基于分類的協同過濾圖書推薦系統應用研究
2015-04-16 01:30:10陳澤波
電腦與電信 2015年9期
陳澤波
(廣州工程技術職業學院信息工程系,廣東 廣州 510075)
1 引言
協同過濾推薦系統是電子商務網站普遍運用的技術,主要目的是為了吸引顧客增加銷售額。將協同過濾應用于圖書館日常管理工作中,目的是希望通過推薦系統推薦給讀者其感興趣的圖書和文獻,幫助讀者更好地使用圖書館資源,同時也能提高圖書館館藏資源的利用率。在原有研究的基礎上提出一種改進的推薦算法——基于分類的協同過濾算法,解決了新讀者的初始評分問題,根據讀者的借閱歷史對讀者進行分類,結合相關影響因子的分析,改進讀者相似度的計算公式,可以有效解決協同過濾推薦系統存在的冷啟動及系統擴展性問題。
2 協同過濾推薦系統
2.1 協同過濾推薦系統的原理
協同過濾系統(Collaborative Filtering)也有學者稱為“協同推薦系統(Collaborative Recommendation)”。系統假設具有相似興趣特征的用戶將會采用相似的行為。系統的原理是通過用戶的注冊信息、歷史記錄來提取用戶的行為特征,接著根據這些特征在用戶群中尋找相似鄰居,最后依據相似鄰居的借閱行為向該用戶進行推薦。協同過濾系統是最早,也是目前得到最廣泛應用的推薦系統。
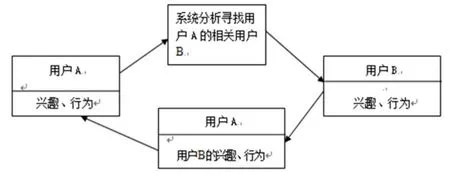
圖1 協同推薦原理示意圖
在協同過濾推薦系統中,用戶對產品的評分通過計算近鄰用戶對其評分而得到。對于近鄰用戶的計算,協同過濾推薦系統采用了很多方法來計算。這些算法中,大都基于用戶對共同喜愛產品的評價。其中,最常用的方法是夾角余弦方法和Person相關性。根據算法是否需要學習已有數據,可以分為基于近鄰和基于模型兩類算法。
基于近鄰的算法利用用戶之前的評分數據,對用戶未評價的對象給出一個平均評分。基于模型的算法利用收集用戶的打分數據進行學習并構建用戶行為模型,然后對某個產品進行預測打分。
2.2 協同過濾推薦系統的優缺點
協同過濾推薦系統的優點是不依賴于推薦對象本身的內容,能夠推薦多種介質,甚至包括虛擬對象。同時,協同過濾推薦的個性符合度較高,而且還可以幫助用戶發現新的興趣。缺點是冷啟動問題,即對于新產品、新用戶,系統得不到產品所獲得的評價,也得不到新用戶的興趣愛好、行為記錄,因此新產品得不到推薦,新用戶無法獲得滿意的推薦產品。同時,隨著用戶數量的增加、產品的增加導致計算量過大,信息過濾的效率不高。因此,協同過濾推薦系統適用于用戶規模相對穩定、產品數量相對固定的系統。
2.3 協同過濾推薦系統有助于充分開發圖書館資源
圖書館的建設不應該僅考慮不斷地擴充圖書文獻資源,被動地等待讀者自己進行選擇,而應該以讀者為中心,整合各種信息資源和手段,主動為讀者提供信息服務,這樣既有利于幫助讀者找到感興趣的圖書文獻,又能大大提升圖書館各類資源的利用率。因此,構建協同過濾圖書推薦系統是十分必要的。
3 基于分類的協同過濾算法
讀者由于專業的限制、興趣的導向,往往更多地關注于某一個或幾個領域,對該領域內的圖書加以評論,而對其它領域內的圖書很少問津。據此行為特征,將圖書分成若干個不同類型,只對讀者感興趣的一個或幾個類別的圖書由讀者進行比較過濾推薦。這樣,可以大大減少參與推薦的圖書數目和讀者數目,從而可以有效地克服數據稀疏性和系統可擴展性的問題。
3.1 圖書的初始評分值問題
由于圖書文獻數量巨大,不是每本圖書都有機會得到讀者的評分。同時,每天都有新書經加工后進入數據庫,這些新書無法獲得讀者的評價,導致數據稀疏性問題。這里采取圖書的初始評分法來解決這一問題。即在新書進行編目和分類加工時,給新書一個初始評分,以解決數據稀疏性問題。
而對于系統已保存的大量未獲評價的圖書,在推薦系統實施之前,可以由系統主動賦予分值。根據圖書的流通次數、流通頻率、借閱時長,系統計算出一個推薦分值。如公式1所示:

其中,v0表示評分的基數,可以設定為-0.5;n表示近兩年的流通次數,當n>10時,n/10取值1;t表示平均借閱時長,單位為天,當t>20時,t/20取值1。
通過以上兩步舉措,可以保證在推薦系統實施之前,所有推薦對象圖書都可以獲得一個初始評分。
3.2 圖書和讀者的分類
利用《中圖法》,對待推薦的圖書進行分類。這里的圖書分類不同于著錄工作中的分類,無需進行細致的類目分析,只須根據圖書的分類號將其納入相應的二級類目中即可。一本圖書在分類時可能不僅僅歸屬于某一類目,有時會同屬于某兩類或多個類目。
根據讀者評價過的圖書,判斷這些圖書的類別,可以進一步把讀者劃分在某一類或某幾類中。表1列出了已經分類的讀者列表,從表中可以判斷讀者所屬類別。
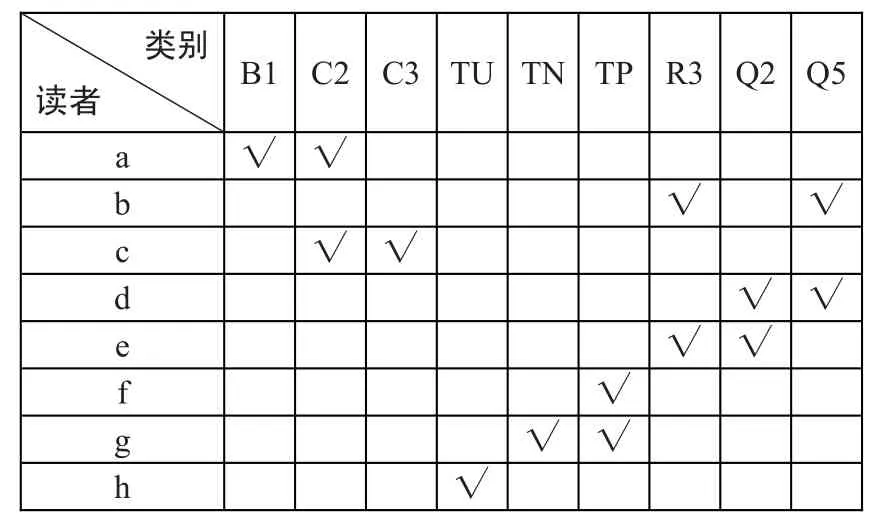
表1 讀者分類表
表2是從借閱數據中抽取的部分信息,根據讀者評價過的圖書、喜愛的圖書,來判斷讀者的分類。
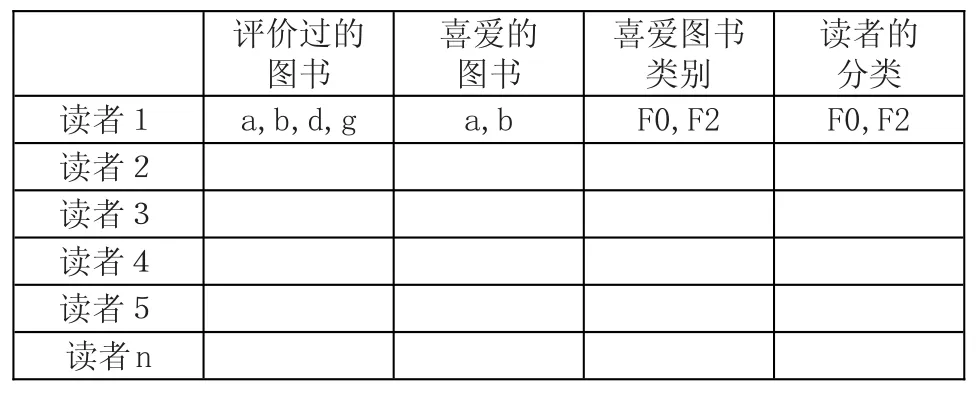
表2 讀者評價圖書分類表
3.3 讀者相似度的影響因子
在現實情況下,讀者的身份、職稱、年齡等不一而同;有的讀者評分時偏向于積極評價,因此分值偏高,有的讀者評分時偏向于審慎評價,因此分值偏低;一些讀者給出的評價比較公正客觀,而一些讀者給出的評價隨意性較大。不同讀者給出的評分值對其他讀者的影響度是不同的,比如研究生導師評價較高的圖書顯然會對其研究生有重要推薦價值。可見,讀者的推薦能力是不同的。
有鑒于此,對讀者的推薦能力進行加權處理,以便正確反映讀者的推薦能力,提高推薦的精確度。
(1)讀者身份
按照常理,本科生、研究生、講師、副教授、教授對某專業圖書的推薦能力是逐漸提高的。因為他們對某專業的研究時間、科研水平也是逐漸提高的。所以,讀者相似度的第一個影響因子w1用讀者的身份來表示。

表3 讀者身份的加權系數
w1表示讀者身份的加權系數,k1,k2,k3,k4逐漸提高,教授的加權系數為1,表示教授的影響力最大,推薦能力最強。
(2)評價過的圖書數量
當讀者對某一領域內的圖書大量閱讀并給出評價,說明該讀者在此領域的研究時間增加、知識掌握全面、經驗值提高,給出的評價也更具有影響力。因此,用讀者評價過的圖書數量作為讀者相似度的第二個影響因子w2。

(3)評價的準確度
當一本圖書被較多的讀者借閱后,得到較多評價時,它會有一個平均評分值。而這個平均評分值也是最接近該圖書的真實評分。這樣,當一位讀者對圖書的評分越接近平均評分值,說明該讀者對圖書評價的準確度越高,其推薦力也越強。因此,評價的準確度可以作為讀者相似度的第三個影響因子w3。

其中,i表示讀者評價過的某本圖書,B表示讀者評價過的圖書的集合,vi表示讀者對圖書i的評分值,-vi表示i獲得的平均評分值,Max和Min分別表示i所獲得的最大評分值和最小評分值,n表示讀者評價過的圖書數量。
綜上所述,影響讀者相似度的因子可以用如下公式表示:

3.4 算法流程
(1)圖書和讀者的分類
按照《中圖法》的分類方法,以二級類目為不同的類別種類,將圖書分別劃分到所屬類別。對于屬于交叉學科的圖書,將其分別歸類于同屬的類別。
對于讀者的分類,可以依據讀者的評分來進行劃分。讀者評分值高、評價數多的幾種圖書類別通常代表了讀者的興趣愛好,可將讀者歸入相應的類別。而讀者評分值低、評價數少的類別基本不在讀者的興趣范圍,讀者不屬于這些類別,對于這些類別的圖書不予推薦。讀者由于專業、興趣和時間的限制,往往固定于某幾個知識領域的圖書,因此同一讀者的分類以2-3種為好。過多的分類會造成運算量大,推薦精確度低等問題。
確定了目標讀者a的所屬類別后,對該類別的讀者進行分析,對于讀者評分數小于閾值的讀者予以屏蔽,留下有效讀者。
(2)相似度的計算
在基于分類的協同過濾算法中,某一類別中的圖書之間相關性很強,讀者對某類圖書的評價等價于讀者對該類圖書的評價總和,即

其中,va,k表示讀者a對某一類別ck的評價,j表示類別ck中的某一種圖書,va,j表示讀者a對圖書j的評價。
如果某本圖書同時屬于多個類別,那么對該類別的評價則應進行加權計算,如公式6所示:

其中,pj,k表示圖書j屬于圖書分類ck的概率,其滿足即圖書j分屬各個類別的概率之和應為1。
讀者之間的相似度計算采用皮爾遜相關系數算法計算。計算讀者a、b的相似度如下:
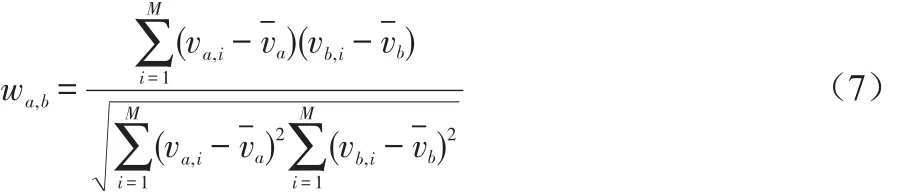
其中,M表示讀者a,b共同評價過的圖書類,-va,-vb分別代表a,b所評價過的圖書類的平均評分值。根據相似度的大小,確定讀者a的最近鄰居集U。
(3)生成推薦結果
在讀者a的最近鄰居集所屬的圖書類別中,預測這些圖書類對讀者a的可能評分值。根據修正的余弦相似性(Adjusted Cosine)算法,考慮讀者相似度的影響因子,對預測評分值提出如下公式:
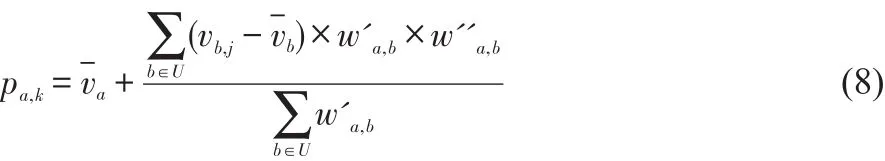
其中,pa,k表示讀者a對圖書類k的預測評分值,-va,-vb表示a,b對圖書類的平均評分值,U表示a的最近鄰居集,w'a,b表示讀者a、b相似度的修正值,w''a,b表示a、b相似度的影響因子。
進一步的,得到a對圖書類k的預測評分值pa,k之后,讀者a對圖書j的預測評分值可以通過公式9得到:

其中,wk表示圖書j屬于類k的概率,R表示j所屬類的集合。通過計算得出讀者a的預測評分值最大的前幾項推薦圖書,推薦給讀者。
4 結語
伴隨著互聯網技術的廣泛應用,現代圖書館正向數字型圖書館方向發展,加上原始的館藏資源不斷增加。面對如此巨大的信息資源,讀者需要某種手段來幫助他們找尋對自己有用的信息。文章提出的基于分類的圖書推薦系統,就是在這方面做努力,希望能幫助讀者找出符合需求的館藏,得到個性化的推薦服務。
[1]謝琳惠.推薦系統在高校數字圖書館的應用[J].現代情報,2006,(11):72-74.
[2]Resnick P,Iakovou N,Sushak M,et al.GroupLens:An open architecture for collaborative filtering of netnews.Proc 1994 Computer Supported Cooperative Work Conf[J].North Carolina:Chapel Hill,1994:175-186.
[3]劉建國,周濤,汪秉宏.個性化推薦系統的研究進展[J].自然科學研究進展,2009,19(1):1-15.
[4]曾慶輝,邱玉輝.一種基于協作過濾的電子圖書推薦系統[J].計算機科學,2005,32(6):147-150.
[5]孫守義,王蔚.一種基于用戶聚類的協同過濾個性化圖書推薦系統[J].現代情報,2007,(11):139-142.
[6]Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C].Proc 10th International WWW Conf.New York:ACM Press,2001:285-295.
[7]Lee TQ,Park Y,Park YT.A time-based approach to effective recommender systems using implicit feedback[J].Expert Systems with Applications,2008,34(4):3055-3062.
[8]Chen YL,Cheng LC.A novel collaborative filtering approach for recommending ranked items[J].Expert Systems with Applications,2008,34(4):2396-2405.
[9]Yang MH,Gu ZM.Personalized recommendation based on partial similarity of interests[M].Advanced Data Mining and Applications Proceedings,2006,4093:509-516.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
