基于PowerPC的主動雷達信號處理軟件的設計與實現
2015-02-22 03:05:01王亞莉童衛勇呂衛祥姜小祥
雷達與對抗 2015年4期
關鍵詞:程序
王亞莉,童衛勇,呂衛祥,姜小祥
(1.91404部隊,河北 秦皇島 066001;2.中國船舶重工集團公司第七二四研究所,南京211153)
基于PowerPC的主動雷達信號處理軟件的設計與實現
王亞莉1,童衛勇2,呂衛祥2,姜小祥2
(1.91404部隊,河北 秦皇島 066001;2.中國船舶重工集團公司第七二四研究所,南京211153)
摘要:介紹了PowerPC處理器的主要特點,設計并實現了基于PowerPC平臺的主動雷達信號處理算法軟件。通過引入局部性原理對PowerPC的存儲器山分析,改善了軟件的時間和空間局部性,優化了軟件的性能,提高了軟件運行的實時性。
關鍵詞:雷達;信號處理;PowerPC8640D;局部性原理;存儲器山
0引言
近年來,隨著電子技術迅猛發展,各種高性能器件如DSP、FPGA、CPU等的不斷涌現和更新換代,使得雷達信號處理從專用硬件的開發轉向基于通用平臺的軟件開發。現代雷達的發展需要對高速海量的數據進行實時的傳輸和處理,而串行RapidIO(SRIO)是當前主流的數據傳輸方式。PowerPC處理器很好地提供了對SRIO的支持,同時其多核機制可以實現海量數據的并行快速處理。另一方面,VxWorks是應用最為廣泛和可靠的實時操作系統。因此PowerPC處理器和VxWorks操作系統的搭配為雷達信號處理提供了很好的軟件化處理平臺。
本文將基于PowerPC8640D處理器設計實現主動雷達的信號處理算法,并就8640D的存儲器山模型分析對算法軟件進行優化改進,從而實現對雷達回波信號的實時處理。
1PowerPC處理器的特點
1.1 PowerPC8640D處理器簡介
FreeScale公司研發的PowerPC8640D/8641D處理器是目前最為先進的處理器,其內部集成兩個e600內核。每個內核的工作主頻最高可達1.5 GHz。內核集成兩個32 KB一級緩存和一個1 MB的二級緩存。另外,e600內核還具有強大運算能力的AltiVec矢量處理引擎。e600通過MPX總線與系統總線進行通信,其中高速千兆網接口、高速SerDes接口提供了對PCI-E和SRIO的訪問支持,以獲取高速的數據傳輸能力、集成的雙內存控制器可實現對內存的低延遲、高帶寬訪問等[1-2]。PowerPC8640D處理器內核組成框圖如圖1所示。
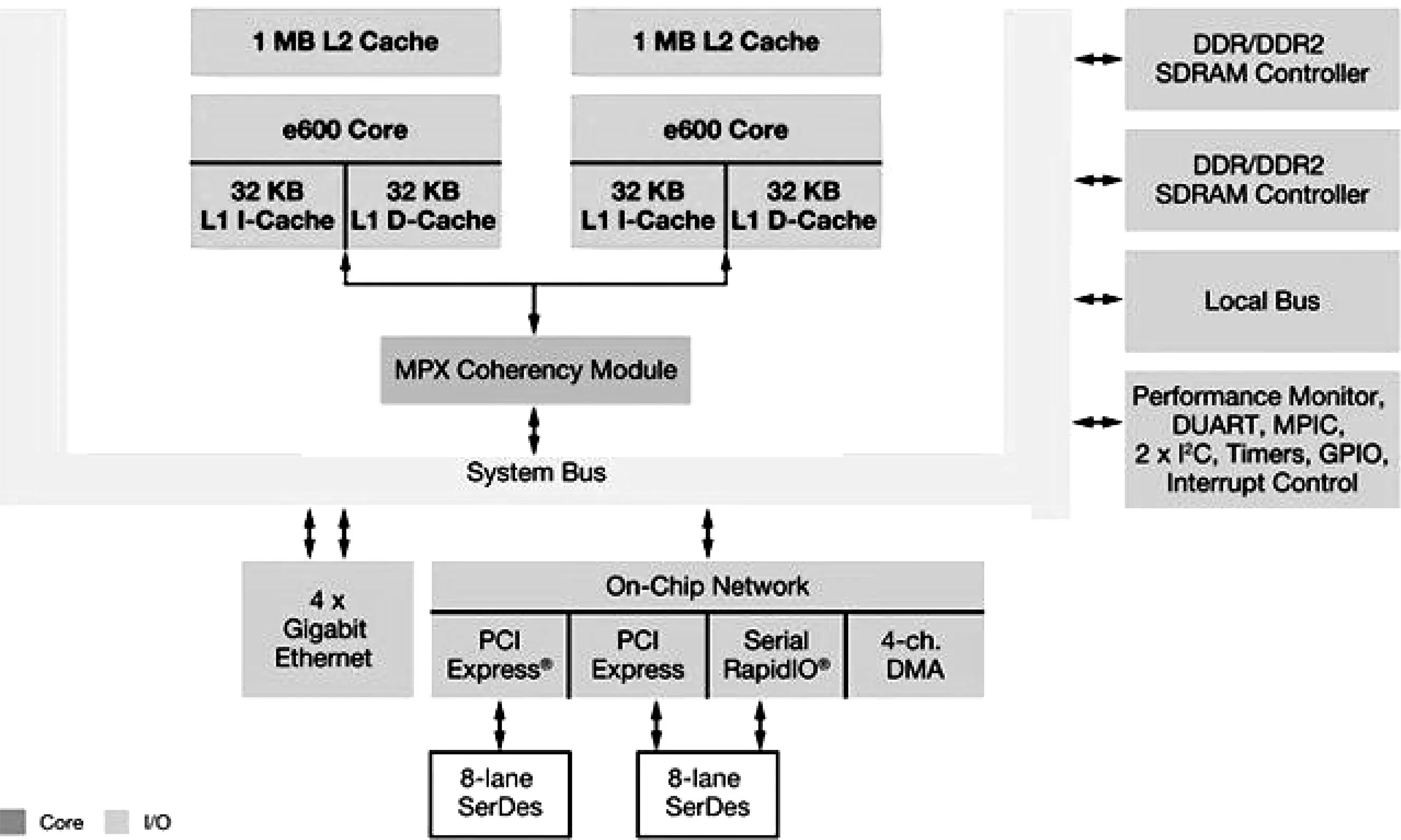
圖1 PowerPC8640D處理器內核組成框圖
作為嵌入式處理器的典型代表,PowerPC在雷達信號處理領域不僅提供了比Intel、AMD系列處理器更低的功耗以及對SRIO高速串行接口更好的支持,而且在算法編程方面給予了DSP和FPGA所不具有的靈活性,從而在節約了研發成本的同時縮短了研發周期、降低了軟件升級維護難度。此外,PowerPC處理器有著對實時操作系統VxWorks的強大兼容性。因此,在雷達這種強實時、高速數據率的系統中,PowerPC處理器具有更好的適應性和應用前景。
1.2 PowerPC8640D存儲器山
一個高性能的程序應該具有良好的局部性。它傾向于引用鄰近于其最近引用過的數據項,或者最近引用過的數據項本身。這種傾向性被稱為局部性原理[3]。局部性原理主要有兩種不同的形式:時間局部性和空間局部性。時間局部性是指在一定的時間內重復訪問同一個地址的次數越多程序的時間局部性越好。空間局部性表現為如果程序兩次訪問的地址越接近,則程序的空間局部性越好。局部性原理對硬件和軟件系統的設計和性能有著極大的影響。
計算機的存儲器系統通常設計成一個存儲器層次結構,從最高層的寄存器到高速緩存再到內存以及最底層的硬盤。各層次存儲器的容量越來越大,訪問速度越來越慢,成本越來越低。存儲器層次結構的運行策略就是盡量讓當前被頻繁訪問的存儲區和其臨近元素的內容駐留在較高層存儲器,而把不常訪問的存儲區的內容置換到較低層存儲器。因此,一個具有良好的局部性的程序要盡可能地適應存儲器層次結構,也就是盡可能地訪問高層的存儲器,享受到最高的訪問速率,從而提高程序運行效率。
筆者通過編寫一個測試分析程序來研究存儲器層次結構對程序的運行效率的影響。測試程序以不同的步長掃描固定長度數組中的不同大小元素集合即工作集,從而測試數據的吞吐率,最后采用K次最優測量方法得到最優測試結果。測試函數中數據的大小和步長控制產生讀序列的局部性程度。數據越小,得到的工作集越小,時間局部性越好。步長的值越小,空間局部性越好。以不同的時間局部性(工作集大小)和空間局部性(訪問步長)對存儲器進行訪問,就能得到存儲器系統在不同的局部性下的性能(即訪問速率),從而得到一個讀帶寬的時間局部性和空間局部性的二維函數,即圖2所示PowerPC8640D的存儲器山模型。
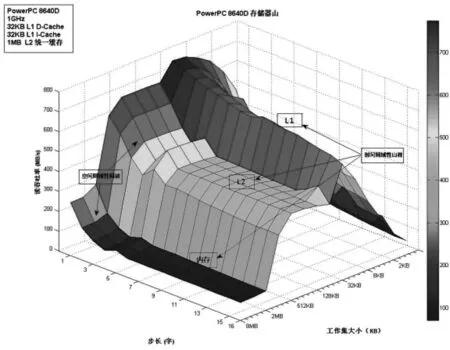
圖2 PowerPC8640D存儲器山模型
存儲器山以工作集大小的變量為x軸,訪問步長的變量為y軸,存儲器訪問速率為z軸。它看起來像一座有著山峰、山脊和山坡的小山,垂直于工作集軸的是3條山脊,分別對應于工作集完全在L1高速緩存、L2高速緩存和主存內的時間局部性區域。重點觀察L2和主存山脊。在L2和主存山脊上隨著步長的增加有一個空間局部性的斜坡,此時意味著程序空間局部性的下降。顯然,盡可能地讓工作集位于高速緩存中,程序的運行速度比工作集位于主存中優勢明顯。然而,當工作集太大不能全部工作在高速緩存時,主存山脊的最高點也比它的最低點高了將近3倍。因此,不難發現,當程序的時間局部性很差時,利用好空間局部性仍然可以補救時間局部性帶來的性能損失。
2信號處理軟件的實現
信號處理軟件運行于一個PowerPC處理器,通過RapidIO協議接收雷達數據,信號形式為每個脈組脈沖數為8個、重復周期為1000 μs的I、Q正交數據。算法流程如圖3所示。

圖3 主動信號處理算法流程圖
(1) 脈沖壓縮
脈壓主要采用頻域卷積法,將脈壓系數和I、Q數據進行FFT后再IFFT實現。
(2) MTI
由于一個脈組含8個脈沖組成,因此采用多階FIR高通濾波器來實現MTI,在設計好高通濾波器后,將脈組內主觸發的I、Q數據與濾波器參數數組復數值進行乘累加運算即可完成動目標處理;
(3) 模值運算
為了計算雷達回波的幅度值需要對I、Q數據進行線性檢波的模值運算,即求得I、Q信號的平方和后再進行開方運算。
(4) 視頻積累
當不選擇MTI處理時,模值運算后對脈組內脈沖求和后對積累系數做除法得到的商即為視頻積累的結果。
(5) CFAR
常用的CFAR算法是兩側單元平均選大法恒虛警GOCA-CFAR,即分別計算主觸發保護單元左、后兩側的快門限和,再將兩側快門限和選大的結果取平均后與CFAR系數相乘,其結果與輸入脈沖的對應距離單元的模值比較,若大于輸入脈沖值則輸出0,反之輸出值為脈沖當前距離單元值。
雷達數據以脈組(一個脈組共8*1000=8000 μs)形式傳輸。當算法選擇MTI處理時,此時不需要視頻積累。經耗時測試,平均每個脈組信號處理耗時3880 μs(<8000 μs),滿足系統實時性要求;而不選擇動目標處理時則需要視頻積累,此時平均每個脈組處理耗時6010 μs(<8000 μs),同樣滿足系統實時性要求。考慮到功能升級的需要,有必要對軟件進行改進和優化。
3軟件的優化
根據Amadahl定律,要提高整個算法的運行速度,必須首先提高對運行速度影響最大的那部分程序運算速度[3]。由于本算法中MTI處理和視頻積累作為可選模塊,而CFAR則作為必選處理,同時經測試CFAR執行耗時668 μs,算法耗時占比較大,因此有著較大的優化空間。本軟件中CFAR算法采用GOCA-CFAR[4],其基本原理如圖4所示。
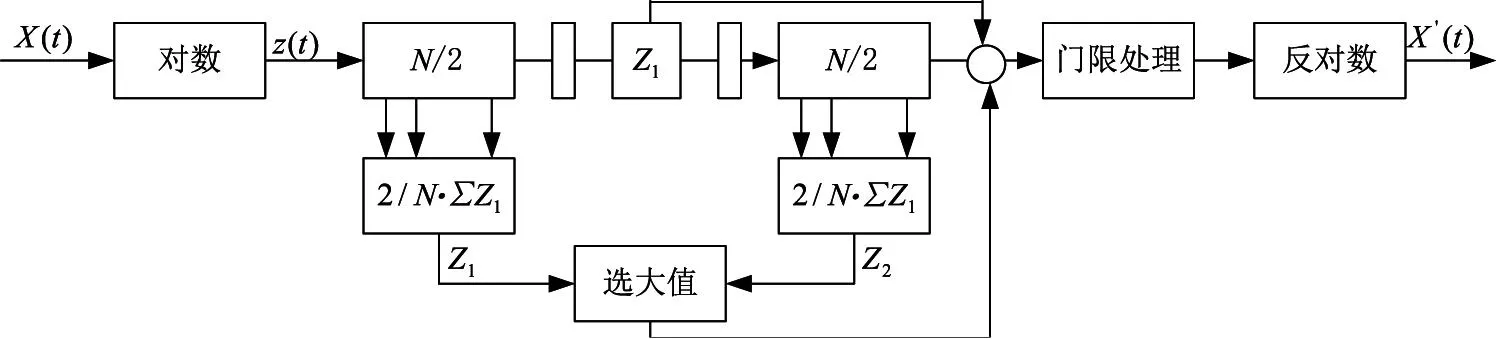
圖4 兩側單元平均選大恒虛警率原理框圖
算法設定平均單元數為16個,保護單元數為左右各1個,平均單元和的計算可采用兩種方法:其一使用傳統方法逐個相加,其二使用滑窗相減技術。使用傳統方法求和,此方法簡單直觀,但存在著冗余計算,其時間復雜度為O(mn),其中n為距離單元個數,m為相加的平均單元數;若采用滑窗相減方法,第i個單元zi的平均單元距離和s0,緊鄰后續單元zi+1的前后距離單元和可以用結果s0加上第i+16+1的距離單元值減去第i-16的距離單元值,后續單元的和以此類推。
相比傳統方法,滑窗相減法減少了計算量,其時間復雜度為O(n),運行效率提高了m倍。但是,采用滑窗相減法需要一直計算左右單元和,程序的時間局部性,空間局部性并不理想,緩存的命中率比較低,仔細觀察不難發現,第i個單元的右側和變成了其滑過16+1個單元后的第i+16+1個單元的左側和。因此,可以對滑窗相減法進行改進,從第1個單元開始,程序將滑窗法計算過右側的和存儲到一個平均和數組中,當計算到第i+16+1個單元的左側平均單元和即是平均和數組中的第1個值,而第i+16+1個單元右側的和則繼續用滑窗相減計算,并存到平均和數組中,供后面的計算左側平均單元和時直接調用。
相比滑窗相減法,改進后的算法通過對平均和數組的調用即可完成相應左側平均單元和的賦值,從而算法只需順序訪問右側的平均單元即可完成右側和計算,并存入平均和數組中作為后續的左側平均和使用。顯然,改進后滑窗相減法的工作集大小減半,不需頻繁訪問左右兩側數據,提高了緩存命中率,其時間局部性和空間局部性都得到了明顯的改善,運行效率又提高了將近一倍。通過測試,優化改進后的CFAR算法耗時158 μs,相比優化前提高了將近5倍,軟件的性能得到了顯著的提高。
4結束語
本文針對PowerPC處理器的主要特點,實現了一個基于PowerPC平臺的主動雷達信號處理典型流程的算法軟件設計,并對PowerPC8640D存儲器山進行建模分析。通過對算法的優化,改善了程序運行的局部性,提高了軟件運行的效率,從而為后續在PowerPC平臺上進行實時信號處理算法的優化設計提供了新的思路。
參考文獻:
[1]e600 PowerPC Core Reference Manual[Z].FreeScale Rev.0,2006.
[2]MPC8641 and MPC8641D Integrated Host Processor Hardware Specifications[Z].FreeScale,2008.
[3]Randal E Bryant,David O’Hallaron.深入理解計算機系統[M].北京:中國電力出版社,2004.
[4]Merrill I Skolnik.雷達手冊[M].北京:電子工業出版社,2010.
※※※※※※※※※※※※※※※※※※※※※※※※※
Design and implementation of signal processing software
based on PowerPC for active radar
WANG Ya-li1, TONG Wei-yong2, LU Wei-xiang2, JIANG Xiao-xiang2
(1.Unit 91404 of the PLA Navy, Qinhuangdao 066001, China;
2. No.724 Research Institute of CSIC, Nanjing 211153)
Abstract:The main characteristics of the PowerPC processor are introduced, and the signal processing algorithm software is designed and implemented based on the PowerPC platform for the active radar. The memory mountain of the PowerPC is analyzed by introducing the principle of locality, improving temporal and spatial locality and real-time operating capability of the software, and optimizing the software performance.
Keywords:radar; signal processing; PowerPC8640D; principle of locality; memory mountain
中圖分類號:TN311.52
文獻標志碼:A
文章編號:1009-0401(2015)04-0064-04
作者簡介:王亞莉(1973-),女,高級工程師,研究方向:雷達工程和雷達數據處理;童衛勇(1981-),男,工程師,碩士,研究方向:數據處理;呂衛祥(1975-),男,研究員,工程碩士,研究方向:雷達總體及信號處理;姜小祥(1984-),男,工程師,碩士,研究方向:雷達信號與數據處理。
收稿日期:2015-06-11;修回日期:2015-07-17
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
