大數據架構在企業中的應用
2015-02-28 02:11:10王永峰程新洲
電信科學 2015年9期
關鍵詞:企業
王永峰,程新洲,高 潔
(中國聯合網絡通信有限公司網絡技術研究院 北京 100048)
1 引言
隨著各行業信息化速度的加快,不同類型的數據皆呈現出爆發性增長的趨勢。對于這些數據,企業往往用來進行運營、策劃、銷售等方面的應用,得到不同層面的技術指標,產生系列的報表并反饋到生產和運營中。但是,當這些數據的量增長到一定程度后,量變引起質變,原有的信息化系統和工具漸漸無法承載如此龐大的數據存儲和運算,分析效率逐步降低,以至于無法勝任數據分析的需求。在這種處境下,決策者們往往向大數據系統架構靠攏,對原有的信息系統進行改造,去擁抱真正意義上的大數據資產。在大數據系統的引入過程中,紛繁復雜的系統實現方法是較為迷惑人的,不同層面、不同技術的選擇也會因為需求和目的的不同而影響到實際的決策。因此,深入地了解大數據系統凸顯出了它的意義。
2 企業大數據應用的關鍵環節
大數據本身是一個較為概括的稱謂,并沒有對數據的量級做明確的界限。在實際應用中,通常把采用大數據架構進行存儲、分析和應用的場景統稱為大數據。
大數據在實際的企業應用中,包含多個環節的處理,最終形成監控運行狀態、支撐方案決策的大數據應用。在大數據分析的全鏈條中,比較關鍵的兩個環節是大數據存儲和大數據計算。如圖1所示,描述了大數據轉化的周期,包括數據的采集、解析、入庫、存儲、分析和應用的各個環節。
大數據采集即數據的初步收集過程。一個公司的數據價值是否明晰,主要從兩個方面判斷,其一是數據源的獲取是否穩定,其二是其數據價值的變現過程是否可持續。因此,大數據采集是至關重要的,數據采集決定了整個系統的輸入、數據采集的深度和廣度,決定了整個大數據分析鏈條的價值導向。大數據采集包含很多類別,如自身用戶數據、系統運營數據產生的自有數據,或者從其他用戶龐大用戶群體的公司處獲取的第三方數據,抑或一些靜態的數據信息,如用戶身份信息、鄉鎮街道信息等。
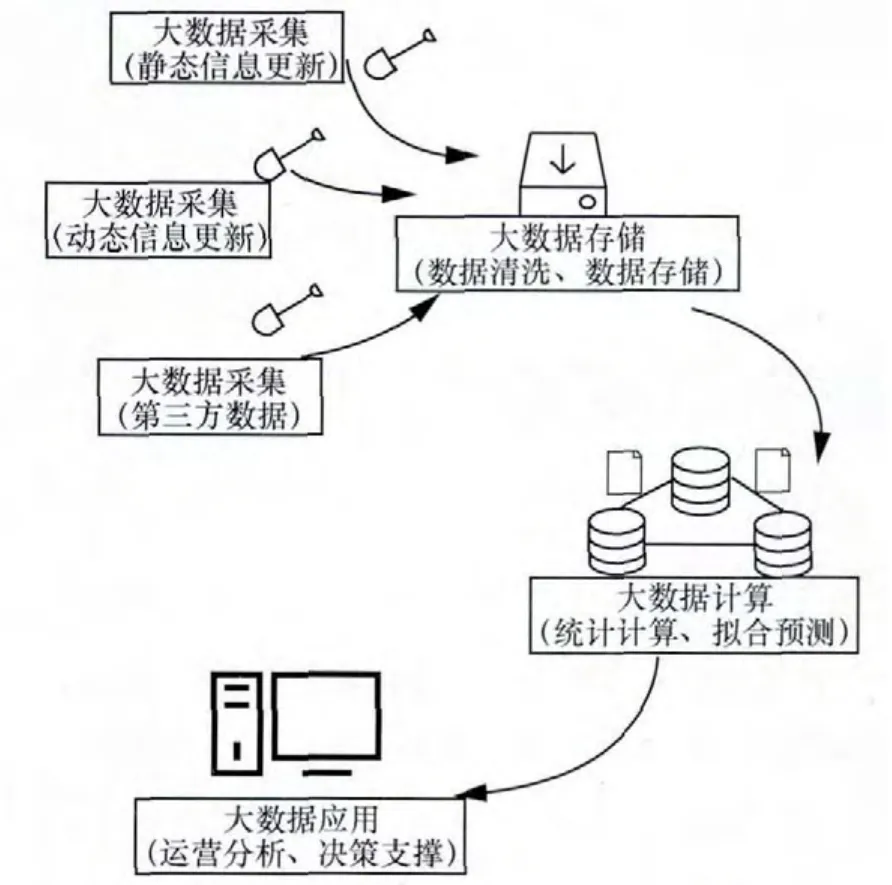
圖1 基于自組織的分布式網絡管理模型
大數據存儲是大數據有別于傳統數據分析的標志性特征,服務于大數據的存儲方式以及相應的工具也蜂擁而至。如何低風險、低成本地建立一套大數據存儲體系是企業構建大數據架構考慮的首要問題。從HDFS(Hadoop distributed file system,Hadoop分布式文件系統),到接踵而至的HBase、Hive、Impala等,縱向細分的差異性的系統和工具給人們更多的選擇空間,企業可根據自身大數據的應用場景,從成本、時效性、數據規模等多個方面選擇,進而因地制宜地搭建適合本企業數據類型、分析方式的大數據存儲架構。
數據存儲和數據計算是相輔相成的,存儲是為了計算,計算中還需要存儲,因此大數據計算不是獨立設計的。在大數據計算中,需要考慮多個方面的因素。數理統計是大數據分析中較為常用的分析方法,例如頻次統計、分布統計等,是支撐企業運營分析的一項重要的途徑。在運營分析中,數據運營是重要的組成部分,通過日報表、周報表、月報表等,企業可以提煉出數據中的價值,明確地看出企業運作中的不同趨勢,進行用戶對比、內容策劃、成本控制、風險預警等。除了數理統計以外,更高一層面的、復合型的分析也是大數據勝任的內容,包括數據的聚類分析、關聯分析、回歸分析、擬合分析等,通過神經網絡、機器學習、迭代等步驟得到更智能、更具有應用價值的計算結果。
諸多的計算步驟,只有一個目的,就是為大數據應用服務。大數據應用就像企業運作中的顧問,用數據說話,給決策者一個參考的依據。大數據應用可以分為前臺和后臺,前臺通過用戶友好的界面,分層次成體系的向用戶展示不同維度的大數據分析結果,提供定制化分析模板,輔助以不同的應用工具,將后臺的運算的數據通過圖表、應用、地理化呈現等方式展示大數據計算的結果。
縱觀整個大數據鏈條可以發現,與大數據核心技術密切相關的環節主要在大數據存儲和大數據計算兩個環節。企業在“互聯網+”戰略計劃中,勢必要加大在大數據分析方面的投入,改造原有的大數據倉庫,或者建造新的大數據倉庫,部署分布式系統架構,搭建大數據平臺。而這些投入不是盲目跟風的,需要針對使用的場景以及預算的成本來綜合抉擇,最終形成企業的大數據方案。
3 典型的架構與差異化策略
大數據典型架構按層級劃分,可分為物理層、存儲層、計算層、業務層和應用層,如圖2所示。層與層之間并沒有天然的隔閡和明顯的劃分標準,只是將邏輯的功能范圍作為劃分的依據。多層的架構承擔著不同的功能,每層都對上層提供可靠的服務,因此形成了一個有機的功能體。
企業在構建大數據架構時,是需要謹慎考慮的,尤其是底層的構建很大程度影響了上層的業務、應用性能。這里著重從差異化的策略來闡述幾種典型技術對大數據架構的影響。
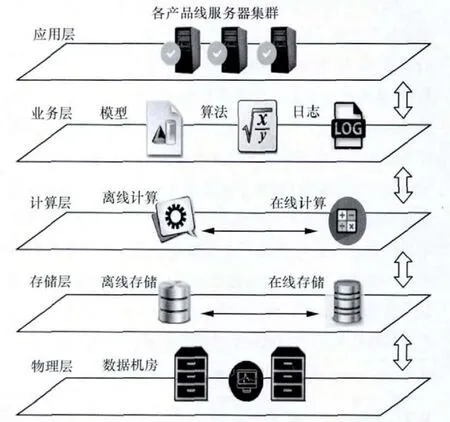
圖2 大數據架構層級
3.1 硬件策略
3.1.1 數據備份與存儲方案選擇
存儲是首要考慮的問題,作為企業級應用,存儲更需要慎重抉擇。歷史經驗證明,數據資產的安全對一個企業是至關重要的,尤其是在如今,數據存儲危機給企業帶來的影響是致命的,數據可靠性對企業的重要性不言而喻。
硬盤作為存儲的重要介質,其類型也是多種多樣的。在做選擇的時候,可依據不同應用場景進行選擇。
(1)SATA硬盤
對于自身容錯備份機制較好的大存儲系統,SATA硬盤是一個很好的選擇。SATA即串口硬盤,現已基本取代了傳統的PATA硬盤。Intel、APT、Dell、IBM、希捷和邁拓幾大廠商組成的“Serial ATA委員會”正式確立了規范,SATA硬盤采用串行連接方式,串行ATA總線使用嵌入式時鐘信號,具備了更強的糾錯能力,與以往相比其最大的區別在于能對傳輸指令進行檢查,如果發現錯誤會自動矯正,這在很大程度上提高了數據傳輸的可靠性。串行接口還具有結構簡單、支持熱插拔的優點。
(2)列陣磁盤
通常,不是所有大數據應用場合都適合建立自身容錯備份機制較好的大存儲系統,在不具備這樣的容錯機制的時候,列陣磁盤是一個很好的解決方案。磁盤陣列是由很多價格較便宜的磁盤,組合成一個容量巨大的磁盤組,利用個別磁盤提供數據所產生加成效果提升整個磁盤系統效能。利用這項技術,將數據切割成許多區段,分別存放在各個硬盤上。數組中任意一個硬盤出現故障時,仍可讀出數據,在數據重構時,將數據經計算后重新置入新硬盤中。
(3)SAS硬盤
SAS硬盤即串行連接SCSI(small computer system interface,小型計算機系統接口),是新一代的SCSI技術,和現在流行的serial ATA(SATA)硬盤相同,都是采用串行技術以獲得更高的傳輸速度,并通過縮短連結線來改善內部空間等。SAS硬盤是并行SCSI之后開發出的全新接口,此接口的設計是為了改善存儲系統的效能、可用性和擴充性,并提供與SATA硬盤的兼容性。
因此,在大數據架構搭建的底層,根據自身場景的需求,做出相應的判斷,進而建立或升級存儲結構是十分必要的。
3.1.2 計算性能的需求與硬件的匹配
雖然計算機硬件的發展速度十分迅猛,但是仍然不能小覷日益增長的計算需求。每當硬件水平上一個新的臺階,計算的需求會迅速地填補上來,因為算法的進步是永無止境的。
隨著語音識別、圖像識別等模式識別的發展以及迭代算法需求的增加,大數據平臺的計算數據量是異常龐大的。因此,當計算性能成為瓶頸的時候,相應的提升工作就成為必要考慮的內容。
(1)處理器加速
隨著非結構化數據的爆發性增長,計算量異常巨大,需要依靠GPU加速或者重核卡的加速才能在可容忍的時間內完成計算,不少企業的大數據集群都采用了GPU加速或重核卡。
(2)SSD
某些應用場景下,如快速的迭代算法會有頻繁的讀取與存儲操作,這使得傳統的I/O暴露出速度慢的弊病,嚴重影響了運算的速率。SSD(solid state drives,固態硬盤)有傳統機械硬盤不具備的快速讀寫、質量輕、能耗低以及體積小等特點。隨著目前SSD價格的不斷下滑,SSD逐漸成為一種十分有吸引力的選擇。
(3)虛擬機
服務器的資源常常由于得不到有效的復用,導致資源無法發揮最大的性能或者資源部分閑置。虛擬機的引入解決了這個問題,它能夠精細化地劃分和管理服務器的資源,實現合理地配置、充分地復用,從而整體提升計算的性能。虛擬機技術正逐步成為一種趨勢,目前很多企業級的大數據平臺都選擇搭建在虛擬機集群上。
以上只做了一些常用的技術的描述,實際需根據企業構建大數據平臺的真實情況,選擇合適的技術方案來提升系統性能。
3.2 云存儲策略
在選定了存儲的硬件介質之后,接下來就是從軟件層面上定義存儲的方式。按照時效性劃分,云存儲可分為離線存儲和在線存儲兩種類型,如圖3所示。選擇何種存儲類型,對于企業整體大數據架構而言十分重要。選擇存儲類型一方面要滿足應用時效性的需求,另一方面要和存儲介質以及算法匹配。
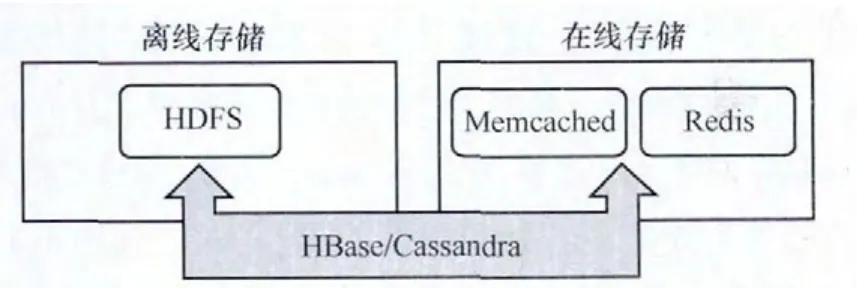
圖3 云存儲的兩種方式
離線存儲一般適用于超大規模的數據量,從時間上來說一般是長時間的存儲,往往應用于對時效性要求不高的場景。例如對于企業應用中一些海量的過程類數據,不需要頻繁訪問的,即可采用離線存儲方式。這種方式最典型的案例就是HDFS,它的部署成本和技術門檻相對較低,因此得以普及。
在線存儲顧名思義需要頻繁的互動,及時性要求較高,同時又具備大數據的海量存儲特征。最常用的Memcached是一個高性能的分布式內存對象緩存系統,常用于動態Web應用以減輕數據庫負載。它通過在內存中緩存數據和對象來減少讀取數據庫的次數,從而提高動態數據庫驅動網站的速度。其本質上是一套分布式的快取系統,但是不提供持久化。與之類似的Redis是一個開源的使用ANSI C語言編寫、支持網絡、可基于內存亦可持久化的日志型key-value數據庫,能夠提供持久化的能力。
3.3 計算層策略
計算層也有離線和在線之分,其實與存儲層區分是類似的,只是表現的技術不同而已,如圖4所示。在分布式系統架構中,不同的任務之間是需要進行數據傳遞的,一部分是采用存儲來傳遞,即存儲和讀取方式實現,另一部分采用數據管道系統來完成。
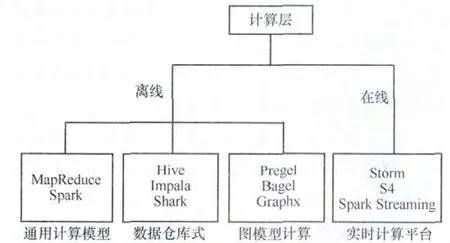
圖4 計算層的不同計算方式
對于數據量龐大、運算耗時長的任務,通常會采用離線計算的方式進行,特別是對于那些需要深度發掘、多次迭代的算法而言。離線計算以MapReduce為代表,MapReduce的設計,采用了很簡化的計算模型,只有map和reduce兩個計算過程,中間用shuffle串聯。用這個模型,可以處理大數據領域很大一部分問題。第二代的Tez和Spark,除了內存緩存之類的新特性以外,讓MapReduce模型更通用,讓map和reduce之間的界限更模糊,數據交換更靈活,更少的磁盤讀寫,以便更方便地描述復雜算法,取得更高的吞吐量。
某些應用場景下需要較短的時延,需要實時性較高,比如智慧城市中的路況監控,這是離線計算無法勝任的。因此,流計算應運而生了,Storm是最流行的流計算平臺。流計算的思路是,如果要達到更實時的更新,則在數據流讀取的時候就直接進行處理。流計算雖然快速,但它不靈活、統計的內容必須預先知道,因此雖然功能強大,但是無法替代數據倉庫和批處理系統。
在企業構建大數據架構的過程中,多種計算方式都是要復合使用的,通過揚長避短達到發揮大數據平臺最高性能的目的。
3.4 業務層策略
構建大數據平臺的之前,必須要做的工作是清楚大數據平臺應用的目的、對象以及算法。否則軟硬件設備購置部署完成后,終究是骨架,而沒有血肉。
業務層承載著大數據的核心思路,包括核心的算法、基礎的分析模塊等。一般來說,這些業務應該包括日志處理、離線分析、深度挖掘、分類聚類和預測建模等離線業務,也有實時挖掘、實時監控等實時處理業務。大數據的核心就是預測,它通常被視為人工智能的一部分,或者更確切地說,被視為一種機器學習。大數據大大解放了人們的分析能力,一是可以分析更多的數據,甚至相關的所有數據,而不再依賴于隨機抽樣;二是研究數據如此之多,以至于人們不再熱衷于追求精確度;三是不必拘泥于對因果關系的探究,而可以在相關關系中發現大數據的潛在價值。因此,當人們可以放棄尋找因果關系的傳統偏好,開始挖掘相關關系的好處時,一個用數據預測的時代才會到來。
業務層可以實現豐富的數學方法、挖掘算法,常用的介紹如下。
(1)聚類算法
企業級應用中的大數據分析經常用到聚類算法,比如針對某些特征對用戶群體進行劃分,如按照用戶標簽對預測其偏好類別,淘寶商鋪將用戶在一段時間內的購買情況劃分成不同的類。聚類方法有許多種,例如基于球鄰域的空間劃分、仿生模式識別、視覺分類方法等。
(2)回歸分析
預測對于企業的意義比較深遠,回歸分析是進行大數據預測的有效方法。回歸分析用函數表達式的形式,反映了值與值、屬性與屬性之間的相互關系。當人們最大似然地獲得了其中的關系,就可以用其中一部分數據來預測另一部分數據。在市場營銷的很多方面都可以運用到回歸分析,例如可以通過回歸分析對當月的銷售規律進行挖掘,從而預測出下個月的趨勢,進而做相應的策略上的變更或保障。
(3)神經網絡
神經網絡是一種人工智能技術,其優勢在于處理非線性以及那些以模糊、不完整、不嚴密的知識或數據為特征的問題。隨著數據的增長與發展,企業中非結構化數據呈爆發增長趨勢,而神經網絡在分析這類數據上有著天然的優勢。神經網絡具有分布存儲和高度容錯等特性,與大數據架構不謀而合,因此部署神經網絡算法來解決數據挖掘的問題成為企業很好的選擇。典型的神經網絡為三大類:第一類是前饋式神經網絡模型,其特征是分類預測和模式識別;第二類是反饋式神經網絡模型,擅長聯想記憶和優化算法;第三類是自組織映射方法,在聚類方面有較好的應用。
業務層的方法是十分豐富的,企業在構建自己的大數據平臺時,不應局限于個別幾類方法,而是需要充分挖掘和匯聚不同方法的潛能,使得統計和預測的結論以更大的概率接近實施情況,從而真正體現企業的數據價值。
4 結束語
數據是資源已經成為共識,如何獲取數據、挖掘數據、盤活數組資源,成為每個企業都需要深度思考的問題。
在反饋經濟中,數據是一面鏡子,企業通過數據了解客戶,了解自身,洞悉整個行業乃至整個產業生態環境,對未來發展有更充分的把握。 工欲善其事,必先利其器。做好企業的運營,大數據平臺是利器。隨著大數據各領域技術的日臻成熟,選擇適合自身發展的技術是要解決的當務之急。存儲、計算、業務的策略是使用者需要考慮的重中之重,是大數據系統得以協調運作的基礎。好馬配好鞍,滿足需求的硬件配置,也是不容忽視的剛性條件。相信只要把這些關鍵環節的工作做到位,大數據給企業帶來的可預見的增益就近在咫尺了。
1 張寧,賈自艷,史忠植.數據倉庫中的ETL技術的研究.計算機工程與應用,2002,38(24):200~211 Zhang N,Jia Z Y,Shi Z Z.Research on technology of ETL in data warehouse.Computer Engineering and Applications,2002,38(24 ):200~211
2 董翔英.SQL Server基礎教程.北京:科學出版社,2005 Dong X Y.Beginning SQL Server for Developers.Beijing:Science Press,2005
3 陶冶,范玉順,羅海濱.分布式工作流系統的可靠性研究.計算機科學,2001,28(5):6~10 Tao Y,Fan Y S,Luo H B.Research on the reliability of distributed workflow system.Computer Science,2001,28(5):6~10
4 Baru C,Bhandarkar M,Nambiar R,et al.Big data benchmarking.Proceedings of the 2012 Workshop on Management of Big Data System of ACM,San Jose,CAL,USA,2012:39~40
5 Rogers Y,Sharp H,Preece J.Interaction Design:Beyond Human-Computer Interaction.West Sussex:Wiley,2011
6 羅軍舟,金嘉暉,宋愛波等.云計算:體系架構與關鍵技術.通信學報,2011,32(7)Luo J Z,Jin J H,Song A B,et al.Cloud computing:architecture and key technologies.Journal on Communications,2011,32(7)
7 王勁.大數據時代的管理變革.中國商貿,2013(2):189~190 Wang J.Management revolution in big data era.China Business & Trade,2013(2):189~190
8 崔杰,李陶深,蘭紅星.基于Hadoop的海量數據存儲平臺設計與開發.計算機研究與發展,2012(49)Cui J,Li T S,Lan H X.Design and development of the mass data storage platform based on Hadoop.Journal of Computer Research and Development,2012(49)
9 張輝,趙郁亮,徐江等.基于Oracle數據庫海量數據的查詢優化研究.計算機技術與發展,2012,22(2)Zhang H,Zhao Y L,Xu J,et al.Query optimization research on mass of data based on Oracle database.Journal of Computer Research and Development,2012,22(2)
10 李成華,張新訪,金海.MapReduce:新型的分布式并行計算變成模型.計算機工程與科學,2011,33(3)Li C H,Zhang X F,Jin H.MapReduce:a new programming model for distributed parallel computing.Computer Engineering and Science,2011,33(3)
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年4期)2022-06-05 07:53:30
當代水產(2022年1期)2022-04-26 14:34:58
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
當代水產(2021年5期)2021-07-21 07:32:44
當代水產(2021年4期)2021-07-20 08:10:14
云南畫報(2020年9期)2020-10-27 02:03:26
