自然語言的計算機處理模型
2015-02-07 07:49:28容聯七陌科技有限公司張志新
電子世界 2015年15期
容聯七陌科技有限公司 張志新
自然語言的計算機處理模型
容聯七陌科技有限公司 張志新
目前在自然語言理解方面的研究程度并不深,始終停留在讓計算機正確理解語言信息上,在自然語言理解的研究上主要有基于規則的語義處理方法和基于語料庫的統計方法兩種,雖然這兩種方法獲得了一些成績,但是二者均需要依賴可靠的語言知識對計算機進行驅動,從而對自然語言進行處理,因此,后臺語言知識的重要性可見一斑。本文主要基于以上內容,提出了粗淺的自然語言處理模型,并針對后臺語言知識庫的建立以及文章知識提取等方面展開了一系列的分析,希望本文的分析可以為同行的研究帶來一些參考。
自然語言;計算機處理;模型
自然語言的計算機處理涉及到多種學科和多個研究領域,其主要研究力量由語言學、數學以及計算機科學等不同學科的研究人員組成,近年來隨著科學技術的快速發展,計算機功能從數值計算逐漸發展為數值計算和信息處理并重的一種狀態。實際上自然語言處理就是對怎樣使計算機理解并生成人們日常需要的進行研究,同時利用對話的方式對人提出的問題進行回答。自然語言處理的目的在于建立起在人和機器之間形成的友好關系,對信息進行高度的傳遞與認知,鑒于此,本文結合筆者的實際工作經驗,針對自然語言的計算機處理模型展開分析,相信一定可以為大家帶來一些啟示。
1 自然語言概述
通常情況下我們所說的計算機理解了一些事情,主要是指計算機將一些表現形式轉換成了另外一種表現形式,也可以說將事件的自然語言表現形式轉換成了計算機能理解的表現形式,這就是目標語言。之所以自然語言在理解上存在一定困難,主要原因可以從以下幾方面進行分析:首先,目標表示的復雜性。例如要想從語句中將關鍵字提取出來非常復雜,同時還要了解很多相關與客觀世界相關的知識。其次,映射的類型。從源語言到目標語言的映射,理想中是一對一類型的映射,但是現實中很難達到一對一的要求。第三,成分的交互程度。語言中每個語句都需要由多個成分組成,如果每個成分的映射都與其成分沒有直接關系,那么映射的過程就會變得非常簡單,但是非常遺憾,自然語言中的成分存在非常高的交互程度,往往將句子中一個成分改變了,其整體結構就會大大改變,從而大大增加映射的復雜程度。目前計算機還遠遠沒有的阿道人一樣的理解水平,相信將來也不會達到這樣的水平,所以應該從實用的角度去判斷計算機對自然語言的理解,只要計算機能夠實現人機會話,或者能夠自動摘錄一些語言信息,那么我們就可以說計算機已經具有了自然語言的能力。
2 自然語言的計算機處理模型
2.1 漢語理解系統模型
漢語理解系統模型主要包括分詞與詞性標注子系統、句子成分劃分子系統、代詞指代子系統、漢語理解子系統幾部分,本系統模型需要建立知識網作為自然語言語義描述上的理論,同時依賴可靠的語言知識驅動計算機對自然語言進行正確處理,這就需要建立起體現知識網理論的詞庫,還要對文章中的信息進行提取,了解每句話所反映的知識,將這些知識提取出來以后,系統會為文章建立語境,從文章中提取有助于理解的信息,完成這些步驟以后,初步的語義提取已經完成。
2.2 知識庫設計
因為漢語獨特的性質及使用習慣,計算機漢語理解非常依賴于語境分析,這就不可避免的要建立知識庫,知識庫中知識的表達方式以及知識的覆蓋范圍都會對系統運作及分析效果產生影響,這種情況下建立知識庫的關鍵在于知識顆粒的大小以及表示方法。知識的表達方式將會直接影響到知識庫的內容及使用方式,由此可見知識庫設計是整個系統成敗的關鍵所在。
2.2.1 知識網理論介紹
知識網是一個以漢語和英語詞語所代表的概念作為描述對象,用來揭示概念之間存在的屬性關系,以這種關系為基本內容的常識知識庫。要想利用好知網系統,首先需要對知網系統的哲學思想進行了解,從知網哲學的觀點來看,世界上所有事物都在特定的空間和時間中發生著變化,一般來說會從一種狀態轉變成為另外一種狀態,主要利用屬性值的改變來實現。知網運算及描述的基本單位是萬物,主要包括物質及精神兩類,值得一提的是,部件與屬性這兩個單位在知網哲學中占據著非常重要的地位,漢語中用擬人的方式來描述部件,其他語言也是如此,直接反映出了人類對事物認識方法的共性,此外,知網還規定在標注屬性值時一定要標注出它指向的屬性。
2.2.2 知網類庫的設計
知網理論主要通過對客觀世界的概念對知識進行描述與分類,概念和概念之間存在著一定的聯系,這些關系在全局中是一個樹型的結構,在不同概念中,都會有相應的概念對其進行描述,對于一種具體的知識來說,知網對其描述主要采用類+屬性的方式進行表示。在知網理論中,每一類概念都有相應的屬性,概念之間又存在直接的關系,因為出于對易擴展性的考慮,通常情況下會采用面向對象的程序設計愛思想來實現知網理論。在現實中知網理論和程序的實現之間是一一對應的關系,往往一個知網概念對應程序中的一個類,而概念屬性主要對應類中的成員變量。因為受到多種因素的影響,現在對知網類庫的設計始終不是很完善,加上自然語言內容比較大,知網理論提出了一種相對來說比較實用的描述方法,從目前的情況來看,知網理論中還有很多地方需要完善。因此,為了滿足未來的擴充及更好的對上層應用進行支持,知網類庫設計中易維護性得到了高度的重視。
2.2.3 知網詞庫設計
要想實現知網類庫對文章的處理,應該以知網類庫為基礎對知網詞庫進行構造,這樣才能使文章理解的需求得到滿足。例如“醫生”這個詞,作為“人”來理解時,那么其“word class”字段應該是“hownnet Class.thing.Humanbeing”,由于醫生的活動中包含“醫治”,這時“init property”字段應填“canSubject=cure”。在生成對象時,醫生與其他人類的對象是不一樣的。在實現過程中需要我們對目前的需求進行考慮,因此采用jdatastore數據庫。
2.2.4 知識庫目前提供的功能支持
實際上知識庫只是語言計算機表達的一種形式,其本身并不能提供分析文章的具體算法,但是可以針對上層分析提供很好的語言知識上的支持,這樣分析起來會更加容易,現階段知識庫對上層分析提供的功能支持主要有提供知識提取功能的支持、提供語義層面辨錯功能的支持、提供準確分詞功能的支持等。
2.3 知識的提取
知識庫建立起來以后,我們開始嘗試對文章知識進行提取,基本的思想是從文章中將知識提取出來,然后將其用對象的形式放在內存中,目前我們只能做到對文章表層知識的提取,也就是分析,了解文章中存在哪些實體,這些實體都做了怎樣的事情以及這些實體之間存在的關系。其具體設計是建立在知識庫建立的基礎上,不僅要對知識進行提取,同時還可以將其作為知識庫使用的例子(見圖1)。
利用句子構造器來接收數據,生成“句子實體”,在未來的運行中該實體可以作為一個整體來使用,利用句型判斷器來接收句子實體,對句子的句型進行判斷,按照句子實體的句型利用句型判斷器將其發給不同的解析器,利用其來提取句子實體中的知識,并將其結果存放在緩沖區中,分析句子之后緩沖區會生成實體對象,這就是提取的知識。在知識提取模塊中句子構造器非常簡單,只需要輸入并生成一個“句子對象”就可以,這里不做過多的說明。
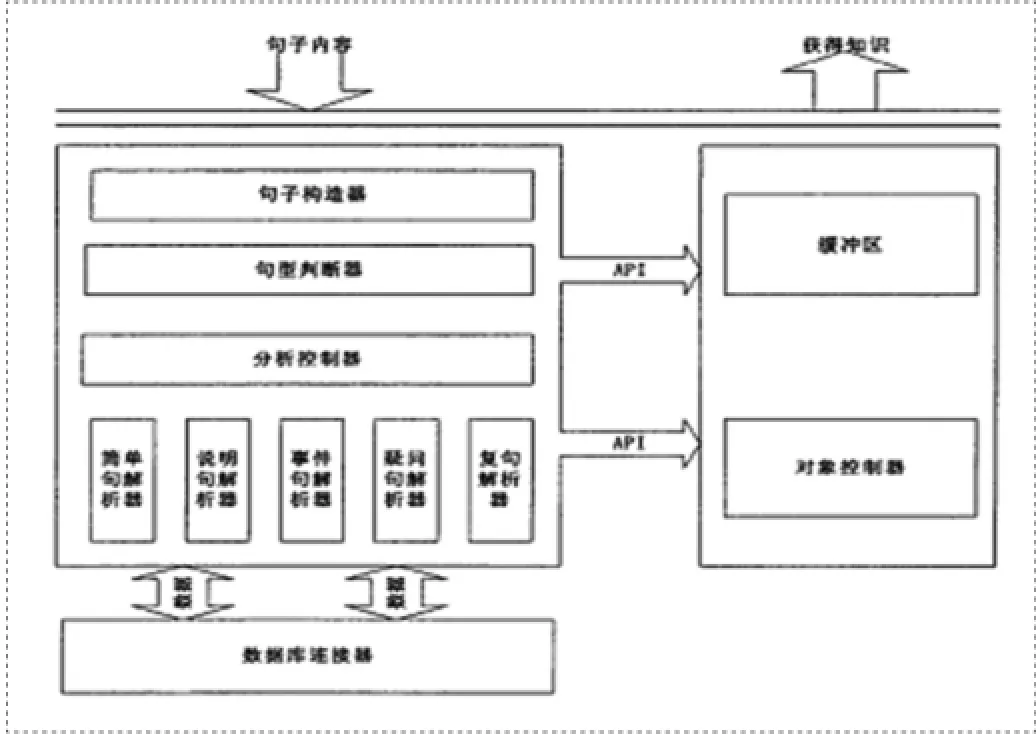
圖1 知識提取模塊框架圖
3 結語
綜上所述,本系統是針對計算機漢語理解的一種嘗試,在系統設計及實現過程中主要完成了知識庫設計與建立、文章知識提取等工作,但是目前該系統中還存在一些不足,例如知識庫設計并不完善,在上層知識提取的工作中,對知識的提取和分析工作做得不夠充分,對于一些問題的處理通常用較為常見的句子作為例子展開分析,其實用性上難免會受到一些限制,現在本系統是一個演示系統,在很多方面都存在著不足,因此程序健壯性還不夠。在這種情況下,希望在以后的工作中能夠積極克服上述不足,并有效提高知識庫的知識表示能力,從而更好的對文章展開知識提取與分析。
[1]葛瑋,吳佳.基于計算機智能識別技術的自然語言處理模型設計[J].無線互聯科技,2014(9):40.
[2]袁毓林,陳振宇,張秀松,李湘,周強,高嵩.從認知假設到計算分析和程序實現——一種認知語言學研究的計算范式與技術路線[J].當代語言學,2010(2):97-114+189.
[3]趙曉琴,孫毅中,薛曉蕾.基于知識單元的自然語言結構化解析模型—以城市規劃領域規則為例[J].測繪科學,2010(6): 110-113.
[4]李翠霞.現代計算機智能識別技術處理自然語言研究的應用與進展[J].科學技術與工程,2012(36):9912-9918.
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
文苑(2020年4期)2020-05-30 12:35:30
現代裝飾(2020年2期)2020-03-03 13:37:44
科技傳播(2019年22期)2020-01-14 03:06:34
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
消費導刊(2017年20期)2018-01-03 06:26:40
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
