基于MapReduce的并行k—modes算法
2015-04-29 00:44:03郭濤丁祥武
智能計算機與應用 2015年1期
郭濤 丁祥武
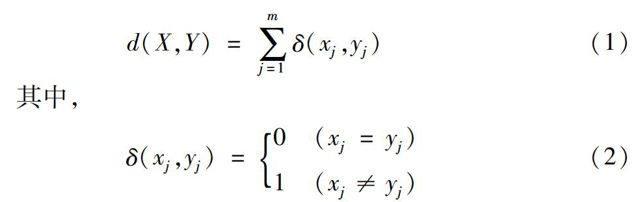

摘 要 k-modes是一種代表性的分類數據的聚類算法。首先對k-modes聚類算法的實現過程進行了改進:通過在分配數據對象到簇時更新這個簇中各個屬性項的次數,使得在遍歷一次全部數據對象就能計算出新的簇中心。為了使k-modes能夠處理大規模分類數據,在Hadoop平臺上用MapReduce并行計算模型實現了k-modes算法。實驗表明:在處理大量數據時,并行k-modes比串行k-modes極大地縮短了聚類時間,取得了較好的加速比。
關鍵詞 分類數據;k-modes;并行聚類;MapReduce
中圖分類號: TP312 文獻標志碼: A 文章編號:2095-2163(2015)01-
Abstract k-modes is a representative categorical attribute oriented clustering algorithm. First, improve the implement process of k-modes: when allocating categorical objects to clusters, update the number of items of each attribute in clusters. so that can compute the new modes of clusters after read the whole dataset once. In order to make k-modes capable for large-scale categorical data, implement k-modes on Hadoop use MapReduce parallel computing model. Experiments show that, parallel k-modes achieve good speedup when dealing with large-scale categorical data.
Key words categorical data; k-modes; parallel clustering; MapReduce
0引言
聚類,屬于無監督學習的范疇,是按照一定的相似性要求將數據對象集劃分成多個簇的過程,聚類結果即使得不同簇中的數據對象要盡可能相異,而同一簇中的數據對象則盡可能相似[1]。時下,分類數據[2]由非數值的屬性組成,且大規模、高維度的分類數據聚類也于近年來獲得了廣泛的關注。
Huang[3]在1998年提出的分類數據聚類算法k-modes[3]是對k-means[4]的擴展,其中采用0-1差異度來代替k-means算法中的距離,算法中差異度越小,就表示距離越小。一個樣本和一個聚類中心的差異度就是兩者中各個屬性不相同的個數,若不相同則記為“1”,統計結束所得“1”的個數總和就是某個樣本到某個聚類中心的差異度。各次比較分析后,該樣本將屬于差異度最小的聚類中心。
k-modes算法因其聚類簡單而得到大范圍應用,但是在如今這個大數據時代,并且隨著互聯網的發展,現實中的分類數據以海量規模存在并且正在呈現爆炸式增長,在單機上實現的串行k-modes已經無法在有效時間內取得聚類結果。Hadoop[5]作為一種流行的分布式系統架構,也因其所具備的高可擴展性等諸多優點而得到了可觀的發展及應用。為此,綜合以上探討研究,本文在Hadoop上基于并行編程模型MapReduce[6]實現了k-modes算法,并通過實驗比較了并行k-modes與串行k-modes的聚類速度。
0k-modes算法研究
k-modes算法是Huang[3]在k-means[4]算法的基礎上提出的,是對k-means算法的一種拓展。與k-means算法相比,k-modes主要表現了三點不同:(1)使用不同的相異度測試;(2)使用modes替換means;(3)使用一個基于頻率的方法更新modes。
0.1相異度測量
進一步地,W是一個的{0,1}矩陣,n表示集合X中對象的個數,k表示簇的個數,wil=1則表示第i個對象被劃分到第l個簇中。
對集合X的聚類的目標就是找到{Q1,Q2,…,Qk}使得目標函數E最小化。對應過程的基本步驟如下:
(1)隨機選擇k個對象作為初始的簇中心;
(2)應用匹配方法計算每個對象與簇中心的相異度,并將這個對象分配到與其相異度最小的簇中去。
(3)使用基于頻率的方法更新各簇的中心。
(4)重復(2)、(3)步驟,直至各簇不再變化。
1MapReduce研究
1.1MapReduce編程模型
MapReduce[6]是Google在2004年對外展示的其公司內部使用的分布式編程模型。Apache旗下的開源項目Hadoop[5]則對MapReduce框架進行了設計實現,同時又進一步實現了分布式的文件系統HDFS[7- 8]。
概括來說,MapReduce對外提供5個組件(InputFormat、Mapper、Partitioner、Reducer和OutputFormat)全部屬于回調接口。具體地,MapReduce編程模型主要由兩部分組成,分別為Map和Reduce。對二者的功能將做如下闡述
(1)自己定義的Map類要繼承系統的Mapper類,而Mapper類中提供的四個方法則依次為:setup、map、cleanup和run。其中,setup和cleanup用于管理Mapper生命周期中的資源,相應地setup是在完成Mapper構造,即將開始執行map動作前調用,cleanup則在所有的map動作完成后進行調用。另外,map可用于處理一次輸入的key/value對。而run方法執行了上面描述的過程,也就是調用setup,迭代所有的key/value對,再運行map,繼而調用cleanup。并且,run方法一般不需要重寫。map的輸出也是key/value,實際上會依據key值按照指定Partition規則分配到相應的Reduce進行處理。
(2)自己定義的Reduce類要繼承系統的Reducer類,Reducer類中提供的四個方法可逐一表示為:setup、reduce、cleanup和run。其中setup、cleanup和run方法的調用與Mapper類中的相似。而reduce方法即是將從map接收到的具有相同key值的value的集合進行一定處理。
1.2MapReduce的優勢
MapReduce屬于數據并行模型,同時又能實現一定程度的共享變量和消息傳遞,將其與此外的并行計算模型(如MPI[9]、OpenMP[10]等)相比,可知其具有如下優勢:
其一,通過MapReduce不僅能用于大規模數據處理,而且還能將很多繁瑣的細節隱藏起來,比如,自動并行化、負載均衡和災備管理等,這就極大地簡化了程序的開發;
其二,MapReduce的伸縮性非常好,每增加一臺服務器,就能將其計算能力接入到集群中,而過去的大多數分布式處理框架,在伸縮性方面都與MapReduce相差甚遠。
0并行k-modes算法設計
本文在不改變k-modes算法原理的基礎上,首先對k-modes聚類算法的實現過程實施了改進研發:通過在分配數據對象到簇時更新這個簇中各個屬性項的次數,使得僅是遍歷一次全部數據對象就能計算出新的簇中心。而后在Hadoop平臺上運用MapReduce并行計算模型實現了k-modes算法。改進后的并行k-modes就能夠對大規模的分類數據進行快速聚類。具體實現分為4個步驟,完整過程如下。
3.1 前期準備
從集合X中隨機選出k個對象作為初始的k個聚類簇的中心,對k個簇從0到k-1編號。定義FileInputFormat函數可根據Hadoop集群的計算能力將待聚類的數據對象集合X分為p個數據塊,從而產生p個Map任務并行執行。并且,每個數據對象均是用一行文本的形式來存儲。過程中,用key表示數據對象所屬的簇,value表示數據對象的信息。
3.2 分配對象
每個Map任務的setup函數均從HDFS中初始化讀取k個聚類簇的中心,并在map函數中依次讀取相應塊內的每個數據對象,其格式為<簇編號,數據對象>信息,計算這個對象與各個簇中心的差異度,再將其分配到差異度最小的簇中,同時進一步更新這個簇中屬性項出現的次數。Map函數的輸出的格式為<新的簇編號,數據對象>。而在cleanup函數中,將k個簇的信息寫回到HDFS,不同的Map任務寫回的簇信息可用Map任務的編號加以區分。
3.3 更新簇中心
將3.2中p個Map寫回到HDFS中的簇信息分別讀取出來,并按照對應的簇編號進行合并。在合并后的簇信息的每個簇中選出對應屬性項頻率最大的屬性作為當前簇的新中心的屬性項,再將新的簇中心的信息寫回到HDFS。
計算新的簇中心與原來簇中心的差異度,如果差異度小于一定閾值(由用戶設定),則聚類過程完成,將執行下一步、即3.4,否則回到3.2繼續執行。
3.4 輸出聚類結果
定義一個有p個Map任務k個Reduce任務的MapReduce程序對3.2的生成的p個數據塊進行處理,每個Map讀取一個數據塊,并按照key值(也是簇編號)將每個數據對象分配至對應的Reduce來處理,Reduce處理完成后將會在HDFS上生成k個文件,并且每個文件中均包含一個簇的全部數據對象。
1實驗與分析
實驗使用Hadoop集群對并行k-modes算法進行了測試,而且又與單機上實現的串行k-modes的執行時間進行了比較。
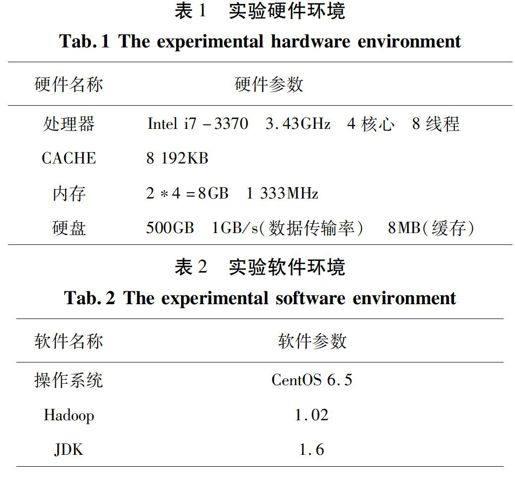
Hadoop集群中共有9臺機器,一臺作為Master,其余8臺作為Slave。每臺機器的硬軟件配置如表 1和表 2所示。
實驗采用美國人口普查數據集(US Census Data Set)(http://dataferrett.census.gov),其中包含1990年美國人口普查公共使用數據樣本1%的數據。集合中共有數據記錄條數為2 458 285,大小345M,包括祖先、族群、拉美族裔來源、行業職業、語言、出生地等68個屬性。按照此數據格式,再隨機生成10G的實驗數據,通過逐漸增加數據量,研究所得的并行k-modes和串行k-modes的處理時間對比則如圖 1所示。
實驗顯示,當處理小量數據時,Hadoop集群并未表現出明顯優勢;但是當數據量較大時,并行k-modes相比串行k-modes的處理時間則大大縮短,因而取得了較好的加速比。
2結束語
本文對k-modes聚類算法的實現過程展開了改進研究,同時為了使k-modes能夠處理大規模分類數據,又在Hadoop平臺上利用MapReduce并行計算模型實現了k-modes算法。實驗表明:在處理大量數據時,并行k-modes與串行k-modes相比,極大地縮短了聚類時間,并且取得了較好的加速比。
本文對k-modes的并行實現程序已經發布到開源社區(https://github.com/j2cms/dog)。
參考文獻
[1] Han J, Kamber M, Pei J. Data Mining: Concepts and Techniques[M]. Third Edition. Burlington: Morgan kaufmann, 2011.
[2] Agresti A. Categorical data analysis[M]. Hoboken: John Wiley & Sons, 2014.
[3] HUANG Z. A fast clustering algorithm to cluster very large categorical data sets in data mining[C]//Tucson: DMKD, 1997: 281--297.
[4] MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]//Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, Oakland: University of California Press, 1967: 281-297.
[5] SHVACHKO K, KUANG H, RADIA S, et al. The hadoop distributed file system[C]//Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium on, Incline Villiage: IEEE, 2010: 1-10.
[6] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[7] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google file system[C]//ACM SIGOPS Operating Systems Review, New York: ACM, 2003: 29-43.
[8] CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: A distributed storage system for structured data[J]. ACM Transactions on Computer Systems (TOCS), 2008, 26(2): 4.
[9] Pacheco P S. Parallel programming with MPI[M]. Burlington: Morgan kaufmann, 1997.
[10] DAGUM L, MENON R. OpenMP: an industry standard API for shared-memory programming[J]. Computational Science & Engineering, IEEE, 1998, 5(1): 46-55.
