說話人功能性副語音自動檢測算法
2015-04-29 00:59:18趙小蕾趙慧青
智能計算機與應用 2015年1期
趙小蕾 趙慧青
摘 要:功能性副語音如笑聲、哭聲、嘆息聲等的研究在情感識別領域中越來越受到關注,開始被作為識別說話人情感重要的信息之一。然在應用與研究中功能性副語音能否被自動檢出是前提。針對這一需求,根據音頻分割算法提出了基于定長分段的功能性副語音自動檢測算法以及基于距離與貝葉斯的功能性副語音自動檢測算法。并提出了結合靜音幀語音分割點確認算法對分割點進一步確認,并通過實驗驗證了該算法是有效的。通過實驗對比兩種檢測算法的優劣,實驗結果表明:基于定長分段自動檢測算法較好,檢測率達到70%,較基于距離與貝葉斯的檢測算法高出5%。
關鍵詞:功能性副語音;定長分段;自動檢測;檢測率
中圖分類號:TP391 文獻標識碼: A 文章編號:2095-2163(2015)01-
Abstract: The functional paralanguages ??such as laughter, cries, and sighs get more and more attention in the field of emotion recognition. It is to be one of the important information as to identify the speaker emotion. While, automatic detection of functional paralanguage is the premise in the application and research. In response to this demand, according to the segmentation algorithm for audio, automatic detection of functional paralanguages algorithm based on fixed-length segments and algorithm based on distance and Bayesian are proposed. And a segment point confirmation combining with silence frame is proposed, and experiments are conducted to verify the algorithm. Through the experimental comparison of the two detection algorithms, the experimental results show that: the automatic detection algorithm based on fixed-length segments is better, and the detection rate is 70%, which is higher than detection algorithm based on distance and Bayesian by 5%.
Key words: Functional Paralanguage; Fixed-length Segment; Automatic Detection; Detection Rate
0引 言
功能性副語音如哭聲、笑聲、嘆息聲等的研究越來越受到各個領域學者的重視,并逐漸被引入到模式識別領域中。在文獻[1]中提到副語音攜帶更重要的情感信息,并且其受說話者的變化影響較少,文獻[2]中提出其比語音更具有可靠性。目前,功能性副語音的研究主要集中在特征提取、識別等方向上,而卻鮮有文章對功能性副語音的自動檢測做出系統的研究。事實上,在實際應用中,功能性副語音的自動檢測尤為重要,其檢測結果更是功能性副語音應用和研究的基礎,針對這一實際需求,本文提出一種較為通用的檢測算法。
功能性副語音與語音之間存在明顯的差異,可將其視為與語音截然不同的音頻類別,故可引入音頻分割算法實現功能性副語音的自動檢測過程。在文獻[3]中就將音頻分割算法分為基于距離的算法、基于模型選擇的算法和基于模型的算法三類。具體地,第一,基于距離的算法采用滑動窗得到一條距離曲線,曲線上大于某一閾值的局部最大點被確認為分割點。該算法實現簡單,缺點是閾值很難確定,閾值過大則會漏檢掉正確的分割點,閾值過小則會增加虛假分割點;第二,基于模型選擇的算法,最常用的是Chen等[4]提出的基于貝葉斯信息準則(Bayesian information criterion, BIC)算法,由于具有良好的統計學理論基礎,而取得了較好的效果。還需指出,BIC音頻分割算法的缺點是計算量較大、受懲罰因子影響較大。相應地,針對BIC的缺點,一些文章對其實現了不同程度的改進,典型成果可如文獻[5-6];第三,基于模型的算法,則是為不同的音頻類別建立模型,并于分割時利用訓練好的模型對每一幀或若干幀進行識別分類,再將類別發生變化處作為分割點。針對性成果可如文獻[7-9]的研究即均以基于模型的分割算法為基礎,但其不足卻是需要事先知道不同音頻的類別數目和大量的音頻訓練數據。此后,綜合以上三類算法的優缺點,又相繼提出了一些混合分割算法,代表性研究如基于距離與貝葉斯混合音頻檢測算法(Distance Bayesian information criterion, DISTBIC)。而且文獻[10]就對基于距離與貝葉斯混合音頻檢測算法進行了改進,進而提出了保守的BIC混合分割算法,并且獲得了較好的效果。
根據以上分析,本文提出了基于定長分段的功能性副語音檢測算法以及基于距離與貝葉斯的功能性副語音檢測算法,而且為了提高檢測精度,又進一步提出了結合靜音幀語音分割點確認算法。
1功能性副語音自動檢測算法
1.1結合靜音幀語音分割點確認算法
在分割不同類別段的過程中,由于實驗誤差等不確定因素,所分割的類別段與實際類別段有一定偏差,這一偏差在這里是以幀為單位。不同類別段之間的分割位置可稱之為類別分割點。不同功能性副語音即可看成不同的類別,而且檢測也必須基于類別段的準確分割,故分割點越接近真實分割位置,功能性副語音的檢測將會越準確。分析大量說話人語音中功能性副語音的特點后,發現類別分割點位于靜音段(由若干靜音幀組成),而靜音幀的過零率為0。根據這一結論,提出了結合靜音幀語音分割點確認算法,對初步分割的分割點進行確認和修正,從而使得分割點更接近于真實分割點。具體算法描述可如算法1所示。
算法1:結合靜音幀語音分割點確認算法
Input:一段語音候選分割點集合Seg
Output:分割點集合SegN
Step1:設定閾值T(以幀為單位);
Setp2:從集合Seg中取一候選分割點,如果分割點過零率為0則將該分割點計入到集合SegN,重復執行Step2直到所有候選分割點處理完畢,執行Step4,否則執行Step3;
Step3:若在閾值T內存在靜音幀,則以該靜音幀為新的類別分割點,并計入到集合SegN中;否則去掉該候選分割點。執行Setp2;
Step4:輸出集合SegN。
1.2說話人功能性副語音自動檢測算法描述
假設功能性副語音檢測模型D_M已經訓練完成,該模型可識別功能性副語音和典型情感語音兩個類別。基于此,另設一含有n個待檢測的與人無關的語音情感樣本集合,標記為Sp={sp1,sp2,…,spn},而segN(Sp)={segN(spi)}為各個樣本的分割點集合,以及對應的分離后的樣本片段集合為S(Sp)={S(spi)},并且各語音片段對應的類別標簽集合又可記為Lable(Sp)={Lable(spi)}。上述集合中,i=1,2,…,n。則功能性副語音自動檢測算法描述則如算法2和算法3所示。
算法2:基于定長分段的功能性副語音自動檢測算法
Input:Sp
Output: SegN(Sp),S(Sp),Lable(Sp)
Step1:取Sp集合中一待測語音樣本sp i;
Step2:初始化參數:段長SegLen和段移SegMov;
Step3:對spi等長分段,得集合Spij,設有m個小語音段;
Step4:使用D_M模型識別這m個小語音段,并合并連續相同類別的語音段,將合并后語音段存入集合S(spi)中,將對應類別標簽記錄在label(spi)中。并將所有類別分割點記錄在segNi中;
Step5:使用算法1對分割點集合進行再次確認得SegN(spi);
Step6:若Sp集合非空,執行Step1,否則執行Step7;
Step7:返回數據集合SegN(Sp),S(Sp),Lable(Sp)。
算法 3:基于距離與貝葉斯的功能性副語音自動檢測算法
Input:Sp
Output: SegN(Sp),S(Sp),Lable(Sp)
Step1:取Sp集合中一待測語音樣本sp i;
Step2:初始化參數:滑動窗長WindowLen和窗移WindowStep;
Step3: 將滑動窗在信號上滑動,計算相鄰窗距離,得到曲線L;計算L上局部最大點集合P={pi},i=1,2…,m以及對應于每個局部最大點的值dmax及其左右兩側的局部最小點值lmin,rmin,并計算L曲線的方差R;
Step4:逐個判定局部最大,如果滿足公式|dmax-lmin|>0.1*R|dmax-rmin|>0.1*R 則,分割點segi=pi; 得候選分割點集合SegNi={seg1,seg2,…,segm};
Step5: 使用文獻[10]CBICV算法對SegNi進行確認,得確認分割點集合SegNi;
Step6:利用算法1對SegNi中的分割點再次確定,得SegN(spi),并標記各分割語音段標簽及語音段集合Lable(Spi),S(Spi) ;
Step7:若Sp集合非空,執行Step1,否則執行Step8;
Step8:返回數據集合SegN(Sp),S(Sp),Lable(Sp)。
2實驗與分析
2.1 實驗數據
實驗數據來源于文獻[11]介紹的包含功能性副語音的語音情感數據庫(FPSED),其中包含了如下六種功能性副語音:笑聲、傷心的哭聲、質疑聲、叫喊聲、害怕的哭聲、嘆息聲,具體對應六種典型情感類別:高興、傷心、驚奇、生氣、害怕和厭惡。由5男6女現場錄制,錄制15個預料,以wav格式存儲,采用手工標注。為了確保實驗結果具有客觀性,實驗均基于非特定人相關的實驗數據集合。
2.2 實驗結果與分析
算法的性能評價指標包括準確率(precision)、查全率(recall rate)和綜合性能(F)。F值是準確率和查全率的調和平均數,介于0~1之間,真實反映了副語音自動檢測算法的綜合性能,而且F值越大表明算法的綜合性能越好。此外,為了驗證算法的實時性能,又將算法的時間效率作為衡定算法好壞的度量標準之一,測得的時間效率越高則實時性能越強,算法應用價值也就越高。
檢測模型D_M訓練:使用“一對一”SVM模型進行訓練,訓練的數據為純副語音集合和純語音集合。數據通過手工截取,分離后共得到360個純副語音訓練集合,以及360個語音訓練集合,采用基因頻率相關、能量相關、共振峰相關等的特征101維 [11],采用SFFS進行特征選擇。最終選擇特征為61維,SVM參數Gamma取0.01、C取8.5可得最佳模型。
實驗:在該實驗中首先驗證算法1的有效性,隨后將介紹功能性副語音自動檢測算法性能隨各個參數的變化情況。
2.2.1 實驗1 驗證算法1有效性
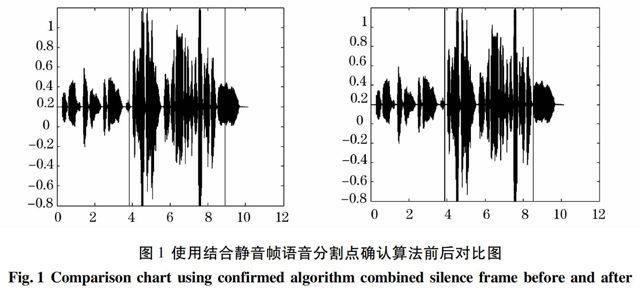
隨機抽取待測集合中的一個測試樣本,對其應用算法1:結合靜音幀分割點確認算法,圖1為應用算法1前后對比情況。從圖1中可以看出利用靜音段確認分割點在功能性副語音自動檢測中效果顯著。該算法可以保證語音片段的完整度,在其后的D_M分類識別中,優化了樣本片段的分類,從而有利于功能性副語音的自動檢測。算法中閾值T取40個采樣點。
2.2.2 實驗2 功能性副語音自動檢測算法性能隨各個參數的變化情況
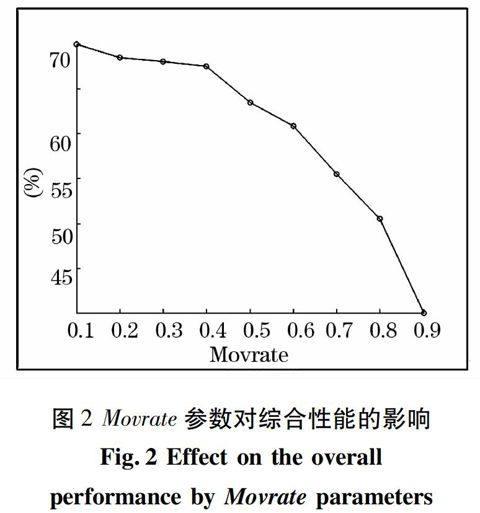
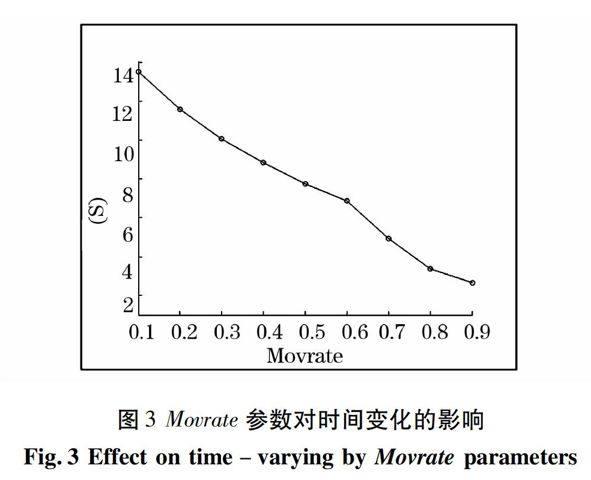
(1)算法2實驗與分析。 段長SegLen與SegMov是影響基于分類的副語音自動檢測算法性能的重要參數,SegLen參數影響D_M模型分類正確率,從而影響真實分割點檢出率;SegMov參數則能確保類別之間的轉換可以平滑過度。兩參數的關系可以表述如下:SegMov=Movrate*SegLen,其中,Movrate范圍為0-1,通過多次實驗確定SegLen取100幀較為合理。圖2和圖3分別給出了Movrate參數對算法綜合性能F、所用時間的影響情況。從圖2可以看出在Movrate取0.1時,即段移為段長的90%時,綜合性能達到最高。然而,從圖3卻可看出,時間消耗也將隨之增加。綜合考慮綜合性能及時間效率兩個重要指標,該算法可令Movrate=0.4。
(2) 算法3實驗與分析。首先給出算法3的相關參數配置:窗長為WindowLen取60個采樣點,窗移WindowStep為40個采樣點。在基于距離的過程中選取共振峰、能量、過零率等統計特征69維特征,在第二趟確認過程中使用12MFCC系數、短時過零率、短時能量等14維特征。輸入D_M檢測模型的語音段,提取同D_M相同的61維特征。
算法3為兩趟算法。第一趟檢測分割點時,當窗長WindowLen過短時虛假分割點增多,當窗長過長時真實分割點會漏檢;第二趟為BIC確認,有模型參數k值是重要影響參數,當k值過小時會增加虛假分割點,過大時會否定真實分割點,從而導致副語音檢測性能降低。在算法實驗中,首先確定WindowLen,因為第一趟是第二趟算法的前提。圖4給出了算法第一趟基于距離的分割算法綜合性能隨窗長WindowLen的變化情況。從圖4可以看出當WindowLen取100幀時其分割性能最好。圖5給出了在圖4的基礎上,固定WindowLen取100時,算法的綜合性能F值隨k值變化情況。從圖5可以看出,在k取5時算法綜合性能最佳,且經試驗測得檢測樣本平均時間為15.61s。
(3)兩種算法對比分析及討論。對比圖2和圖5可以發現,算法2的最高綜合性能為70%,而算法3的最高性能為65%,算法2較算法3高出5%。從時間效率上分析,算法3耗費時間項為:第一趟候選分割點確定+第二趟分割點確認+D_M分類。算法2耗費時間的過程有:預分段+D_M分類+連續段合并。經試驗測得,算法3平均每個樣本使用15.61s,算法2平均每個樣本所需時間為12.79s。算法2耗時更少。這是因為算法3為兩趟算法,因而更加耗時。從算法復雜度角度分析,對于一個問題規模為n的算法而言,整個算法的執行時間與基本操作重復執行的次數成正比。從算法2和算法3的檢測算法描述中可以得知,算法2的時間復雜度為O(m*n),其中m為各個樣本平均的分段數,而n為待測樣本總數。假設m<
3結束語
要想將功能副語音在情感領域的研究進行推廣應用,功能性副語音的自動檢出是前提。為了實現自動檢測,本文根據音頻分割算法提出了兩種具有代表性的功能性副語音自動檢測算法(算法2和算法3)。為了提高檢測精度,提出了結合靜音幀語音分割點確認算法(算法1)。并通過實驗驗證了算法1的有效性,同時也對比分析了算法2和算法3的性能。算法2在時間效率、檢測率和算法復雜度上均較算法3更為優越。但算法2也存在一定的不足:算法是基于模型的,要事先知道功能性副語音的類別,并且需要大量的訓練樣本,而算法3則不需要。本文接下來的工作:檢測到功能性副語音后,可以將功能副語音從語音段中分離出來,實現功能性副語音類別的進一步確定,且可進一步用于輔助傳統語音情感識別。
參考文獻:
[1]ISHI C T, ISHIGURO H, HAGITA N. Automatic extraction of paralinguistic information using prosodic features related to F0, duration and voice quality[J]. SCI, Speech Communication 50, 2008: 531-543.
[2]李春光. 副語音問題研究[D]. 哈爾濱:黑龍江大學, 2004.
[3]CHENG S S, WANG H M.A. Sequential metric to based audio segmentation method via the Bayesian information criterion [C]// Proceedings of Eurospeech, Geneva: University of Geneva, 2003:945-948.
[4]CHEN S S, GOPLALAKRISHNAN P. Speaker, environment and channel change detection and clustering via the Bayesian information criterion[C]// Proceedings of the DARPA workshop, Lansdowne,1988:127-132.
[5]CETTOLO M, VESCOVI M. Efficient audio segmentation algorithms based on the BIC [C]//Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Hong Kong :IEEE, 2003: 537-540.
[6]Cettolo M, Vescovi M, Rizzi R. Evaluation of BIC based algorithms for audio segmentation [J]. Computer Speech and Language, 2005, 19(2): 147-170.
[7]張一彬,周杰,邊肇祺,等. 一種基于內容的音頻流二級分割方法[J].計算機學報,2006,29(3): 457-465.
[8]嚴宇,吳功平,楊展,等.基于模型的巡線機器人無碰壁障方法研究[J].武漢大學學報(工學版),2013,46(2):261-265.
[9]鄭能恒,張亞磊,李霞. 基于模型在線更新和平滑處理的音樂分割算法.深圳大學學報(理工版),2011,28(3):271-275.
[10]于俊清,胡小強,孫凱.改進的音頻混合分割方法[J]. 計算機輔助設計與圖形學學報, 2010(7): 1174-1181.
[11]趙小蕾,毛啟容,詹永照. 融合功能性副語言的語音情感識別新方法[J].計算機科學與探索,2014,8(2):186-199.
[12]MAO QiRong, WANG XiaoJia, ZHAN YongZhao. Speech Emotion Recognition Method Based on Improved Decision Tree and layered feature selection[J]. International Journal of Humanoid Robotics, 2010:245-261.
