自動(dòng)文摘的關(guān)鍵技術(shù)
2015-05-15 10:13:40駱俊帆
現(xiàn)代計(jì)算機(jī) 2015年2期
駱俊帆
(四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065)
自動(dòng)文摘的關(guān)鍵技術(shù)
駱俊帆
(四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065)
隨著互聯(lián)網(wǎng)上信息爆炸性地增長(zhǎng),信息過載問題給人們?cè)斐闪死_,檢索過程中如何有效地命中所需信息成為一個(gè)亟待解決的問題。為了從互聯(lián)網(wǎng)上更加效率地瀏覽和吸收信息,自動(dòng)文摘技術(shù)在保留原文主要內(nèi)容的前提下,對(duì)文檔進(jìn)行壓縮表示。探討自動(dòng)文摘的概念和意義,并對(duì)當(dāng)前自動(dòng)文摘的關(guān)鍵技術(shù)做一個(gè)較為全面的綜述性介紹。
檢索;自動(dòng)文摘;效率
0 引言
隨著信息時(shí)代的飛速發(fā)展,互聯(lián)網(wǎng)中累積了大量的文本信息,然而通常人們的興趣點(diǎn)只是其中極少的部分,如何迅速有效地從海量信息中找到它們是亟待解決的問題。信息檢索技術(shù)的出現(xiàn)緩解了這個(gè)問題帶來(lái)的壓力,但成千上萬(wàn)的檢索結(jié)果與人們的實(shí)際需求還相差甚遠(yuǎn)。
自動(dòng)文摘技術(shù)[1]的目標(biāo)是在保留原文核心內(nèi)容的前提下,對(duì)原始文本進(jìn)行信息壓縮表示。文摘準(zhǔn)確全面地反映了某一文獻(xiàn)的核心內(nèi)容,它是一種簡(jiǎn)潔連貫的短文,而自動(dòng)文摘技術(shù)則用于自動(dòng)地從文檔中提取文摘。傳統(tǒng)的信息檢索技術(shù)在面對(duì)信息過載危機(jī)時(shí)并不能達(dá)到一個(gè)很好的效果,而自動(dòng)文摘技術(shù)可以在一定程度上起到輔助作用[2]。首先,信息檢索過程中可以使用優(yōu)質(zhì)的文摘替代原始文本進(jìn)行檢索,極大提高了檢索信息的效率。其次,在檢索結(jié)果的可視化中利用優(yōu)質(zhì)文摘,用戶不需要對(duì)大量的原始檢索結(jié)果進(jìn)行瀏覽便能輕松取舍,不但能提高需求信息的命中率,用戶負(fù)擔(dān)也大大地降低了。因此自動(dòng)文摘技術(shù)逐漸成為當(dāng)前信息檢索領(lǐng)域的研究熱點(diǎn)之一。
自動(dòng)文摘技術(shù)可被分為摘要(abstract)和摘錄(extract)兩類[3],摘要方法[4~5]試圖在對(duì)文本主要內(nèi)容的理解基礎(chǔ)上,使用簡(jiǎn)短連貫的自然語(yǔ)言將原文主要內(nèi)容描述出來(lái),即會(huì)使用新的句子組成摘要。而摘錄方法則首先從原始文檔中抽取出重要的句子,然后再將這些句子連貫到一起形成摘要。其中句子重要性由一些統(tǒng)計(jì)和語(yǔ)言學(xué)特征所決定。當(dāng)前自動(dòng)摘要技術(shù)大多都是基于摘錄的方法,通常自動(dòng)文摘包含文本預(yù)處理、文本分析處理以及生成文摘三個(gè)步驟,并且存在一些不同的文摘評(píng)估方法。本文接下來(lái)將對(duì)自動(dòng)文摘技術(shù)做一個(gè)概述性的介紹。
1 文本預(yù)處理
經(jīng)過預(yù)處理,原始文本有結(jié)構(gòu)化的表示。一般包括三步:
句子邊界識(shí)別。英文文本中,常常利用句點(diǎn)本身,再考慮句點(diǎn)上下文信息制訂一些規(guī)則進(jìn)行句子邊界識(shí)別[6]。
去除停用詞。對(duì)于一個(gè)特定的目的,停用詞可以是任意類別的詞語(yǔ)。一般停用詞可分為兩類:人類語(yǔ)言常出現(xiàn)的功能詞和應(yīng)用十分廣泛的詞。所謂功能詞是不包含任何實(shí)際意義的詞語(yǔ),如“am”、“is”、“are”、“the”、“what”等。而對(duì)于第二類詞語(yǔ),如“want”,廣泛地出現(xiàn)在各種文檔中。
還原詞根。詞根還原的目的是,獲取到能表達(dá)詞義的原始詞根形態(tài)。表1是一個(gè)詞根還原示例。
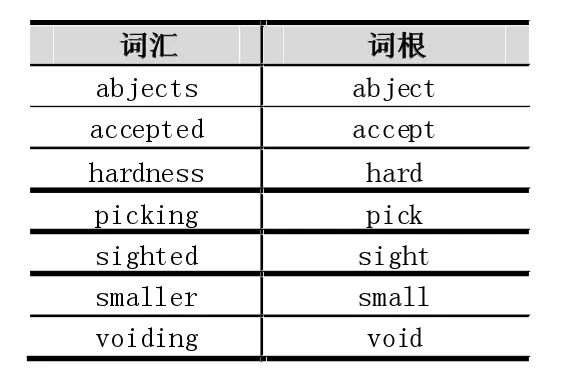
表1 詞根還原示例
2 文本分析處理
文本分析處理過程輸出一個(gè)涵蓋了原始文本主要內(nèi)容的中間表示文本,并對(duì)文本中的每個(gè)句子賦以重要性得分,這里列舉一些常用的方法。
2.1 詞逆向文檔頻率(TF-IDF)方法
文獻(xiàn)[7]中使用詞頻和逆向句子頻率構(gòu)建句子級(jí)別的詞袋子模型,其中逆向句子頻率就是文檔中包含給定單詞的句子的頻率。查詢相關(guān)的文摘系統(tǒng)中,構(gòu)建好這些句子向量之后,通過計(jì)算和查詢的相似度,高相似度的句子可用作摘要。一般性的文摘系統(tǒng)中,可以將一些文檔中的高頻詞作為查詢?cè)~集,因?yàn)檫@些高頻詞可以視作是文檔的一些主題詞。
2.2 基于聚類的方法
人們通常是一個(gè)主題接一個(gè)主題地組織一篇文檔,這些不同的主題會(huì)顯式或隱式地分布在不同的章節(jié)部分中,這種現(xiàn)象在自動(dòng)文摘中也可以用到。直覺上,摘要涉及到文檔的每個(gè)主題,因此有自動(dòng)文摘技術(shù)通過聚類的方法,將同一主題下的句子聚到一起,進(jìn)而生成合適的摘要。這類自動(dòng)文摘系統(tǒng)輸入的是經(jīng)過聚簇的文檔,每個(gè)簇是文檔的一個(gè)主題,主題用簇中TFIDF[8]值高的詞匯集表示。句子重要性得分由句子和主題的相似度度量,另外句子在文檔中出現(xiàn)的位置信息也能考慮進(jìn)去,例如在新聞文章中,開頭位置的句子就更重要一些。
2.3 基于圖論的方法
從前面的方法可以看出,識(shí)別文檔中主題是一個(gè)必要的環(huán)節(jié)。文獻(xiàn)[9]提出一個(gè)基于圖論的方法來(lái)識(shí)別這些主題,用一個(gè)無(wú)向圖表示文檔,圖中節(jié)點(diǎn)表示文檔中的句子。如果兩個(gè)句子有一定數(shù)量的相同詞匯,或者說它們的余弦相似度超過一定閾值,那么這兩個(gè)句子間存在一條邊。如圖1所示,不相連的子圖其實(shí)就是文檔的不同主題塊,而重要性越大的句子節(jié)點(diǎn)即有越多的邊連接。圖1中就包含有3~4個(gè)主題,大的實(shí)心黑圈則表示重要性大的句子。

圖1 基于圖論的方法示例
2.4 基于機(jī)器學(xué)習(xí)的方法
給定訓(xùn)練文檔和相應(yīng)摘要的集合,自動(dòng)文摘可以看作是一個(gè)分類問題:基于一些語(yǔ)言學(xué)特征和上下文特征,文檔中的每個(gè)句子被分為摘要類句子和非摘要類句子。文獻(xiàn)[10]中,利用大規(guī)模訓(xùn)練語(yǔ)料和貝葉斯分類器計(jì)算每個(gè)句子屬于摘要型句子的概率:
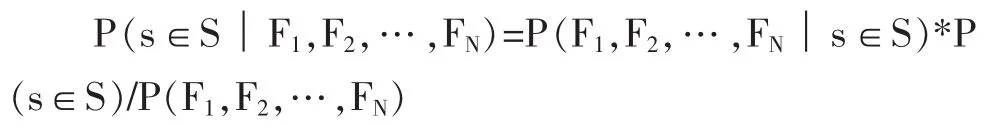
其中s表示文檔中的句子,S是最終生成的摘要,F(xiàn)1…FN是分類用到的特征。
3 生成文摘
最終文摘生成的復(fù)雜度取決于用戶不同的需求,目前實(shí)用系統(tǒng)所能生成的摘要是把從原文中抽取的片段和句子稍作潤(rùn)色及修改得到的結(jié)果。如果只需要簡(jiǎn)單地羅列出來(lái)原文的信息片段所包含的語(yǔ)義信息,那么幾乎可以省略掉生成摘要這步工作。而如果最終需要的是一篇語(yǔ)句連貫、內(nèi)容完整的短文,達(dá)到與人工水平相提并論的程度,那這一步工作就非常復(fù)雜了。因?yàn)槲恼哪康氖翘岣咝畔z索命中文獻(xiàn)的速度和效率,潤(rùn)色及修改工作不會(huì)做出太大貢獻(xiàn),反而檢索系統(tǒng)的處理時(shí)間會(huì)消耗更多。所以雖然語(yǔ)言學(xué)知識(shí)有利于增強(qiáng)文摘的可讀性,但自動(dòng)文摘系統(tǒng)大多情況下并不需要它。
4 文摘評(píng)估
自動(dòng)文摘的評(píng)估[12~14]也是一項(xiàng)非常重要的任務(wù),一般來(lái)說文摘評(píng)估策略分為內(nèi)部(intrinsic)評(píng)價(jià)和外部(extrinsic)評(píng)價(jià)兩種。內(nèi)部評(píng)價(jià)要利用到人工主觀性感覺,語(yǔ)句通順、句間語(yǔ)義連貫并且不包含主語(yǔ)懸掛現(xiàn)象的文摘是優(yōu)質(zhì)的文摘。而外部評(píng)價(jià)策略則是一種基于任務(wù)的評(píng)價(jià)方法,例如針對(duì)信息檢索任務(wù)設(shè)計(jì)評(píng)估策略,文檔正確檢索率就可以作為評(píng)價(jià)指標(biāo)[15]。兩種評(píng)價(jià)方法各有利弊:內(nèi)部評(píng)價(jià)方法需要人工評(píng)價(jià),主觀性太強(qiáng),并且評(píng)價(jià)結(jié)果可能因人而異,但是評(píng)價(jià)方法不局限于特定的任務(wù);而外部評(píng)價(jià)方法雖然是客觀性的評(píng)價(jià),易于對(duì)比不同的文摘系統(tǒng),但是評(píng)價(jià)方法局限于一個(gè)特定的任務(wù)。
5 結(jié)語(yǔ)
自動(dòng)文摘技術(shù)可以將冗長(zhǎng)的文檔內(nèi)容進(jìn)行精簡(jiǎn),并且不損失主要信息,在一定程度上能輔助檢索系統(tǒng)解決信息過載問題。挑戰(zhàn)在于從海量的文本信息中,針對(duì)特定的用戶需求能迅速地生成高準(zhǔn)確率、低冗余的摘要。本文從文本預(yù)處理、文本分析處理、生成文摘和文摘評(píng)估四個(gè)方面對(duì)自動(dòng)文摘技術(shù)進(jìn)行了綜述。
[1] Mani I.,Maybury M.,eds.1999.Advances in Automatic Text Summarization[M].MIT Press
[2] 柴曉麗.自動(dòng)文摘技術(shù)的研究與應(yīng)用[D].長(zhǎng)春理工大學(xué),2007
[3] Vishal Gupta,Gurpreet Singh Lehal.A Survey of Text Summarization Extractive Techniques[J].Journal of Emerging Technologies in Web Intelligence,2010:258~268
[4] G Erkan,Dragomir R.Radev.LexRank:Graph-based Centrality as Salience in Text Summarization[J].Journal of Artificial Intelligence Research,2004:457~479
[5] Udo Hahn,Martin Romacker.The SYNDIKATE Text Knowledge Base Generator[C].Proceedings of the First International Conference on Human Language Technology Research,2001
[6] Read,Jonathon,Rebecca Dridan,Stephan Oepen,Lars Jrgen Solberg.Sentence Boundary Detection:A Long Solved Problem[C].In Proceedings of COLING,2012:985~994
[7] H.P.Luhn.The Automatic Creation of Literature Abstracts[R].Presented at IRE National Convention,1958:159~165
[8] Yong zheng,Nur,Evangelos.Narrative Text Classification for Automatic Key Phrase Extraction in Web Document Corpora[C].WIDM,2005:51~57
[9] Canasai Kruengkari,Chuleerat Jaruskulchai.Generic Text Summarization Using Local and Global Properties of Sentences[C].Proceedings of the IEEE/WIC International Conference on Web Intelligence(WI’03),2003
[10] Horacek H,ZockM,ed.New Concepts in Natural Language Generation:Planning,Realizations and Systems[M].London:Pinter Publishers,1985
[11] Salton G,Singhal A,Mitra M.,Buckley C.Automatic Text Structuring and Summarization[C].IP&M,1997:193~207
[12] Ani Nenkova,Rebecca Passonneau.Evaluating Content Selection in Summarization:The Pyramid Method[C].HLT-NAACL,2004: 145~152
[13] Chin-yew Lin.A Package for Automatic Evaluation of Summaries[C].in Proc.ACL Workshop on Text Summarization Branches Out, 2004
[14] Eduard Hovy,Chin-Yew Lin,Liang Zhou,Junichi Fukumoto.Automated Summarization Evaluation with Basic Elements[C].In Proceedings of the 5th International Conference on Language Resources and Evaluation(LREC),2006
[15] Kathleen Mackeown,Ani Nenkova,David Elson,Rebecca Passonneau,Julia Hirschberg.A Task Based Evaluation of Multidocument System[C].SIGIR,2005
作者簡(jiǎn)介:駱俊帆(1990-),男,湖北黃岡人,在讀碩士研究生,研究方向?yàn)閿?shù)據(jù)挖掘
The Key Technologies of Automatic Summarization
LUO Jun-fan
(College of Computer Science,SCU,Chengdu 610000)
With the explosive growth of the Internet information,the information overload problem trouble people.How to effectively hit the required information in retrieval has become a problem to be solved.In order to view and absorb information from the Internet more efficiently,automatic summarization technology can compress the document by keeping the original main content.Discusses the concept and significance of automatic summarization,and makes an introduction for the key technologies of the automatic summarization.
Retrieval;Automatic Summarization;Efficient
1007-1423(2015)02-0035-04
10.3969/j.issn.1007-1423.2015.02.009
2014-12-02
2014-12-16
四川省科技創(chuàng)新苗子工程(No.13-YCG058)
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中國(guó)教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
