利益相關者帶來負面影響,更容易使公司陷入法律糾紛。據此,本文使用審計意見、法律訴訟衡量合理化因素。
(4) 能力因素。財務報告舞弊通常由管理者主導實施,對其個人能力特征的考察有助于識別潛在舞弊風險。Magnan(2013) [22]研究發現,管理者自負是財務報告舞弊的重要隱患,管理者自負的公司更傾向于實施財務報告舞弊。公司業務的增長來自持續的盈利,而自負的管理者傾向于通過資本運作等外部融資實現業務規模的快速擴張,通常體現為活躍的兼并收購計劃。換言之,兼并收購與財務報告舞弊的管理者具有共同的自負特征。鑒于此,不妨使用兼并收購衡量能力因素。綜上,本文提取的特征屬性指標如表1所示。3. 特征屬性篩選。
對訓練集進行指標均值差異檢驗,根據差異程度篩選用于舞弊識別的指標。使用SPSS軟件對舞弊和非舞弊公司的22個指標是否服從正態分布做KolmogorovSmirnov單樣本正態性檢驗,若兩類公司的某個指標均服從正態分布,則使用兩獨立樣本T檢驗方法檢驗該指標算術平均值是否相等,并依方差齊次性選擇對應的t值及其顯著性概率p值,據以判定均值差異是否顯著。對兩類公司不全服從正態分布的指標,則使用兩獨立樣本MannWhitney U檢驗方法檢驗其均值差異顯著性。均值存在顯著性差異的指標有總資產凈利率、銷售凈利率、財務費用率、資產負債率、總資產增長率、事務所變更、審計意見。
4. 原始案例庫構建。
設原始案例(即訓練集)為n個,案例特征屬性(即舞弊識別指標)為m個,則原始案例庫可以表示為如下矩陣:
公司1x11x12…x1m公司2x21x22…x2m……………公司nxn1xn2…xnm
其中,xij(i=1,2,…,n;j=1,2,…,m)表示第i個公司的第j個指標。(二) 案例檢索
1. 檢索方法確定。
K近鄰法作為一類非參數判別方法,常用于分類問題的解決。隨著K值取值增大(≥3個),該方法優勢更為明顯[23,24]。Terrell等(1992)研究表明,K近鄰法適用于變量為3個以上維數較多的情況 [25]。本文均值差異顯著的變量為7個,適宜采用K近鄰法進行案例檢索。
該方法的操作首先需要逐一測算新案例與所有原始案例的相似度,然后,對原始案例按與該案例相似程度大小進行降序排列,取其前K個案例,將此K個案例中占多數的類別賦予新案例,實現新案例類別判斷。為了追求判斷結果的穩健性,K值越大越好;而K值越大,相似度低的案例被檢索到的概率也會隨之增加,從而對新案例類別判斷形成干擾。最佳K值是在考慮穩健性和相似度基礎上的綜合折中。可以通過試算獲得不同K值的判斷正確率曲線,從中選擇最佳K值。為避免二義性,一般將K取為奇數。
2. 相似性測度公式確定。
研究中對案例相似性的測度往往使用兩個對象之間的距離來表達。距離越小表示兩案例越相似。常用的距離公式有:明氏距離(包括曼哈頓距離、歐氏距離、切比雪夫距離)和仿蘭氏距離[26]。
(1) 明氏距離。把案例看成m維空間的點,令dij表示案例i與案例j間距離,則明氏距離定義為:
dij(q)=q∑mα=1xiα-xjαq(1)
當q=1時,該公式稱為曼哈頓距離:dij(1)=∑mα=1xiα-xjα。經過加權的曼哈頓距離公式為: dyi(1)=∑mα=1ωαΩ×xyα-xiα,Ω=∑mα=1ωα。其中,dyi(1)是新案例y到第i個原始案例的距離(i=1,2,…,n);ωα是第α個屬性的權重(α=1,2,…,m);ωαΩ保證公式中m個特征屬性值的權重之和為1。當q=2時,該公式稱為歐氏距離:dij(2)=∑mα=1xiα-xjα2。經過加權的歐氏距離為:dyi(2)=∑mα=1ωαΩ×xyα-xiα2 ,公式中各參數意義同前。
當q=
(2) 仿蘭氏距離。蘭氏距離是由Lance和Williams最早提出,其計算公式為:dij=1m∑mα=1xiα-xjαxiα+xjα,該公式要求各屬性值大于0。由于存在負數故采用了所謂的仿蘭氏距離(加權后為): dyi=∑mα=1ωαΩ×xyα-xiαxyα+xiα,定義當xyα=xiα=0時,dyi=0。公式中各參數意義同前。
3. 特征屬性權重確定。
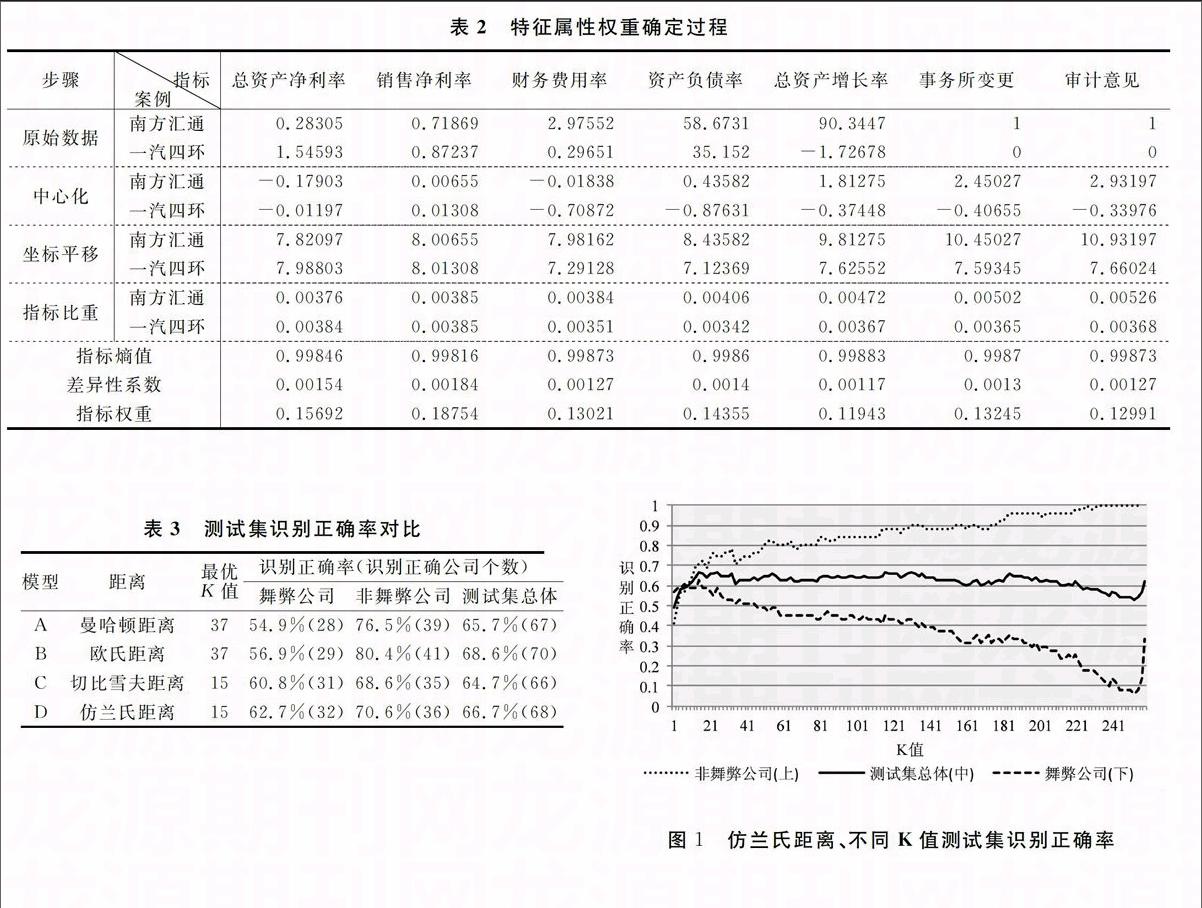
根據是否有人為因素參與,可以分為主觀賦權法和客觀賦權法。主觀賦權法包括層次分析法、德爾菲法等。客觀賦權法包括熵值法、主成分分析法、中心化系數Logistic回歸等,根據數據信息的相關性或差異性等特征構權。本文采用熵值法確定特征屬性權重。
三、財務報告舞弊識別案例推理模型的構建
(一) 熵值法確定權重的基本原理和步驟
熵是對系統無序程度的度量,系統越無序,熵值越大,系統越有序,熵值越小。因此,對于指標xj(j=1,2,…,m),其n個指標值差異越大,則該指標在案例綜合評價中所起的作用越大,所占的權重也應該越大;如果某個指標的n個值全部相等,則該指標對于不同案例不具有區分能力,其所占的權重應該為零[27]。熵值法賦權的計算步驟為:
1.指標無量綱化處理。對于由n個公司樣本,m個評價指標形成的指標矩陣X=(xij)n×m,中心化的公式為:
x′ij=(xij-x-j)/sj(2)
其中x′ij是中心化后的指標值,xj-=1n∑ni=1xij是第j項指標的均值,sj=1n-1∑ni=1(xij-xj-)2是第j項指標的標準差。
2.坐標平移。數據中心化后落入區間[-7.787136,9.681681]中,由于負數不能取對數、不能直接計算比重,所以進行坐標平移,令Zij=8+x'ij。為方便,仍將Zij記為xij。
3.計算指標xj中第i公司指標值xij的比重pij=xij/∑ni=1xij。
4. 計算指標xj的熵值ej=-(1ln n)∑ni=1pij×ln pij,式中乘以系數1/ln n,以便使得0≤ej≤1。
5.計算指標xj的差異性系數gj,定義gj=1-ej。
6.計算指標xj的權重wj=gj/∑mj=1gj,j=1,…,m。
上述數據處理過程示意如表2所示。
(二) 使用熵值法確定權重的案例推理模型
任取一家測試集案例y(y=1,2,…,102)計算其與訓練集260家案例的曼哈頓距離,得到距離集合Dy=dy1,dy2,…dy260。260家案例的類別集合定義為C=c1,c2,…,c260,其中ci(i=1,2,…,260)值為1表示舞弊、為0表示非舞弊。取集合Dy中K個最小值,構成案例調用集合Dyk,對應的類別集合為Cyk。若Cyk中等于1的元素的個數超過K/2,則將y判為舞弊公司,否則判為非舞弊公司。然后與y的實際類別對照,類別相同則判別正確,反之,則判別錯誤。取另一家測試集案例重復上述過程,遍歷測試集,最后得到測試集識別正確率。由于K取不同值時集合Cyk中的元素不同,從而識別結果不同,可以繪制不同K值的判別正確率曲線,從中選擇最佳K值。為避免二義性,K取1~259的奇數。
使用歐氏、切比雪夫、仿蘭氏距離重復上述計算過程,以對比不同距離的識別正確率,結果如表3所示。模型B總體正確率最高為68.6%,然而其舞弊公司識別正確率偏低。由于舞弊公司的錯判成本較高,因此考慮錯判成本,D模型為最優模型,其舞弊公司、非舞弊公司以及總識別正確率分別為62.7%、70.6%、66.7%。D模型不同K值下的識別正確率曲線如圖1所示,最優K值為15。
圖1仿蘭氏距離、不同K值測試集識別正確率
四、研究結論
本文以“舞弊鉆石”理論為指導提取舞弊識別指標,構建了案例推理模型并具有較高的識別正確率。研究發現,較之于非舞弊公司,舞弊公司通常面臨更大的盈利壓力和償債壓力,成長能力更弱,事務所變更現象更為普遍,被出具非標準審計意見的概率更高。基于仿蘭氏距離的案例推理測試集識別正確率達到66.7%,具有一定實用性。該研究豐富了舞弊識別領域的文獻,啟示審計師在舞弊審計中打破線性思維模式,充分調用已有舞弊審計經驗,以相似案例為參照,從整體上系統把握財務報告舞弊特征,提高舞弊識別能力,降低審計風險。
案例推理方法具有較強的開放性。還可以采用其它方法對指標賦權,如使用主成分分析、層次分析等方法賦權,以便與熵值法相互校驗權重設置的合理性。另外,不同距離公式下的模型識別正確率各不相同,未來還可以探討更多距離公式的應用,例如馬氏距離、夾角余弦、案例相關系數等。
參考文獻:
[1]Ngai E W T, Hu Y, Wong Y H, et al. The application of data mining techniques in financial fraud detection:a classification framework and an academic review of literature[J].Decision Support Systems, 2011, 50(3): 559-569.
[2]Beasley M S. An empirical analysis of the relation between the board of director composition and financial statement fraud[J]. Accounting Review, 1996, 71(4): 443-465.
[3]Lee T A, Ingram R W, Howard T P. The difference between earnings management and operating cash flow as an indicator of financial reporting fraud[J].Contemporary Accounting Research, 1999, 16(4): 749-786.
[4]Green B P, Choi J H. Assessing the risk of management fraud through neural network technology[J].AuditingA Journal of Practice &Theory, 1997, 16(1): 14-28.
[5]Fanning K M, Cogger K O. Neural network detection of management fraud using published financial data[J]. International Journal of Intelligent Systems in Accounting,Finance & Management,1998, 7(1): 21-41.
[6]Spathis C, Doumpos M, Zopounidis C. Detecting falsified financial statements: a comparative study using multicriteria analysis and multivariates statistical techniques[J]. The Euronean Accounting Review, 2002, 11(3): 509-535.
[7]Curet O, Jackson M, Tarar A. Designing and evaluating a casebased learning and reasoning agent in unstructured decision making[A]. In 1996 IEEE International Conference on Systems Man and Cybernetics[C]. IEEE,1996,4(10):2487-2492.
[8]Hwang S S, Shin T, Han I. CRASCBR: internal control risk assessment system using casebased reasoning[J]. Expert Systems, 2004, 21(1): 22-33.
[9]陳國欣, 呂占甲, 何峰. 財務報告舞弊識別的實證研究基于中國上市公司經驗數據[J]. 審計研究, 2007,(3): 88-93.
[10]韋琳, 徐立文, 劉佳. 上市公司財務報告舞弊的識別基于三角形理論的實證研究[J]. 審計研究, 2011,(2): 98-106.
[11]洪葒, 胡華夏, 郭春飛. 基于GONE理論的上市公司財務報告舞弊識別研究[J]. 會計研究, 2012,(8): 84-90.
[12]梁杰,位金亮,扎彥春. 基于神經網絡的會計舞弊混合識別模型研究[J]. 統計與決策, 2006,(3):152-153.
[13]劉君, 王理平. 基于概率神經網絡的財務舞弊識別模型[J]. 哈爾濱商業大學學報(社會科學版), 2006,(3): 102-105.
[14]陳慧璇,朱君.我國上市公司財務報告舞弊特征分析[J].稅務與經濟,2013,(2):52-27.
[15]Ashley K D, Rissland E L. Compare and contrast: a test of expertise[A].AAAI'87 Proceedings of the Sixth National Conference on Artificial Intelligence, 1987:273-278.
[16]Wolfe D T, Hermanson D R. The fraud diamond:considering the four elements of fraud[J]. The CPA Journal, 2004,(12): 38-42.
[17]Kassem R, Higson A. The new fraud triangle model[J]. Journal of Emerging Trends in Economics & Management Sciences, 2012, 3(3): 191-195.
[18]Dechow P, Sloan R, Sweeney A. Causes and consequences of earnings manipulation:an analysis of firms subject to enforcement actions by the SEC[J]. Contemporary Accounting Research, 1996, 13(1): 1-36.
[19]劉立國, 杜瑩. 公司治理與會計信息質量關系的實證研究[J]. 會計研究, 2003,(2): 28-36.
[20]Beasley M S, Carcello J V, Hermanson D R. Fraudulent financial reporting: 1987-1997.an analysis of US public companies[EB/OL]. http://www.Coso.org/Publications/FFR_1987_1997.pdf,2014-10-01.
[21]Rae K, Subramaniam N. Quality of internal control procedures:antecedents and moderating effect on organisational justice and employee fraud[J]. Managerial Auditing Journal, 2008, 23(2): 104-124.
[22]Magnan M, Cormier D. Financial reporting frauds:a manifestation of hubris in the csuite?some exploratory evidence[J]. Cahier De Recherche, 2013,(2):1-51.
[23]Fix E, Hodges Jr J L. Discriminatory analysisnonparametric discrimination:small sample performance[R]. California Univ Berkeley, 1952.
[24]Cover T, Hart P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory,1967, 13(1): 21-27.
[25]Terrell G R, Scott D W. Variable kernel density estimation[J]. The Annals of Statistics, 1992, 20(3): 1236-1265.
[26]李清, 劉金全. 基于案例推理的財務危機預測模型研究[J]. 經濟管理, 2009, 31(6): 123-131.
[27]郭顯光. 改進的熵值法及其在經濟效益評價中的應用[J]. 系統工程理論與實踐, 1998,(12): 99-103.
(責任編輯:漆玲瓊)
