基于特征加權張量分解的標簽推薦算法研究
2015-01-17 02:07:20孫玲芳馮遵倡
江蘇科技大學學報(自然科學版) 2015年6期
孫玲芳,馮遵倡
(1.泰州學院計算機科學與技術學院,江蘇泰州225300)
(2.江蘇科技大學計算機科學與工程學院,江蘇鎮江212003)
基于特征加權張量分解的標簽推薦算法研究
孫玲芳1,馮遵倡2
(1.泰州學院計算機科學與技術學院,江蘇泰州225300)
(2.江蘇科技大學計算機科學與工程學院,江蘇鎮江212003)
針對標簽推薦系統存在極度稀疏性的問題,通過提取標注過程的關鍵特征并計算元組的初始權重,構建加權元組集的張量模型;然后應用高階奇異值分解(high order singular value decomposition,HOSVD)對張量模型降維,根據處理結果作標簽推薦,從而達到提高推薦效率的目的;運用MovieLens數據集對基于特征加權張量分解的標簽推薦算法進行了模擬,實驗結果表明:基于特征加權張量分解的標簽推薦算法比傳統算法推薦效果更好。該方法能夠有效改善數據稀疏性問題,提高了推薦效率.
大眾標注;標簽推薦;張量分解;特征加權;高階奇異值分解
隨著WEB2.0的快速發展,網絡中社會標簽(Social Tags)數據越來越多,大量標簽數據處于無控制狀態,存在冗余性和概念上的模糊性等問題,影響了大眾標注系統的進一步發展.標簽推薦(tag recommendation)是大眾標注系統的重要應用之一,它能夠簡化標注過程,為用戶提供個性化的標簽并很好地控制數據的冗余性和模糊性[1].
為解決標簽推薦系統存在數據極度稀疏性的問題,張量分解方法越來越多地被應用到標簽推薦系統中.文獻[2]中首先將張量應用于社會標簽系統中,利用其能夠完整地表示高維數據并且能維持高維空間數據的本征結構信息等特點來進行標簽預測.文獻[3]中嘗試將K-means聚類與張量分解結合起來建立張量模型,既保證了數據初始聚合性又可以改善數據的稀疏性.然而,在現有國內外研究成果中,忽略了一些標注過程的重要特征.例如,用戶使用不同標簽的頻率體現了標簽在其心目中的重要程度;用戶標注不同資源的頻率體現了用戶的興趣大小.這些特征的忽略多少影響了推薦的個性化程度和準確度.
在此基礎上,文中介紹了一種基于特征加權張量分解的標簽推薦算法.首先提取標注過程中體現用戶興趣的重要特征進行加權,然后結合張量分解方法建立模型.在解決數據稀疏性問題的同時,提供更加準確和個性化的標簽推薦.最后以MovieLens數據集對該方法進行檢驗.
1 大眾標注與標簽
大眾標注(Folksonomy)又被稱作大眾分類、通俗分類,是在WEB2.0環境下伴隨標簽(Tag)技術的出現而產生的新型網絡信息組織方式.大眾標注允許用戶對網絡信息資源添加標簽以方便對其進行管理和組織,并且可以和他人共享標注[4].大眾標注不采用嚴格的分類標準,分類全部由用戶提交,分類的形成過程是完全自發的,因此具備:①平面化、非等級的類目結構;② 低成本的信息組織方式;③多維度揭示信息資源等優勢[5].隨著WEB2.0的發展,大眾標注以其獨特的優勢得到廣泛的研究和應用,國外著名網站有Del.icio.us,Flickr,CiteUlike等,國內較受歡迎的有新浪微博、豆瓣等.圖1給出了一則豆瓣電影標簽示例,網頁不僅包括電影基本信息,還顯示用戶常用的標簽以供其他用戶選擇.

圖1 豆瓣電影示例Fig.1 Example of movie.douban.com
與傳統結構的“用戶—資源”二元組關系不同,大眾標注包括3個重要組成部分,即用戶(User)、資源(Item)和標簽(Tag).標簽是用戶根據各自需求、偏好對感興趣資源的注釋,是用戶為資源添加的自定義關鍵詞[6].用戶可以為資源標注一個或者多個標簽,也可以看到網絡上的具有相同標簽的網絡資源,并以此建立與其他客戶更貼心的聯系和溝通.因此標簽體現出了群體的力量,它進一步增強了網絡資源之間的相關性和用戶之間的交互性,讓互聯網用戶接觸到一個更加多樣化的世界,一個關聯度更大的網絡資源.社會標簽是標簽的進一步延伸和擴展,當標簽在信息關聯中被大眾關注和使用時,標簽就具有了社會意義,從而轉化為社會標簽[7].
由大眾標注過程可以看出,標注過程主要涉及到4個方面的內容:資源、標簽、用戶以及三者之間的交互關系.因此將大眾標注形式化定義為一個四元組[7]:F(U,I,T,A),其中U為所有用戶的集合; I為所有資源的集合;T為所有標簽的集合,A?T ×U×I是T,U,I之間的交互關系,它是三元組(T,U,I)的集合,表示用戶u使用標簽t標注資源i.
2 標簽推薦及其分類
標簽推薦是大眾標注系統重要應用之一,它通過挖掘分析信息資源的內容、用戶的標注歷史等為待標注信息資源提供一系列高質量的標簽作為候選[8].目前國內外應用較為廣泛的標簽推薦技術主要分為兩類:基于協同過濾的標簽推薦和基于內容的標簽推薦.
2.1 基于協同過濾的標簽推薦
協同過濾是面向用戶行為的標簽推薦技術,是迄今最為成熟、應用最廣泛的推薦技術.它基于一組相似的用戶或項目進行推薦,根據相似用戶的偏好信息產生對目標用戶的推薦列表[14].根據考慮對象的不同,協同過濾算法又可以分為基于用戶的協同過濾和基于項目的協同過濾.
基于用戶的(User-based)協同過濾算法是根據與當前用戶相似的用戶信息預測產生對當前用戶的推薦標簽.它基于這樣一個假設:如果一些用戶對某一類項目的推薦結果比較接近,則他們對其他類項目的推薦結果也比較接近.首先查找與當前用戶相似的用戶,然后根據這些用戶的標簽信息去預測當前用戶的標簽信息.基于用戶的協同過濾算法核心在于用戶之間的相似度計算,常用方法有向量空間相似度和Pearson相關系數等[15].
基于項目的(Item-based)協同過濾是根據用戶對相似項目的推薦結果產生對當前項目的推薦標簽,它基于如下假設:如果用戶對相似項目的推薦結果相近,則用戶對當前項的推薦結果也會比較接近.基于項目的協同過濾算法核心在于項目之間的相似性計算,然后返回K個相似度最大的項目的標簽[16-17].
以基于用戶的協同過濾為例,協同過濾算法的計算過程如下:
1)獲取用戶ua和用戶us評價過的相同項目,即兩個項目集的交集,定義為項目集合Ia,s.
2)在Ia,s中,計算目標用戶ua和用戶us之間評分向量的相似度Sa,s.常用的相似度度量公式有以下3種[13]:
余弦相似度

相關性相似度,即Pearson相關系數

式中,Ra,Rs分別為用戶ua和us對已評價項目的評分均值.Jaccard相關系數

式中,Ia和Is分別為用戶ua和us評價過的項目.Jaccard相關系數的計算就是用兩個用戶共同評價過的項目總數除以兩個用戶分別評價過的項目數的總和.
3)重復進行第1步和第2步,直至得到ua和所有用戶的相似度集合Sa,并使用Top-N方法得到最臨近集合UN.
4)預測用戶ua可能對未評價項目ij的評分,公式如下:

式中,Uj為評價過項目ij的用戶集合.
5)重復上一步,直至得到用戶ua對所有未評價項目的預測值集合Pa.然后采用Top-N方法,從集合Pa中選取前N個最高評分的項目推薦給用戶.
協同過濾推薦的優點,如非結構化信息處理、個性化推薦以及自動化程度高等.但同時也暴露了一些缺點,如稀疏性問題、冷啟動問題、實時性問題等[12].
基于內容的標簽推薦是標簽推薦的基本方法,是以文檔的內容作為標簽推薦的依據,一般使用文本內容,如新聞網頁、博客等.該方法通常包括3個步驟:首先提取文本內容特征建立模型,然后比較已有標簽與內容特征之間的相似度,得出有序的標簽推薦候選集,最后選出相似度最大的前N個標簽,推薦給用戶[7].
使用基于內容的方法作標簽推薦首先考慮內容特征粒度問題,即用什么粒度的特征來表示文本內容,作為標簽推薦的依據.
詞匯是一種表示文本內容的細粒度特征.當新的資源被提交時,推薦算法首先從文本內容中抽取關鍵詞,找出關鍵詞與已有標簽之間的相似度,根據相似度選擇前N個標簽推薦給用戶.關鍵詞和標簽的相關性計算有許多方法,最簡單直觀的是計算關鍵詞和標簽共同出現的次數占所有情況的比例.但是,由于標簽的稀疏性,直接使用該方法可能使得相似性無法計算.因此,使用改進的Google距離公式[8]計算描述詞和標簽的相關性.

式中:f(w),f(t)分別為關鍵詞和標簽在詞集和標簽集的并集中出現的次數;f(w,t)為關鍵詞和標簽同時出現在并集中的次數;N為并集總計詞數.
隱含主題是表示文本內容的粗粒度特征.在基于隱含主題的方法中,不再考慮單個詞匯與標簽之間的關系,而是將整個文本看作不同主題的混合,通過抽取文本與標簽集的主題特征,找出兩者之間的相似度,根據相似度,選擇前N個標簽推薦給用戶.應用最廣泛的是隱含狄利克雷分配模型(latent dirichlet allocation,LDA)[9].LDA模型最早是由Blei等人提出的無監督的概率圖模型,它將文本表示為K個隱含主題上的一個分布,而文本中的每個詞是由一個不可觀察的隱含主題生成,這些隱含主題則是從文本對應的分布中采樣得到.標準LDA模型的建模對象是文本中的詞,為把標簽引入LDA模型,同時建模文本資源的詞匯集和標簽集.文獻[8]中對Author-Topic模型作改進,提出了新的模型Tag Topic來進行標簽的推薦.標簽的概率計算如下: PTT(ti|Tr)=Σzj=1p(ti|zi=j)p(zi=j|(Tr∪Dr))=

3 基于特征加權張量分解的標簽推薦
3.1 計算元組的初始權重
在標簽推薦系統中,用戶的標注過程在一定程度上反映了用戶的興趣.注意到這樣兩個特征:用戶使用特定標簽進行標注的次數越多,表明用戶對此標簽的興趣越大;用戶對特定資源進行標注的次數越多,表明用戶對此資源的興趣越大.因此,用戶的興趣度就通過元組集中標簽和資源出現的頻率得以表現[10].據此特征為元組的初始權重進行加權計算,經過標準化處理之后,元組ti的權重T表示為:

式中:fu1(ti)為用戶u使用標簽ti的頻數;fu1為用戶u的標簽總頻數;fu2(ri)為用戶u標注資源ri的頻數;fu2為用戶的資源總頻數;0.5為調節因子.
坡度空間數據由DEM數據在ArcGIS 9.3中,通過Slope功能生成。曼寧系數空間數據利用ArcGIS 9.3將查閱文獻獲得的曼寧系數屬性數據(表1)與土地覆蓋類型空間數據相關聯生成。土壤飽和導水率與土壤儲水能力,通過結合土壤類型組成及其土壤剖面等屬性數據,借助于土壤水分運動參數模型RETC推導獲得,空間數據在ArcGIS 9.3下通過建立土壤水分運動參數與土壤類型空間數據之間的關聯生成。
3.2 初始三維張量的構建
基于用戶標注關系,根據加權三元組集(user,item,tag)構建三維張量A∈Ru×i×t,使用p表示三元組的初始權重,其大小代表二元組(user,item)對tag的喜好程度,使用u,t和i分別表示用戶、標簽和資源的字序標識.
3.3 張量分解和重構
對張量A進行高階奇異值分解,首先需要將張量進行矩陣展開,也就是將張量按照不同的維度(n-mode)重新排列成新的矩陣[11].文中張量為三維張量,因此根據定義將張量A的三個維度分別展開,可構成張量1-模、2-模、3-模展開式A1,A2,A3分別如下:

3.3.1 奇異值分解(SVD)
接下來對得到的展開矩陣分別作奇異值分解,通過奇異值分解,得到由矩陣An的奇異值組成的對角矩陣S(n).具體分解如下:

張量分解過程中,最重要的是矩陣的低秩逼近計算,即對矩陣An的奇異值進行刪減(保留前c個較大的奇異值,且滿足c<min{I1,I2},其中c可以通過實驗保留對角陣si(1≤i≤3)中原始信息的百分比來確定.低秩逼近能夠很好地過濾掉由小的奇異值引起的噪聲,從而達到降噪的目的.
3.3.2 高階奇異值分解
高階奇異值分解是奇異值分解(high order singulr value decomposition,HOSVD)[18]在張量中的推廣,張量的高階奇異值分解是指將張量分解成與其大小相同的核心張量和多個矩陣的乘積形式.本文中,將三維張量A高階奇異值分解表示為:

式中,核心張量S∈RIu×It×Ii是一個與張量A維數相同的正交張量,確定了實體user,item和tag之間的交互關系.S的數學表達式為:
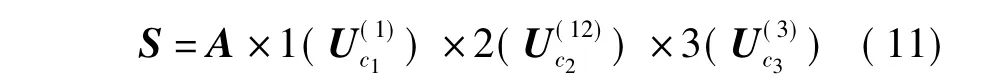
最后,由于張量數據中存在大量噪聲,張量A并不具備低秩性,需要通過HOSVD構造張量A的近似張量^A.重構張量^A的數學表達式如下:

4 實驗及結果分析
4.1 數據集
文中采用Mevie Lens標簽數據集進行模擬分析(表1).該網站是歷史最悠久的推薦系統,由美國明尼蘇達大學計算機科學與工程學院的GroupLens項目組創辦,是一個非商業性質的,以研究為目的的實驗性站點,主要用途是向用戶推薦他們感興趣的電影.該數據集包含37個用戶,671部電影及1 120個標簽,共2 287個標注元組.實驗過程中,將數據集劃分為訓練集和測試集,其中75%為訓練集,25%為測試集.

表1 部分Movie lens數據Table 1 Data from Movie lens
4.2 評估標準
文中采用準確率Precision和召回率Recall來評估推薦算法的準確性和有效性,這兩個評估指標定義如下:
準確率

式中,test和N分別代表測試集的大小和推薦的數目,準確率和召回率分別表示算法成功推薦的比率和待推薦項目被推薦的比率[3].可見,這兩個指標是沖突的,為尋找二者之間的平衡點,設定測度值F,F越大說明推薦效果越好:

式中,P和R分別為準確率和召回率.
4.3 結果分析
實驗過程中,為比較算法性能,文中采用經典的協同過濾算法進行對比,兩種方法采用相同的數據集和評估標準.計算初始權重時將調節因子設為0.5以避免出現負數或較小的數值,在作低秩逼近計算過程中,經過數次測試調節,將參數ci(1≤i≤3)分別設置為40,56,56.另外,按照數據集標簽的數量特征,實驗中top-N值分別取2,4,6,8和10進行對比分析,計算結果如表2,3,兩種算法性能比較如圖2.

表2 文中算法推薦結果Table 2 Recommended results in this paper

表3 協同過濾算法推薦結果Table 3 Recommended results of collaborative filtering algorithm

圖2 兩種算法性能比較Fig.2 Comparison of performances of two algorithms
綜上所示,文中介紹算法所得F值在不同top-N值時均比協同過濾算法要大,而且隨著N的增大,F值呈上升趨勢,文中推薦算法最大值可達到0.38,而協同過濾算法得到的最大值略高于0.29.由此可以看出,基于特征加權張量分解的標簽推薦算法比傳統算法推薦效果更好.
5 結論
大眾標注系統中的標注數據稀疏性非常嚴重,并且會時常出現缺失情況,張量分解是用來解決數據稀疏性問題的常用手段,但是由于算法相對復雜,處理稀疏性和缺失值的效果不甚理想.另外,傳統張量分解算法對所有元組數據均一視同仁,采用相同的初始權重值,無法有效區分用戶標注的重要特征.
文中的基于特征加權的張量分解算法,提取用戶標注的重要特征,在張量分解算法基礎上對元組初始權重進行改進,通過不同權重值反映用戶的興趣所在;同時使用相同數據集和評估標準與經典協同過濾算法推薦結果進行了比較,實驗結果表明基于特征加權張量分解的標簽推薦算法的推薦效果更好.
References)
[1]許棣華,王志堅,林巧民,等.一種基于偏好的個性化標簽推薦系統[J].計算機應用研究,2011,28 (7):2573-2579.Xu Dihua,Wang Zhijian,Lin Qiaomin,et al.Personalized tag recommendation system based on preferences[J].Application Research of Computers,2011,28 (7):2573-2579.(in Chinese)
[2]Symeonidis P,Nanopoulos A,Manolopoulos Y.Tag recommendations based on tensor dimensionality reduction[C]∥Proceedings of the 2008 ACM Conference on Recommender Systems.New York,NY,USA:ACM,2008: 43-50.
[3] 孫玲芳,李爍朋.基于K-means聚類與張量分解的社會化標簽推薦系統研究[J].江蘇科技大學學報(自然科學版),2012,26(6):597-601.Sun Lingfang,Li Shuopeng.Social tagging recommendation system based on K-means cluster and tensor decomposition[J].Journal of Jiangsu University of Science and Technology(Natural Science Edition),2012,26(6):597-601.(in Chinese)
[4] 喬綠茵,張敏.我國基于Folksonomy的標簽推薦方法研究綜述[J].信息資源管理學報,2012(4):41 -46.Qiao Lvyin,Zhang Min.Review of tag recommendation method on folksonomy in China[J].Journal of Information Resources Management,2012(4):41-46.(in Chinese)
[5] 余金香.Folksonomy及其國外研究進展[J].圖書情報工作,2007,51(7):38-74.Yu Jinxiang.Folksonomy and related research progress in some advanced countries[J].Library and Information Service,2007,51(7):38-74.(in Chinese)
[6] 吳思竹.社會標注系統中標簽推薦方法研究進展[J].圖書館雜志,2010,29(3):48-52.Wu Sizhu.Research on tag recommendation methods in the social tagging system[J].Library Journal,2010,29(3):48-52(in Chinese)
[7]劉志麗.基于內容的社會標簽推薦技術研究[D].哈爾濱:哈爾濱工程大學,2012.
[8] 靳延安,李玉華,劉行軍.不同粒度標簽推薦算法的比較研究[J].計算機應用研究,2012,29(2): 504-509.Jin Yan'an,Li Yuhua,Liu Xingjun.Comparative research on different grain-based tag recommendation algorithm[J].Application Research of Computers,2012,29(2):504-509.(in Chinese)
[9]司憲策.基于內容的社會標簽推薦與分析研究[D].北京:清華大學,2010.
[10] 叢維強.基于數據倉庫和語義分析的社會標簽推薦技術研究[D].江蘇鎮江:江蘇科技大學,2014.
[11] 李貴,王爽,李征宇等.基于張量分解的個性化標簽推薦算法[J].計算機科學,2015,42(2):267-273.Li Gui,Wang Shuang,Li Zhengyu,et al.Personalized tag recommendation algorithm based on tensor decomposition[J].Computer Science,2015,42(2): 267-273.(in Chinese)
[12]王金輝.基于標簽的協同過濾稀疏性問題研究[D].合肥:中國科技大學,2011.
[13] 萬朔.基于社會化標簽的協同過濾推薦策略研究[D].成都:電子科技大學,2010.
[14] 張兵.基于標簽的協同過濾推薦技術的研究[D].杭州:浙江大學,2011.
[15]Symeonidis P,Nanopoulos A,Manolopoulos Y.A unified framework for providing recommendations in social tagging systems based on ternary semantic analysis[J].IEEE Transactions on Knowledge and Data Engineering,2010(22):1-14.
[16]Sarwar B,Karypis G,Konstan J et al.Item-based collaborative filtering recommendation algorithms[C]∥Proceedings of the 10th International Conference on World Wide Web.New York:ACM,2001:285-295.
[17]Linden G,Smith B,York J.Anlazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[18]Harvey M,Baillie M,Ruthven I,et al.Tripartite hidden topic models for personalised tag suggestion[M]∥Advances in Information Retrieval.Berlin Heidelberg: Springer,2010:432-443.
[19]Jaschke R,Marinho L,Hotho A,et al.Tag recommendations in folksonomies[M]∥Knowledge Discovery in Databases:PKDD 2007.Berlin Heidelberg: Springer,2007:506-514.
[20]Lee S O K,Chun A H W.A web 2.0 tag recommendation algorithm using hybrid ANN semantic structures[J].International Journal of Computers,2007,1:49 -58.
(責任編輯:童天添)
Tag recommendation algorithm based on feature weighting and tensor decomposition
Sun Lingfang1,Feng Zunchang2
(1.College of Computor Science and Technology,Taizhou University,Taizhou Jiangsu 225300,China)
(2.School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang Jiangsu 212003,China)
Aiming at the problem that the tag recommendation system is extremely sparse,the tensor model of weighted tuble set is constructed by extracting the key features of the tagging process and calculating the initial weights of the elements;Then,we use the high order singular value decomposition(HOSVD)to reduce the dimension of the tensor model,So that it can improve the recommendation efficiency;The MovieLens data set is used to simulate the tag recommendation algorithm based on feature weighting tensor decomposition.The experimental results show that the tag recommendation algorithm based on feature weighting tensor decomposition is better than the traditional algorithm.The proposed method can effectively deal with the data sparsity problem and improve the recommendation effect.
folksonomy;tag recommendation;tensor decomposition;feature weighting;HOSVD
TP39
A
1673-4807(2015)06-0574-06
10.3969/j.issn.1673-4807.2015.06.012
2015-08-04
泰州市科技支撐項目(TS201515);教育部人文社科基金資助項目(10YJAZH069);江蘇省“六大人才高峰”項目(2012XXRJ-013)
孫玲芳(1963—),男,博士,教授,研究方向為計算機應用技術.E-mail:slf0308@163.com
孫玲芳,馮遵倡.基于特證加權張量分解的標簽推薦算法研究[J].江蘇科技大學學報(自然科學版),2015,29(6):574-579.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
