一種融合詞序信息的多粒度文本話題情感聯合模型
2014-08-07 12:17:59趙煜邵必林邊根慶
西安交通大學學報 2014年11期
趙煜,邵必林,邊根慶
(西安建筑科技大學管理學院, 710055, 西安)
一種融合詞序信息的多粒度文本話題情感聯合模型
趙煜,邵必林,邊根慶
(西安建筑科技大學管理學院, 710055, 西安)
針對基本話題模型只能抽取粗粒度上下文信息的問題,通過對潛在狄里克雷分配(LDA)模型進行擴展,建立了一種利用詞序信息的多粒度話題情感聯合模型(MTSU-Col)。MTSU-Col模型客觀表達了詞匯、全局/局部話題、情感標簽和詞序信息之間的關聯關系,使模型中話題和情感的建模更加符合文本的語義表達,有效解決了現有話題、情感分析方法存在的領域依賴問題,從而實現了文本多粒度話題信息和情感傾向信息的同步非監督獲取。實驗表明:利用MTSU-Col模型對文本進行情感傾向性分類,可使綜合評價指標F1值達到84%,整體性能與監督分類方法支持向量機(SVM)類似,均優于未采用詞序信息的分析方法。由于挖掘話題集合具有層次化、語義相關的特點,因此MTSU-Col模型對觀點挖掘是可行、有效的。
話題模型;文本情感分析;聯合模型;詞序信息
網絡評論文本具有海量化、復雜化的特點,促使人們利用自動評論文本挖掘技術[1]進行人工難以完成的深層次、智能化的評論文本分析。評論文本挖掘包括話題挖掘技術、文本情感傾向性分類技術以及觀點挖掘技術。話題挖掘技術主要抽取文本中的客觀信息[2],但無法抽取情感語義信息。情感傾向性分類技術利用各類文本分類算法判別文本的主客觀屬性或褒貶傾向屬性[3-4],這一類方法只能對整篇評論進行情感分析,缺乏對話題等深層次語義對象的情感分析,因此無法進行細粒度文本情感信息獲取。觀點挖掘技術在獲取客觀話題信息和主觀情感傾向性信息的基礎上,挖掘話題與子話題、話題與情感傾向信息之間的關聯信息[5-6],但評價特征集合沒有明確的語義關系[6],需要利用領域知識解決評價特征集合的冗余問題[5]。
潛在狄里克雷分配(LDA)模型[7]是一個完全的生成模型,具有良好的數學基礎和拓展性,LDA模型及其擴展模型在文本分類、情感分析等領域受到了越來越多的關注[8-12]。Lin等(記為Lin模型)在LDA模型中加入了情感標記節點,模型中文本與多個文本-話題條件分布相關,詞匯生成需同時考慮話題和情感信息[10]。利用Lin模型進行篇章級情感分析的整體效果優于監督分類方法,但Lin模型僅面向篇章級分析,無法挖掘評價特征之間的語義關系。Titov等提出了完整的評價特征挖掘方法和情感傾向性預測方法[11],由于需要外部信息來輔助情感傾向性判斷,屬于監督學習方法。Jo等提出的方法[12]是以假定句子中所有的詞來自一致的話題和情感為前提條件,強制性地縮小了詞匯之間的主題聯系,與客觀情況并不相符。
針對上述研究存在的問題,本文提出了一種利用詞序信息的多粒度話題情感聯合模型(MTSU-Col),用戶可以同步進行評價對象挖掘和情感傾向性分類2個任務。該模型將LDA模型進行擴展,同時融入了文本的情感和話題信息,每個句子都采樣情感標簽,每個詞都采樣全局/局部主題標簽,利用詞序信息建模方法[13]使MTSU-Col模型更加貼近文本的真實語義。MTSU-Col模型采用非監督學習方法,不需要任何領域相關的先驗知識,具有領域獨立性。實驗表明,MTSU-Col模型挖掘的評價特征集合具有明確的語義關系,從而大量減少了冗余評價特征,篇章級情感傾向性分類的整體效果優于一般的監督分類方法。
1 MTSU-Col模型的建立
MTSU-Col模型將話題分為全局話題和局部話題,全局話題混合分布固定不變,局部話題混合分布隨上下文環境變化。評論文本由短句構成,由于字數較少,短句通常是文本情感表達的基本單元,因此MTSU-Col模型在句子級采樣情感標簽并引入滑動窗口隨機變量中起到了記錄局部話題變化的作用。
假設語料庫中包含D個文檔,共有K1個全局話題,K2個局部話題;共有S種文本情感;文本d由H個句子構成;每個滑動窗口由M個句子構成;每個句子由N個詞匯構成。對語料庫進行去重操作后,詞匯表中的詞匯數量為V。利用貝葉斯網絡表示MTSU-Col模型如圖1所示。
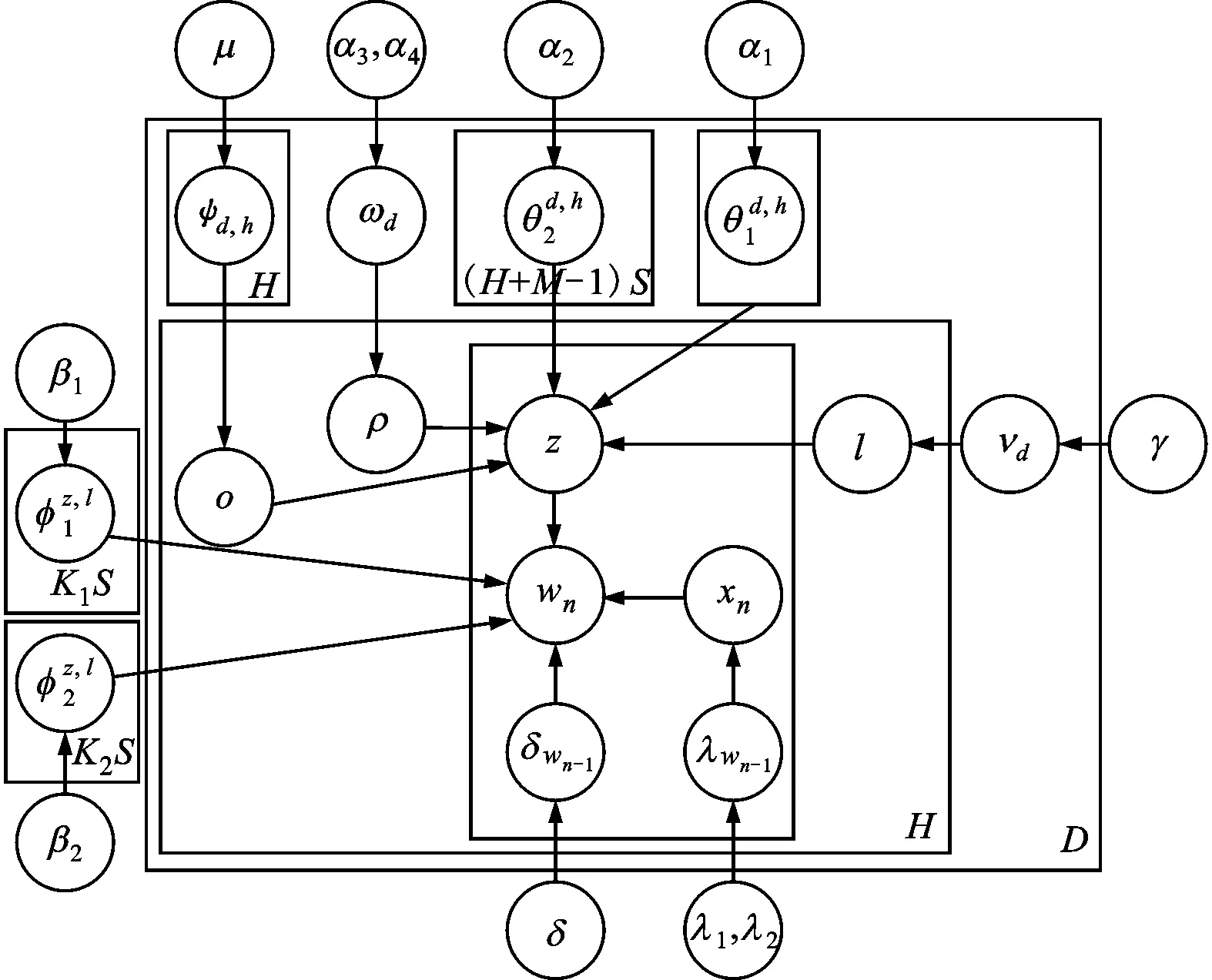
圖1 MTSU-Col模型
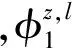
MTSU-Col模型生成過程的描述如下:當xn=0詞匯由話題、情感相關的詞匯概率分布采樣;當xn=1詞匯采樣自詞匯連接的概率分布。MTSU-Col模型生成過程如下。
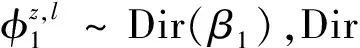
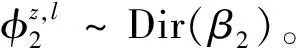
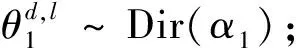
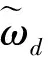
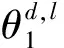
2 MTSU-Col模型推理及分析
Gibbs采樣算法是MCMC(Markov Chain Monte Carlo)算法的一種,多用于貝葉斯圖模型求解中。與變分貝葉斯方法相比較,Gibbs采樣方法描述簡單且容易實現,是目前LDA及擴展模型最常用的參數估計方法[8,14]。本文采用Gibbs采樣算法對MTSU-Col模型進行推理。
為了描述方便,定義wi為詞匯記號,表示wi出現在第d個文本的第n個位置,屬于文本d的第h個句子;lh表示wi所屬句子的情感標注結果;zi表示詞匯記號wi所屬話題。依據MTSU-Col模型生成過程分為2種情況。
(1)當xi=0時,wi出現在句子h的滑動窗口o中,屬于全局話題z,且lh=l時的條件后驗分布如下
P(zi=z,ρi=1,oi=o,lh=l|z-i,ρ-i,o-i,l-h,W)
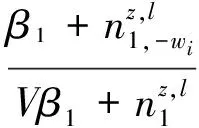
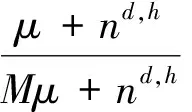
(1)
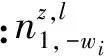
(2)當xi=1時,wi根據詞匯連接的概率分布產生,因此當wi出現在句子的滑動窗口中,屬于全局話題,且lh=l的條件后驗分布如下
P(zi=z,ρi=1,oi=o,lh=l|z-i,ρ-i,o-i,l-h,W)

(2)
當xi=1時,詞匯記號屬于局部話題的條件后驗分布同理可得。
當xi=1時,xi的條件后驗分布如下
P(xi|x-i,W,z,ρ,o,l)=
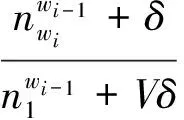
(3)
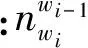
利用馬爾可夫鏈收斂狀態下的抽樣樣本,舍棄詞匯記號,將w作為唯一性詞,估計MTSU-Col模型參數如下
(4)
(5)
(6)
(7)
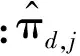
3 實驗驗證與分析
MTSU-Col模型主要用于文本情感傾向性分類和全局/局部話題挖掘2個任務,因此本文依據這2個任務對MTSU-Col模型進行驗證。
3.1 數據集預處理
本文實驗數據集由3部分構成,第1部分來自中科院譚松波研究員收集的中文情感挖掘語料集,選取其中酒店類評價文本,第2和第3部分是搜集于主流電商網站的關于書籍和手機的評價文本。針對短文本的特點,預處理過程還采取3項特殊措施,分別是:①僅選取出現頻次高于4次的詞匯進行實驗;②將“,”號也作為分句的標志;③將包含感情色彩的“?”、“!”號作為詞匯對待。
情感詞典是提高文本情感傾向性分類效果的有效手段。本文首先采用知網提供的負面和正面評價詞語作為基礎情感詞典,再對實驗數據集進行統計,從基礎情感詞典中篩選出頻率高于30的情感詞,構成實驗情感詞典,整個構造過程與領域無關。在MTSU-Col模型推斷的初始化階段,若實驗詞匯記號出現在情感詞典中,則將詞匯記號情感傾向性初始化為對應值。
3.2 話題挖掘和情感分類實驗
對MTSU-Col模型推斷時,超參數賦值依據文獻[10-11,13-14]中的經驗值;全局話題數的確定通常采用多次實驗調整法進行設置[10-11],本文也采用該方法;與文獻[11]處理方法一致,實驗將局部話題數設置為評價特征數;情感標注類別數設置為2。在LDA模型及其擴展模型的推斷過程中,常用實驗方法是將Gibbs抽樣過程迭代500~2 000次,實驗將迭代次數設置為2 000次。
3.2.1 多粒度話題挖掘實驗 LDA模型是一種具有代表性的話題模型,實驗將LDA模型與MTSU-Col模型的話題挖掘效果進行對比,驗證了利用詞序信息、層次話題結構擴展LDA模型的有效性。LDA模型中的參數設置與MTSU-Col模型一致,部分褒貶話題挖掘結果如表1所示。
由表1可以看出,褒義全局詞匯集是對單詞類書籍的評價,貶義局部詞匯集是書籍翻譯質量的貶義評價。說明MTSU-Col模型挖掘的全局話題與評價對象相對應,局部話題與評價特征相對應。與MTSU-Col模型相比較,LDA模型挖掘的話題沒有將評價對象和評價特征區分開,話題1詞匯集中既包含對數據庫類書籍的整體評價,如“入門”、“基礎”等詞,也包含用戶對書籍內容的評價,如“難”、“懂”等詞。話題2詞匯集是關于書籍包裝的話題,既出現了“新”、“厚”等褒義詞,也出現了“破”、“舊”等貶義詞,不具有挖掘情感信息的功能。這驗證了MTSU-Col模型在多層次話題挖據方面的有效性。

表1 話題挖掘對比實驗結果
3.2.2 篇章級情感傾向性分類實驗 Pang提出的利用支持向量機(SVM)的篇章級情感傾向性分析方法[3]是目前常用的標準比較系統,其中采用一元文法屬性分類的結果最優。本文的實驗采用了該比較系統(記為Pang)。為了驗證融入詞序信息對篇章級情感分類結果的有效性,實驗將不包含詞序信息的話題情感聯合模型(MTSU)作為比較系統,對MTSU模型的超參數賦值以及Gibbs采樣設置與本文模型相一致。
針對短文本的特點,本文采用“,”號作為分句標志、引入領域無關情感詞典等2項措施,來提高篇章級情感分析的準確率。措施驗證實驗結果如下。
從表2中可以得到:文本預處理階段采用“,”號作為分句標志,解決了評價文本書寫不規范,“,”號前后的句義表達不同的問題,有效提高了評價文本情感傾向性分類的準確率;情感詞典是文本情感分析的重要參考依據,利用語料庫詞頻信息對通用情感詞典進行過濾,提高了文本情感傾向性分類的準確率。
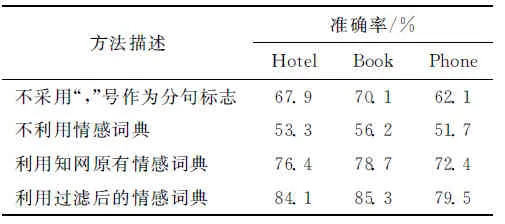
表2 文本情感傾向性的預測準確率
對大規模數據集合進行檢索和選取時,一般均采用準確率、召回率及綜合評價指標F1值作為數據分析結果的衡量指標。3種分析方法的實驗結果如圖2~圖4所示。
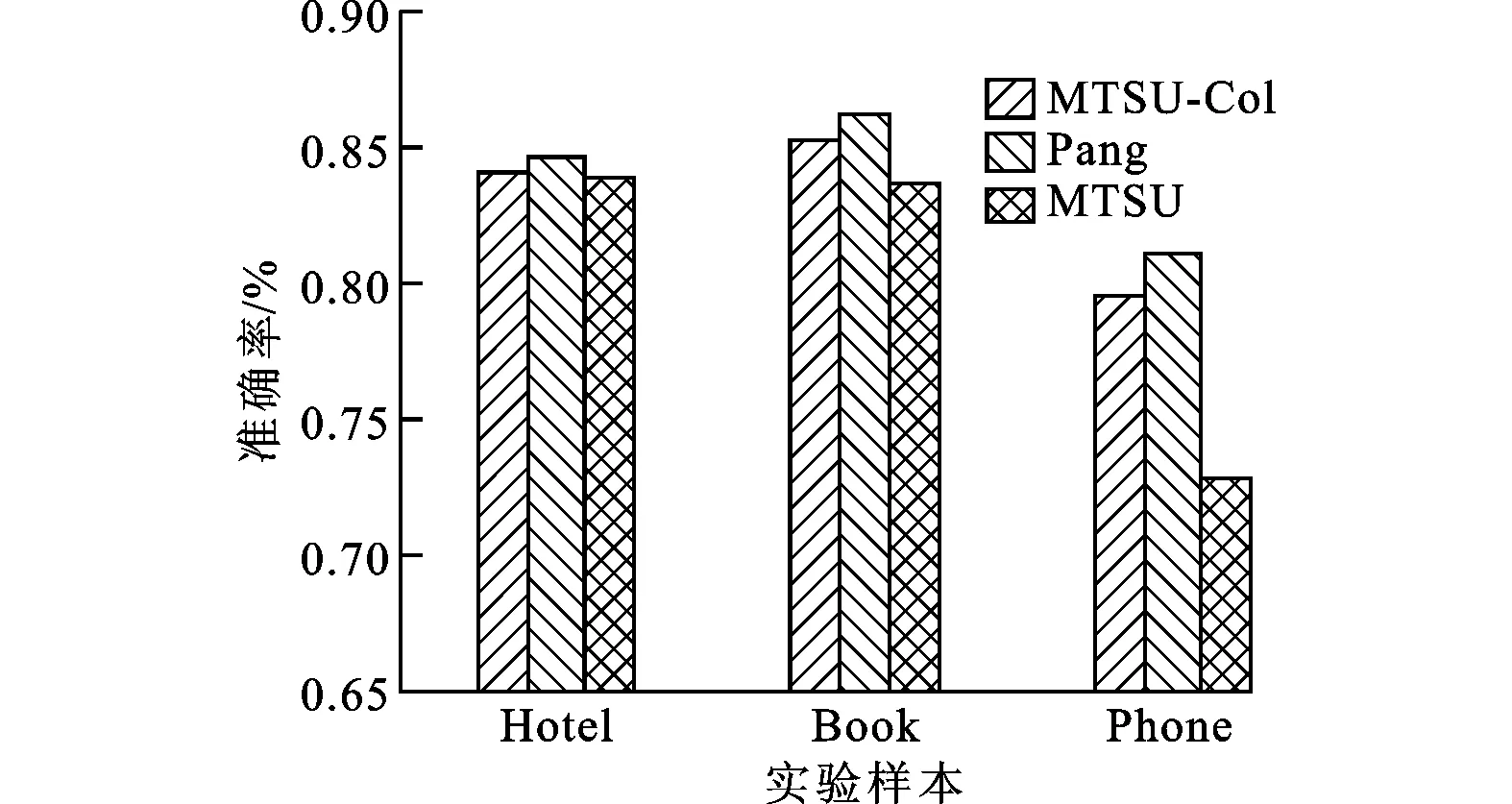
圖2 文本情感傾向性分類的準確率對比
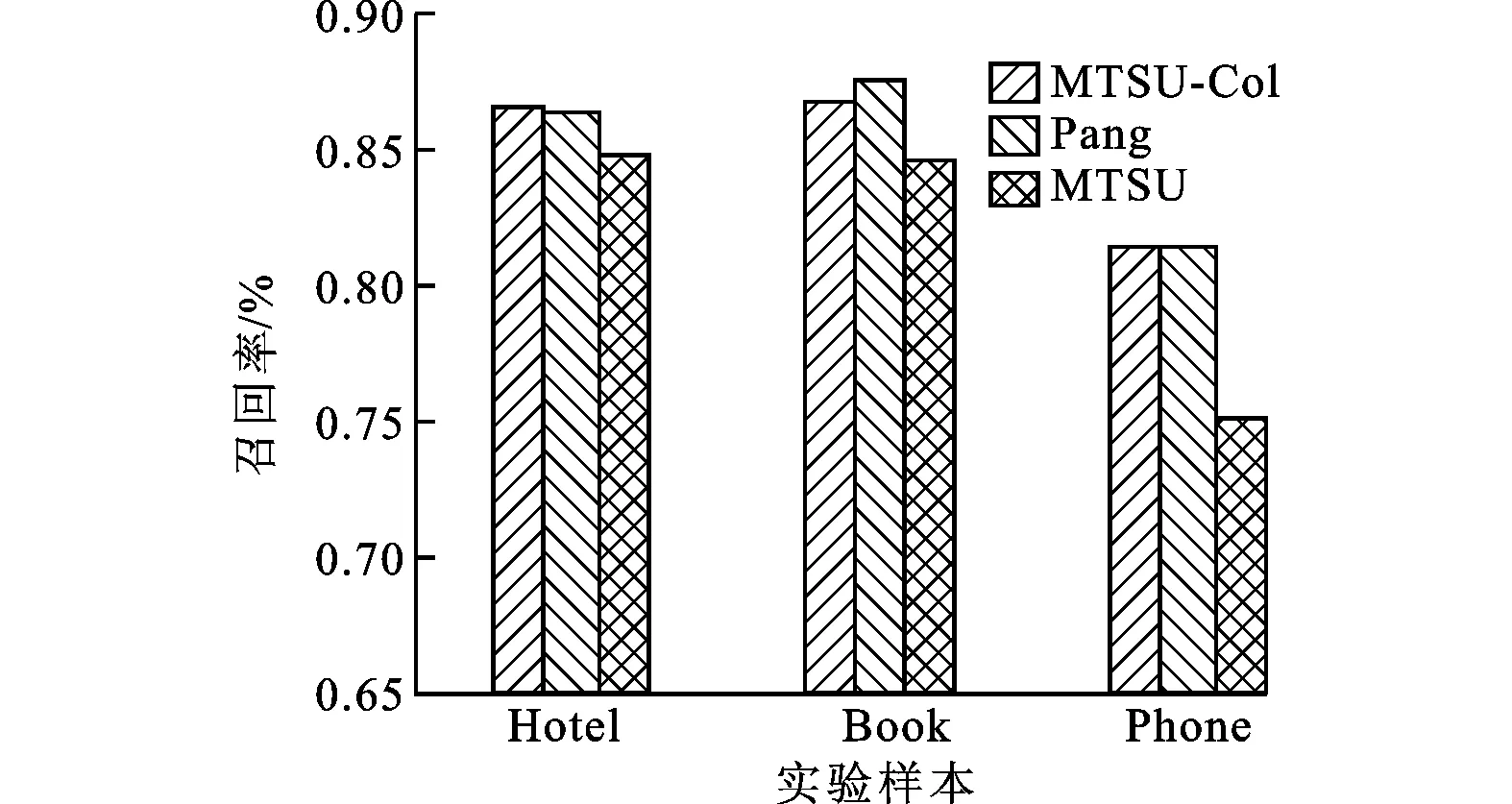
圖3 文本情感傾向性分類的召回率對比
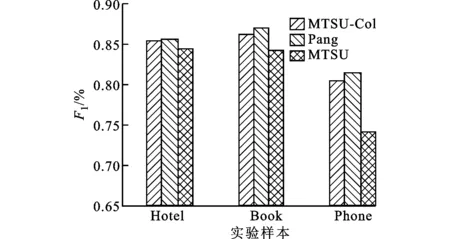
圖4 文本情感傾向性分類的F1值對比
由圖2~圖4可以看出:利用本文模型對實驗數據集進行文本情感傾向性分類的平均準確率達到了83%,與Pang方法相比,只降低了1%,與MTSU模型相比,則提高了3%;本文模型的F1值達到了84%,低于Pang方法0.7%,高于MTSU模型3%,驗證了將詞序信息融入文本情感分析方法的有效性與客觀性。
4 結 論
本文針對基本話題模型只能抽取粗粒度上下文信息的問題,利用詞匯搭配信息對LDA模型進行擴展,建立了一種融合詞序信息的多粒度話題情感聯合模型MTSU-Col模型。MTSU-Col模型考慮了詞匯生成過程中全局/局部話題、句子情感標簽之間的關聯關系,對詞序信息的建模使MTSU-Col模型更加貼近文本的真實語義,得到的結論如下。
(1)利用MTSU-Col模型進行文本情感傾向性分類的平均準確率達到83%,平均F1值達到84%,整體性能與監督分類方法SVM類似,且均優于未采用詞序信息的分析方法,挖掘話題集合具有層次化、語義相關的特點。
(2)MTSU-Col模型更有利于提取文本真實語義,并且既不需要大量人工語料庫標注,也不依賴于領域相關的先驗知識,是一種整體性能優秀的非監督文本情感信息分析方法。
(3)MTSU-Col模型對LDA模型進行了多粒度話題擴展,并融入了豐富的語言結構信息,進一步提高了文本觀點挖掘結果的層次性和語義相關性。
[1] LIU B, ZHANG L.A survey on opinion mining and sentiment analysis [M].Berlin, Germany: Springer, 2012: 415-463.
[2] MEI Q, ZHAI C.Discovering evolutionary theme patterns from text-an exploration of temporal text mining [C]∥Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York, USA: ACM, 2005: 198-207.
[3] PANG B, LEE L.Opinion mining and sentiment analysis [J].Foundations and Trends in Information Retrieval, 2008, 2(1/2): 1-135.
[4] TANG H, TAN S, CHENG X.A survey on sentiment detection of reviews [J].Expert Systems with Applications, 2009, 36(7): 10760-10773.
[5] CARENINI G, NG R, PAULS A.Multi-document summarization of evaluative text [C]∥Proceedings of the 11th European Chapter of the Association for Computational Linguistics.Trento, Italy: ACL, 2006: 3-7.
[6] HU M, LIU B.Mining and summarizing customer reviews [C]∥The 10th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2004.New York, USA: ACM, 2004: 168-177.
[7] BLEI D M, NG A Y, JORDAN M I.Latent Dirichlet allocation [J].Journal of Machine Learning Research, 2003, 3(4/5): 993-1022.
[8] 徐戈, 王厚峰.自然語言處理中主題模型的發展 [J].計算機學報, 2011, 34(8): 1423-1436.
XU Ge, WANG Houfeng.The development of topics models in natural language processing [J].Chinese Journal of Computers, 2011, 34(8): 1423-1436.
[9] 馮時, 景珊, 楊卓, 等.基于LDA模型的中文微博話題意見領袖挖掘 [J].東北大學學報, 2013, 34(4): 490-494.
FENG Shi, JING Shan, YANG Zhuo, et al.Detecting topical opinion leaders based on LDA model in Chinese microblogs [J].Journal of Northeastern University, 2013, 34(4): 490-494.
[10]LIN C, HE Y.Joint sentiment/topic model for sentiment analysis [C]∥The 18th ACM Conference on Information and Knowledge Management.New York, USA: ACM, 2009: 375-384.
[11]TITOV I, MCDONALD R.Modeling online reviews with multi-grain topic models [C]∥The 17th International World Wide Web Conference 2008.New York, USA: ACM, 2008: 111-120.
[12]JO Y, OH A.Aspect and sentiment unification mode for online review analysis [C]∥The 4th ACM International Conference on Web Search and Data Mining.New York, USA: ACM, 2011: 815-824.
[13]GRIFFITHS T, STEYVERS M, TENENBAUM J B.Topics in semantic representation [J].Psychological Review, 2007, 114(2): 211-244.
[14]GRIFFITHS T, STEYVERS M.Finding scientific topics [C]∥Proceedings of the National Academy of Sciences.New York, USA: United States National Academy of Sciences, 2004: 5228-5235.
(編輯 趙煒)
AJointModelforMulti-GranularityTopicsandSentimentswithFusingWordOrderInformation
ZHAO Yu,SHAO Bilin,BIAN Genqing
(School of Management, Xi’an University of Architecture and Technology, Xi’an 710055, China)
A joint model for multi-granularity topics and sentiments (MTSU-Col model) based on an extension to LDA model by incorporating collocation is proposed to solve the problem that the basic topic model captures only coarse-granularity contextual information.The MTSU-Col model objectively expresses the correlative relationship among words, globallocal topics, sentiment labels and collocation, allows us to infer topics and sentiment information, and provides a closer match to real semantic representation contained in texts.The MTSU-Col model synchronously realizes an unsupervised mining of multi-granularity topics and sentiment information, and effectively solves the domain dependent problem in existing methods.Experimental results show that the proposed model achievesF1of 84% for sentiment classification, and its performance is comparable to the performance of SVM methods.Since the mining collection of topics is hierarchy and semantic related, it is feasible and effective to use the proposed model for opinion mining.
topic model; text sentiment analysis; unification model; collocation
2014-03-26。
趙煜(1981—),男,博士生;邵必林(通信作者),男,教授,博士生導師。
國家自然科學基金資助項目(61272458)。
10.7652/xjtuxb201411018
TP391
:A
:0253-987X(2014)11-0103-06
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
