面向分布式環境的信號驅動任務調度算法
2015-01-06 01:08:04辛宇楊靜謝志強
通信學報 2015年7期
辛宇,楊靜,謝志強
(1. 哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001;2. 哈爾濱理工大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
1 引言
隨著云計算技術的迅猛發展,云計算技術可將計算、存儲、軟件、服務等資源從分散的個人計算機或服務器移植到互聯網環境中,以集中管理大規模高性能計算機、個人計算機、虛擬計算機,從而方便用戶使用云資源。從層次上云計算平臺可以分為以下3種服務模型:軟件即服務(SaaS, software as a service),平臺即服務(PaaS, platform as a service),基礎架構即服務(IaaS, infrastructure as a service)。
目前 IaaS模型是當前最重要的云平臺模型,IaaS的意義在于,用戶可通過云接口利用IaaS云服務提供商所提供的 IT設備資源運行所需應用,且無需考慮硬件的維護及更新[1]。IaaS的技術核心是硬件虛擬化,通過利用虛擬化技術,把物理主機的各種硬件整合起來,屏蔽其硬件的物理細節,以資源池的概念統一代表物理硬件,保證資源的可定制能力和統一分配能力[2]。目前,有很多企業和科研機構推出了自己的IaaS云計算平臺,面向用戶提供計算資源和存儲資源。最具代表性的是亞馬遜(Amazon)的彈性計算云(EC2, elastic compute cloud)[3],它通過Web服務的方式讓用戶彈性地運行自己的Amazon機器映像,用戶可以在自己申請的虛擬機鏡像上運行任何自己所需的軟件或應用程序。同時,還有一些開源 IaaS云計算平臺:與EC2兼容的云平臺Eucalyptus (elastic utility computing architecture for linking your programs to useful systems)[4],美國國家航空航天局和Rackspace合作研發的OpenStack[5]以及中科院的LingCloud[6]等。
IaaS通過虛擬設備實現用戶的服務,IaaS在進行虛擬設備管理時,將一臺物理設備劃分為多臺獨立的虛擬設備,各個虛擬設備之間能進行有效的資源隔離和數據隔離;由于多個虛擬設備共同享一臺物理設備的物理資源,能夠充分復用物理設備的計算資源,提高資源利用率。IaaS將云環境中的所有物理設備資源轉化為對用戶透明的統一資源池,并能按照用戶需求分配不同性能的虛擬設備。IaaS模型的框架體系如圖1所示,其中用戶的服務請求通過Scheduler模型進行虛擬設備的任務分配。

圖1 IaaS的拓撲結構
為提高資源分配及數據處理的效率,近些年來面向IaaS的虛擬設備資源調度問題逐漸成為學術研究的重點,其研究內容主要包括任務分配調度和數據傳輸調度。在任務分配調度方面,主要研究內容是處理用戶的任務分解及分配,對此Marcos等對IaaS模型的調度模塊設計了6種面向彈性計算云(EC2)的兼容策略,并提出了 cloud schedule和sub-schedule兩級調度模式,分別從宏觀和微觀角度進行任務分配優化[7,8];在數據傳輸調度方面,主要研究內容是根據數據的分布式存儲特性建立以通信損耗化及數據時效優化的調度策略,對此Nan等[9]提出了cost model及queuing model模型,構建了多媒體數據的傳播評價方法,并設計了以多媒體數據傳輸QoS優化為導向的云資源分布調度算法,Kllapi等[10]建立了流式數據的 split、compute和 merge過程,實現了分布式數據流的傳輸調度。為統一IaaS分配和數據傳輸的調度模型,Lin等[11]根據虛擬機的處理能力及網絡的數據傳輸能力,將功能和位置相近的虛擬機劃歸為cluster單元,從而將IaaS模型的調度問題轉化為DAG(directed acyclic graph)調度優化問題,統一了IaaS任務調度模型。
目前可面向IaaS模型的DAG調度算法主要分為以下5類。
1) 權值選擇算法。如HEFT[12]、ACPM算法[13]等,此類算法是早期DAG調度的主要算法,其實現原理是根據DAG的結構關系預先計算各個任務分片的EFT(earliest finish time),以確定任務分片的先后關系。
2) 層次優先選擇算法。如 PCH(path clustering heuristic)[14]、優先工序集調度[15]等,此類算法以最大化同一層任務分片的并行處理為手段,將任務分片的層數作為優先級,以確定任務分片的調度次序。
3) 堆棧式回退算法。如 HEFT-lookahead[16]、回退搶占算法[17]等,此類算法考慮了后續調度中空閑時段被占用的情況,當出現預先計算的EFT與實際的結束時間偏差較大時,采用重定向的方式回退前續調度任務分片。
4) 路徑聚合算法。如HH(hybrid heuristic)[18]、動態關鍵路徑法[19]等,此類算法考慮優先調度關鍵路徑上的任務分片,增加關鍵路徑上任務分片的優先級,從縱向角度優化調度結果。
5) 啟發式優化算法。如遺傳算法[20],粒子群算法[21,22]等,此類算法通過建立代價函數對調度結果進行局部優化,建立并利用循環選擇策略逐步保留局部優化結果,從而實現全局調度優化。
為實現高效處理用戶IaaS任務請求,本文設計了一種基于信號驅動的DAG調度算法,由于采用了信號驅動的形式,可使算法結合權值選擇算法、層次優先選擇算法和路徑聚合算法的特點,即在每一調度時刻根據任務分片的縱向權值進行橫向并行優化選擇,從而實現了DAG任務分片的縱橫雙向篩選,使調度過程更加合理化。另外,該算法由于回避了堆棧式回退算法的重定向操作,以及層次優先選擇算法和路徑聚合算法的預調度操作,因此,算法的復雜度較低(約為O(nlog(n)))且優于傳統DAG調度算法,更適于應對云計算環境中的海量任務請求問題。
2 IaaS模型的DAG調度問題分析
根據 IaaS模型的分布式特性和虛擬設備的異構特性,IaaS任務以分片的形式進行調度且各任務分片之間滿足以下約束[7,20,21]。
1) IaaS任務具有唯一的起始任務分片(DAG入口節點)和唯一的終止任務分片(DAG出口節點)。
2) 某一任務分片僅在滿足其要求的虛擬設備中執行,且滿足同一任務分片要求的虛擬設備不唯一,任務分片在各虛擬設備中的執行時間已知。
3) 任一虛擬設備在同一時刻只能執行同一任務的一個任務分片。
4) 任務分片vi的緊后任務分片vj需要等待vi執行完畢后的通信數據,若vi與vj在同一虛擬設備中執行,則通信時間為0。
5) 每一任務分片必須在其前任務分片均執行完畢,并收集到所有前序任務分片的通信數據時才可開始執行。
可根據IaaS模型的任務約束建立DAG調度模型,其符號描述如下。
1) DAG模型以圖G=(V,E)表示,G表示某一任務,V={v1,v2, …,vn}表示任務G的任務分片集合,其中n=|V|為任務分片的個數。
2)D={d1,d2, …,dm}表示虛擬設備的集合,其中m=|D|表示IaaS模型中虛擬設備的個數。
3)ci,j表示虛擬設備di到虛擬設備dj的通信代價。
圖2為某任務的DAG結構模型,其中節點表示任務分片,節點1和節點8為起始任務分片和終止任務分片,有向邊表示任務分片的有序關系,其權值代表任務分片間的通信代價,表1為任務分片在各虛擬設備中的執行時間。

圖2 DAG結構模型

表1 任務分片執行時間
3 IaaS調度系統設計
3.1 系統結構設計
定義1任務完畢信號(Sig_F):NS在任務分片執行完畢時向CS發送的反饋信號。
定義2數據傳遞信號(Sig_T):CS在分配任務分片時向NS發送的通知信號,該信號包含通信數據的源虛擬設備ID和目標虛擬設備ID。
定義 3任務分配信號(Sig_A):CS在分配任務分片時向NS發送的通知信號,該信號包含被分配的任務分片ID及虛擬設備ID。
定義 4就緒信號(Sig_R):NS在某一任務分片集齊所有所需的通信數據時向CS發送的信號。
圖3為CS和NS的信號交互過程示例,圖中CS包含了3個任務分片(vi,vj,vk),NS包含了3個虛擬設備(d1,d2,d3),vi、vj、vk分別在d1、d3、d2中執行,實箭頭和虛箭頭分別表示信號交互和數據傳遞,序號標識了CS與NS的信號先后次序,分別表示為:①任務分片vj在d3中執行完畢時,NS向CS反饋信號;②任務分片vi在d1中執行完畢時,NS向CS反饋信號;③CS通知d1和d3向d2傳遞數據;④NS內部的數據傳遞;⑤d2在集齊所需的數據時向CS反饋信號;⑥CS通知NS在d2中執行vk;⑦任務分片vk在d2中執行完畢時,NS向 CS反饋信號。
3.2 系統狀態分析
每一任務分片的運行過程中均會經歷 4種狀態,各狀態的定義如下。
定義 5接收數據狀態:某一任務分片的任一緊前任務分片執行完畢時所處的狀態。

圖3 CS和NS信號交互
定義 6就緒狀態:某一任務分片在接集齊所有所需的通信數據時所處的狀態。
定義 7執行狀態:某一任務分片在開始執行時所處的狀態。
定義 8完畢狀態:某一任務分片執行完畢時所處的狀態。
虛擬設備會經歷2種狀態,其定義如下。
定義 9忙碌狀態:某一虛擬設備執行任務分片時所處的狀態。
定義10空閑狀態:某一虛擬設備無任務分片執行時所處的狀態。
圖4為任務分片和虛擬設備的狀態變化示例,該示例直觀表示了任務分片和虛擬設備在運行過程中的狀態變化關系,圖中右(左)側虛框表示某一任務分片vi在某一虛擬設備dj中執行(完畢)時,vi和dj的狀態同時變化。其中,信號起到信息傳遞及驅動狀態轉化的作用。
3.3 調度系統優化分析
由于各任務分片的執行時間和各虛擬設備的數據傳遞時間均為已知,因此任務的尋優過程是靜態過程,可向所有的虛擬設備發送Sig_A作尋優假設,具體的優化方案如下。
1) 當某一任務分片vi的任一緊前任務分片執行完畢時(此時變為接收數據狀態),CS向NS發送m個不同目標虛擬設備ID的信號Sig_T,為vi預分配所有m個虛擬設備。
2) CS建立任務分片就緒表(RT),記錄任務分片在不同虛擬設備中變為就緒狀態的時刻。
3) NS建立虛擬設備空閑表(DT),記錄任一虛擬設備下一次變為空閑狀態的時刻。
4) 由于RT和DT會隨CS和NS的狀態變化而變化,當RT或DT發生變化時利用current記錄當前時刻,并利用下一節描述的并行優化選擇策略進行任務分片的選擇。

圖4 任務分片和虛擬設備的狀態轉化
4 并行優化選擇策略
任務分片的執行需具備 2個條件:1) 任務分片處于就緒狀態;2) 虛擬設備處于空閑狀態。為此本文所提出的并行優化選擇策略以RT或DT的更新作為一次任務分片分配的時刻,為處于就緒狀態的任務分片分配空閑虛擬設備,將該時刻定義為調度時刻。
由于當某一任務分片變為接收數據狀態時,CS會向NS中所有的虛擬設備發送Sig_A,因此當調度時刻來臨時,就緒的任務分片與空閑的虛擬設備間會存在多對多的關系,為實現任務分片與虛擬設備的一對一執行關系,本文在調度時刻利用如下策略為空閑的虛擬設備分配執行任務。
1) 利用 HEFT算法[12]計算就緒任務分片的rank值,rank值最大者優先選擇空閑虛擬設備,HEFT的計算公式為

其中,succ(vi)為任務分片vi的緊后任務分片的集合,wi為vi在各虛擬設備中執行時間的均值,當vi為終止任務分片時ranki=wi,表2為圖2實例的rank值。

表2 圖2示例的rank值
2) 計算就緒任務分片在每個虛擬設備的執行完畢時刻,選擇執行完畢時刻最小者作為該任務分片的執行虛擬設備。
3) RT和DT中的最小值為下一個調度時刻。
表3記錄了圖2示例的調度優化過程,表中各行記錄了各調度時刻RT與DT的變化過程,2列和3列為調度之前RT與DT的內容,4列和5列為調度之后RT與DT的內容,第6列為預算出的下一調度時刻,如2列和3行可表示為:當current為17 時,d1、d2、d3均空閑且v2、v3、v4、v5均只能在d1中執行,此時利用優化選擇策略選擇在d1中執行v2,RT和DT中的最小值為30,即為下一個調度時刻;當current為30時,僅d2,d3空閑且v3和v5只能在d1中執行,因此無法調度v3和v5,又由于此時v4可在d2,d3中執行,此時利用優化選擇策略選擇在d2中執行v4,并計算下一調度時刻為33。在RT表格中R表示在當前時刻任務分片vi可在dj中執行,即dj在當前時刻已集齊了vi所需的數據,DT記錄了虛擬設備所執行的任務分片及執行結束時間。任務分片的調度結果如圖5所示。
5 算法設計及復雜性分析
5.1 調度算法設計
通過以上分析,在以下2種情況發生的時刻,可作為調度時刻:①NS在任務分片執行完畢時,通過改變DT內容的同時驅動CS改變RT的內容;②當某一任務分片變為就緒狀態時,CS改變RT的內容。本節通過分析CS和NS內部運行機制,從全局角度設計調度算法。
1) 信號設計。根據CS和NS的運行機制,設計了信號Sig_A、Sig_T、Sig_R和Sig_F進行數據通信與執行任務分片的交互,其中,Sig_T和Sig_R用于數據通信的交互,Sig_A和Sig_F用于執行任務分片的交互,4種信號的說明如表4所示。
2) NS內部運行算法。
①NS等待CS傳來的信號;
②若CS傳來的信號為信號Sig_T則轉③,若為信號Sig_A則轉④;
③此時說明CS需求Sig_T->D_ID接受數據,NS驅動虛擬設備Sig_T->S_ID向虛擬設備D_ID傳遞數據,并轉⑤;
④此時說明CS需求Sig_T->D_ID執行任務分片,任務分片Sig_A->partition在Sig_A->DB_ID中執行,轉⑥;
⑤當任務分片vi在虛擬設備dj中變為就緒狀態時(即此時dj已接收到所有所需的數據),向 CS反饋信號Sig_R(Sig_R-> partition=vi, Sig_R->DB_ID=dj),此時利用Sig_R向CS報告虛擬設備dj可執行調度任務,轉①;
⑥當任務分片vi在虛擬設備dj中執行完畢時,向CS反饋信號Sig_F(Sig_F->partition=vi,Sig_F->DB_ID=dj)并更新DT,若vi為終止任務分片則轉⑦否則轉①;
⑦結束。

表3 圖2示例的rank值

圖5 圖2示例的調度結果

表4 信號說明
3) CS內部運行算法。CS內部在RT和DT的內容變化時(收到Sig_R或Sig_F時),利用并行優化選擇策略對就緒任務分片進行分配,其運行機制如下:
①等待NS傳來的信號;
②若為Sig_F則轉⑥,若為信號Sig_R轉③;
③根據Sig_R->partition和Sig_R->DB_ID更新RT;
④利用并行優化選擇策略對處于就緒狀態的任務分片進行調度;
⑤任務分片vi在虛擬設備dj中執行,向NS反饋信號 Sig_A(Sig_A->partition=vi,Sig_A-> DB_ID=dj),驅動NS執行任務vi,若vi為終止任務分片則轉⑦否則轉①;
⑥向NS反饋信號Sig_T(Sig_T->S_ID =Sig_F->DB_ID,Sig_A-> DB_ID=所有虛擬設備ID),對執行完畢的任務進行后續執行的數據傳遞,轉①;
⑦結束。
圖6為CS與NS算法流程。其中,實線表示單一任務分片的運行過程,虛線表示多個任務分片的實時等待過程。
5.2 復雜度分析
本算法的復雜之處在于某一調度時刻到來時,利用并行優化選擇策略,實現任務分片與虛擬設備一對一的選擇,設任務分片總數為n,虛擬設備總數為m,總體復雜度分析如下。
1) NS算法復雜度分析
NS只接收信號Sig_T和Sig_A,在調度過程中CS為每一任務分片發送m個信號Sig_T和1個信號 Sig_A,NS共需處理n(m+1)個信號,且 Sig_T和Sig_A的處理過程僅為常數復雜度,因此NS的復雜度為O(mn)。
2) CS算法復雜度分析
① 根據文獻[12]計算每個任務分片rank值的時間復雜度為O(mn);

圖6 CS與NS算法流程
②n個任務分片按rank值進行排序的時間復雜度為O(nlog(n));
③ 每一調度時刻,處于空閑狀態的虛擬設備個數最大為m,因此,就緒任務分片對虛擬設備的選擇次數據最大為m,總選擇次數為mn,其時間復雜度為O(mn)。
綜上所述,本文算法的時間復雜度為O(mn+nlog(n)),由于在現實環境下虛擬設備總數為較小的常數,因此本文算法的復雜度可近似為O(nlog(n)),文獻[12~19]的復雜度分別為O(n2)、O(n2log(n))、O(n2log(n))、O(n2log(n))、O(n3)、O(n2log(n))、O(n2log(n))、O(n3)均高于本文算法。
6 實驗分析
為驗證本文算法的有效性,本實驗以文獻[23]的DAG數據NSL(normalized schedule length)為標準隨機生成任務,以模擬IaaS云計算平臺的DAG任務分片結構,并以 HEFT[12]、PCH[14]、HEFT-lookahead[16]和HH算法[18]作為對比算法(本文算法用 SD表示)。本實驗平臺軟件:Win7 32位,Matlab2012;硬件:intel i3處理器,4 GB內存,所設計的4組實驗如下。
1) 資源占用時間分析實驗。本組實驗通過計算100組隨機任務的調度結果,分析任務對虛擬設備的占用時間

其中,makespanvi為任務分片vi的執行時間,makespan越小說明運行結果對虛擬設備的占用率越低,算法有效性越高。由于100組隨機任務的結構差異較大,為直觀顯示實現各算法的對比結果,分別按各算法的makespan對100組結果進行排序,其結果如圖7所示,該圖分別以各算法為視角,對比各算法的資源占用時間,其中曲線越靠近底部說明算法有效性越高,從圖7可直觀看出,在資源占用時間方面 lookahead和本文算法優于其他算法且HEFT算法的效果最差。為消除各組隨機任務的結構差異,本實驗采用對每組結果進行[0,1]區間映射的方法整理各組數據,并以各算法結果之和作為各算法的數值評價,本實驗中各算法的計算結果分別為:84.54,76.00,18.09,60.32,10.99,數值越小表示算法有效性越高,因此在本實驗中各算法的有效性排序為:SD(本文算法)、lookahead、PCH、HH、HEFT。

圖7 資源占用時間對比

圖8 總執行時間對比
2) 任務總執行時間分析。本實驗以實驗1的結果為數據集分析各算法的執行時間,其執行時間越短,說明調度算法的有效性越高,本實驗采用與實驗 1相同的方式,分別按各算法的執行時間對100組結果進行排序,其結果如圖8所示,其中曲線越靠近底部說明算法有效性越高,從圖8中可直觀看出,HEFT算法的效果最差,其他算法性能相近。本實驗采用實驗1的[0,1]區間映射求和方法進行計算,結果分別為:96.57,31.59,21.98,34.63,23.39,其中數值越小表示算法有效性越高,因此各算法的有效性排序為:lookahead、SD、HH、PCH、HEFT。
3) CCR(communication computation ratios)分析實驗。CCR分析的目的在于通過改變隨機任務的通信時間以驗證調度算法的穩定性,本實驗以[5,25]為隨機區間生成各任務分片的執行時間,以[6,26]CCR(CCR=0.5~3)為隨機區間生成通信時間,創建6組DAG任務樣本(每組100個樣本)作為實驗數據。圖9為各算法在執行6組數據后的平均總執行時間和平均資源占用時間對比,圖9的結果說明了本文算法在不同 CCR條件下,相較于其他算法在資源占用方面的優越性較高。
4) DAG任務頑健性實驗。調度算法的頑健性表現在處理異構DAG任務時的穩定性,本實驗隨機生成 6組(每組 100個樣本)層數為 5~10的異構DAG模型,統計各算法執行每組數據后的平均總執行時間和平均資源占用時間,其對比結果如圖 10所示,從圖中本文算法與其他算法的性能對比變化可知,異構DAG任務對SD算法影響較小。
5) 虛擬設備個數穩定性實驗。本實驗生成了6組(每組 100個樣本)虛擬設備個數不同(3~8)的任務,統計各算法執行每組數據后的平均執行時間和平均資源占用時間,其對比結果如圖 11所示,從圖中本文算法與其他算法的性能對比變化可知,虛擬設備的個數變化對SD算法的影響較小。
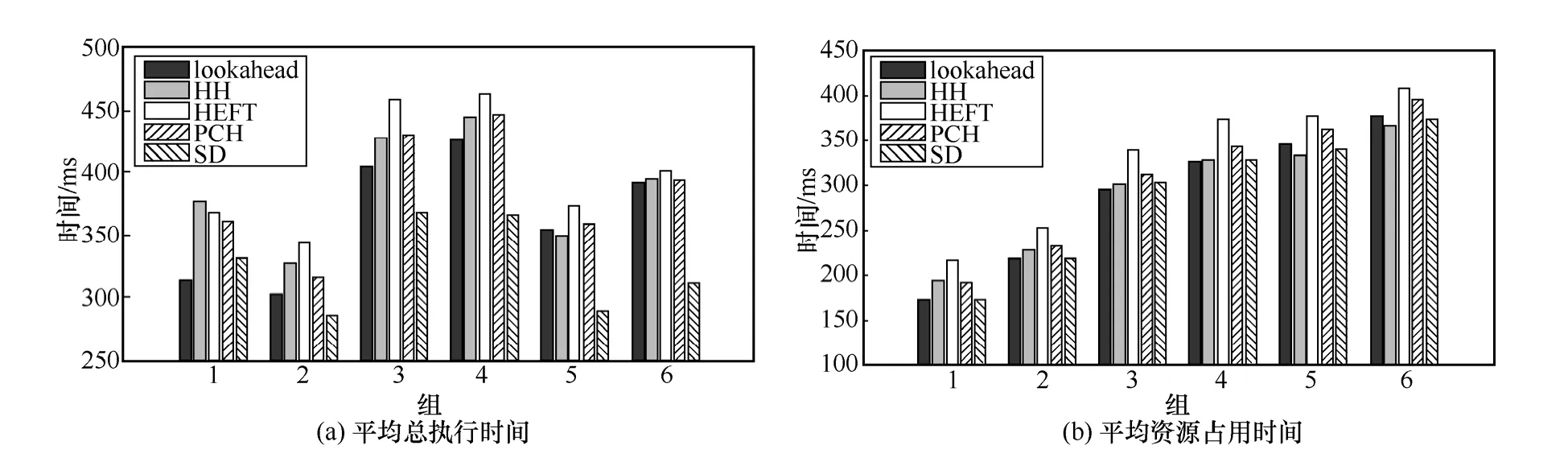
圖9 CCR分片對比

圖10 DAG模型頑健性對比

圖11 虛擬設備個數穩定性對比
6) 實驗結論。本實驗分別從5個方面實證了算法的有效性,在CCR分析實驗、DAG任務頑健性實驗和虛擬設備個數穩定性實驗方面,通過與其他算法結果的對比,驗證了本文算法的穩定性,說明本文算法面對各類DAG任務調度問題時可保持其有效性;在任務總執行時間分析實驗方面,本文算法執行結果近于同類算法最優值,在資源占用時間方面優于其他算法。
7 結束語
本文根據 IaaS模型中各虛擬設備離散分布的特點,建立控制子系統CS和節點子系統NS及IaaS模型的DAG任務調度模型,并利用信號驅動的方式處理DAG任務調度問題。由于該算法以并行計算的DAG任務調度模型為基礎使該算法具有普適性,可解決一般并行計算優化問題,本文算法的創新性和意義如下:所設計的利用信號交互機制進行驅動式調度,是面向IaaS的DAG任務調度的一次創新;所設計的并行優化選擇策略,從全局角度考慮了DAG結構,使調度結果更加合理化;算法的復雜度為O(nlog(n)),低于傳統DAG調度算法,使得該算法更加簡單適用;算法的穩定性高于其他算法,適用于各類異構任務;相較于其他算法,本文算法的執行總時間近于最優,且對虛擬設備的占用時間最低。
因此,本文提出的算法不僅可以解決IaaS模型的調度問題,且對深入研究并行調度優化問題具有一定的理論和實際意義。
[1] ZHANG J X, GU Z M, ZHENG C. Survey of research progress on cloud computing[J]. Application Research of Computers, 2010, 27(2):429-433.
[2] 謝亞龍, 丁麗萍, 林渝淇等. ICFF:一種IaaS模式下的云取證框架[J]. 通信學報, 2013, 34(5): 200-206.XIE Y L, DING L P, LIN Y Q. ICFF: a cloud forensics framework under the IaaS model[J]. Journal on Communications, 2013, 34(5):200-206.
[3] AMAZON Inc. Amazon elastic compute cloud (Amazon EC2)[EB/OL].http://aws.amazon.com/ec2.
[4] NURMI D, WOLSKI R, GRZEGORCZYK C,et al. The eucalyptus open-source cloud-computing system[A]. Proceedings of the 9th IEEE/ACM Conference on International Computing and the Grid[C].Tsukuba, Japan, 2009.124-131.
[5] COMPUTING R C. Openstack open source cloud computing software[EB/OL]. http://openstaek.org.
[6] LU X Y, LIN J, ZHA L,et al. Vega LingCloud: a resource single leasing point system to support heterogeneous application modes on shared infrastructure[A]. Proceedings of the 9th IEEE Conference on Parallel and Distributed Processing with Applications[C]. Busan, Korea, 2011. 99-106.
[7] MARCOS D, COSTANZO A, BUYYA R. A cost-benefit analysis of using cloud computing to extend the capacity of clusters[J]. Cluster Computing, 2010, 13(3): 335-347.
[8] MARCOS D , COSTANZO A, BUYYA R. Evaluating the cost-benefit of using cloud computing to extend the capacity of clusters[A]. Proceedings of the 18th ACM international Conference on High Performance Distributed Computing[C]. Munich, Germany, 2009.141-150.
[9] NAN X, HE Y, GUAN L. Optimal resource allocation for multimedia cloud based on queuing model[A]. Proceedings of the 13th IEEE Conference on Multimedia Signal[C]. Hangzhou, China, 2011.1-6.
[10] KLLAPI H, SITARIDI E, TSANGARIS M M,et al. Schedule optimization for data processing flows on the cloud[A]. Proceedings of the 2011 ACM SIGMOD Conference on Management of Data[C]. Athens,Greece, 2011. 289-300.
[11] LIN C, LU S. Scheduling scientific workflows elastically for cloud computing[A]. Proceedings of the 2011 IEEE Conference on Cloud Computing[C]. Washington DC, USA, 2011. 746-747.
[12] TOPCUOGLU H, HARIRI S. Performance-effective and low- complexity task scheduling for heterogeneous computing[J]. Parallel and Distributed Systems, 2002(13):260-274.
[13] 謝志強, 劉勝輝, 喬佩利. 基于 ACPM 和 BFSM 的動態 Job-Shop調度算法[J]. 計算研究與發展, 2003, 40(7): 977-983.XIE Z Q, LIU S H, QIAO P L. Dynamic job-shop scheduling algorithm based on ACPM and BFSM[J]. Journal of Computer Research and Development, 2003, 40(7): 977-983.
[14] LUIZ F B, EDMUNDO R M. Towards the scheduling of multiple workflows on computational grids[J]. Journal of Grid Computing,2010, 8(3): 419-441.
[15] 謝志強, 楊靜, 楊光. 可動態生成具有優先級工序集的動態Job-Shop調度算法[J]. 計算機學報, 2008, 31(3): 502-508.XIE Z Q, YANG J, YANG G. Dynamic Job-Shop scheduling algorithm with dynamic set of operation having priority[J]. Chinese Journal of Computers, 2008, 31(3): 502-508.
[16] LUIZ F B, RIZOS S, EDMUNDO R M. DAG scheduling using a lookahead variant of the heterogeneous earliest finish time algorithm[A].Proceedings of the 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing[C]. Pisa, Italy, 2010.27-34.
[17] 謝志強, 辛宇, 楊靜. 可回退搶占的設備驅動綜合調度算法[J]. 自動化學報, 2011, 37(11): 1332-1343.XIE Z Q, XIN Y, YANG J. Machine-driven integrated scheduling algorithm with rollback-preemptive[J]. Acta Automatica Sinica, 2011,37(11): 1332-1343.
[18] RIZOS S, HENAN Z. A hybrid heuristic for DAG scheduling on heterogeneous systems[A]. Proceedings of the 18th IEEE International Parallel and Distributed Processing Symposium (IPDPS)[C]. Santa Fe,USA, 2004.266-286.
[19] 謝志強, 楊靜, 周勇等. 基于工序集的動態關鍵路徑多產品制造調度算法[J]. 計算機學報, 2011, 34(2): 406-412.XIE Z Q, YANG J, ZHOU Y,et al. Dynamic critical paths multi-product manufacturing scheduling algorithm based on operation set[J]. Chinese Journal of Computers, 2011, 34(2): 406-412.
[20] TAYAL S. Tasks scheduling optimization for the cloud computing systems[J]. International Journal of Advanced Engineering Sciences And Technologies, 2011, 5(2): 111-115.
[21] PANDEY S, WU L, GURU S M,et al. A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments[A]. Proceedings of the 24th IEEE Conference on Advanced Information Networking and Applications[C].Perth, Australia, 2010.400-407.
[22] WU Z, NI Z, GU L,et al. A revised discrete particle swarm optimization for cloud workflow scheduling[A]. Proceedings of the 2010 IEEE Conference on Computational Intelligence and Security[C]. Guangzhou, China, 2010.184-188.
[23] LUIZ F B, EDMUNDO R M. Towards the scheduling of multiple workflows on computational grids[J]. Journal of Grid Computing.2010, 8(3) : 419-441.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國特種設備安全(2022年6期)2022-09-20 02:52:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年11期)2018-08-04 03:25:42
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
工業設計(2016年12期)2016-04-16 02:52:00
