基于JAVA建立樹形結構的算法優化
2015-05-25 03:24:10宋小倩張書茂
大慶師范學院學報 2015年3期
宋小倩,張書茂,康 彥
(安徽城市管理職業學院 信息工程系 安徽 合肥230011)
0 引言
樹形結構是指數據元素之間存在著一對多的樹形關系的數據結構,是一類非常重要的非線性數據結構。樹形結構可用于表示從屬關系,層級關系等。本文介紹一種從普通Java 對象中建立樹形結構的算法。
1 樹形結構的算法設計
1.1 場景介紹
在教師信息系統中,基本信息模塊中需要填寫各種地址,包含戶口所在地地址、家庭詳細地址和當前居住地詳細地址等。如果這些地址直接由輸入框輸入,則無法保證信息填寫的信息準確性,另外在后續需要根據省、市、縣等各類條件生成報表信息時會無法處理。因此,通過以樹形形式提供選擇框供選擇,這樣上面的信息準確性、后續條件過濾時出現的問題都可以避免。
而地址的原始數據與頁面中樹的展示格式相差較遠。如何高效地根據原始數據生成樹形結構便成為該模塊中非常重要的問題。如果處理不好就會在使用樹進行選擇的時候出現卡頓現象,影響用戶體驗。下面詳細介紹一種高效地在內存中構建完整樹形結構的算法,供大家借鑒學習。
數據本身存儲在數據庫中,需要顯示時則從數據庫加載數據后進行顯示。需要建立樹形結構的時候,可以從最頂級節點開始按級查找下級所有子節點來構建樹形結構[1]。優點:不需要一次性構建整個樹形結構。缺點:每次展開某節點時,都需要去數據庫查詢該節點的所有子節點。數據庫壓力非常大,同時會導致界面操作出現卡頓現象。
可以考慮將樹形結構需要的數據一次性加載到內存當中,在內存中構建樹形結構的所有節點結構然后再顯示。這樣既可以減輕數據庫壓力,又可以增強用戶體驗[2]。
如圖1給出省市縣鎮村的部分數據。其中code 列為身份證識別碼,first 列為省,second 為市,third 為縣,fourth 為鎮,fifth 為村。現在即要在這種數據對象中構建省市縣鎮村多級樹形結構。
因為每級結構都是文本數據,無法直接通過上一級節點直接得到下一級節點數據,更無法直接通過下一級節點得到上一級節點數據。比如通過“鎮”列得到“村”列時,必須保證“鎮”列所屬的“省、市、縣”是一致的。這樣從省到村上下級關系來構建樹形結構,則查詢每個節點(除最后一級節點外)的所有子節點都需要遍歷整份數據。假設整份數據有N 條,則需要遍歷數據N^5 次,即遍歷算法復雜度至少O(N^5)。如果數據為100 條則需要100^5=100 億次。這種算法必然是不可行的。
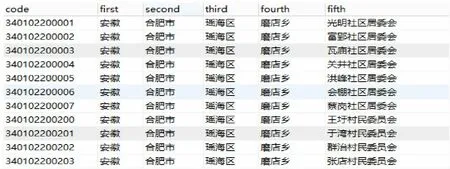
圖1 省市縣鎮村數據(部分)
1.2 算法設計
圖1這種數據在日常生活中是非常常見的。如果算法設計不當,則會得到O(N^5)的算法復雜度,在程序設計中必然無法接受。
分析這種方法的不合理的原因,主要有以下幾點:
(1)每個節點都是無狀態的。即每個節點都不是自說明的,而是由前面幾級節點共同控制才能保證唯一性[3]。
(2)每次遍歷數據都沒有對數據進行緩存。因為沒有緩存上一次讀取的數據,導致處理任何一個節點的下一級節點時都需要再完整遍歷一次整份數據。
為了解決節點的無狀態問題,可以對每級節點進行編碼,比如first 可以編碼為01,second 節點編碼為0101,third 節點編碼為010101,fourth 節點編碼為01010101,fifth 節點編碼為0101010101。這種方法的優點是每個節點都是有狀態的。缺點是每個節點在構建時需要先編碼。
本文設計的算法則是對上述方法進行改進,即對每級節點做到狀態自說明。方法即是在每級節點中記錄上一級節點文本。比如記錄“合肥市”則記錄為“安徽@合肥”,“瑤海區”則記錄為“安徽@合肥@瑤海區”,之后節點依次類推(假設分隔符號為“@”)。如圖2為優化后的記錄方式。這些記錄只在內存中進行構建,不真正修改數據庫。
從圖中可以看出,該種處理方式是一種以空間換時間的解決方案。可以解決節點的無狀態問題,但仍然無法解決需要多次遍歷數據的問題。還需要對節點數據進行緩存。

圖2 優化后的記錄方式
在讀取數據過程中要對層級關系進行存儲,因為使用圖2的優化后記錄方式,再也不用擔心節點名稱重復的問題了。
如何預處理一遍數據則建立上下級層級關系呢?使用一個關系容器(假設名稱為dataMap)記錄上下級層級關系,所有層級關系存儲在同一個關系容器當中。如first 與second,second 與third 等都存儲起來,過濾掉重復的記錄[4]。
關系容器記錄后效果如下(“=>”或“/”符號只用于說明上下級關系,不代碼具體存儲方式):
安徽=>安徽@合肥市/ 安徽@蕪湖市...
安徽@合肥市=>安徽@合肥市@瑤海區
安徽@合肥市@瑤海區=>安徽@合肥市@瑤海區@磨店鄉
安徽@合肥市@瑤海區@磨店鄉=>安徽@合肥市@瑤海區@磨店鄉@富郢社區居委會/ 安徽@合肥市@瑤海區@磨店鄉@瓦廟社區居委會...
上面僅解決了如何記錄數據和存儲數據,還沒有真正地建立樹形結構。
有了上述的數據,再來建立樹形結構則非常方便了。假設需要生成的樹形結構數據如圖3的JSON格式。
在圖3中,對于每級節點記錄文本數據(text)和子節點數據(children)。如果該層節點沒有子節點僅記錄text 而不記錄children。

圖3 需要的樹形結構數據
2 算法實現
第1 部分已經非常清晰地將算法設計出來了,下面使用Java 來實現該算法。
2.1 算法的Java 實現
優化數據記錄實現如圖4所示。其中,srcList 是源數據,可以從數據庫中加載或在程序中模擬。nodeList 是需要構建樹的節點名稱。dataMap 用于記錄節點與下級節點的map 數據。rootList 用于記錄根節點數據。cnMap 用于記錄每個節點所有子節點數量。
詢多個節點的子節點數據的實現如圖5所示。其中map 為圖4中輸出的dataMap。keyList 為多個節點的名稱。cnMap 為圖4中輸出的cnMap。
圖6為構建樹形結構程序的入口。輸入參數為srcList,可以從數據庫中加載或在程序中模擬。nodeList 是需要構建樹的節點名稱,傳入想要構建樹的字段即可[5]。
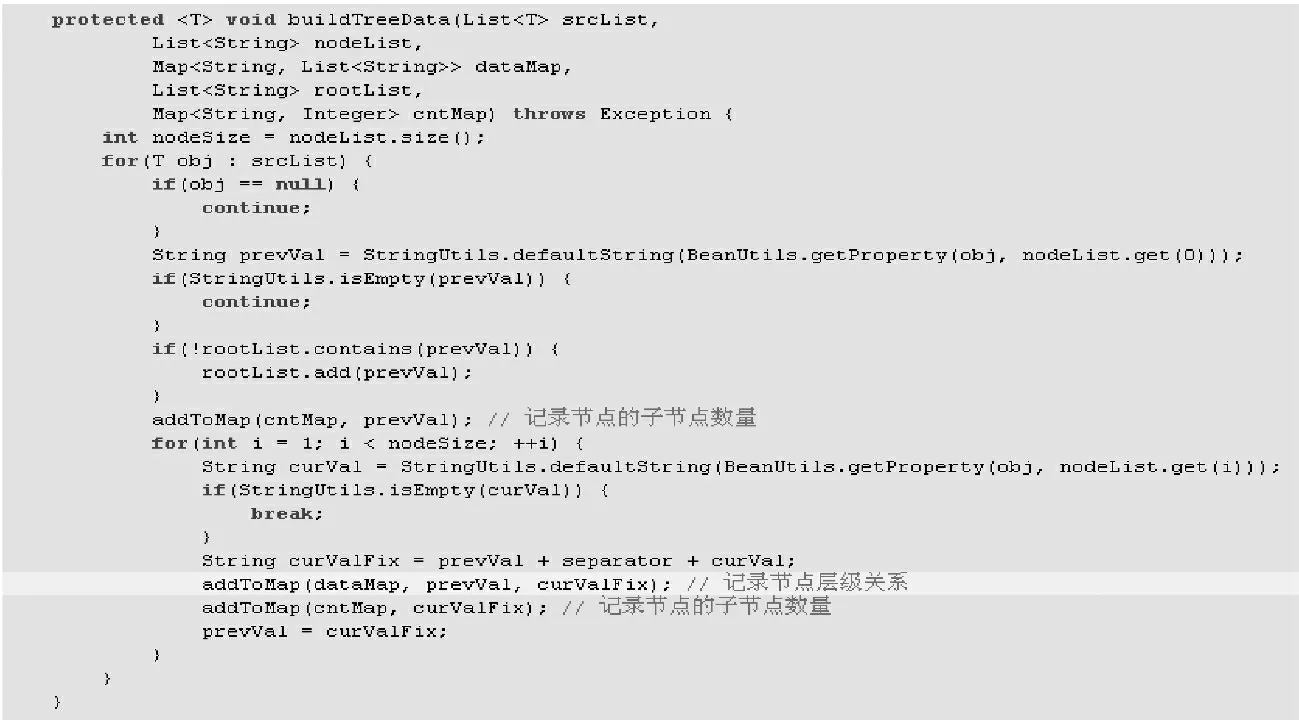
圖4 優化數據記錄的實現
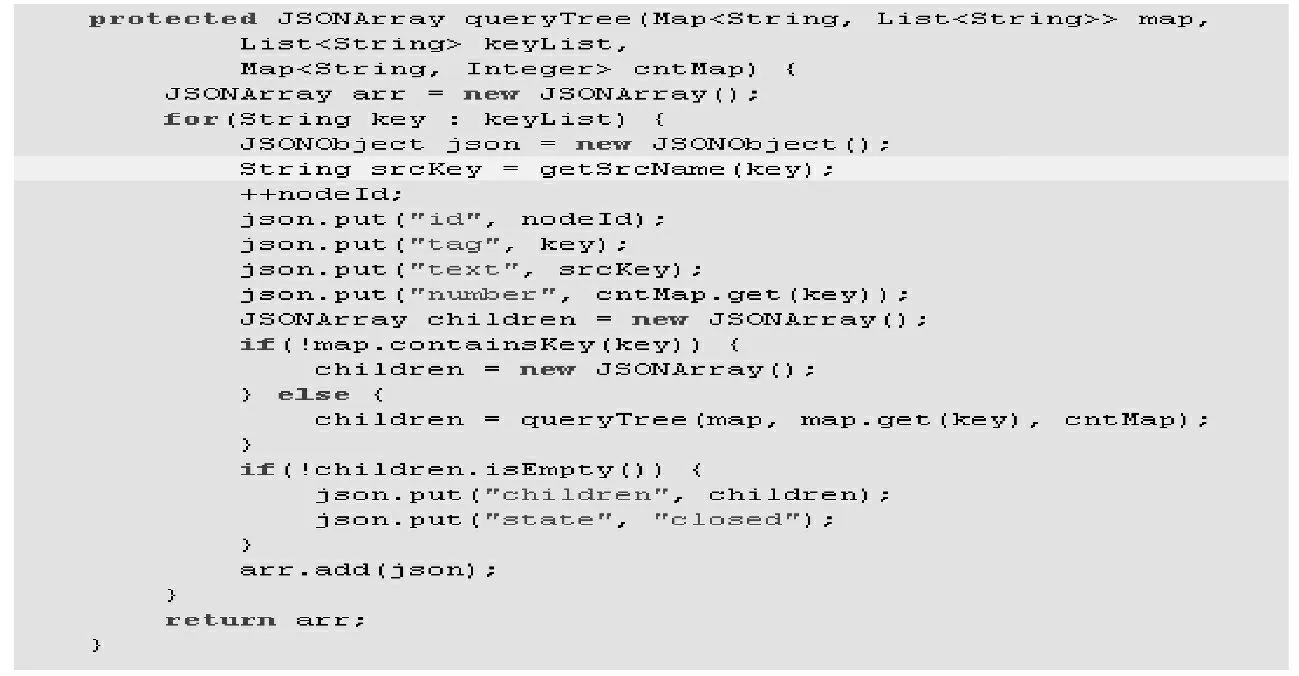
圖5 遞規查詢多個子節點的實現
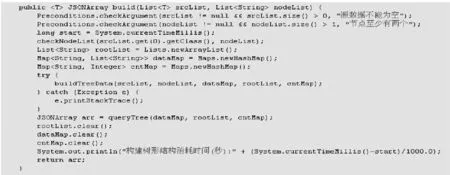
圖6 構建樹形結構的實現
2.2 實現效率和效果
在Java 中實現該算法是非常高效的,構建樹的效率也是非常高的。
使用全國的省市縣鎮村的數據來構建樹,原始數據有70 萬條左右。在Windows8 中構建該樹的5 級結構只需要5 秒左右。
如果使用安徽省的數據來測試,原始數據是2 萬條左右。構建該樹的5 級結構只需要0.2 秒左右。
顯示的效果如圖7所示。左邊的圖即是普通的樹形結構顯示,右邊的圖中每級節點顯示時加入了其對應的所有子節點個數。

圖7 樹形結構顯示效果
3 結 語
本文描述了從普通對象中建立樹形結構的一種算法設計,并使用Java 語言進行了實現。如果需要建立相關樹形結構會非常方便。
通過使用文中所述的根據對象集合建立樹形結構算法,即可高效地創建頁面中需要的樹形結構,提升頁面展現效果,有效地解決了系統中多處地址選擇問題,達到了預期效果。另外,文中對該算法也使用高效的方法進行實現,如果需要建立相關樹形結構直接借鑒即可。
[1]嚴蔚敏等.數據結構:2 版[M].北京:清華大學出版社,2012.
[2]Thomas H.Cormen 等.算法導論:3 版[M].北京:機械工業出版社,2013.
[3]嚴蔚敏等.數據結構題集(C 語言版)[M].北京:清華大學出版社,2011.
[4]韋斯等.數據結構與算法分析:Java 語言描述[M].北京:機械工業出版社,2009.
[5]王希軍.java 程序設計案例教程[M].北京:北京郵電大學出版社,2012.
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
現代企業(2015年9期)2015-02-28 18:56:50
