自適應(yīng)多趟聚類(lèi)在檢測(cè)無(wú)線(xiàn)傳感器網(wǎng)絡(luò)安全中的應(yīng)用*
2015-03-26 07:59:56滕少華李日貴劉冬寧
傳感器與微系統(tǒng) 2015年2期
滕少華,洪 源,李日貴,張 巍,劉冬寧
(廣東工業(yè)大學(xué) 計(jì)算機(jī)學(xué)院,廣東 廣州510006)
0 引 言
數(shù)據(jù)庫(kù)技術(shù)的快速發(fā)展和數(shù)據(jù)庫(kù)管理系統(tǒng)的廣泛應(yīng)用,使得各種組織結(jié)構(gòu)積累了海量數(shù)據(jù)。人們迫切希望從海量數(shù)據(jù)中找到有用的知識(shí)和信息,從而在市場(chǎng)競(jìng)爭(zhēng)中搶占先機(jī)。面對(duì)這種挑戰(zhàn),數(shù)據(jù)挖掘技術(shù)獲得了迅速發(fā)展,不僅在理論上有眾多成果[1,2],且已廣泛走向工業(yè)應(yīng)用。聚類(lèi)分析是數(shù)據(jù)挖掘的主要方法之一[2],它是分析數(shù)據(jù)并從中發(fā)現(xiàn)信息和知識(shí)的一種手段。對(duì)聚類(lèi)分析,人們?nèi)〉昧艘幌盗醒芯砍晒-Means 算法[3]是經(jīng)典的聚類(lèi)算法之一,但需要預(yù)先給定聚類(lèi)個(gè)數(shù)和初始值,開(kāi)銷(xiāo)大且對(duì)數(shù)據(jù)輸入順序敏感;文獻(xiàn)[4]提到的Rock 算法是一種經(jīng)典的層次聚類(lèi)算法,針對(duì)包含分類(lèi)屬性的數(shù)據(jù)集使用鏈接(兩個(gè)對(duì)象間共同的近鄰數(shù)目),不但考慮了對(duì)象間的相似度,還考慮了鄰域信息;改進(jìn)的DBSCAN 算法[5]是一種基于高密度聯(lián)通區(qū)域的基于密度的聚類(lèi)方法,可以有效地找出任意形狀的簇。
無(wú)線(xiàn)網(wǎng)絡(luò)傳感器[6]作為一種檢測(cè)裝置,能夠獲得周?chē)男畔ⅲ⑦@些信息按照一定的規(guī)律轉(zhuǎn)換為其他需要形式的信息,滿(mǎn)足傳輸、存儲(chǔ)等功能。通過(guò)無(wú)線(xiàn)傳感器收集的信息,這里成為無(wú)線(xiàn)網(wǎng)絡(luò)數(shù)據(jù)集,本文在提出了自適應(yīng)的多趟聚類(lèi)分析方法,并將其運(yùn)用到無(wú)線(xiàn)數(shù)據(jù)中,發(fā)現(xiàn)數(shù)據(jù)特征,尋找離群信息,對(duì)于一般的離群點(diǎn),往往有重要研究?jī)r(jià)值,可以用于研究無(wú)線(xiàn)傳感器節(jié)點(diǎn)的安全信息[7]。
1 KSummary 算法
1.1 KSummary 算法與相關(guān)概念
KSummary 算法[8]能夠處理分類(lèi)屬性與混合屬性數(shù)據(jù),提出使用聚類(lèi)摘要信息(cluster summary information,CSI)來(lái)表示一個(gè)簇,算法給出了自己的相似度計(jì)算方法。
設(shè)D 為數(shù)據(jù)集合,D 中任意一條記錄有m 個(gè)屬性,其中有mc個(gè)分類(lèi)屬性和mN個(gè)數(shù)值屬性,顯然滿(mǎn)足m=mc+mN。用Di表示第i 個(gè)屬性取值的集合,x=2。下面給出KSummary 算法的定義[9]:
定義1 給定簇C,a∈Di,a 在C 中關(guān)于Di的頻度定義為C 在Di上的投影中包含a 的個(gè)數(shù)
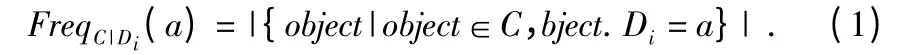
定義2 給定簇C,n=|C|表示C 的大小,C 的CSI 定義為CSI={n,summary},由數(shù)值型屬性的質(zhì)心和分類(lèi)屬性中不同取值的頻度信息兩部分組成,即
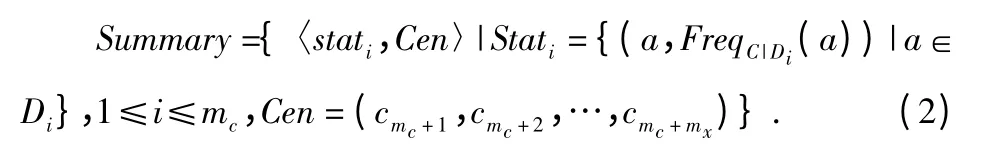
定義3 設(shè)C,C1,C2為數(shù)據(jù)集合D 劃分的簇,p=[p1,p2,…,pm],q=[q1,q2,…,qm]表示兩個(gè)對(duì)象,x >0。
1)對(duì)象p 到簇C 的距離d(p,C)定義為p 與簇C 的摘要之間的距離

對(duì)于dif(pi,Ci),當(dāng)Di表示分類(lèi)屬性時(shí),該值定義為p與C 中每個(gè)對(duì)象在屬性Di上的距離的算術(shù)平均值,即

當(dāng)Di是數(shù)值屬性時(shí),定義為

2)簇C1和簇C2間的距離d(C1,C2)定義為兩個(gè)簇的摘要間的距離

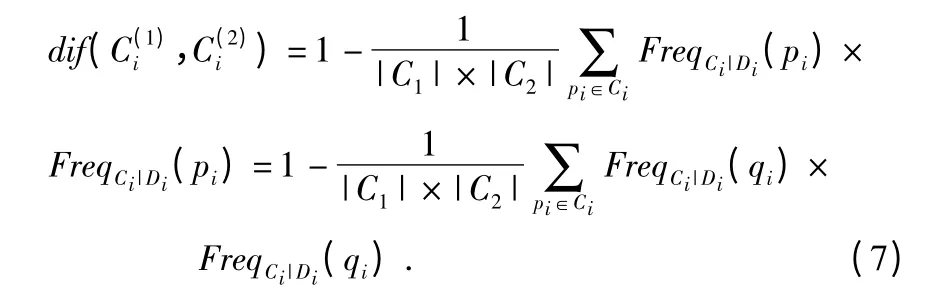
若Di為數(shù)值屬性,則該值定義為
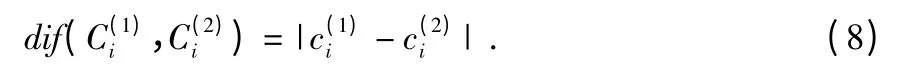
3)dif(pi,qi)表示兩個(gè)對(duì)象p,q 在屬性Di上距離,dif(p,q)表示對(duì)象p,q 之間的距離
a.若Di是二值屬性或分類(lèi)屬性或:
當(dāng)pi=qi,dif(pi,qi)=0;
當(dāng)pi≠qi,dif(pi,qi)=1 .
b.若Di是順序?qū)傩曰蜻B續(xù)數(shù)值屬性

c.兩個(gè)對(duì)象p,q 間的距離為

1.2 KSummary 算法的不足
KSummary 算法能夠很好地處理混合型數(shù)據(jù)集[9],但需要解決下列問(wèn)題:1)預(yù)先給定聚類(lèi)個(gè)數(shù)k 值,k 的取值直接影響聚類(lèi)結(jié)果;2)需要隨機(jī)選擇k 個(gè)初始聚類(lèi)中心,記為集合Q,但是KSummary 算法的聚類(lèi)結(jié)果對(duì)Q 存在依賴(lài)關(guān)系。
2 自適應(yīng)多趟聚類(lèi)分析方法
2.1 體系結(jié)構(gòu)
本文提出自適應(yīng)多趟聚類(lèi)分析方法,采用層次聚類(lèi)、基于密度聚類(lèi)和KSummary 聚類(lèi)算法相結(jié)合的思想,對(duì)數(shù)據(jù)集進(jìn)行多趟聚類(lèi)。多趟聚類(lèi)體系結(jié)構(gòu)如圖1 所示。
2.2 自適應(yīng)層次聚類(lèi)
本階段在層次聚類(lèi)的基礎(chǔ)上,使用自適應(yīng)[10]層次聚類(lèi)算法。實(shí)施時(shí),對(duì)于數(shù)據(jù)集,根據(jù)公式(11),給出閾值R,R值會(huì)選擇的相對(duì)大些,這樣在調(diào)整閾值時(shí)可以直接減小該值。通過(guò)計(jì)算簇內(nèi)和簇間對(duì)象的相似度,得到一個(gè)評(píng)價(jià)函數(shù)。
若評(píng)價(jià)函數(shù)偏高,則減小閾值R,繼續(xù)剛才的聚類(lèi),得到新的層次聚類(lèi),直到評(píng)價(jià)函數(shù)[2]的值達(dá)到理想條件為止,這樣獲得聚類(lèi)結(jié)果依賴(lài)于具體的數(shù)據(jù)集,使得算法更實(shí)用和可靠。
算法閾值[11,12]R 定義為
其中,total(D)為數(shù)據(jù)集D 中對(duì)象間的距離之和,n 為指對(duì)象個(gè)數(shù),α 為閾值調(diào)節(jié)系數(shù)。對(duì)于不熟悉的數(shù)據(jù)集,α值一般都是要通過(guò)經(jīng)驗(yàn)值來(lái)獲得。
文中使用均衡化的評(píng)價(jià)函數(shù)[11,12],對(duì)于聚類(lèi)C 計(jì)算類(lèi)內(nèi)相似度D(C)和類(lèi)間相似度L(C),獲得了評(píng)價(jià)函數(shù)為
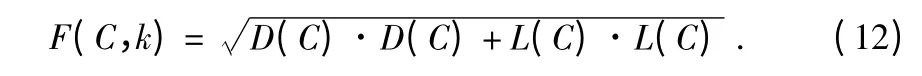
當(dāng)滿(mǎn)足距離代價(jià)最小時(shí),可以得到最優(yōu)的空間聚類(lèi)結(jié)果。自適應(yīng)層次聚類(lèi)的流程圖圖2。
2.3 密度聚類(lèi)與迭代過(guò)程
本文使用的密度聚類(lèi)[2]方法是在已經(jīng)有一組聚類(lèi)基礎(chǔ)上進(jìn)行的。用D 來(lái)表示數(shù)據(jù)集,Ci(i=1,2,..,k)表示簇。本階段通過(guò)計(jì)算各個(gè)簇中對(duì)象密度,選擇簇中密度相對(duì)較大的點(diǎn)作為該簇的代表點(diǎn),并選為下一步算法的初始聚類(lèi)中心。將簇Ci中的任意對(duì)象pi的密度定義為density(pi)[11,12]
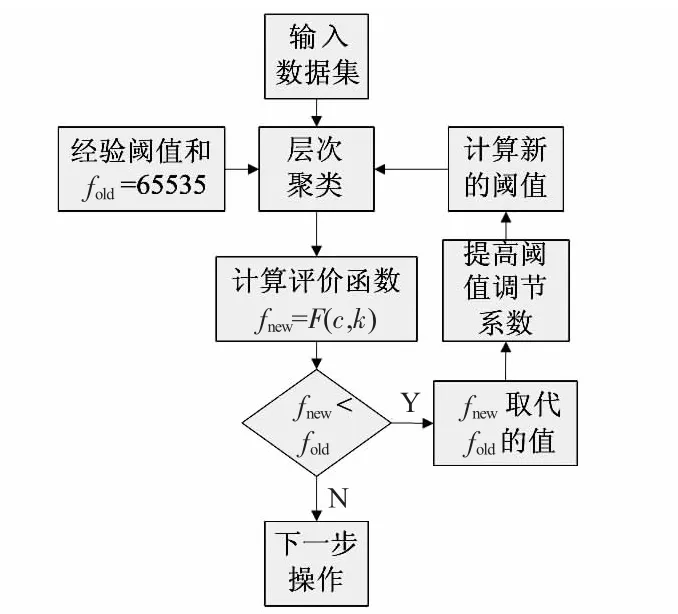
圖2 自適應(yīng)層次聚類(lèi)流程Fig 2 Flow chart of adaptive hierarchical clustering
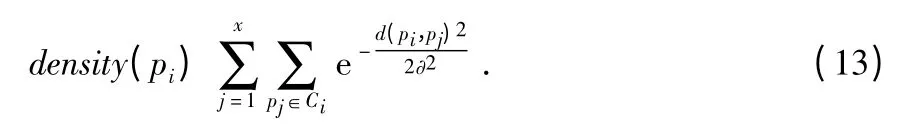
其中,x 為pi所在簇中的對(duì)象個(gè)數(shù),pj為該簇內(nèi)對(duì)pi有影響的的任一對(duì)象,d(pi,pj)為pi到pj的距離,?為對(duì)象之間可以相互影響的閾值。對(duì)象pi密度是在該對(duì)象所在的簇內(nèi)計(jì)算,因而,閾值?僅和該簇內(nèi)對(duì)象有關(guān),不同簇中的?值也是不同的。
獲得初始聚類(lèi)個(gè)數(shù)k 和初始聚類(lèi)中心Q 以后,運(yùn)用KSummary 算法,重復(fù)迭代,不斷更新簇的摘要信息和對(duì)象所屬的簇,直到每個(gè)對(duì)象所屬的簇不再發(fā)生變化時(shí),算法終止。
2.4 傳感器數(shù)據(jù)集
使用無(wú)線(xiàn)傳感器收集手機(jī)通信信息,從傳感器收集的信息要經(jīng)過(guò)多重處理,包括數(shù)據(jù)壓縮和融合等[13,14],這樣在經(jīng)過(guò)處理后會(huì)產(chǎn)生能夠使用的數(shù)據(jù)集,這樣的數(shù)據(jù)集適用于自適應(yīng)多趟聚類(lèi)算法。數(shù)據(jù)集的主要屬性包括:移動(dòng)信號(hào)強(qiáng)度(MSPOWER)、上行接收信號(hào)(RXLEV)、時(shí)間延遲量(TA)等。數(shù)據(jù)集的每條記錄,都有標(biāo)記其來(lái)源的若干屬性,這樣在聚類(lèi)后,記錄位置變化后,仍能找到獲得該記錄的傳感器設(shè)備,這樣的數(shù)據(jù)特征有助于分析實(shí)驗(yàn)結(jié)果。
數(shù)據(jù)集經(jīng)過(guò)數(shù)據(jù)預(yù)處理[15]后,能夠獲得切合實(shí)際并且適合聚類(lèi)方法的數(shù)據(jù)集,部分?jǐn)?shù)據(jù)如下

3 實(shí)驗(yàn)結(jié)果和分析
3.1 實(shí)驗(yàn)環(huán)境
本文使用了無(wú)線(xiàn)傳感器收集數(shù)據(jù),用于接收手機(jī)發(fā)出的無(wú)線(xiàn)電信號(hào)。數(shù)據(jù)處理和聚類(lèi)算法使用在機(jī)器為:CPU:Inter Core(TM)T5800,RAM:2GB,32 位操作系統(tǒng)。工具為Weka 3.7,Vs 2010.使用精度、平均評(píng)價(jià)函數(shù)、統(tǒng)計(jì)方法[16,17]等來(lái)對(duì)實(shí)驗(yàn)結(jié)果分析。
3.2 實(shí)驗(yàn)和結(jié)果
聚類(lèi)分析的統(tǒng)計(jì)結(jié)果見(jiàn)圖3、表2 和圖4。
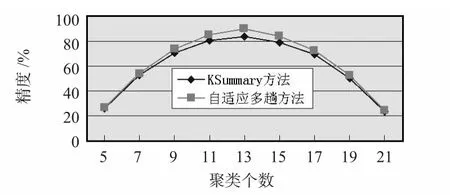
圖3 兩種方法在不同聚類(lèi)個(gè)數(shù)下的精度Fig 3 Precision of the two methods under different number of clustering

表1 實(shí)驗(yàn)結(jié)果統(tǒng)計(jì)Tab 1 Statistics of experimental results
表1 記錄了實(shí)驗(yàn)過(guò)程的計(jì)算結(jié)果,結(jié)合圖3 可以看到:本文算法得到的評(píng)價(jià)函數(shù)、平均評(píng)價(jià)函數(shù)都比原算法低,而最高精度和平均精度也優(yōu)于原算法的處理結(jié)果。圖3 也說(shuō)明自適應(yīng)多趟聚類(lèi)算法可以找到在無(wú)線(xiàn)網(wǎng)絡(luò)數(shù)據(jù)集上的最佳聚類(lèi)個(gè)數(shù),聚類(lèi)的精度也達(dá)到了比較理想的數(shù)值。
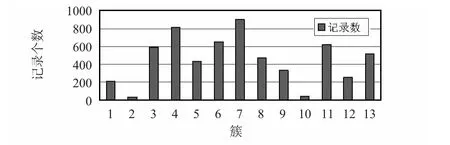
圖4 簇中對(duì)象的個(gè)數(shù)Fig 4 Number of objects in each cluster
圖4 給出了聚類(lèi)后的數(shù)據(jù)分布,給出了簇中數(shù)據(jù)對(duì)象的個(gè)數(shù),容易發(fā)現(xiàn)第2,10 簇中數(shù)據(jù)比其他簇少很多,所以,這些對(duì)象就很大概率是要找的離群點(diǎn),通過(guò)對(duì)這些對(duì)象的分析,可以定位到收集這些信息的無(wú)線(xiàn)傳感器,進(jìn)一步研究可以分析出該傳感器某個(gè)節(jié)點(diǎn)的安全狀況。
4 結(jié)束語(yǔ)
自適應(yīng)多趟聚類(lèi)分析方法相比傳統(tǒng)KSummary 算法,從平均評(píng)價(jià)函數(shù)和平均精度都有更好的效果。自適應(yīng)多趟聚類(lèi)算法是將整個(gè)過(guò)程分為三趟聚類(lèi),三趟之間屬于串行。與KSummary 算法相比,確實(shí)增加了一定的時(shí)間開(kāi)銷(xiāo),但是在數(shù)量級(jí)與指數(shù)級(jí)上都沒(méi)有增加,而且聚類(lèi)的效果要好于原算法。
使用自適應(yīng)多趟聚類(lèi)算法,應(yīng)用于傳感器收集的無(wú)線(xiàn)網(wǎng)絡(luò)數(shù)據(jù)中,離群點(diǎn)表現(xiàn)出來(lái)的信息與其他信息會(huì)有較大差異,這在本算法中會(huì)有明顯的體現(xiàn),實(shí)驗(yàn)結(jié)果也說(shuō)明了這個(gè)問(wèn)題。對(duì)聚類(lèi)后找到的可疑離群點(diǎn)進(jìn)行分析,定位到收集該信息的傳感器,就能夠知道該設(shè)備的節(jié)點(diǎn)是否處于安全的工作狀態(tài)。
[1] 王令劍,滕少華.聚類(lèi)和時(shí)間序列分析在入侵檢測(cè)中的應(yīng)用[J].計(jì)算機(jī)應(yīng)用,2010,30(3):699-701.
[2] Han Jianwei,Micheline Kamber,Pei Jian.數(shù)據(jù)挖掘概念與技術(shù)[M].范 明,孟小峰,譯.3 版.北京:機(jī)械工業(yè)出版社,2012.
[3] Kanungo T,Mount D,Netanyahu N,et al.An efficient k-means clustering algorithm:Analysis and implementation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(7):881-992.
[4] Dutta M,Kakoti A Mahanta,Arun Pujari K.QROCK:A quick version of the ROCK algorithm for clustering of categorical data[J].Pattern Recognition Letters,2005,26(15):2364-2373.
[5] 周水庚,周傲英,金 文,等.FDBSCAN:一種快速DBSCAN算法[J].軟件學(xué)報(bào),2000,11(6):735-744.
[6] 馬華東,陶 丹.多媒體傳感器網(wǎng)絡(luò)及其研究進(jìn)展[J].軟件學(xué)報(bào),2006,17(9):2013-2028.
[7] 陳 娟,張宏莉.無(wú)線(xiàn)傳感網(wǎng)絡(luò)安全研究綜述[J].哈爾濱工業(yè)大學(xué)學(xué)報(bào),2011,43(7):90-95.
[8] 蔣盛益,李 霞,鄭 琪.數(shù)據(jù)挖掘原理與實(shí)踐[M].北京:電子工業(yè)出版社,2011.
[9] 蔣盛益,李慶華.一種增強(qiáng)的K-Means 聚類(lèi)算法[J].計(jì)算機(jī)工程與科學(xué),2006,28(11):56-59.
[10]馬 力,焦李成,白 琳,等.自適應(yīng)多克隆聚類(lèi)算法及收斂性分析[J].模式識(shí)別與人工智能,2008,21(1):72-83.
[11]汪 中,劉貴全,陳恩紅.一種優(yōu)化初始中心點(diǎn)的K-Means 算法[J].模式識(shí)別與人工智能,2009,22(2):299-305.
[12]袁 方,周志勇,宋 鑫.初始聚類(lèi)中心點(diǎn)優(yōu)化的K-Means 算法[J].計(jì)算機(jī)工程,2007,33(3):65-69.
[13]尹亞光,貴 廣.無(wú)線(xiàn)傳感器網(wǎng)絡(luò)中的數(shù)據(jù)壓縮技術(shù)研究[J].計(jì)算機(jī)應(yīng)用與軟件,2010,27(7):1-4.
[14]張 軍,楊子晨.多傳感器數(shù)據(jù)采集系統(tǒng)中的數(shù)據(jù)融合研究[J].傳感器與微系統(tǒng),2014,33(3):52-57.
[15]趙 偉,何丕廉,陳 霞,等.Web 日志挖掘中的數(shù)據(jù)預(yù)處理技術(shù)研究[J].計(jì)算機(jī)應(yīng)用,2003,23(5):62-67.
[16]Yosr N,Kaouther B S.Interpretability-based validity methods for clustering results evaluation[J].Journal of Intelligent Information Systems,2012,39(1):109-139.
[17]Peter T,Jana H.Mathematical tools of cluster analysis[J].Applied Mathematics,2003,4(5):814-816.
[18]古 平,劉海波,羅志恒.一種基于多重聚類(lèi)的離群點(diǎn)檢測(cè)算法[J].計(jì)算機(jī)應(yīng)用研究,2013,30(3):751-756.
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
中華手工(2017年2期)2017-06-06 23:00:31
山東青年(2016年1期)2016-02-28 14:25:25
中外會(huì)展(2014年4期)2014-11-27 07:46:46
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
公務(wù)員文萃(2013年5期)2013-03-11 16:08:37
海外英語(yǔ)(2006年11期)2006-11-30 05:16:56
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32

- 傳感器與微系統(tǒng)的其它文章
- 分段冪函數(shù)模型在氣敏檢測(cè)器定量算法中的應(yīng)用
- PSO-BP 神經(jīng)網(wǎng)絡(luò)在多元有害氣體檢測(cè)中的應(yīng)用*
- 基于次錨節(jié)點(diǎn)的無(wú)線(xiàn)傳感器網(wǎng)絡(luò)改進(jìn)加權(quán)質(zhì)心定位算法
- 一種無(wú)線(xiàn)傳感器網(wǎng)絡(luò)可靠拓?fù)涞纳伤惴?
- 基于分簇的移動(dòng)協(xié)助無(wú)線(xiàn)傳感器網(wǎng)絡(luò)路由協(xié)議*
- 一種基于A(yíng)PIT 的無(wú)線(xiàn)傳感器網(wǎng)絡(luò)混合型定位算法