《紅樓夢》中社會權勢關系的提取及網絡構建
2015-04-21 10:40:58胡亦旻胡俊峰
中文信息學報 2015年5期
關鍵詞:文本
陳 蕾,胡亦旻,艾 葦,胡俊峰,2
(1. 北京大學 信息科學與技術學院,北京 100871;2. 計算語言學教育部重點實驗室(北京大學),北京 100871)
?
《紅樓夢》中社會權勢關系的提取及網絡構建
陳 蕾1,胡亦旻1,艾 葦1,胡俊峰1,2
(1. 北京大學 信息科學與技術學院,北京 100871;2. 計算語言學教育部重點實驗室(北京大學),北京 100871)
社會地位與權勢的研究一直是社會語言學領域的一個熱點話題。該文借助數據挖掘中的關系提取方案雪球算法(SnowballAlgorithm),實現了《紅樓夢》文本中候選的特征語言模式(pattern)和人物關系對之間的相互定位與賦權,對小說中頻繁同現的人物對之間的社會等級關系進行挖掘,以此建立了能反映人物等級關系的有向加權人際關系網絡。進一步應用最小樹形圖算法,生成了涵蓋192個《紅樓夢》主要人物的單向聯通的樹狀社會關系圖。通過這種方法生成的社會關系圖不但能有效反映人際交往親密度與社區影響力,同時還透視了人與人之間的社會等級差異。相較于單純基于人際交往親密程度的無向關系網絡,能更加客觀地表達出社會交往中人際關系網絡的真實圖景。
關系提取;權勢關系;社會關系網絡;最小樹形圖
1 前言
社會語言學研究作為一門新興學科,其主題圍繞著語言和社會之間的相互作用展開,社會權勢關系和不同社會階層的語言使用是其中常見的研究方向之一[1]。不同身份地位的人群所使用的語言有特異性,特殊的用語往往也會成為特定社會關系的語言標志。據此,如果收集人物間兩兩互動的語料,并提取出一些反映相對權勢關系的特征詞語,理論上就可以通過這些特征詞語在群體中評估人物地位高低,并定位出具有權勢差距的一對對個體。本文旨在通過文本提取信息,構建《紅樓夢》一書中微型社會的權勢網絡。
權勢是一種等級化、易于度量的單向社會關系。關于權勢的社會語言學研究可以追溯到20世紀60年代,美國語言學家William Labov在1966年出版的TheSocialStratificationofEnglishinNewYorkCity一書中報道了用“隱蔽式錄音”的方法研究紐約市百貨公司職員口語中對(r)音的著重程度和其社會地位之間的關系[2],發現社會地位越高的職員越傾向于將(r)音發出。1972年,英國語言學家通過采集英國諾里奇市方言的語音資料,得出與性別和潛在聲望相關的音位和語音變素[3]。早期的社會心理學家也曾經嘗試通過分析歐洲語言中權勢與同等關系的代詞的使用,揭示在歷史進程中不同社會階級之間的人際關系演變[4],探討了社會地位高的人自稱和他稱方式從明顯與社會地位低的人用語方式分開,到逐漸也用權勢低者的用語進行自稱和他稱的變化。社會語言學在中國發展起來后,國內相關研究也逐漸發展起來。2009年胡美馨等通過分析前秦到晚清的文本,揭示女性身份認同的話語從強調男女差異(如在文學作品中“妳”和“你”的性別區分,暗示女性社會地位較低)逐漸過渡至男女“平等”(如逐漸趨向于“你”的統一化使用,代表女性社會地位趨于平等)的變化,探討了女性社會地位的變遷[5]。2013年李佳靜等通過對杭州市“老板娘”一稱呼語的調查,認為“老板娘”一用語包含上對下的社會權勢關系,而這種用語的逐漸減少和廢棄,也從另一方面反映出女性地位的提升[6]。傳統的社會語言學研究方法能夠以專業角度結合社會歷史發展進程和語言元素的變化,然而往往也需要投入大量時間和人力進行采樣。本研究中,我們采用了程序篩選結合人工監督過程,有效提高研究效率,同時更多從文本和數據本身入手,研究角度有別于前述“由假設推動的(hypotheses driven)”的研究。
近年來,隨著計算科學的介入,基于文本的權勢研究中出現了更多機器學習和統計模型的方法。大多數研究針對易于根據團隊角色明確劃分強弱勢團體的情況。如2012年Danescu Niculescu Mizil等[7]于World Wide Web Conference發表文章,分別采集維基百科中管理員、管理員申請者、非管理員的網絡討論記錄和美國最高法院的辯護記錄,根據不同群體間互動時使用與對方相同語言模式的頻率差異,分析“附和”(coordination)行為與權勢的關系。同年,Gilbert[8]使用開源的Enron公司內部電子信件,根據職位建立權勢層級結構,并據此提取不同權勢階級在詞匯選用上的不同偏好。2014年Agarwal等[9]使用相同語料,說明交談中被提到次數越多的人物,社會地位就越高的現象。以上研究與前文提到的傳統社會語言學研究思路較為相似,都是在已知個體或群體的社會地位的基礎上,尋找分布特點對應權勢差異的語言因素,如詞語、詞性、語言習慣等。另外一些研究則采用逆向思維,通過少數已知權勢關系,提取特征語素,再用這些特征語素建立分類器,進行未知權勢關系的預測。如2011年Bramsen[10]等發表的研究,同樣利用Enron公司Email文本資料,將雇員間兩兩通郵的信件分為訓練集和測試集,并通過在訓練集中統計N-gram頻率,篩選特征,借助支持向量機模型(Support Vector Machine)預測寄信者相對于收信人的地位差異。本文中,我們希望能夠通過地位關系和語言特征之間的互證從而擴增已知信息,這一點與前人研究相似。然而,我們同時也嘗試探索結構信息,在《紅樓夢》的虛擬社會體系中構建權勢關系網絡,一方面修正兩人交互的偶然性偏差,獲得人物之間社會地位關系的全局最優解;另一方面,清晰闡述小說的社會關系和權勢結構。這一點由于應用文本的特殊性,則是在前述研究中鮮少出現的。
本文選用《紅樓夢》作為研究語料主要基于以下三點考慮。首先,《紅樓夢》中出場人物數量多,人物間階級關系相對穩定且鮮明;其次,針對該語料的研究能夠比較容易地通過人們對小說內容的理解進行驗證與評測;最后,為該項研究今后在更加廣泛的領域開展研究奠定可靠的基礎。
2 實驗方法
2.1 實驗背景介紹和方法概述
本實驗采用已分詞的《紅樓夢》小說文本和包括了各人物所有稱謂的紅樓夢人名文本,在預處理階段提取兩個人名同現的語句(如“惜春 又 謝 了 王夫人”)。目標是從出現在人名之間的詞語中提取模式,并用模式詞語預測人物對間權勢關系。由于小說文本容量有限,相當一部分人物對之間的交互頻率不高,以前研究中普遍是基于統計的方法使用分類器系統,對于樣本量小的情況不甚適用。在此處我們引入的雪球系統本質上采用了HITS算法,能夠通過不斷迭代,強化最具優勢的特征,過濾掉一些偶發的干擾特征。在關系提取階段,會盡量保留人物對之間雙向的可能關系,最后通過生成有向圖的單向連通最小支撐樹的方案來削減偶然交互造成的異常值。
主要方法部分,本文先借鑒經典雪球系統,由權勢人名對提取特征模式詞語。后用同義詞林擴充,經HITS系統篩選后,對得分低的詞語進行去除,保留質量較高的特征模式詞語。接下來對上述特征詞在文中進行定位,并據此計算每一對存在交互的人物之間的權勢值。最后,用最小樹形圖算法生成整個紅樓夢社區中可定位人物組成的有向無環權勢關系圖。
2.2 經典雪球系統對研究有向關系的啟發
1999年哥倫比亞大學的Agichtein和Gravano等發表了一個用于關系提取的經典算法,命名為“雪球”(Snowball)系統[11]。雪球系統及其各類變體多應用于開放系統中實體提取,如互聯網中的問題發掘等。其基于“關系”(relationships)的篩選機制,對本文研究小說文本這一封閉集合中社會關系結構具有深刻啟發。研究者們觀察到,在《紅樓夢》中具有權勢差的個體之間,普遍存在不少重復出現的“相處模式”,如權勢高的一方對權勢低的一方常常有“命令”、“驅使”等行為[12]:
“原來寶玉心里有件私事,于頭一日就吩咐茗煙……”
“寶玉便命晴雯來吩咐道……”
“黛玉不時遣雪雁來探消息……”
而權勢低的一方對權勢高的一方常常有“伴”、“從”等行為:
“惜春又謝了王夫人。”
“這里紫鵑扶著黛玉躺在床上……”
“這里雪雁正在屋里伴著黛玉 ……”
這些在文本中反復出現的特征詞匯和經典雪球系統中的“模式”非常相似,而具有權勢差的一對人物可看做主體。因此,在最初的嘗試中,本文作者嘗試了通過經典雪球系統進行實體與模式的迭代提取,后考慮到文學作品的修辭特點和人際關系的信息復雜性,在傳統算法的思路基礎上做出以下改進。
(1) 改用單個詞語取代詞向量作為模式。
(2) 使用HITS算法對候選的語言模式和關系實體進行加權評估。
(3) 考慮到封閉系統的特點,減少迭代次數、并就每一步擴展和提取采用不同的策略(圖1)。
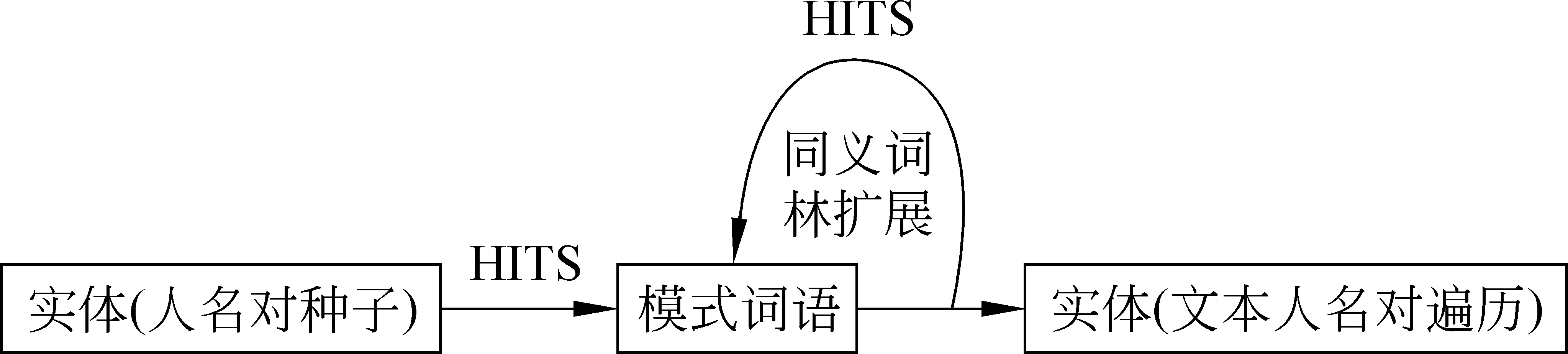
圖 1 改進后的實體和模式提取流程
(4) 原始雪球系統中,辨別的是“存在目標關系的實體”和“不存在目標關系的實體”。而在我們的假設中,每對人物之間總是存在一定的權勢差,只是實體之間社會地位相差的程度有異,因此我們根據模式對文中所有實體共現場景進行遍歷,最后得出的并非一個區分系統,而是一個N×N打分矩陣,儲存每一個人相對于其他所有人的權勢分值。
(5) 根據打分矩陣確定主要人物間權勢關系,初步決定圖中大多數邊的方向。
(6) 引入有向圖的最小生成樹算法,以交互頻率為邊權,生成主要人物間社會權勢關系的有向加權無環圖。
2.3 用種子實體提取模式詞語
首先,通過文本閱讀和資料分析,我們列出100對存在明確地位差異的人物對作為種子實體,其中主要以“主-仆”(如“黛玉-紫鵑”、“寶玉-襲人”)、“長-幼”(如“賈母-鳳姐”、“賈政-寶玉”)關系為主。按照上位者所處的位置順序分為“上對下”和“下對上”兩組種子包。
然后,提取原文中所有在種子之間出現的詞語,統計其在不同種子之間出現的頻率,并根據頻率(經過詞頻修正)各篩選出前100個“上對下”和“下對上”的模式詞語。
2.4 引入HITS算法進行權威度評估
HITS (Hyperlink-Induced Topic Search) 算法是1999年由康奈爾大學的Jon Kleinberg提出的一種基于“樞紐值(hubs)”和“權威值(authorities)”進行網頁質量評價的算法思想。本文引入此方法實現對實體和模式的質量控制:假設人物對主要具備“權威性”,模式詞語主要具備“樞紐性”——即被具有高樞紐性的模式所命中的人物對,具有更為顯著的地位差異;而存在于權勢差更顯著的人物之間的模式詞語, 能更有效地區分人物之間的地位差異。最終根據迭代至基本穩定的分值,將“上對下”和“下對上”的模式詞語進行排序。
2.5 通過同義詞詞林擴充模式詞語范圍
考慮到意義相近的詞語在揭示權勢關系的作用上有最大概率和原模式詞語相同,我們運用哈爾濱工業大學信息檢索研究室《同義詞詞林》(擴展版)對模式詞語列表進行擴增。擴展后,分別得到“上對下”模式詞語1 494個和“下對上”模式詞語1 214個。然而,由于漢語詞匯的一詞多義現象,其中很多結果可信度較低。因此,對各1 000余個詞語再次使用HITS算法評估其質量,將小于底限分數(0.000 1)的結果去掉,并將“上對下”和“下對上”中都出現的重復詞匯去掉,最終得到“上對下”模式詞語112個,“下對上”模式詞語124個,作為對2.2中所得詞語的修正和擴充。
2.6 人物關系加權有向無環圖的生成
將模式詞語作為地位差距的標志,遍歷文中所有人名對,對其交互頻率和出現權勢差異的次數進行統計,得出一個交互頻率矩陣和雙向的權勢矩陣。以兩個矩陣為數據基礎,結合最小樹形圖算法,我們希望得到人物關系的加權有向無環圖,將兩點之間交互頻率的對數值賦值為兩個點之間的交互邊權,作為親疏程度的衡量。親疏程度在某種程度上反映了社會關系中子群落的信息,我們使用這種信息對一些偶然交互造成的誤判進行校正。例如,彩屏在權勢矩陣中體現出比賈母更高的地位,而兩人在文中僅有一次交互,數據可信性極低,故用對數計算剔除是合理的,同時對于交互次數多的兩人,其邊權值自然就大,體現出兩者關系的緊密。
接下來,再根據權勢矩陣,考察圖中每對人物之間的權勢方向,以明確上述帶權圖邊的指向。首先計算出所有人名對的權勢差的絕對值的平均值,將其作為篩選的閾值。當權勢差高于閾值,保留權勢更大的方向為最終無環圖中兩結點間方向,若小于等于閾值,則暫時保留結點間的雙向關系,若認為之間的相對權勢并不明顯,但對于權勢值較高的方向,增加10%的邊權,以保證在之后生成樹的過程中實際存在的微弱地位優勢不會被過強的交互頻率所逆轉。
在此圖的基礎上,運行最小樹形圖算法最終得到確定的方向。使用最小樹形圖的目的在于得到全局邊權的最優的情況,并依此得到每個人名對確定的單一權勢方向。具體來說,對于我們之前得到的有向帶權的圖,假設一個“權勢至高者”作為根節點(本文中假設賈母在文中的地位最高),從根出發,選擇其伸出的邊權最大的邊來擴展下一個點,并從下一個點重復這一擴展方法,直至所有的點連入圖中,從而得到一個較優解。考察每一個點的入邊,如果有比其值更大的未選邊,就要考慮替換,由于圖中不可成環,故有兩種情況:
(1) 如果待替換的邊與原來的邊共圈,替換不產生環,則直接替換(圖2a)。
(2) 如果替換邊與其他邊成環,先替換掉原邊,再考慮打開所成的環。在從所有連到環上某點的未選邊中選擇與該點原入邊邊權差最小的替換環中邊,若還有環則放棄,選差第二小的反復進行直至無環(圖2b)。

圖 2 最小樹形圖算法思路圖解粗箭頭代表待替換邊
通過這樣的算法,我們就成功得到了邊權和最大《紅樓夢》人物關系有向無環圖,即最小樹形圖[13]。
3 實驗結果
3.1 模式詞匯提取
列舉“上對下”、“下對上”兩種關系中最終權重較高的模式詞匯(圖3、表1、表2),可看出,在“上對下”關系中,模式詞匯之間權重差距更為明顯;而“下對上”關系中,模式詞匯的權重差異則較為緩和。根據得分最高的模式詞匯,可推測其中社會地位相對較高的人對社會地位較低的人在“命”一詞的使用上有很高的頻率,且一旦這一語素出現于兩個人之間,二者社會地位懸殊的事實就很容易被確定下來。而從“下對上”的關系詞中,直觀上應該更為顯著的如“陪”、“扶”等詞匯實際上得分卻并不如“到”、“睡”一
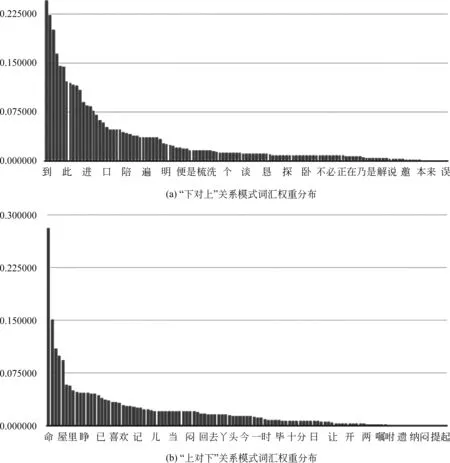
圖 3 關系模式詞匯權重分布示意圖
類從詞義本身偏向中性的詞匯那么高。推測出現這種差異的原因是,在《紅樓夢》這一作品中對于地位高者的威嚴和權勢的形象塑造著墨更重(致使相似命令式詞匯出現頻繁),而對于丫鬟和小輩這樣的地位相對較低者,則一來更少作為交際中的主動者(模式詞匯描述的更多是回應和反應的行動),二來《紅樓夢》中對他們的描寫也更注重人物的獨特個性(使得如同“命”一樣千遍一律的詞匯很少出現)。
從模式詞匯的提取結果上看,我們并不能下結論說每一個詞匯都能夠獨自代表一種關系,甚至其中也有可能出現一些由于主被動關系無法區分而混淆的結果。但是從另一方面說,在對文本進行深入研究之前,也無法根據對詞義的直觀理解來排除結果。因此我們選擇在關系提取這一步中驗證這些模式詞匯對權勢關系的預測準確度,來判斷模式詞匯對文中社會地位差異場景的敏感性。

表1 “上對下”關系模式詞匯舉例

表2 “下對上”關系模式詞匯舉例
3.2 《紅樓夢》權勢關系人物對的提取
對于主要的192個人物之間的社會地位差異,我們使用模式詞語在其間出現的頻率計算,對于每兩個人之間出現雙向有權邊的情況,保留得分更高的一條,作為權勢降低的方向。之后,用已知158對具有相對權勢差異的人物對,進行準確度測試。具體地,對于二者能夠通過一條邊直接連通的人物對,觀察連通方向是否與假設方向相同,若相同則記為“正確”,反之記為“不正確”;對于二者不能夠通過一條邊直接連通的人物對,在只能往權勢降低方向行進的前提下,觀察從假設中地位高的一方是否能夠間接連通地位低的一方,以及地位低的一方是否能夠連通地位高的一方。若前一種情況通暢而后一種情況無法到達,記為“正確”,反之記為“不正確”,若兩種情況都可以連通,則記為“不定”。最終,我們得到92個正確結果,23個不正確結果,以及43個不定結果。
3.3 《紅樓夢》社會關系網絡模型初探
原始的有向關系網絡存在相當數量的環路,這反映了人際交往過程中地位關系的復雜性。因此存在43對人物之間權勢方向無法確定。例如,湘云和岫煙、湘云和鴛鴦、鳳姐和探春、鳳姐和寶釵等。因此,直接觀察該有向關系網絡中人物間等級化關系和社區結構劃分并不清晰(圖4a)。
考慮到個人之間的關系在實際交往中可能會有偶然性,即跨越等級的表現(如寶玉和晴雯之間常常出現僭越主仆關系的互動),但從社群整體來看等級關系則是相對穩定的。因此,我們利用最小樹形圖算法將有向關系網絡中的次要的邊去除,形成一個整體上擁有最強單向依賴關系的樹,由此得到以數個主要人物為中心的多中心輻射狀樹形圖(圖4b、圖4c)。考慮到賈母在紅樓夢中的地位,我們這里選取賈母作為樹根,默認沒有權勢地位明顯高于賈母的人。大多數(134個)結 點 都只有一條關聯的邊(葉子結點),而只有少數結點(8個)被多余五條邊連接,成為每一簇小社群的中心,通常都是《紅樓夢》中社會地位較高的人物(表3)。其中,賈寶玉的主角效應非常顯著,其他人物社會關系也能在圖中很好地體現出來。

圖 4 《紅樓夢》192個主要人物網絡模型(未示權勢方向)


圖 4(續)

表3 樹形網絡中出入邊總數大于5的人物
可以預期,由于人物間交互信息繁雜,不怎么打交道的兩人之間,容易在少數往來中偶然命中特征詞匯,造成原始網絡中一些誤保留的邊。通過生成最小樹形圖刪除一些邊后,這種情況有所改善,使得社會關系結構能夠更好地體現出來,如圖5所示情況。在原圖中,除去權重顯著低于反向邊權的邊后,紫鵑相連的邊共有30條,而雪雁所連的邊有12條。在最小樹形圖算法處理下, 許多邊由于交互頻率過低而被消除,如雪雁和紫鵑與賈母、寶玉之間的邊。然而,這并不代表我們放棄了對這些關系的判定,雖然沒有被直接相連,我們依然可以從樹形圖中得到紫鵑、雪雁和賈母、寶玉等人之間的關系。從而很大程度上去除了冗雜交互信息,促進有向社交網絡的可視化。事實上,這樣的樹狀網絡直觀地反應出了人物的行政權勢關系。最小樹形圖算法不僅刪除了許多可疑的邊,還刪除了非直接隸屬(聯系不夠緊密)關系的邊,這樣留下的邊往往連接的是有直接上下級關系的兩人,有利于我們對整個網絡的權勢脈絡有更加清晰、正確的認識。同時,對于文本中沒有直接產生交互關系的個體,只要在樹上存在直接連通的通路,就可以預測其在《紅樓夢》中的相對權勢關系。舉例來說,墨雨很少與其他人物有交集,但其處于紫鵑的下級,從而我們可以合理地推斷,與其在同一路徑且位于上層的賈寶玉對于墨雨有社會地位上的優勢。也就是說,即使對于非直接隸屬的關系,我們通過權勢的可傳遞性以及樹的特點,能夠做出合理的推斷。

圖5 樹形網絡局部特寫(寶玉——黛玉——紫鵑——雪雁)
當然,最小樹形圖也有其局限性,對于數據稀少的個體,可能由于全局最優的需要而生成我們意料之外的邊,例如,原始關系數據極少的北靜郡王和賈元春,就接入了寶玉的下方,并不太符合實際的關系。同樣地,有些與他人交集較少的底層的丫鬟或奴仆,也可能作為個例接入并非其主人的父節點。根據觀察,若不考慮一些個體由于數據不足而產生的問題,樹形圖整體上以很高的準確度反應《紅樓夢》中的權力制約關系。
4 結語
本研究嘗試了在文本語料中提取人物社會階層關系,建立了反映社會階層關系的紅樓夢人際關系網。實驗表明,通過該有向關系網做出的最小樹形圖能較為準確地反映《紅樓夢》中192個主要人物之間的社群結構,對多數人物對之間的社會地位差異的預測結果也比較可靠。
相對于以前的研究,此方法的特點有三個;其一,適用于文學作品一類的小文本,人物關系復雜,而交互信息有限的情況;其二,相較于以往的社區劃分算法,在加入了權勢依賴關系是單向且無環路的約束后,實現了整體權勢結構的最優。能有效地消除個別人物角色之間偶然發生的階層越位的互動帶來的干擾,因此在社會地位的判定上更為精細。由于階層關系并非可以單純依據人物之間的兩兩互動來確定,因此在本研究中我們沒有使用常見的分類器的方案,一開始就盡可能地保留了人物之間所有的雙向關系,然后再局部對比和全局考量過程中逐漸選擇性刪除邊,最后達到了好的效果;其三,所得到的權勢關系不再局限于有交互事件發生的個體之間,而是可以借助連接其他節點形成通路來間接比較,因此能有很好的預測性。在權勢網絡中的兩個人物只要有通路,就能唯一判定相互之間的權勢關系,而并不要求在文本中兩個人有實際的互動。
在人際關系網絡研究中加入等級關系更真實地還原了社會網絡中人物之間的社會交往形態。可以認為本文的方法在研究社群劃分、社會關系變遷和社會結構分析中都存在更大的應用潛力。
同時,本研究仍然存在一些局限性。
(1) 可應用語料的有限性。如《紅樓夢》這樣出場人物眾多、存在明確而復雜的人物關系、等級森嚴的社會制度的小說非常少。因此,在后續的探索中,我們考慮嘗試在網絡論壇的社區環境下考察此方法的有效性,并同時嘗試尋找其他可用語料和應用場景。
(2) 由于文學作品側重于主角的描寫,眾多配角的出場多是圍繞主角進行,而現實生活中,這樣以一人為核心、其他人之間的關系都很疏離的情況是不太常見的。且由于最小生成樹的算法特征,無法連入劇情主干的一些成獨立“小圈子”的節點們在建樹過程中被逐漸刪去,邊緣化群體之間的關系無法被觀測到。因此,若考慮將本文方法應用于現實生活中的網絡社區,尚且需要做更多的嘗試和調整。
(3) 本文以詞語提取而非詞包提取為主,并沒有特別考慮被動式。分辨“上對下”和“下對上”關系主要依靠兩個人物在文本中出現的順序。當被動式一類可能造成詞義反轉的情況出現時,詞語在兩種關系方向中的權重都會降低(主動式和被動式的權重互相抵消)。這就導致本研究在模式詞語的提取上始終比較保守。在未來大文本的工作中,可以考慮進一步使用詞袋模型或更復雜的語言元素代替單獨詞組,將被動式等可能造成詞義削弱或反轉的因素納入模型中。而在現有的小文本情況下使用詞袋模型等可能會導致每個候選模式的頻率都比較低。
5 致謝
感謝北京大學信息科學與技術學院張夢楠、苗睿同學,地球空間學院李豐翔同學為本文研究工作提供幫助和支持。
[1] 趙蓉暉編. 社會語言學[M]. 上海:上海外語教育出版社,2004.
[2] Labov W. The social stratification of English in New York city[M]. Cambridge University Press, 2006.
[3] 祝畹瑾編. 社會語言學譯文集[M]. 北京:北京大學出版社,1985.
[4] 祝畹瑾編. 社會語言學譯文集[M]. 北京:北京大學出版社,1985.
[5] 胡美馨,吳宗杰. 從先秦與晚清文本看女性身份的話語變遷——一種譜系學的跨文化分析[J]. 中國社會語言學,2009,2(13): 141-151.
[6] 李佳靜,孫德平. 杭州市稱呼語"老板娘"調查[J]. 中國社會語言學,2013,1(20): 27-37.
[7] Danescu-Niculescu-Mizil C, Lee L, Pang B, et al. Echoes of power: Language effects and power differences in social interaction[C]//Proceedings of the 21st international conference on World Wide Web. ACM, 2012: 699-708.
[8] Gilbert E. Phrases that signal workplace hierarchy[C]//Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work. ACM, 2012: 1037-1046.
[9] Agarwal A, Omuya A, Zhang J, et al. Enron Corporation: You're the Boss if People Get Mentioned to You[C]//Proceedings of the 2014 International Conference on Social Computing. ACM, 2014: 2.
[10] Bramsen P, Escobar-Molano M, Patel A, et al. Extracting social power relationships from natural language[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011: 773-782.
[11] Agichtein E, Gravano L. Snowball: Extracting relations from large plain-text collections[C]//Proceedings of the fifth ACM conference on Digital libraries. ACM, 2000: 85-94.
[12] 曹雪芹,高鶚. 紅樓夢[M]. 北京:人民文學出版社,2000.
[13] Kleinberg J M. Hubs, authorities, and communities[J]. ACM Computing Surveys (CSUR), 1999, 31(4es): 5.
Extraction of Power Relationship and Its Corresponding Social Network inTheStoryofStone
CHEN Lei1, HU Yimin1,AI Wei1, HU Junfeng1,2
(1. School of Information Science and Engineering, Peking University, Beijing 100871,China;2. Key Laboratory of Computational Linguistics (Peking University), Ministry of Edncation, Beijing 100871,China)
The study of social status has always been a hot spot in sociolinguistics. In this study, we applied Snowball Algorithm and HITS Algorithm to discover the social relationships in the Chinese novelTheStoryoftheStone. By locating and weighting “Patterns” and “Tuples” iteratively, we construct a relationship network with social class information. Finally, we generate a min-cost arborescence of the social relationships of 192 main characters inTheStoryoftheStonewith Chu-Liu/Edmonds' algorithm. The generated social relationship reflects not only the intimacy and social influences, but also the hierarchical inequality of people. We regard it as a more objective and authentic reflection of social relationship network in class society.
relationship extraction; power relationships; social network analysis; min-cost arborescence

陳蕾(1993—),美國圣路易斯華盛頓大學博士研究生,主要研究領域為生物信息學和統計遺傳學。E-mail:1100012154@pku.edu.cn胡亦旻(1994—),本科生,主要研究領域為計算機科學與技術。E-mail:1300011764@pku.edu.cn艾葦(1990—),美國密歇根大學博士研究生,主要研究領域為數據挖掘與推薦系統。E-mail:aiwei@pku.edu.cn
1003-0077(2015)05-0185-09
2015-06-26 定稿日期: 2015-09-10
國家自然科學基金(M1321005);國家自然科學基金(61472017)
TP
A
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
